機器學習分類問題:九個常用的評估指標總結

對機器學習的評估度量是機器學習核心部分,本文總結分類問題常用的請估指標。
分類問題評估指標
在這里,將討論可用于評估分類問題預測的各種性能指標。
1. Confusion Matrix
這是衡量分類問題性能的最簡單方法,其中輸出可以是兩種或更多類型的類。混淆矩陣只不過是一個具有兩個維度的表,即“實際”和“預測”,此外,這兩個維度都有“真陽性(TP)”、“真陰性(TN)”、“假陽性(FP)”和“假陰性(FN)”,如下所示:

與混淆矩陣相關的術語解釋如下:
- 真陽(TP)? 當數據點的實際類別和預測類別均為1
- 真實陰(TN)? 當數據點的實際類和預測類都為0
- 假陽(FP)? 當數據點的實際類別為0,預測的數據點類別為1
- 假陰(FN)? 當數據點的實際類別為1,預測的數據點類別為0
我們可以使用sklearn的混淆矩陣函數confusion_matrix,用于計算分類模型混淆矩陣的度量。
2. Accuracy
它是分類算法最常見的性能度量。它可以被定義為正確預測的數量與所有預測的比率。我們可以通過混淆矩陣,借助以下公式輕松計算:
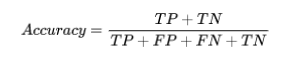
我們可以使用sklearn的accuracy_score函數,計算分類模型準確性的指標
3. Precision
precision定義為ML模型預測結果中:預測正確的正樣本數除以所有的預測正樣本數:

4. Recall
recall定義為ML模型預測結果中:預測正確的正樣本數除以所有的實際正樣本數:
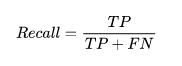
5. Specificity
specificity定義為ML模型預測結果中:預測正確的負樣本數除以所有的實際負樣本數:
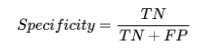
6. Support
支持度可定義為每類目標值中相應的樣本數。
7. F1 Score
該分數將為我們提供precision和recall的調和平均值。從數學上講,F1分數是precision和recall的加權平均值。F1的最佳值為1,最差值為0。我們可以使用以下公式計算F1分數:

F1分數對precision和recall的相對貢獻相等。
我們可以使用sklearn的classification_report功能,用于獲取分類模型的分類報告的度量。
8. AUC (Area Under ROC curve)
AUC(曲線下面積)-ROC(接收器工作特性)是基于不同閾值的分類問題性能指標。顧名思義,ROC是一條概率曲線,AUC衡量可分離性。簡單地說,AUC-ROC度量將告訴我們模型區分類的能力,AUC越高,模型越好。
從數學上講,可以通過繪制不同閾值下的TPR(真陽性率),即specificity或recall與FPR(假陽性率),下圖顯示了ROC、AUC,y軸為TPR,x軸為FPR:

我們可以使用sklearn的roc_auc_score函數,計算AUC-ROC的指標。
9. LOGLOSS (Logarithmic Loss)
它也稱為邏輯回歸損失或交叉熵損失。它基本上定義在概率估計上,并測量分類模型的性能,其中輸入是介于0和1之間的概率值。
通過精確區分,可以更清楚地理解它。正如我們所知,準確度是我們模型中預測的計數(預測值=實際值),而對數損失是我們預測的不確定性量,基于它與實際標簽的差異。借助對數損失值,我們可以更準確地了解模型的性能。我們可以使用sklearn的log_loss函數。
例子
下面是Python中的一個簡單方法,它將讓我們了解如何在二進制分類模型上使用上述性能指標。
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
from sklearn.metrics import roc_auc_score
from sklearn.metrics import log_loss
X_actual = [1, 1, 0, 1, 0, 0, 1, 0, 0, 0]
Y_predic = [1, 0, 1, 1, 1, 0, 1, 1, 0, 0]
results = confusion_matrix(X_actual, Y_predic)
print ('Confusion Matrix :')
print(results)
print ('Accuracy Score is',accuracy_score(X_actual, Y_predic))
print ('Classification Report : ')
print (classification_report(X_actual, Y_predic))
print('AUC-ROC:',roc_auc_score(X_actual, Y_predic))
print('LOGLOSS Value is',log_loss(X_actual, Y_predic))
輸出:
Confusion Matrix :
[
[3 3]
[1 3]
]
Accuracy Score is 0.6
Classification Report :
precision recall f1-score support
0 0.75 0.50 0.60 6
1 0.50 0.75 0.60 4
micro avg 0.60 0.60 0.60 10
macro avg 0.62 0.62 0.60 10
weighted avg 0.65 0.60 0.60 10
AUC-ROC: 0.625
LOGLOSS Value is 13.815750437193334