帶掩碼的自編碼器MAE在各領域中的應用總結
機器學習算法應該理解數據從中提取有用的特征才能夠解決復雜的任務。通常訓練泛化模型需要大量帶注釋的數據。這個是非常費時費力的,并且一般情況下都很難進行。
所以各種基于帶掩碼的自編碼器技術就出現了,這種技術允許在未標記的數據上訓練模型,并且獲得的特征能夠適應常見下游任務
- BERT — 最早的遮蔽模型,用于文本任務 1810.04805
- MAE — 圖像,可以說它將BERT的輝煌延伸到了視覺 2111.06377
- M3MAE — 圖像+文字 2205.14204
- MAE that listen — 音頻 2207.06405
- VideoMAE — 視頻 2203.12602
- TSFormer — 時間序列 2107.10977
- GraphMAE — 圖 2205.10803
從上面我們可以看到 Masked Autoencoder幾乎覆蓋了大部分的主要研究領域是一種強大而簡單的技術,它使用基于transformer的模型進行預訓練得到高水平的數據表示,這對在任何下游任務(遷移學習,微調)上采用該模型都很有幫助。
自監督學習是一種不需要任何標簽就能獲得數據信息表示的方法。標準的自監督學習技術通常使用高級數據增強策略。但是對于文本、音頻、大腦信號等形式來說,如何選擇增強策略并且保證策略的合理性是一個非常棘手的問題
而Masked Autoencoder不使用這種策略。我們只需要有數據,并且是大量的數據還有必要的計算資源即可。它使用重建的方式根據被部分遮蔽的樣本來預測完整的數據。如果遮蔽了大約70%的數據,模型還能夠恢復數據的話,則說明模型學習到了數據的良好的高級表示
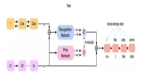
MAE是如何工作的?
MAE 的工作原理非常簡單。看看下面的圖片:

訓練前需要屏蔽一半以上的Patch(比如75%)。編碼器接收可見的Patch塊。在編碼器之后,引入掩碼標記,用一個小(相對于編碼器小)解碼器對全部編碼的Patch和掩碼標記進行解碼,重建原始圖像。下游的任務中,編碼器的輸出作為特征,下游任務不需要進行遮蔽。
一般流程如下:
- 獲取數據樣本(圖像)。
- 對樣本進行區域劃分(patches for image, word for text等)
- 應用高比率的隨機遮蔽(論文中使用75%)
- 只保留可見的部分,并將它們輸入編碼器。
- 使用上面的掩碼進行填充,將編碼器的輸出和遮蔽進行合并并且保留原始順序,作為解碼器的輸入。
- 解碼器來負責重建遮蔽。
就是這么一個簡單的流程就能夠從數據中提取有意義的特征??
對于下游的任務,只使用預訓練的編碼器,因為它學習數據的有用表示。
這里需要說明的是,因為由transformer 不依賴于數據的長度,所以在下游使用時可以將完整的樣本輸入到模型中,也就是說下游的任務不需要進行掩碼遮蔽了。
MAE為什么可以在不同的領域中使用?
MAEs可以很容易地適應不同的數據模式。下面圖是在視頻和音頻領域中使用MAE的流程。如果你是這個方向的從業者,試試它吧。
音頻的頻譜圖的MAE

下面的說明來自論文
我們探索了將MAE簡單擴展到音頻數據的方法。我們的audio - mae學習從音頻錄音中重建隱藏的聲譜圖Patch,并在6個音頻和語音分類任務中實現了最先進的性能。得出了一些有趣的觀察結果:1、一個簡單的MAE方法對音頻譜圖的效果出奇的好。2、在解碼器中學習具有局部自我注意的更強的表示是可能的。3、掩蔽可以應用于訓練前和微調,提高精度和減少訓練計算
視頻的MAE

為了進行視頻自監督學習,VideoMAE使用了一個遮蔽的自編碼器和一個普通的ViT主干。與對比學習方法相比,VideoMAE有更短的訓練時間(3.2倍加速)。在未來關于自監督視頻訓練的研究中,VideoMAE可能是一個很好的起點。
結果展示
最值得關注的結果是所有這些MAE技術都在他們相應的領域擊敗了SOTA。



訓練的細節
這些論文中也都包含了訓練的細節的信息,這對于我們進行詳細研究非常有幫助。例如損失函數(MSE)僅在不可見的令牌上計算,剩下的就是一些訓練的參數:
這是MAE的

這是視頻的

優點和缺點
優點
可以看到,MAE這種方式幾乎適用于任何形式的任務
缺點
這種方法的骨干都是transformer,(目前)沒有其他的骨干,并且它需要大量的數據和計算資源。
總結
這是一個非常強大的技術,可以用于任何領域,并且還能夠起到很好的效果。
TSFormer 雖然使用了這個方法但是也沒有公開代碼,并且效果也不太好,但是我們是否可以利用MAE,將多元時間序列表示為音頻,并提供相同的預訓練呢?這可能對用少量標記數據解決下游任務有很大幫助。
是否可以增加額外的損失函數和限制。這樣就可以對訓練模型進行重構,甚至做一些聚類的工作。
除此以外還有更多的論文我們可以參考:
- MultiMAE(2204.01678):多模態多任務MAE。
- 結合對比學習(augs)與MAE:Contrastive Masked Autoencoders are Stronger Vision Learners 2207.13532
其實MAE的出現不僅僅是將BERT在NLP中的成就擴展到了CV:
- iGPT是最早提出(目前我所知道的,歡迎指正)把圖像馬賽克掉,變成一個個色塊,數量一下就減少了,可以像NLP一樣愉快地輸入到Transformer了,但是會存在訓練預測不一致的問題。
- ViT的預訓練方法,mask掉50%的patch,預測patch的mean color
- BEiT用了一個dVAE對patch進行離散化,mask 40%的patch
但他們其實都沒有理解一個問題,就是到底是什么原因導致視覺和語言用的masked autoencoder不一樣。而MAE的成功就在于這個問題想清楚,并且給出了解決方案。
所以我個人認為MAE是一個很好的開端,并且它已經證明了領域內的知識+簡單的方法能夠創造出很好的模型。