利用卷積自編碼器對圖片進行降噪
前言
這周工作太忙,本來想更把 Attention tranlsation 寫出來,但一直抽不出時間,等后面有時間再來寫。我們這周來看一個簡單的自編碼器實戰代碼,關于自編碼器的理論介紹我就不詳細介紹了,網上一搜一大把。最簡單的自編碼器就是通過一個 encoder 和 decoder 來對輸入進行復現,例如我們將一個圖片輸入到一個網絡中,自編碼器的 encoder 對圖片進行壓縮,得到壓縮后的信息,進而 decoder 再將這個信息進行解碼從而復現原圖。

自編碼器實際上是通過去最小化 target 和 input 的差別來進行優化,即讓輸出層盡可能地去復現原來的信息。由于自編碼器的基礎形式比較簡單,對于它的一些變體也非常之多,包括 DAE,SDAE,VAE 等等,如果感興趣的小伙伴可以去網上搜一下其他相關信息。
本篇文章將實現兩個 Demo,***部分即實現一個簡單的 input-hidden-output 結的自編碼器,第二部分將在***部分的基礎上實現卷積自編碼器來對圖片進行降噪。
工具說明
-
TensorFlow1.0
-
jupyter notebook
-
數據:MNIST 手寫數據集
-
完整代碼地址:NELSONZHAO/zhihu
***部分
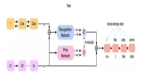
首先我們將實現一個如上圖結構的最簡單的 AutoEncoder。
加載數據
在這里,我們使用 MNIST 手寫數據集來進行實驗。首先我們需要導入數據,TensorFlow 已經封裝了這個實驗數據集,所以我們使用起來也非常簡單。
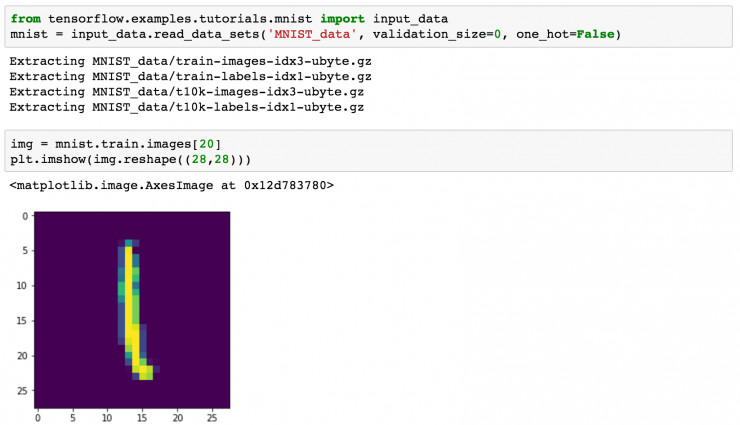
如果想讓數據顯示灰度圖像,使用代碼 plt.imshow(img.reshape((28,28)), cmap='Greys_r') 即可。
通過 input_data 就可以加載我們的數據集。如果小伙伴本地已經有了 MNIST 數據集(四個壓縮包),可以把這四個壓縮包放在目錄 MNIST_data 下,這樣 TensorFlow 就會直接 Extract 數據,而不用再重新下載。我們可以通過 imshow 來隨便查看一個圖像。由于我們加載進來的數據已經被處理成一個 784 維度的向量,因此重新顯示的時候需要 reshape 一下。
構建模型
我們把數據加載進來以后就可以進行最簡單的建模。在這之前,我們首先來獲取一下 input 數據的大小,我們加載進來的圖片是 28x28 的像素塊,TensorFlow 已經幫我們處理成了 784 維度的向量。同時我們還需要指定一下 hidden layer 的大小。

在這里我指定了 64,hidden_units 越小,意味著信息損失的越多,小伙伴們也可以嘗試一下其他的大小來看看結果。
AutoEncoder 中包含了 input,hidden 和 output 三層。

在隱層,我們采用了 ReLU 作為激活函數。
至此,一個簡單的 AutoEncoder 就構造完成,接下來我們可以啟動 TensorFlow 的 graph 來進行訓練。
訓練結果可視化
經過上面的步驟,我們構造了一個簡單的 AutoEncoder,下面我們將對結果進行可視化看一下它的表現。

這里,我挑選了測試數據集中的 5 個樣本來進行可視化,同樣的,如果想觀察灰度圖像,指定 cmap 參數為'Greys_r'即可。上面一行為 test 數據集中原始圖片,第二行是經過 AutoEncoder 復現以后的圖片,可以很明顯的看到像素信息的損失。
同樣,我們也可以把隱層壓縮的數據拿出來可視化,結果如下:

這五張圖分別對應了 test 中五張圖片的隱層壓縮后的圖像。
通過上面一個簡單的例子,我們了解了 AutoEncoder 的基本工作原理,下面我們將更進一步改進我們的模型,將隱層轉換為卷積層來進行圖像降噪。
上面過程中省略了一部分代碼,完整代碼請去我的 GitHub 上查看。
第二部分
在了解了上面 AutoEncoder 工作原理的基礎上,我們在這一部分將對 AutoEncoder 加入多個卷積層來進行圖片的降噪處理。
同樣的我們還是使用 MNIST 數據集來進行實驗,關于數據導入的步驟不再贅述,請下載代碼查看。在開始之前,我們先通過一張圖片來看一下我們的整個模型結構:

我們通過向模型輸入一個帶有噪聲的圖片,在輸出端給模型沒有噪聲的圖片,讓模型通過卷積自編碼器去學習降噪的過程。
輸入層

這里的輸入層和我們上一部分的輸入層已經不同,因為這里我們要使用卷積操作,因此,輸入層應該是一個 height x width x depth 的一個圖像,一般的圖像 depth 是 RGB 格式三層,這里我們的 MNIST 數據集的 depth 只有 1。
Encoder 卷積層
Encoder 卷積層設置了三層卷積加池化層,對圖像進行處理。

***層卷積中,我們使用了 64 個大小為 3 x 3 的濾波器(filter),strides 默認為 1,padding 設置為 same 后我們的 height 和 width 不會被改變,因此經過***層卷積以后,我們得到的數據從最初的 28 x 28 x 1 變為 28 x 28 x 64。
緊接著對卷積結果進行***池化操作(max pooling),這里我設置了 size 和 stride 都是 2 x 2,池化操作不改變卷積結果的深度,因此池化以后的大小為 14 x 14 x 64。
對于其他卷積層不再贅述。所有卷積層的激活函數都是用了 ReLU。
經過三層的卷積和池化操作以后,我們得到的 conv3 實際上就相當于上一部分中 AutoEncoder 的隱層,這一層的數據已經被壓縮為 4 x 4 x 32 的大小。
至此,我們就完成了 Encoder 端的卷積操作,數據維度從開始的 28 x 28 x 1 變成了 4 x 4 x 32。
Decoder 卷積層
接下來我們就要開始進行 Decoder 端的卷積。在這之前,可能有小伙伴要問了,既然 Encoder 中都已經把圖片卷成了 4 x 4 x 32,我們如果繼續在 Decoder 進行卷積的話,那豈不是得到的數據 size 越來越小?所以,在 Decoder 端,我們并不是單純進行卷積操作,而是使用了 Upsample(中文翻譯可以為上采樣)+ 卷積的組合。
我們知道卷積操作是通過一個濾波器對圖片中的每個 patch 進行掃描,進而對 patch 中的像素塊加權求和后再進行非線性處理。舉個例子,原圖中我們的 patch 的大小假如是 3 x 3(說的通俗點就是一張圖片中我們取其中一個 3 x 3 大小的像素塊出來),接著我們使用 3 x 3 的濾波器對這個 patch 進行處理,那么這個 patch 經過卷積以后就變成了 1 個像素塊。在 Deconvolution 中(或者叫 transposed convolution)這一過程是反過來的,1 個像素塊會被擴展成 3 x 3 的像素塊。
但是 Deconvolution 有一些弊端,它會導致圖片中出現 checkerboard patterns,這是因為在 Deconvolution 的過程中,濾波器中會出現很多重疊。為了解決這個問題,有人提出了使用 Upsample 加卷積層來進行解決。
關于 Upsample 有兩種常見的方式,一種是 nearest neighbor interpolation,另一種是 bilinear interpolation。
本文也會使用 Upsample 加卷積的方式來進行 Decoder 端的處理。

在 TensorFlow 中也封裝了對 Upsample 的操作,我們使用 resize_nearest_neighbor 對 Encoder 卷積的結果 resize,進而再進行卷積處理。經過三次 Upsample 的操作,我們得到了 28 x 28 x 64 的數據大小。***,我們要將這個結果再進行一次卷積,處理成我們原始圖像的大小。

***一步定義 loss 和 optimizer。

loss 函數我們使用了交叉熵進行計算,優化函數學習率為 0.001。
構造噪聲數據
通過上面的步驟我們就構造完了整個卷積自編碼器模型。由于我們想通過這個模型對圖片進行降噪,因此在訓練之前我們還需要在原始數據的基礎上構造一下我們的噪聲數據。

我們通過上面一個簡單的例子來看一下如何加入噪聲,我們獲取一張圖片的數據 img(大小為 784),在它的基礎上加入噪聲因子乘以隨機數的結果,就會改變圖片上的像素。接著,由于 MNIST 數據的每個像素數據都被處理成了 0-1 之間的數,所以我們通過 numpy.clip 對加入噪聲的圖片進行 clip 操作,保證每個像素數據還是在 0-1 之間。
np.random.randn(*img.shape) 的操作等于 np.random.randn(img.shape[0], img.shape[1])
我們下來來看一下加入噪聲前后的圖像對比。
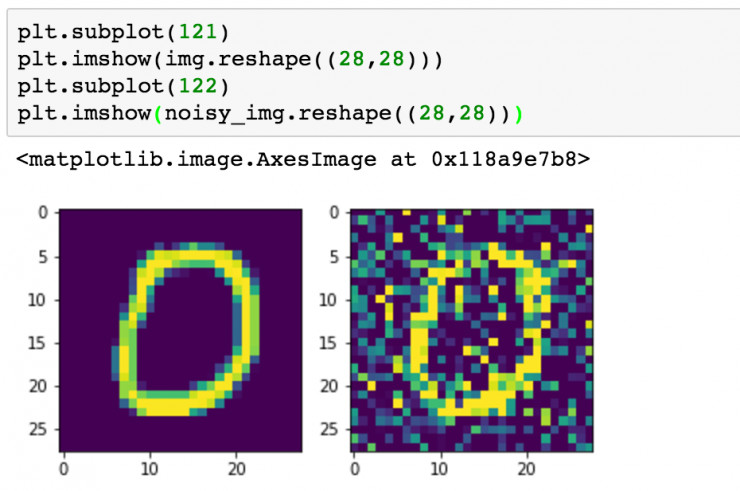
訓練模型
介紹完模型構建和噪聲處理,我們接下來就可以訓練我們的模型了。
在訓練模型時,我們的輸入已經變成了加入噪聲后的數據,而輸出是我們的原始沒有噪聲的數據,主要要對原始數據進行 reshape 操作,變成與 inputs_相同的格式。由于卷積操作的深度,所以模型訓練時候有些慢,建議使用 GPU 跑。
記得***關閉 sess。
結果可視化
經過上面漫長的訓練,我們的模型終于訓練好了,接下來我們就通過可視化來看一看模型的效果如何。
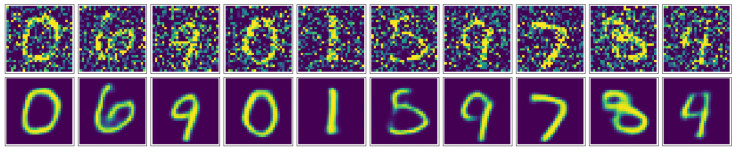
可以看到通過卷積自編碼器,我們的降噪效果還是非常好的,最終生成的圖片看起來非常順滑,噪聲也幾乎看不到了。
有些小伙伴可能就會想,我們也可以用基礎版的 input-hidden-output 結構的 AutoEncoder 來實現降噪。因此我也實現了一版用最簡單的 input-hidden-output 結構進行降噪訓練的模型(代碼在我的 GitHub)。我們來看看它的結果:
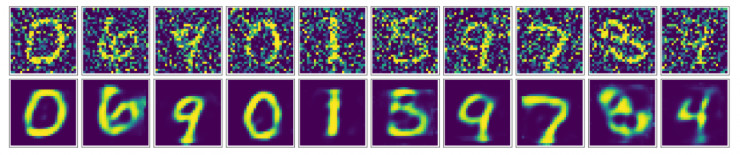
可以看出,跟卷積自編碼器相比,它的降噪效果更差一些,在重塑的圖像中還可以看到一些噪聲的影子。
結尾
至此,我們完成了基礎版本的 AutoEncoder 模型,還在此基礎上加入卷積層來進行圖片降噪。相信小伙伴對 AntoEncoder 也有了一個初步的認識。
完整的代碼已經放在我的 GitHub(NELSONZHAO/zhihu) 上,其中包含了六個文件:
-
BasicAE,基礎版本的 AutoEncoder(包含 jupyter notebook 和 html 兩個文件)
-
EasyDAE,基礎版本的降噪 AutoEncoder(包含 jupyter notebook 和 html 兩個文件)
-
ConvDAE,卷積降噪 AutoEncoder(包含 jupyter notebook 和 html 兩個文件)
如果覺得不錯,可以給我的 GitHub 點個 star 就更好啦!