在??上一篇??中主要講了對于文本語料的提取和預處理的過程,接下來就要進入到核心步驟,即對于處理模型的掌握,處理模型這塊的篇幅會很長,對于不同的模型,其優缺點各不相同,因此有必要對這一塊進行一個全方面的掌握。
在深度學習技術還未應用到自然語言處理領域中之前,在自然語言處理領域中最通用的模型都是基于概率統計的。而其中最為核心的模型就是HMM(隱馬爾可夫模型)。下面就讓本篇文章為讀者揭開HMM的面紗吧,提前說明,對于這一塊模型的掌握需要具備一定的概率論的基礎知識,對于這一塊內容,本文不再作過多的贅述,因為大學本科的高數基本都包含了概率論這門課程。
1.概率模型
在掌握HMM模型之前,首先需要對概率模型進行一個掌握。概率模型,顧名思義,就是將學習任務歸結到計算變量的概率分布的模型。針對于自然語言處理領域,即通過概率分布的形式來表達不同詞匯之間的關聯和區別。概率模型的提出是基于生活中一些觀察到的現象來推測和估計未知的事務這一任務的,在概率模型中這種推測和估計也叫推斷。推斷的本質也就是利用已經有的或者可觀測到的變量,來推測未知變量的條件分布。
1.1.生成模型和判別模型
目前概率模型又可以分為兩類,即生成模型和判別模型。由上文可知,概率模型是通過可觀測變量來推斷未知變量分布,因此為了更好的掌握生成模型和判別模型之間的差異,可以將可觀測的變量命名為X,而需要推斷的未知的變量命名為Y。那么對于生成模型,其需要學習的是X和Y之間的聯合概率分布P(X,Y),而判別模型學習的是條件概率分布P(Y|X)。而對于聯合概率分布和條件概率分布已經是概率論的基礎理論知識,在這不再贅敘了,望不了解的讀者自行查閱。
對于這兩種不同概率分布的模型,其各自模型的能力不同。例如,對于某一個給定的觀測值X,運用條件概率分布P(Y|X),即可以很容易的得出未知Y的值(P(Y)=P(X)*P(Y|X))。因此對于分類問題,就可以直接運用判別模型,即觀測對于給定的X,得到的Y的概率哪一個最大,就可以判別為哪一個類別。因此判別模型更適用于分類任務,其在分類任務上具備顯著的優勢。而對于生成模型,直接用該模型來做分類任務是比較困難的,除非將聯合概率分布轉化為條件概率分布,即將生成模型轉化為判別模型去做分類任務。但是,生成模型主要并不是處理分類問題的,其有專門的用途,之后講的HMM就是一種生成模型,在這先賣個小關子。
1.2.概率圖模型
在掌握生成模型和判別模型的主要過程和任務之后,還需要對概率圖模型有個基本的掌握。它是一種用圖結構作為表示工具,來表達變量之間的關系的概率模型。這里的圖與數據結構中圖的結構是類似的,即由節點和連接節點的邊組成。在概率圖模型中,一般會用節點來表示某一隨機變量,而節點之間的邊則表示不同變量之間的概率關系。同時類比于數據結構,邊也是分為有方向和無方向的,從而也就分為有向圖模型(貝葉斯網絡)和無向圖模型(馬爾可夫網)。雖然HMM的名字里有“馬爾可夫”,但是HMM模型是貝葉斯網絡的一種,在這里不要弄混淆了。
HMM是最為普遍的動態貝葉斯網絡,即對變量序列建模的貝葉斯網絡,屬于有向圖模型。為了后續HMM模型更好的理解,在這里先對馬爾可夫鏈進行介紹,馬爾可夫鏈是一個隨機過程模型,該模型描述了一系列可能的事件,而這一系列中的每一個事件的概率僅僅依賴于前一個事件。如下圖所示:

該圖就是一個簡單的馬爾可夫鏈,圖中的兩個節點就分別表示晴天和下雨兩個事件,圖中節點之間的邊就表示事件之間的轉移概率。即:晴天以后,有0.9的概率還是晴天,0.1的概率會下雨;而雨天以后,有0.4的概率是晴天,0.6的概率還會繼續下雨。因此這個模型對于今天天氣的預測,只與昨天天氣有關,與前天以及更早的天氣無關。因此由馬爾可夫鏈可知,只要知道前一天的天氣,即可以推測今天的天氣的可能性了。
2.HMM——隱馬爾可夫模型
在掌握了概率模型的基礎上,進一步去掌握HMM模型將會加深讀者對HMM這一模型的理解。HMM屬于概率模型的一種,即時序的概率模型。
2.1.序列模型
HMM是一個時序的概率模型,其中的變量分為狀態變量和觀測變量兩組,各自都是一個時間序列,每個狀態或者觀測值都和一個時刻相對應,如下圖所示(其中箭頭表示依賴關系):
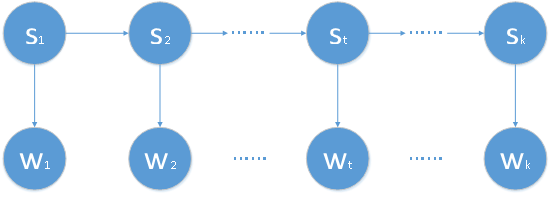
上圖中,狀態變量分別為 , …… ,觀測變量分別為 , …… 。一般情況下,狀態序列都是隱藏的,也就是不能被觀測到的,所以狀態變量是隱變量,即HMM中的Hidden的緣由。其中這個隱藏的、不可觀測的狀態序列就是由一個馬爾可夫鏈隨機生成的,即HMM中的第一個M即馬爾可夫的含義。同時,一般的HMM的狀態變量取值都是離散的,觀測變量的取值可以是離散的,也可以是連續的。為了下文進行方便地闡述,僅討論狀態變量和觀測變量都是離散的情況,并且這也是大多數應用中出現的情況。
2.2.基本假設
HMM模型是建立在兩個基本假設之上的:
1. 假設隱藏的馬爾可夫鏈在任意時刻t的狀態只依賴于前一個時刻(t-1)的狀態,而與其他時刻的狀態和觀測無關,這一假設也叫齊次馬爾可夫假設,公式表示為:
P( …… )= P( ),t=1,2,……k
2. 假設任意時刻的觀測只依賴于該時刻的馬爾可夫鏈狀態,而與其他觀測和狀態無關,這一假設也叫觀測獨立性假設,公式表示為:
P( …… …… )= P( )
2.3.HMM確定條件
確定一個HMM模型的條件為兩個空間和三組參數,兩個空間也就是上文提到的觀測值和狀態值空間,即觀測空間W和狀態空間S。確定這兩個空間后,還需要三組參數,也就是三個概率矩陣。分別為:
- 初始狀態概率:模型在初始時刻各個狀態出現的概率,該概率矩陣即表示每個狀態初始的概率值,通常定義為=(,……),其中就表示模型初始狀態為的概率;
- 狀態轉移概率:即模型在不同狀態之間切換的概率,通常將該概率矩陣定義為A=,矩陣中的就表示在任意時刻下,狀態到下個時刻狀態的概率;
- 輸出觀測概率:模型根據當前的狀態來獲得不同觀測值的概率,通常將該概率矩陣定義為:B=,矩陣中的 就表示在任意時刻下,狀態為時,觀測值被獲取的概率。(這個概率矩陣針對于有時候已知,而未知的情況)。
有了上述的狀態空間S、觀測空間O以及三組參數 =[A,B, ]后,一個HMM模型就可以被確定下來了。
2.4.HMM解決問題
確定好HMM模型后,就需要用該模型去解決一系列問題,其中主要包括概率計算問題、預測問題以及學習問題。
- 概率計算問題,即評價問題,對給定模型設置參數 后,給定觀測序列,來求其與模型之間的匹配度。
- 預測問題,即解碼問題,對給定模型設置參數 后,給定觀測序列,求最有可能(概率值最大)與其對應的裝填序列。
- 學習問題,即訓練問題,給定觀測序列及狀態序列,來估計模型的參數,使得在該模型參數下,觀測序列概率最大。即訓練模型,來更好地用模型表示觀測數據。
以上三個問題中,前兩個問題都是已知模型參數(模型已經確定),如何使用該模型的問題,而第三個問題則是如何通過訓練來得到模型參數(確定模型)的問題。
3.模型學習算法
HMM模型的學習算法可根據訓練數據的不同,分為有監督學習和無監督學習兩種。這兩種學習方法在今后深度學習技術模型中也是應用最為廣泛的。即對于模型來說,若訓練數據既包括觀測值(觀測序列),又包括狀態值(狀態序列),并且兩者之間的對應關系已經標注了(即訓練之前確定了對應關系),那么采用的學習算法就是有監督學習。否則,對于只有觀測序列而沒有明確對應的狀態序列,則使用的就是無監督學習算法進行訓練。
3.1.有監督學習
在模型訓練過程中,訓練數據是由觀測序列和對應的狀態序列的樣本對組成,即訓練數據不僅包含觀測序列,同時包含每個觀測值對應的狀態值,這些在訓練前都是已知的。這樣就可以頻數來估計概率。首先通過統計訓練數據中的狀態值和觀測值,分別得到狀態空間( , …… ),觀測變量分別為( , …… )。然后當樣本在時刻t時處于狀態 ,等到了t+1時刻,狀態屬于 的頻數為 ,則可以用該頻數來表達估計狀態轉移概率 為:
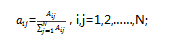
當樣本狀態為 ,觀測為 的頻數為 ,則可以用該頻數來表示觀測概率 為:
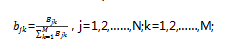
而初始狀態概率 即為訓練數據中所有初始狀態為 的樣本的頻率。所以,有監督學習通過對訓練數據進行統計估計就可以得到模型的相應參數 =[A,B, ]。
3.2.無監督學習
無監督學習即訓練數據僅僅只有觀測值(觀測序列),而沒有與其對應的狀態序列,因此狀態序列S實際上是處于隱藏狀態,也就無法通過頻數來直接估計概率了。對于這一算法有專門的類似前向-后向算法的Baum-Welch算法來學習。該算法與聚類算法中用到的EM算法類似,即運用迭代思想解決數據缺失情況下的參數估計問題,其基本過程是根據已經給出的觀測數據,估計出模型參數的值;然后再依據上一步估計出的參數值來估計缺失數據的值,再根據估計出的缺失數據加上之前己經觀測到的數據重新再對參數值進行估計,然后反復迭代,直至最后收斂,迭代結束。
4.總結
在深度學習模型運用在自然語言處理之前,對于自然語言領域的序列數據進行處理是采用概率統計模型,具體的概率統計模型有HMM和CRF兩種,其中最為核心的是HMM模型,CRF也是是類似HMM的一個模型。
該篇文章主要針對HMM模型進行闡述,有助于讀者更為全面地掌握HMM模型,由于篇幅緣故,CRF模型將在后續進行闡述。該模型也是在HMM基礎上進行延申的,適用性低于HMM模型。因此,對于HMM模型的掌握至關重要,同時目前針對于自然語言處理領域深度學習技術的瓶頸問題(難以取得較大改善的結果),不妨考慮換個思維,使用下概率統計模型HMM來處理,也許能取得不錯的效果。
作者介紹
稀飯,51CTO社區編輯,曾任職某電商人工智能研發中心大數據技術部門,做推薦算法。目前攻讀智能網絡與大數據方向的研究生,主要擅長領域有推薦算法、NLP、CV,使用代碼語言有Java、Python、Scala。