一步一步學(xué)習(xí)大數(shù)據(jù):Hadoop生態(tài)系統(tǒng)與場(chǎng)景
Hadoop概要
到底是業(yè)務(wù)推動(dòng)了技術(shù)的發(fā)展,還是技術(shù)推動(dòng)了業(yè)務(wù)的發(fā)展,這個(gè)話題放在什么時(shí)候都會(huì)惹來(lái)一些爭(zhēng)議。
隨著互聯(lián)網(wǎng)以及物聯(lián)網(wǎng)的蓬勃發(fā)展,我們進(jìn)入了大數(shù)據(jù)時(shí)代。IDC預(yù)測(cè),到2020年,全球會(huì)有44ZB的數(shù)據(jù)量。傳統(tǒng)存儲(chǔ)和技術(shù)架構(gòu)無(wú)法滿足需求。在2013年出版的《大數(shù)據(jù)時(shí)代》一書(shū)中,定義了大數(shù)據(jù)的5V特點(diǎn):Volume(大量)、Velocity(高速)、Variety(多樣)、Value(低價(jià)值密度)、Veracity(真實(shí)性)。
當(dāng)我們把時(shí)間往回看10年,來(lái)到了2003年,這一年Google發(fā)表《Google File System》,其中提出一個(gè)GFS集群中由多個(gè)節(jié)點(diǎn)組成,其中主要分為兩類(lèi):一個(gè)Master node,很多Chunkservers。之后于2004年Google發(fā)表論文并引入MapReduce。2006年2月,Doug Cutting等人在Nutch項(xiàng)目上應(yīng)用GFS和 MapReduce思想,并演化為Hadoop項(xiàng)目。
Doug Cutting曾經(jīng)說(shuō)過(guò)他非常喜歡自己的程序被千萬(wàn)人使用的感覺(jué),很明顯,他做到了;下圖就是本尊照片,帥氣的一塌糊涂
2008年1月, Hadoop成為Apache的開(kāi)源項(xiàng)目。
Hadoop的出現(xiàn)解決了互聯(lián)網(wǎng)時(shí)代的海量數(shù)據(jù)存儲(chǔ)和處理,其是一種支持分布式計(jì)算和存儲(chǔ)的框架體系。假如把Hadoop集群抽象成一臺(tái)機(jī)器的話,理論上我們的硬件資源(CPU、Memoery等)是可以無(wú)限擴(kuò)展的。
Hadoop通過(guò)其各個(gè)組件來(lái)擴(kuò)展其應(yīng)用場(chǎng)景,例如離線分析、實(shí)時(shí)處理等。
Hadoop相關(guān)組件介紹
本文主要是依據(jù)Hadoop2.7版本,后面沒(méi)有特殊說(shuō)明也是按照此版本
HDFS
HDFS,Hadoop Distributed File System (Hadoop分布式文件系統(tǒng))被設(shè)計(jì)成適合運(yùn)行在通用硬件(commodity hardware)上的分布式文件系統(tǒng)。它和現(xiàn)有的分布式文件系統(tǒng)有很多共同點(diǎn),例如典型的Master/Slave架構(gòu)(這里不準(zhǔn)備展開(kāi)介紹);然而HDFS是一個(gè)高度容錯(cuò)性的系統(tǒng),適合部署在廉價(jià)的機(jī)器上。
關(guān)于HDFS主要想說(shuō)兩點(diǎn)。
- HDFS中的默認(rèn)副本數(shù)是3,這里涉及到一個(gè)問(wèn)題為什么是3而不是2或者4。
- 機(jī)架感知(Rack Awareness)。
只有深刻理解了這兩點(diǎn)才能理解為什么Hadoop有著高度的容錯(cuò)性,高度容錯(cuò)性是Hadoop可以在通用硬件上運(yùn)行的基礎(chǔ)。
Yarn
Yarn,Yet Another Resource Negotiator(又一個(gè)資源協(xié)調(diào)者),是繼Common、HDFS、MapReduce之后Hadoop 的又一個(gè)子項(xiàng)目。Yarn的出現(xiàn)是因?yàn)樵贖adoop1.x中存在如下幾個(gè)問(wèn)題:
- 擴(kuò)展性差。JobTracker兼?zhèn)滟Y源管理和作業(yè)控制兩個(gè)功能。
- 可靠性差。在Master/Slave架構(gòu)中,存在Master單點(diǎn)故障。
- 資源利用率低。Map Slot(1.x中資源分配的單位)和Reduce Slot分開(kāi),兩者之間無(wú)法共享。
- 無(wú)法支持多種計(jì)算框架。MapReduce計(jì)算框架是基于磁盤(pán)的離線計(jì)算 模型,新應(yīng)用要求支持內(nèi)存計(jì)算、流式計(jì)算、迭代式計(jì)算等多種計(jì)算框架。
Yarn通過(guò)拆分原有的JobTracker為:
- 全局的 ResourceManager(RM)。
- 每個(gè)Application有一個(gè)ApplicationMaster(AM)。
由Yarn專(zhuān)門(mén)負(fù)責(zé)資源管理,JobTracker可以專(zhuān)門(mén)負(fù)責(zé)作業(yè)控制,Yarn接替 TaskScheduler的資源管理功能,這種松耦合的架構(gòu)方式 實(shí)現(xiàn)了Hadoop整體框架的靈活性。
Hive
Hive的是基于Hadoop上的數(shù)據(jù)倉(cāng)庫(kù)基礎(chǔ)構(gòu)架,利用簡(jiǎn)單的SQL語(yǔ)句(簡(jiǎn)稱(chēng)HQL)來(lái)查詢、分析存儲(chǔ)在HDFS的數(shù)據(jù)。并且把SQL語(yǔ)句轉(zhuǎn)換成MapReduce程序來(lái)數(shù)據(jù)的處理。
Hive與傳統(tǒng)的關(guān)系數(shù)據(jù)庫(kù)主要區(qū)別在以下幾點(diǎn):
- 存儲(chǔ)的位置 Hive的數(shù)據(jù)存儲(chǔ)在HDFS或者Hbase中,而后者一般存儲(chǔ)在裸設(shè)備或者本地的文件系統(tǒng)中。
- 數(shù)據(jù)庫(kù)更新 Hive是不支持更新的,一般是一次寫(xiě)入多次讀寫(xiě)。
- 執(zhí)行SQL的延遲 Hive的延遲相對(duì)較高,因?yàn)槊看螆?zhí)行HQL需要解析成MapReduce。
- 數(shù)據(jù)的規(guī)模上 Hive一般是TB級(jí)別,而后者相對(duì)較小。
- 可擴(kuò)展性上 Hive支持UDF/UDAF/UDTF,后者相對(duì)來(lái)說(shuō)較差。
HBase
HBase,是Hadoop Database,是一個(gè)高可靠性、高性能、面向列、可伸縮的分布式存儲(chǔ)系統(tǒng)。它底層的文件系統(tǒng)使用HDFS,使用Zookeeper來(lái)管理集群的HMaster和各Region server之間的通信,監(jiān)控各Region server的狀態(tài),存儲(chǔ)各Region的入口地址等。
HBase是Key-Value形式的數(shù)據(jù)庫(kù)(類(lèi)比Java中的Map)。那么既然是數(shù)據(jù)庫(kù)那肯定就有表,HBase中的表大概有以下幾個(gè)特點(diǎn):
- 大:一個(gè)表可以有上億行,上百萬(wàn)列(列多時(shí),插入變慢)。面向列:面向列(族)的存儲(chǔ)和權(quán)限控制,列(族)獨(dú)立檢索。
- 稀疏:對(duì)于為空(null)的列,并不占用存儲(chǔ)空間,因此,表可以設(shè)計(jì)的非常稀疏。
- 每個(gè)cell中的數(shù)據(jù)可以有多個(gè)版本,默認(rèn)情況下版本號(hào)自動(dòng)分配,是單元格插入時(shí)的時(shí)間戳。
- HBase中的數(shù)據(jù)都是字節(jié),沒(méi)有類(lèi)型(因?yàn)橄到y(tǒng)需要適應(yīng)不同種類(lèi)的數(shù)據(jù)格式和數(shù)據(jù)源,不能預(yù)先嚴(yán)格定義模式)。
Spark
Spark是由伯克利大學(xué)開(kāi)發(fā)的分布式計(jì)算引擎,解決了海量數(shù)據(jù)流式分析的問(wèn)題。Spark首先將數(shù)據(jù)導(dǎo)入Spark集群,然后再通過(guò)基于內(nèi)存的管理方式對(duì)數(shù)據(jù)進(jìn)行快速掃描 ,通過(guò)迭代算法實(shí)現(xiàn)全局I/O操作的最小化,達(dá)到提升整體處理性能的目的,這與Hadoop從“計(jì)算”找“數(shù)據(jù)”的實(shí)現(xiàn)思路是類(lèi)似的。
Other Tools
Phoneix
基于Hbase的SQL接口,安裝完P(guān)honeix之后可以適用SQL語(yǔ)句來(lái)操作Hbase數(shù)據(jù)庫(kù)。
Sqoop
Sqoop的主要作用是方便不同的關(guān)系數(shù)據(jù)庫(kù)將數(shù)據(jù)遷移到Hadoop,支持多種數(shù)據(jù)庫(kù)例如Postgres,Mysql等。
Hadoop集群硬件和拓?fù)湟?guī)劃
規(guī)劃這件事情并沒(méi)有最優(yōu)解,只是在預(yù)算、數(shù)據(jù)規(guī)模、應(yīng)用場(chǎng)景下之間的平衡。
硬件配置
Raid
首先Raid是否需要,在回答這個(gè)問(wèn)題之前,我們首先了解什么是Raid0以及Raid1。
Raid0是提高存儲(chǔ)性能的原理是把連續(xù)的數(shù)據(jù)分散到多個(gè)磁盤(pán)上存取,這樣,系統(tǒng)有數(shù)據(jù)請(qǐng)求就可以被多個(gè)磁盤(pán)并行的執(zhí)行,每個(gè)磁盤(pán)執(zhí)行屬于它自己的那部分?jǐn)?shù)據(jù)請(qǐng)求。這種數(shù)據(jù)上的并行操作可以充分利用總線的帶寬,顯著提高磁盤(pán)整體存取性能。(來(lái)源百度百科)
當(dāng)Raid0與Hadoop結(jié)合在一起會(huì)產(chǎn)生什么影響呢?
優(yōu)勢(shì):
- 提高IO。
- 加快讀寫(xiě)。
- 消除單塊磁盤(pán)的讀寫(xiě)過(guò)熱的情況。
然而在Hadoop系統(tǒng)中,當(dāng)Raid0中的一塊磁盤(pán)數(shù)據(jù)出現(xiàn)問(wèn)題(或者讀寫(xiě)變得很慢的時(shí)候)時(shí),你需要重新格式化整個(gè)Raid,并且數(shù)據(jù)需要重新恢復(fù)到DataNode中。整個(gè)周期會(huì)隨著數(shù)據(jù)的增加而逐步增加。
其次Raid0的瓶頸是Raid中最慢的那一塊盤(pán),當(dāng)你需要替換其中最慢的那一塊盤(pán)的時(shí)候就會(huì)重新格式化整個(gè)Raid然后恢復(fù)數(shù)據(jù)。
RAID 1通過(guò)磁盤(pán)數(shù)據(jù)鏡像實(shí)現(xiàn)數(shù)據(jù)冗余,在成對(duì)的獨(dú)立磁盤(pán)上產(chǎn)生互 為備份的數(shù)據(jù)。當(dāng)原始數(shù)據(jù)繁忙時(shí),可直接從鏡像拷貝中讀取數(shù)據(jù),因此RAID 1可以提高讀取性能。RAID 1是磁盤(pán)陣列中單位成本最高的,但提供了很高的數(shù)據(jù)安全性和可用性。當(dāng)一個(gè)磁盤(pán)失效時(shí),系統(tǒng)可以自動(dòng)切換到鏡像磁盤(pán)上讀寫(xiě),而不需要重組失效的數(shù)據(jù)。(來(lái)源百度百科)
所以Raid1的本質(zhì)是提高數(shù)據(jù)的冗余,而Hadoop本身默認(rèn)就是3個(gè)副本,所以當(dāng)存在Raid1時(shí)候,副本數(shù)將會(huì)變成6,將會(huì)提高系統(tǒng)對(duì)于硬件資源的需求。
所以在Hadoop系統(tǒng)中不建議適用Raid的,其實(shí)更加推薦JBOD,當(dāng)一塊磁盤(pán)出現(xiàn)問(wèn)題時(shí),直接unmount然后替換磁盤(pán)(很多時(shí)候直接換機(jī)器的)。
集群規(guī)模及資源
這里主要依據(jù)數(shù)據(jù)總量來(lái)推算集群規(guī)模,不考慮CPU以以及內(nèi)存配置。
一般情況來(lái)說(shuō),我們是根據(jù)磁盤(pán)的的需求來(lái)計(jì)算需要機(jī)器的個(gè)數(shù)。
首先我們需要調(diào)研整個(gè)系統(tǒng)的當(dāng)量以及增量數(shù)據(jù)。
舉個(gè)例子來(lái)說(shuō),假如現(xiàn)在系統(tǒng)中存在8T的數(shù)據(jù),默認(rèn)副本數(shù)為3,那么所需要的存儲(chǔ)=8T*3/80% = 30T左右。
每臺(tái)機(jī)器存儲(chǔ)為6T,則數(shù)據(jù)節(jié)點(diǎn)個(gè)數(shù)為5。
加上Master節(jié)點(diǎn),不考慮HA的情況下,大概是6臺(tái)左右機(jī)器。
軟件配置
根據(jù)業(yè)務(wù)需求是否需要配置HA方案進(jìn)行劃分,由于實(shí)際場(chǎng)景復(fù)雜多變,下面方案僅供參考。
1.非HA方案
一般考慮將所有的管理節(jié)點(diǎn)放在一臺(tái)機(jī)器上,同時(shí)在數(shù)據(jù)節(jié)點(diǎn)上啟動(dòng)若干個(gè)Zookeeper服務(wù)(奇數(shù))。
- 管理節(jié)點(diǎn):NameNode+ResourceManager+HMaster
- 數(shù)據(jù)節(jié)點(diǎn):SecondaryNameNode
- 數(shù)據(jù)節(jié)點(diǎn):DataNode +RegionServer+Zookeeper
2.HA方案
在HA方案中,需要將Primary Node 與Standby Node 放在不同的機(jī)器上,一般在實(shí)際場(chǎng)景中,考慮到節(jié)省機(jī)器,可能會(huì)將不同的組件的Master節(jié)點(diǎn)進(jìn)行交叉互備,如A機(jī)器上有Primary NameNonde 以及 Standby HMaster ,B機(jī)器上有Standby NameNode 以及 Primary Master。
- 管理節(jié) 點(diǎn):NameNode(Primary)+HMaster(Standby)
- 管理節(jié)點(diǎn):NameNode(Standby)+HMaster(Primary)
- 管理節(jié)點(diǎn):ResourceManager
- 數(shù)據(jù)節(jié)點(diǎn):DataNode +RegionServer+Zookeeper
Hadoop的設(shè)計(jì)目標(biāo)和適用場(chǎng)景
其實(shí)在上面的Hadoop概要上我們就可以看到Hadoop當(dāng)初的設(shè)計(jì)目標(biāo)是什么。Hadoop在很多場(chǎng)合下都是大數(shù)據(jù)的代名詞。其主要是用來(lái)處理半結(jié)構(gòu)以及非結(jié)構(gòu)數(shù)據(jù)(例如MapReduce)。
其本質(zhì)也是通過(guò)Mapreduce程序來(lái)將半結(jié)構(gòu)化或者非結(jié)構(gòu)化的數(shù)據(jù)結(jié)構(gòu)化繼而來(lái)進(jìn)行后續(xù)的處理。
其次由于Hadoop是分布式的架構(gòu),其針對(duì)的是大規(guī)模的數(shù)據(jù)處理,所以相對(duì)較少的數(shù)據(jù)量并不能體現(xiàn)Hadoop的優(yōu)勢(shì)。例如處理GB級(jí)別的數(shù)據(jù)量,利用傳統(tǒng)的關(guān)系型數(shù)據(jù)庫(kù)的速度可能相對(duì)較快。
基于上述來(lái)看Hadoop的適用場(chǎng)景如下:
- 離線日志的處理(包括ETL過(guò)程,其實(shí)本質(zhì)就是基于Hadoop的數(shù)據(jù)倉(cāng)庫(kù))。
- 大規(guī)模并行計(jì)算。
Hadoop的架構(gòu)解析
Hadoop由主要由兩部分組成:
- 分布式文件系統(tǒng)(HDFS),主要用于大規(guī)模的數(shù)據(jù)存儲(chǔ)。
- 分布式計(jì)算框架MapReduce,其主要用來(lái)對(duì)HDFS上的數(shù)據(jù)進(jìn)行運(yùn)算處理。
HDFS主要由NameNode(Master)以及DataNode(Slave)組成。前者主要是對(duì)命名空間管理:如對(duì)HDFS中的目錄、文件和塊做類(lèi)似 文件系統(tǒng)的創(chuàng)建、修改、刪除、列表文件和目錄等基本操作。后者存儲(chǔ)實(shí)際的數(shù)據(jù)塊,并與NameNode保持一定的心跳。
MapReduce2.0的計(jì)算框架本質(zhì)是有Yarn來(lái)完成的,Yarn是關(guān)注點(diǎn)分離的思路,由Yarn專(zhuān)門(mén)負(fù)責(zé)資源管理 ,JobTracker可以專(zhuān)門(mén)負(fù)責(zé)作業(yè)控制,Yarn接替 TaskScheduler的資源管理功能,這種松耦合的架構(gòu)方式 實(shí)現(xiàn)了Hadoop整體框架的靈活性。
MapReduce工作原理和案例說(shuō)明
MapReduce可謂Hadoop的精華所在,是用于數(shù)據(jù)處理的編程模型。MapReduce從名稱(chēng)上面可以看到Map以及Reduce兩個(gè)部分。其思想類(lèi)似于先分后合,Map對(duì)與數(shù)據(jù)進(jìn)行抽取轉(zhuǎn)換,Reduce對(duì)數(shù)據(jù)進(jìn)行匯總。其中需要注意的是Map任務(wù)將輸出結(jié)果存儲(chǔ)在本地磁盤(pán),而不是HDFS。
在我們執(zhí)行MapReduce的過(guò)程中,根據(jù)Map與數(shù)據(jù)庫(kù)的關(guān)系大體上可以分為三類(lèi):
- 數(shù)據(jù)本地
- 機(jī)架本地
- 跨機(jī)架
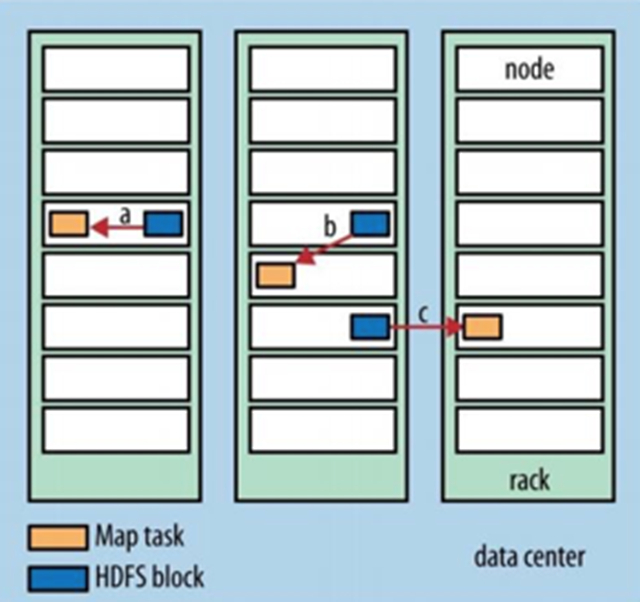
從上述幾種可以看出來(lái),假設(shè)一個(gè)MapReduce過(guò)程中存在大量的數(shù)據(jù)移動(dòng)對(duì)于執(zhí)行效率來(lái)說(shuō)是災(zāi)難性。
MapReduce數(shù)據(jù)流
從數(shù)據(jù)流來(lái)看MapReduce的關(guān)系大體可以分為以下幾類(lèi):
- 單Reduce
- 多Reduce
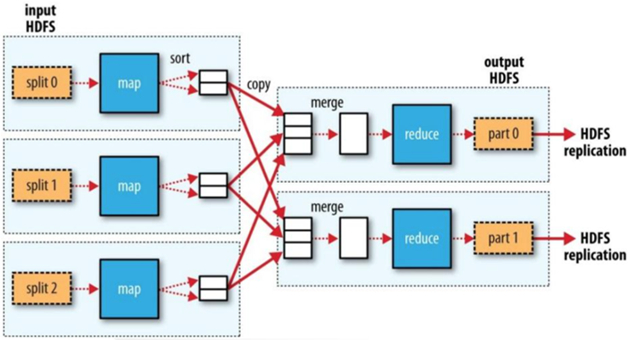
- 無(wú)Reduce
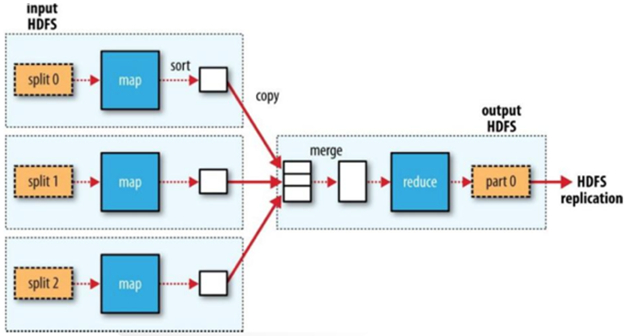
然而無(wú)論什么MapReduce關(guān)系如何,MapReduce的執(zhí)行流程都如下圖所示:
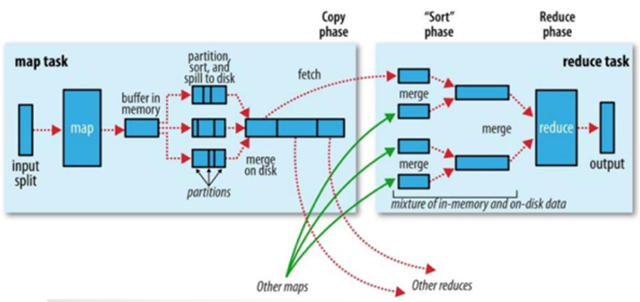
其中在執(zhí)行每個(gè)Map Task時(shí),無(wú)論Map方法中執(zhí)行什么邏輯,最終都是要把輸出寫(xiě)到磁盤(pán)上。如果沒(méi)有Reduce階段,則直接輸出到HDFS上。如果有Reduce作業(yè),則每個(gè)Map方法的輸出在寫(xiě)磁盤(pán)前線在內(nèi)存中緩存。每個(gè)Map Task都有一個(gè)環(huán)狀的內(nèi)存緩沖區(qū),存儲(chǔ)著Map的輸出結(jié)果,默認(rèn)100m,在每次當(dāng)緩沖區(qū)快滿的時(shí)候由一個(gè)獨(dú)立的線程將緩沖區(qū)的數(shù)據(jù)以一個(gè)溢出文件的方式存放到磁盤(pán),當(dāng)整個(gè)Map Task結(jié)束后再對(duì)磁盤(pán)中這個(gè)Map Task產(chǎn)生的所有溢出文件做合并,被合并成已分區(qū)且已排序的輸出文件。然后等待Reduce Task來(lái)拉數(shù)據(jù)。
上述這個(gè)過(guò)程其實(shí)也MapReduce中赫赫有名的Shuffle過(guò)程。
MapReduce實(shí)際案例
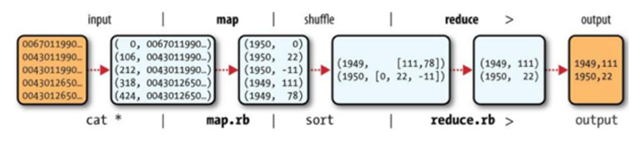
Raw Data原始的數(shù)據(jù)文件是普通的文本文件,每一行記錄中存在一個(gè)年份以及改年份中每一天的溫度。

MapMap過(guò)程中,將每一行記錄都生成一個(gè)key,key一般是改行在文件中的行數(shù)(Offset),例如下圖中的0,106代表第一行、第107行。其中粗體的地方代表年份以及溫度。

Shuffle該過(guò)程中獲取所要的記錄組成鍵值對(duì){年份,溫度}。
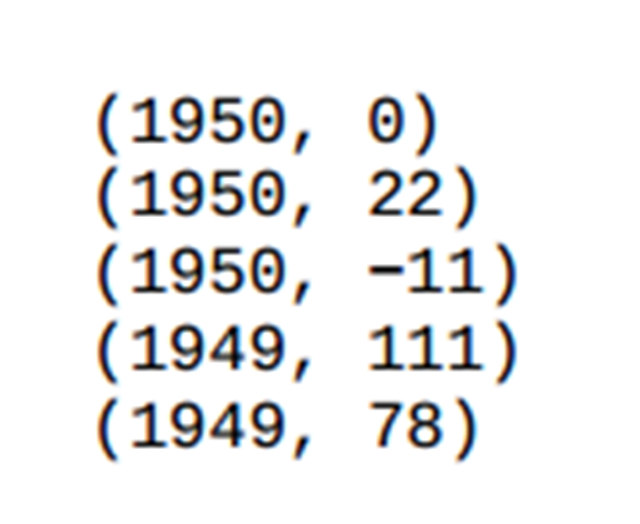
Sort將上一步過(guò)程中的相同key的value組成一個(gè)list,即{年份,List<溫度>},傳到Reduce端。
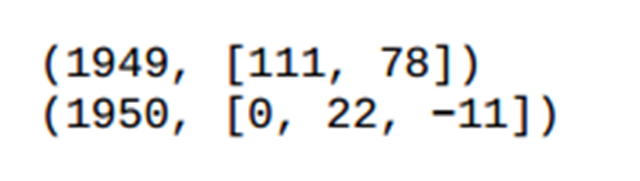
ReduceReduce端對(duì)list進(jìn)行處理,獲取最大值,然后輸出到HDFS中。

上述過(guò)程進(jìn)行總結(jié)下來(lái)流程如下: