從重采樣到數據合成:如何處理機器學習中的不平衡分類問題?
如果你研究過一點機器學習和數據科學,你肯定遇到過不平衡的類分布(imbalanced class distribution)。這種情況是指:屬于某一類別的觀測樣本的數量顯著少于其它類別。
這個問題在異常檢測是至關重要的的場景中很明顯,例如電力盜竊、銀行的欺詐交易、罕見疾病識別等。在這種情況下,利用傳統機器學習算法開發出的預測模型可能會存在偏差和不準確。
發生這種情況的原因是機器學習算法通常被設計成通過減少誤差來提高準確率。所以它們并沒有考慮類別的分布/比例或者是類別的平衡。
這篇指南描述了使用多種采樣技術來解決這種類別不平衡問題的各種方法。本文還比較了每種技術的優缺點。最后,本文作者還向我們展示了一種讓你可以創建一個平衡的類分布的方法,讓你可以應用專門為此設計的集成學習技術(ensemble learning technique)。
目錄
1. 不平衡數據集面臨的挑戰
2. 處理不平衡數據集的方法
3. 例證
4. 結論
一、不平衡數據集面臨的挑戰
當今公用事業行業面臨的主要挑戰之一就是電力盜竊。電力盜竊是全球第三大盜竊形式。越來越多的公用事業公司傾向于使用高級的數據分析技術和機器學習算法來識別代表盜竊的消耗模式。
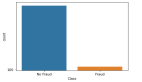
然而,最大的障礙之一就是海量的數據及其分布。欺詐性交易的數量要遠低于正常和健康的交易,也就是說,它只占到了總觀測量的大約 1-2%。這里的問題是提高識別罕見的少數類別的準確率,而不是實現更高的總體準確率。
當面臨不平衡的數據集的時候,機器學習算法傾向于產生不太令人滿意的分類器。對于任何一個不平衡的數據集,如果要預測的事件屬于少數類別,并且事件比例小于 5%,那就通常將其稱為罕見事件(rare event)。
1. 不平衡類別的實例
讓我們借助一個實例來理解不平衡類別。
例子:在一個公用事業欺詐檢測數據集中,你有以下數據:
- 總觀測 = 1000
- 欺詐觀測 = 20
- 非欺詐觀測 = 980
- 罕見事件比例 = 2%
這個案例的數據分析中面臨的主要問題是:對于這些先天就是小概率的異常事件,如何通過獲取合適數量的樣本來得到一個平衡的數據集?
2. 使用標準機器學習技術時面臨的挑戰
面臨不平衡數據集的時候,傳統的機器學習模型的評價方法不能精確地衡量模型的性能。
諸如決策樹和 Logistic 回歸這些標準的分類算法會偏向于數量多的類別。它們往往會僅預測占數據大多數的類別。在總量中占少數的類別的特征就會被視為噪聲,并且通常會被忽略。因此,與多數類別相比,少數類別存在比較高的誤判率。
對分類算法的表現的評估是用一個包含關于實際類別和預測類別信息的混淆矩陣(Confusion Matrix)來衡量的。
 / (TP+FN+FP+TP)")
如上表所示,模型的準確率 = (TP+TN) / (TP+FN+FP+TP)
然而,在不平衡領域時,準確率并不是一個用來衡量模型性能的合適指標。例如:一個分類器,在包含 2% 的罕見事件時,如果它將所有屬于大部分類別的實例都正確分類,實現了 98% 的準確率;而把占 2% 的少數觀測數據視為噪聲并消除了。
3. 不平衡類別的實例
因此,總結一下,在嘗試利用不平衡數據集解決特定業務的挑戰時,由標準機器學習算法生成的分類器可能無法給出準確的結果。除了欺詐性交易,存在不平衡數據集問題的常見業務問題還有:
- 識別客戶流失率的數據集,其中絕大多數顧客都會繼續使用該項服務。具體來說,電信公司中,客戶流失率低于 2%。
- 醫療診斷中識別罕見疾病的數據集
- 自然災害,例如地震
4. 使用的數據集
這篇文章中,我們會展示多種在高度不平衡數據集上訓練一個性能良好的模型的技術。并且用下面的欺詐檢測數據集來精確地預測罕見事件:
- 總觀測 = 1000
- 欺詐觀測 = 20
- 非欺詐性觀測 = 980
- 事件比例 = 2%
- 欺詐類別標志 = 0(非欺詐實例)
- 欺詐類別標志 = 1(欺詐實例)
二、處理不平衡數據集的方法
1. 數據層面的方法:重采樣技術
處理不平衡數據集需要在往機器學習算法輸入數據之前,制定諸如提升分類算法或平衡訓練數據的類(數據預處理)的策略。后者因為應用范圍廣泛而更常使用。
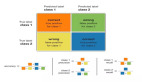
平衡分類的主要目標不是增加少數類的的頻率就是降低多數類的頻率。這樣做是為了獲得大概相同數量的兩個類的實例。讓我們一起看看幾個重采樣(resampling)技術:
(1)隨機欠采樣(Random Under-Sampling)
隨機欠采樣的目標是通過隨機地消除占多數的類的樣本來平衡類分布;直到多數類和少數類的實例實現平衡,目標才算達成。
- 總觀測 = 1000
- 欺詐性觀察 = 20
- 非欺詐性觀察 = 980
- 事件發生率 = 2%
這種情況下我們不重復地從非欺詐實例中取 10% 的樣本,并將其與欺詐性實例相結合。
隨機欠采樣之后的非欺詐性觀察 = 980 x 10% = 98
結合欺詐性與非欺詐性觀察之后的全體觀察 = 20+98 = 118
欠采樣之后新數據集的事件發生率 = 20/118 = 17%
優點
- 它可以提升運行時間;并且當訓練數據集很大時,可以通過減少樣本數量來解決存儲問題。
缺點
- 它會丟棄對構建規則分類器很重要的有價值的潛在信息。
- 被隨機欠采樣選取的樣本可能具有偏差。它不能準確代表大多數。從而在實際的測試數據集上得到不精確的結果。
(2)隨機過采樣(Random Over-Sampling)
過采樣(Over-Sampling)通過隨機復制少數類來增加其中的實例數量,從而可增加樣本中少數類的代表性。
- 總觀測 = 1000
- 欺詐性觀察 = 20
- 非欺詐性觀察 = 980
- 事件發生率 = 2%
這種情況下我們復制 20 個欺詐性觀察 20 次。
- 非欺詐性觀察 = 980
- 復制少數類觀察之后的欺詐性觀察 = 400
- 過采樣之后新數據集中的總體觀察 = 1380
- 欠采樣之后新數據集的事件發生率 = 400/1380 = 29%
優點
- 與欠采樣不同,這種方法不會帶來信息損失。
- 表現優于欠采樣。
缺點
- 由于復制少數類事件,它加大了過擬合的可能性。
(3)基于聚類的過采樣(Cluster-Based Over Sampling)
在這種情況下,K-均值聚類算法獨立地被用于少數和多數類實例。這是為了識別數據集中的聚類。隨后,每一個聚類都被過采樣以至于相同類的所有聚類有著同樣的實例數量,且所有的類有著相同的大小。
- 總觀測 = 1000
- 欺詐性觀察 = 20
- 非欺詐性觀察 = 980
- 事件發生率 = 2%
多數類聚類
- 1. 聚類 1:150 個觀察
- 2. 聚類 2:120 個觀察
- 3. 聚類 3:230 個觀察
- 4. 聚類 4:200 個觀察
- 5. 聚類 5:150 個觀察
- 6. 聚類 6:130 個觀察
少數類聚類
- 1. 聚類 1:8 個觀察
- 2. 聚類 2:12 個觀察
每個聚類過采樣之后,相同類的所有聚類包含相同數量的觀察。
多數類聚類
- 1. 聚類 1:170 個觀察
- 2. 聚類 2:170 個觀察
- 3. 聚類 3:170 個觀察
- 4. 聚類 4:170 個觀察
- 5. 聚類 5:170 個觀察
- 6. 聚類 6:170 個觀察
少數類聚類
- 1. 聚類 1:250 個觀察
- 2. 聚類 2:250 個觀察
基于聚類的過采樣之后的事件率 = 500/ (1020+500) = 33 %
優點
- 這種聚類技術有助于克服類之間不平衡的挑戰。表示正例的樣本數量不同于表示反例的樣本數量。
- 有助于克服由不同子聚類組成的類之間的不平衡的挑戰。每一個子聚類不包含相同數量的實例。
缺點
- 正如大多數過采樣技術,這一算法的主要缺點是有可能過擬合訓練集。
(4)信息性過采樣:合成少數類過采樣技術(SMOTE)
這一技術可用來避免過擬合——當直接復制少數類實例并將其添加到主數據集時。從少數類中把一個數據子集作為一個實例取走,接著創建相似的新合成的實例。這些合成的實例接著被添加進原來的數據集。新數據集被用作樣本以訓練分類模型。
- 總觀測 = 1000
- 欺詐性觀察 = 20
- 非欺詐性觀察 = 980
- 事件發生率 = 2%
從少數類中取走一個包含 15 個實例的樣本,并生成相似的合成實例 20 次。
生成合成性實例之后,創建下面的數據集
- 少數類(欺詐性觀察)= 300
- 多數類(非欺詐性觀察)= 980
- 事件發生率 = 300/1280 = 23.4 %
優點
- 通過隨機采樣生成的合成樣本而非實例的副本,可以緩解過擬合的問題。
- 不會損失有價值信息。
缺點
- 當生成合成性實例時,SMOTE 并不會把來自其他類的相鄰實例考慮進來。這導致了類重疊的增加,并會引入額外的噪音。
- SMOTE 對高維數據不是很有效。

圖 1:合成少數類過采樣算法,其中 N 是屬性的數量

圖 2:借助 SMOTE 的合成實例生成
(5)改進的合成少數類過采樣技術(MSMOTE)
這是 SMOTE 的改進版本,SMOTE 沒有考慮數據集中少數類和潛在噪聲的基本分布。所以為了提高 SMOTE 的效果,MSMOTE 應運而生。
該算法將少數類別的樣本分為 3 個不同的組:安全樣本、邊界樣本和潛在噪聲樣本。分類通過計算少數類的樣本和訓練數據的樣本之間的距離來完成。安全樣本是可以提高分類器性能的那些數據點。而另一方面,噪聲是可以降低分類器的性能的數據點。兩者之間的那些數據點被分類為邊界樣本。
雖然 MSOMTE 的基本流程與 SMOTE 的基本流程相同,在 MSMOTE 中,選擇近鄰的策略不同于 SMOTE。該算法是從安全樣本出發隨機選擇 k-最近鄰的數據點,并從邊界樣本出發選擇最近鄰,并且不對潛在噪聲樣本進行任何操作。
2. 算法集成技術(Algorithmic Ensemble Techniques)
上述部分涉及通過重采樣原始數據提供平衡類來處理不平衡數據,在本節中,我們將研究一種替代方法:修改現有的分類算法,使其適用于不平衡數據集。
集成方法的主要目的是提高單個分類器的性能。該方法從原始數據中構建幾個兩級分類器,然后整合它們的預測。

圖 3:基于集成的方法
(1)基于 Bagging 的方法
Bagging 是 Bootstrap Aggregating 的縮寫。傳統的 Bagging 算法包括生成「n」個不同替換的引導訓練樣本,并分別訓練每個自舉算法上的算法,然后再聚合預測。
Bagging 常被用于減少過擬合,以提高學習效果生成準確預測。與 boosting 不同,bagging 方法允許在自舉樣本中進行替換。

圖 4:Bagging 方法
- 總觀測= 1000
- 欺詐觀察= 20
- 非欺詐觀察= 980
- 事件率= 2%
從具有替換的群體中選擇 10 個自舉樣品。每個樣本包含 200 個觀察值。每個樣本都不同于原始數據集,但類似于分布和變化上與該數據集類似。機器學習算法(如 logistic 回歸、神經網絡與決策樹)擬合包含 200 個觀察的自舉樣本,且分類器 c1,c2 ... c10 被聚合以產生復合分類器。這種集成方法能產生更強的復合分類器,因為它組合了各個分類器的結果。
優點
- 提高了機器學習算法的穩定性與準確性
- 減少方差
- 減少了 bagged 分類器的錯誤分類
- 在嘈雜的數據環境中,bagging 的性能優于 boosting
缺點
- bagging 只會在基本分類器效果很好時才有效。錯誤的分類可能會進一步降低表現。
(2)基于 Boosting 的方法
Boosting 是一種集成技術,它可以將弱學習器結合起來創造出一個能夠進行準確預測的強大學習器。Boosting 開始于在訓練數據上準備的基本分類器/弱分類器。
基本學習器/分類器是弱學習器,即預測準確度僅略好于平均水平。弱是指當數據的存在小變化時,會引起分類模型出現大的變化。
在下一次迭代中,新分類器將重點放在那些在上一輪中被錯誤分類的案例上。

圖 5:Boosting 方法
a. 自適應 boosting——Ada Boost
Ada Boost 是最早的 boosting 技術,其能通過許多弱的和不準確的規則的結合來創造高準確度的預測。其中每個訓練器都是被串行地訓練的,其目標在每一輪正確分類上一輪沒能正確分類的實例。
對于一個學習過的分類器,如果要做出強大的預測,其應該具備以下三個條件:
- 規則簡單
- 分類器在足夠數量的訓練實例上進行了訓練
- 分類器在訓練實例上的訓練誤差足夠低
每一個弱假設都有略優于隨機猜測的準確度,即誤差項 € (t) 應該略大約 ½-β,其中 β>0。這是這種 boosting 算法的基礎假設,其可以產生一個僅有一個很小的誤差的最終假設。
在每一輪之后,它會更加關注那些更難被分類的實例。這種關注的程度可以通過一個權重值(weight)來測量。起初,所有實例的權重都是相等的,經過每一次迭代之后,被錯誤分類的實例的權重會增大,而被正確分類的實例的權重則會減小。

圖 6:自適應 boosting 的方法
比如如果有一個包含了 1000 次觀察的數據集,其中有 20 次被標記為了欺詐。剛開始,所有的觀察都被分配了相同的權重 W1,基礎分類器準確分類了其中 400 次觀察。
然后,那 600 次被錯誤分類的觀察的權重增大為 W2,而這 400 次被正確分類的實例的權重減小為 W3。
在每一次迭代中,這些更新過的加權觀察都會被送入弱的分類器以提升其表現。這個過程會一直持續,直到錯誤分類率顯著降低,從而得到一個強大的分類器。
優點
非常簡單就能實現
可以很好地泛化——適合任何類型的分類問題且不易過擬合
缺點
- 對噪聲數據和異常值敏感
b. 梯度樹 boosting
在梯度 Boosting(Gradient Boosting)中,許多模型都是按順序訓練的。其是一種數值優化算法,其中每個模型都使用梯度下降(Gradient Descent)方法來最小化損失函數 y = ax+b+e。
在梯度 Boosting 中,決策樹(Decision Tree)被用作弱學習器。
盡管 Ada Boost 和梯度 Boosting 都是基于弱學習器/分類器工作的,而且都是在努力使它們變成強大的學習器,但這兩種方法之間存在一些顯著的差異。Ada Boost 需要在實際的訓練過程之前由用戶指定一組弱學習器或隨機生成弱學習器。其中每個學習器的權重根據其每步是否正確執行了分類而進行調整。而梯度 Boosting 則是在訓練數據集上構建第一個用來預測樣本的學習器,然后計算損失(即真實值和第一個學習器的輸出之間的差),然后再使用這個損失在第二個階段構建改進了的學習器。
在每一個步驟,該損失函數的殘差(residual)都是用梯度下降法計算出來的,而新的殘差會在后續的迭代中變成目標變量。
梯度 Boosting 可以通過 R 語言使用 SAS Miner 和 GBM 軟件包中的 Gradient Boosting Node 實現。

圖 7:梯度 Boosting 方法
比如,如果有一個包含了 1000 次觀察的訓練數據集,其中有 20 次被標記為了欺詐,并且還有一個初始的基礎分類器。目標變量為 Fraud,當交易是欺詐時,Fraud=1;當交易不是欺詐時,Fraud=0.
比如說,決策樹擬合的是準確分類僅 5 次觀察為欺詐觀察的情況。然后基于該步驟的實際輸出和預測輸出之間的差,計算出一個可微的損失函數。該損失函數的這個殘差是下一次迭代的目標變量 F1。
類似地,該算法內部計算該損失函數,并在每個階段更新該目標,然后在初始分類器的基礎上提出一個改進過的分類器。
缺點
- 梯度增強過的樹比隨機森林更難擬合
- 梯度 Boosting 算法通常有 3 個可以微調的參數:收縮(shrinkage)參數、樹的深度和樹的數量。要很好擬合,每個參數都需要合適的訓練。如果這些參數沒有得到很好的調節,那么就可能會導致過擬合。
c. XGBoost
XGBoost(Extreme Gradient Boosting/極限梯度提升)是 Gradient Boosting 算法的一種更先進和更有效的實現。
相對于其它 Boosting 技術的優點:
- 速度比普通的 Gradient Boosting 快 10 倍,因為其可以實現并行處理。它是高度靈活的,因為用戶可以自定義優化目標和評估標準,其具有內置的處理缺失值的機制。
- 和遇到了負損失就會停止分裂節點的 Gradient Boosting 不同,XGBoost 會分裂到指定的最大深度,然后會對其樹進行反向的剪枝(prune),移除僅有一個負損失的分裂。
XGBoost 可以使用 R 和 Python 中的 XGBoost 包實現。
三、實際案例
1. 數據描述
這個例子使用了電信公司的包含了 47241 條顧客記錄的數據集,每條記錄包含的信息有 27 個關鍵預測變量

罕見事件數據集的數據結構如下,缺失值刪除、異常值處理以及降維

從這里下載數據集:
https://static.analyticsvidhya.com/wp-content/uploads/2017/03/17063705/SampleData_IMC.csv
2. 方法描述
使用合成少數類過采樣技術(SMOTE)來平衡不平衡數據集——該技術是試圖通過創建合成實例來平衡數據集。下面以 R 代碼為例,示范使用 Gradient Boosting 算法來訓練平衡數據集。
- R 代碼
- # 加載數據
- rareevent_boost <- read.table("D:/Upasana/RareEvent/churn.txt",sep="|", header=TRUE)
- dmy<-dummyVars("~.",data=rareevent_boost)
- rareeventTrsf<-data.frame(predict(dmy,newdata= rareevent_boost))
- set.seed(10)
- sub <- sample(nrow(rareeventTrsf), floor(nrow(rareeventTrsf) * 0.9))
- sub1 <- sample(nrow(rareeventTrsf), floor(nrow(rareeventTrsf) * 0.1))
- training <- rareeventTrsf [sub, ]
- testing <- rareeventTrsf [-sub, ]
- training_sub<- rareeventTrsf [sub1, ]
- tables(training_sub)
- head(training_sub)
- # 對于不平衡的數據集 #
- install.packages("unbalanced")
- library(unbalanced)
- data(ubIonosphere)
- n<-ncol(rareevent_boost)
- output<- rareevent_boost $CHURN_FLAG
- output<-as.factor(output)
- input<- rareevent_boost [ ,-n]
- View(input)
- # 使用 ubSMOTE 來平衡數據集 #
- data<-ubBalance(X= input, Y=output, type="ubSMOTE", percOver=300, percUnder=150, verbose=TRUE
- View(data)
- # 平衡的數據集 #
- balancedData<-cbind(data$X,data$Y)
- View(balancedData)
- table(balancedData$CHURN_FLAG)
- # 寫入平衡的數據集來訓練模型 #
- write.table(balancedData,"D:/ Upasana/RareEvent /balancedData.txt", sep="\t", row.names=FALSE)
- # 創建 Boosting 樹模型 #
- repalceNAsWithMean <- function(x) {replace(x, is.na(x), mean(x[!is.na(x)]))}
- training <- repalceNAsWithMean(training)
- testing <- repalceNAsWithMean(testing)
- # 重采樣技術 #
- View(train_set)
- fitcontrol<-trainControl(method="repeatedcv",number=10,repeats=1,verbose=FALSE)
- gbmfit<-train(CHURN_FLAG~.,data=balancedData,method="gbm",verbose=FALSE)
- # 為測試數據評分 #
- testing$score_Y=predict(gbmfit,newdata=testing,type="prob")[,2]
- testing$score_Y=ifelse(testing$score_Y>0.5,1,0)
- head(testing,n=10)
- write.table(testing,"D:/ Upasana/RareEvent /testing.txt", sep="\t", row.names=FALSE)
- pred_GBM<-prediction(testing$score_Y,testing$CHURN_FLAG)
- # 模型的表現 #
- model_perf_GBM <- performance(pred_GBM, "tpr", "fpr")
- model_perf_GBM1 <- performance(pred_GBM, "tpr", "fpr")
- model_perf_GBM
- pred_GBM1<-as.data.frame(model_perf_GBM)
- auc.tmp_GBM <- performance(pred_GBM,"auc")
- AUC_GBM <- as.numeric(auc.tmp_GBM@y.values)
- auc.tmp_GBM
結果
這個在平衡數據集上使用了 SMOTE 并訓練了一個 gradient boosting 算法的平衡數據集的辦法能夠顯著改善預測模型的準確度。較之平常分析建模技術(比如 logistic 回歸和決策樹),這個辦法將其 lift 提升了 20%,精確率也提升了 3 到 4 倍。
四、結論
遇到不平衡數據集時,沒有改善預測模型準確性的一站式解決方案。你可能需要嘗試多個辦法來搞清楚最適合數據集的采樣技術。在絕大多數情況下,諸如 SMOTE 以及 MSMOTE 之類的合成技術會比傳統過采樣或欠采樣的辦法要好。
為了獲得更好的結果,你可以在使用諸如 Gradeint boosting 和 XGBoost 的同時也使用 SMOTE 和 MSMOTE 等合成采樣技術。
通常用于解決不平衡數據集問題的先進 bagging 技術之一是 SMOTE bagging。這個辦法采取了一種完全不同于傳統 bagging 技術的辦法來創造每個 Bag/Bootstrap。通過每次迭代時設置一個 SMOTE 重采樣率,它可以借由 SMOTE 算法生成正例。每次迭代時,負例集會被 bootstrap。
不平衡數據集的特點不同,最有效的技術也會有所不同。對比模型時要考慮相關評估參數。
在對比通過全面地結合上述技術而構建的多個預測模型時,ROC 曲線下的 Lift & Area 將會在決定最優模型上發揮作用。
本文作者為來自 KPMG 的數據分析顧問 Upasana Mukherjee。
原文地址:https://www.analyticsvidhya.com/blog/2017/03/imbalanced-classification-problem/
【本文是51CTO專欄機構機器之心的原創譯文,微信公眾號“機器之心( id: almosthuman2014)”】