干貨|在機器學習中如何應對不均衡分類問題?
在處理機器學習等數據科學問題時,經常會碰到不均衡種類分布的情況,即在樣本數據中一個或多個種類的觀察值明顯少于其他種類的觀察值的現象。在我們更關心少數類的問題時這個現象會非常突出,例如竊電問題、銀行詐騙性交易、罕見病鑒定等。在這種情況下,運用常規的機器學習算法的預測模型可能會無法準確預測。這是因為機器學習算法通常是通過減少錯誤來增加準確性,而不考慮種類的平衡。這篇文章講了不同的方法來解決這個不均衡分類問題,同時說明了這些方法的好處和壞處。
不均衡數據集一般是指少數類所占比例少于5%的數據集,少數類通常是指稀有事件的發生。例如在一個公共欺詐檢測數據集中,有如下數據:
總觀測數據 = 1000 欺詐的觀測數據 = 20 非欺詐的觀測數據 = 980 事件發生率 = 2%
在分析這個數據集時最主要的問題是,如何通過合適的稀有事件的樣本數目得到一個平衡的數據集?
傳統的模型評估方法不能準確的評價不均衡數據集訓練的模型的表現。顯然,模型趨向于預測多數集,少數集可能會被當作噪點或被忽視。因此,相比于多數集,少數集被錯分的可能性很大。當使用一個不均衡數據集訓練模型時,準確率并不是一個合適的評價方式。假如一個分類器可以達到98%的準確率,我們會認為這個模型表現很好,而對于一個少數集占總體2%的數據集來說,如果分類器把全部都預測為多數集,準確率就能達到98%,可是這個分類器對于預測沒有任何用處。
不均衡數據集解決方法
解決不均衡數據集帶來的模型預測不準確的問題主要有兩種方法,第一種方法是在數據層面將數據集轉變為較為平衡的數據集,然后進行建模;第二種則是在算法層面改進算法模型的表現。
數據層面方法:重抽樣
在將數據用于建模之前,先運用重抽樣技術使數據變平衡。平衡數據主要通過兩種方式達到:增加少數類的頻率或減少多數類的頻率。通過重抽樣來改變兩個種類所占的比例。
隨機欠抽樣
隨機欠抽樣技術通過隨機刪除多數類的實例來平衡種類分布。在之前的例子中,我們無放回的取10%非欺詐數據,結合所有的欺詐數據形成新數據集。這樣,總觀測數據變為20+980*10%=118,而欠抽樣之后新數據集的事件發生率為20/118=17%。
當訓練數據很多時,隨機欠抽樣通過減少訓練數據的數量提高運行時間和解決存儲問題。然而,這也會帶來潛在有效信息被刪除的問題。欠抽樣選擇的數據可能是偏差樣本,無法準確代表總體。因此,會導致在測試集中表現欠佳。
隨機過抽樣
過抽樣技術是通過隨機復制少數類的實例來增加少數類的數量。在之前的例子中,復制20個少數實例20遍,使少數類數據變為400條,總觀測數據變為980+400=1380,事件發生概率為400/1380=29%。與欠抽樣不同,過抽樣不會損失任何信息。一般來說,過抽樣表現好于欠抽樣。然而,由于過抽樣復制了多遍少數類數據,導致過擬合(over-fitting)的可能性變大。
基于聚類的過抽樣
基于聚類的過抽樣是將k-means聚類算法分別應用在少數類和多數類中,識別出數據集中不同簇(cluster)。隨后,通過對每個簇過抽樣來確保多數類和少數類的簇中實例的數目相等。假設對于剛才的數據集做聚類結果如下:
多數類簇:
簇1: 150觀測數據
簇2: 120觀測數據
簇3: 230觀測數據
簇4: 200觀測數據
簇5: 150觀測數據
簇6: 130觀測數據
少數類簇:
簇1: 8觀測數據
簇2: 12觀測數據
對簇過抽樣之后,每個相同種類的簇含有相同的數量的觀測數據:
多數類簇:
簇1: 170觀測數據
簇2: 170觀測數據
簇3: 170觀測數據
簇4: 170觀測數據
簇5: 170觀測數據
簇6: 170觀測數據
少數類簇:
簇1: 250觀測數據
簇2: 250觀測數據
基于聚類的過抽樣之后,事件發生率為 500/(1020+500)=33%。這種方法考慮了多數類少數類由不同的簇組成,解決了每個簇所包含的實例不同的問題。然而,由于這是一種過抽樣技術,同樣也可能會導致過擬合。
合成少數類過抽樣(SMOTE)
SMOTE避免了復制少數類導致的過擬合問題。用少數類的子集來創造新的合成的相似少數類實例。將這些合成的實例加入原有數據集,豐富少數類的數據。下圖展示了創造合成實例的方法。
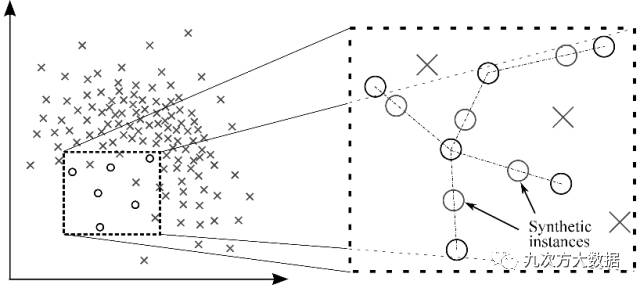
圖1:通過SMOTE創造合成實例
還是用之前的例子,在少數類中選取15個樣本實例,合成20次新的數據。少數類數據變為為300條,事件發生率為300/1280=23.4%。
這種方法通過合成新數據緩解了由于復制少數類帶來的過擬合問題,同時不會造成有效信息丟失。然而,當合成新實例時,沒有考慮與其他類的相鄰實例,這可能會導致種類重疊,并且可能會添入額外的噪點。
算法集合技術
上面所說的技術都是通過對原數據集進行重抽樣來得到均衡數據集。在這一部分中,我們將對于現有分類算法進行改進,使其適用于不均衡數據集。算法合成的目的是提升單一分類器的表現,下圖展示了合成算法的方法。

圖2:算法集合技術的方法
基于bagging
Bagging是Bootstrap Aggregating的縮寫。傳統的bagging算法生成n個可以互相替換的bootstrap訓練樣本。基于每個樣本,訓練不同的模型,最后匯總這些模型的預測結果。Bagging可以減少過擬合,從而創造更精準的預測模型。與boosting不同的是,bagging允許對訓練樣本集進行替換。下圖展示了bagging的流程。

圖3: Bagging的方法
在之前的例子中,從總體中可替換的抽取10個bootstrap樣本,每個樣本包含200個觀測值。每個樣本都與原始數據不相同,但是與原始數據的分布和可變性相似。很多機器學習算法都可以用來訓練這10個bootstrap樣本,如邏輯回歸、神經網絡、決策樹等,得到10個不同的分類器C1,C2…C10。將這10個分類器 集合成一個復合分類器。這種集合算法結合了多個單獨的分類器的結果,可以得到一個更好的復合分類器。Bagging算法提升了機器學習算法的穩定性和準確性,并且解決了過擬合問題。在有噪點的數據環境中,bagging比boosting表現更加優異。
基于Boosting
Boosting也是一個算法集合技術,它將弱分類器結合起來,形成一個可以準確預測的強分類器。Boosting從一個為訓練集準備的弱分類器開始。弱分類器是指預測準確率只比平均數高一點的分類器,如果數據發生一點變化就會導致分類模型發生很大變化。Boosting是一種提高任意給定學習算法精確度的方法。下圖展示了Boosting的方法。

圖4: Boosting的方法
下面介紹幾種不同的boosting技術。
Ada Boost是Boosting算法家族中的代表算法,通過結合許多弱分類器形成一個準確的預測分類器。每個分類器的目的都是正確分類上一輪被分錯的實例。每一輪之后,被分錯的實例的權重增加,被正確分類的實例的權重降低。應用Ada Boost到剛才的不均衡數據集中,首先給每一個實例相同的權重,假設基礎分類器只分對了400個實例,將這400個實例的權重減小為,剩下600個被錯分的實例的權重增加到。每一輪中,弱分類器通過更新權重來提升它的表現。這個過程持續到錯分率明顯下降,分類器變成了強分類器為止。Ada Boost的好處在于它非常便于執行,而且非常普遍,適用于所有種類的分類算法,也不會導致過擬合。壞處是它對于噪點和異常值非常敏感。
Gradient Boosting 是一個最優化算法,每個模型都按順序通過Gradient Descent方法最小化損失函數。在Gradient Boosting中,決策樹被當作一個弱分類器。Ada Boost和Gradient Boosting都是將弱分類器變為強分類器的方法,但這兩種方法有本質的不同。Ada Boost在學習過程開始之前要求用戶設立弱分類器集或者隨機生成弱分類器集,每一個弱分類器的權重會根據是否分類正確調整。Gradient Boosting則是在訓練集上建立第一個分類器預測,接著計算損失值,然后運用損失值來改進分類器。每一步中,損失函數的殘差都會通過Gradient Descent Method來計算。在隨后的迭代中,新的殘差變成了目標變量。Gradient Tree Boosting比隨機森林更難以擬合。它有三個參數可以微調,Shrinkage參數,樹的深度和樹的數量。選擇合適的參數才能得到好的擬合的Gradient boosted tree。如果參數調整的不正確,可能會導致過擬合。
結論
當面對不均衡數據集時,沒有一個解決方案可以提升所有預測模型的準確性。我們所需要做的可能就是嘗試不同的方法,找出最適合這個數據集的方法。最有效的解決不均衡數據集的技術取決于數據集的特征。在大多數情況中,合成抽樣技術如SMOTE會比傳統的過抽樣和欠抽樣表現更好。為了得到更好的結果,可以同時使用合成抽樣技術和boosting方法。在比較不同方法時,可以考慮相關的評估參數。在比較使用前述方法所建立的多個預測模型的時候,可以用ROC曲線下的面積來得出哪個模型效果更好。