Keras+OpenAI強化學習實踐:深度Q網(wǎng)絡
在之前的 Keras/OpenAI 教程中,我們討論了一個將深度學習應用于強化學習環(huán)境的基礎案例,它的效果非常顯著。想象作為訓練數(shù)據(jù)的完全隨機序列(series)。任何兩個序列都不可能高度彼此重復,因為這些都是隨機產(chǎn)生的。然而,成功的試驗之間存在相同的關鍵特征,例如在 CartPole 游戲中,當桿往右靠時需要將車向右推,反之亦然。因此,通過在所有這些試驗數(shù)據(jù)上訓練我們的神經(jīng)網(wǎng)絡,我們提取了有助于成功的共同模式(pattern),并能夠平滑導致其產(chǎn)生獨立故障的細節(jié)。
話雖如此,我們認為這次的環(huán)境比上次要困難得多,即游戲:MountainCar。
一、更復雜的環(huán)境
即使看上去我們應該能夠應用與上周相同的技術,但是有一個關鍵特征使它變得不可能:我們無法生成訓練數(shù)據(jù)。與簡單的 CartPole 例子不同,采取隨機移動通常只會導致實驗的結果很差(谷底)。也就是說,我們的實驗結果***都是相同的-200。這用作訓練數(shù)據(jù)幾乎沒有用。想象一下,如果你無論在考試中做出什么答案,你都會得到 0%,那么你將如何從這些經(jīng)驗中學習?
境的隨機輸入不會產(chǎn)生任何對于訓練有用的輸出")
「MountainCar-v0」環(huán)境的隨機輸入不會產(chǎn)生任何對于訓練有用的輸出。
由于這些問題,我們必須找出一種能逐步改進以前實驗的方法。為此,我們使用強化學習最基本的方法:Q-learning!
二、DQN 的理論背景
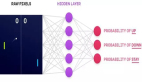
Q-learning 的本質是創(chuàng)建一個「虛擬表格」,這個表格包含了當前環(huán)境狀態(tài)下每個可能的動作能得到多少獎勵。下面來詳細說明:

網(wǎng)絡可以想象為內生有電子表格的網(wǎng)絡,該表格含有當前環(huán)境狀態(tài)下可能采取的每個可能的動作的值。
「虛擬表格」是什么意思?想像一下,對于輸入空間的每個可能的動作,你都可以為每個可能采取的動作賦予一個分數(shù)。如果這可行,那么你可以很容易地「打敗」環(huán)境:只需選擇具有***分數(shù)的動作!但是需要注意 2 點:首先,這個分數(shù)通常被稱為「Q-分數(shù)」,此算法也由此命名。第二,與任何其它得分一樣,這些 Q-分數(shù)在其模擬的情境外沒有任何意義。也就是說,它們沒有確定的意義,但這沒關系,因為我們只需要做比較。
為什么對于每個輸入我們都需要一個虛擬表格?難道沒有統(tǒng)一的表格嗎?原因是這樣做不和邏輯:這與在谷底談采取什么動作是***的,及在向左傾斜時的***點討論采取什么動作是***的是一樣的道理。
現(xiàn)在,我們的主要問題(為每個輸入建立虛擬表格)是不可能的:我們有一個連續(xù)的(***)輸入空間!我們可以通過離散化輸入空間來解決這個問題,但是對于本問題來說,這似乎是一個非常棘手的解決方案,并且在將來我們會一再遇到。那么,我們如何解決呢?那就是通過將神經(jīng)網(wǎng)絡應用于這種情況:這就是 DQN 中 D 的來歷!
三、DQN agent
現(xiàn)在,我們現(xiàn)在已經(jīng)將問題聚焦到:找到一種在給定當前狀態(tài)下為不同動作賦值 Q-分數(shù)的方法。這是使用任何神經(jīng)網(wǎng)絡時遇到的非常自然的***個問題的答案:我們模型的輸入和輸出是什么?本模型中你需要了解的數(shù)學方程是以下等式(不用擔心,我們會在下面講解):
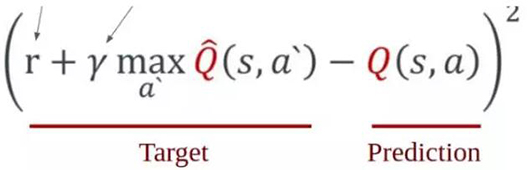
如上所述,Q 代表了給定當前狀態(tài)(s)和采取的動作(a)時我們模型估計的價值。然而,目標是確定一個狀態(tài)價值的總和。那是什么意思?即從該位置獲得的即時獎勵和將來會獲得的預期獎勵之和。也就是說,我們要考慮一個事實,即一個狀態(tài)的價值往往不僅反映了它的直接收益,而且還反映了它的未來收益。在任何情況下,我們會將未來的獎勵折現(xiàn),因為對于同樣是收到$100 的兩種情況(一種為將來,一種為現(xiàn)在),我會永遠選擇現(xiàn)在的交易,因為未來是會變化的。γ因子反映了此狀態(tài)預期未來收益的貶值。
這就是我們需要的所有數(shù)學!下面是實際代碼的演示!
四、DQN agent 實現(xiàn)
深度 Q 網(wǎng)絡為持續(xù)學習(continuous learning),這意味著不是簡單地累積一批實驗/訓練數(shù)據(jù)并將其傳入模型。相反,我們通過之前運行的實驗創(chuàng)建訓練數(shù)據(jù),并且直接將運行后創(chuàng)建的數(shù)據(jù)饋送如模型。如果現(xiàn)在感到好像有些模糊,別擔心,該看看代碼了。代碼主要在定義一個 DQN 類,其中將實現(xiàn)所有的算法邏輯,并且我們將定義一組簡單的函數(shù)來進行實際的訓練。
1. DQN 超參數(shù)
首先,我們將討論一些與 DQN 相關的參數(shù)。它們大多數(shù)是實現(xiàn)主流神經(jīng)網(wǎng)絡的標準參數(shù):
- class DQN:
- def __init__(self, env):
- self.env = env
- self.memory = deque(maxlen=2000)
- self.gamma = 0.95
- self.epsilon = 1.0
- self.epsilon_min = 0.01
- self.epsilon_decay = 0.995
- self.learning_rate = 0.01
讓我們來一步一步地講解這些超參數(shù)。***個是環(huán)境(env),這僅僅是為了在建立模型時便于引用矩陣的形狀。「記憶(memory)」是 DQN 的關鍵組成部分:如前所述,我們不斷通過實驗訓練模型。然而與直接訓練實驗的數(shù)據(jù)不同,我們將它們先添加到內存中并隨機抽樣。為什么這樣做呢,難道僅僅將*** x 個實驗數(shù)據(jù)作為樣本進行訓練不好嗎?原因有點微妙。設想我們只使用最近的實驗數(shù)據(jù)進行訓練:在這種情況下,我們的結果只會學習其最近的動作,這可能與未來的預測沒有直接的關系。特別地,在本環(huán)境下,如果我們在斜坡右側向下移動,使用最近的實驗數(shù)據(jù)進行訓練將需要在斜坡右側向上移動的數(shù)據(jù)上進行訓練。但是,這與在斜坡左側的情景需決定采取的動作無關。所以,通過抽取隨機樣本,將保證不會偏離訓練集,而是理想地學習我們將遇到的所有環(huán)境。
我們現(xiàn)在來討論模型的超參數(shù):gamma、epsilon 以及 epsilon 衰減和學習速率。***個是前面方程中討論的未來獎勵的折現(xiàn)因子(<1),***一個是標準學習速率參數(shù),我們不在這里討論。第二個是 RL 的一個有趣方面,值得一談。在任何一種學習經(jīng)驗中,我們總是在探索與利用之間做出選擇。這不僅限于計算機科學或學術界:我們每天都在做這件事!
考慮你家附近的飯店。你***一次嘗試新飯店是什么時候?可能很久以前。這對應于你從探索到利用的轉變:與嘗試找到新的更好的機會不同,你根據(jù)自己以往的經(jīng)驗找到***的解決方案,從而***化效用。對比當你剛搬家時:當時你不知道什么飯店是好的,所以被誘惑去探索新選擇。換句話說,這時存在明確的學習趨勢:當你不了解它們時,探索所有的選擇,一旦你對其中的一些建立了意見,就逐漸轉向利用。以同樣的方式,我們希望我們的模型能夠捕捉這種自然的學習模型,而 epsilon 扮演著這個角色。
Epsilon 表示我們將致力于探索的時間的一小部分。也就是說,實驗的分數(shù) self.epsilon,我們將僅僅采取隨機動作,而不是我們預測在這種情況下***的動作。如上所述,我們希望在開始時形成穩(wěn)定評估之前更經(jīng)常地采取隨機動作:因此開始時初始化ε接近 1.0,并在每一個連續(xù)的時間步長中以小于 1 的速率衰減它。
2. DQN 模型
在上面的 DQN 的初始化中排除了一個關鍵環(huán)節(jié):用于預測的實際模型!在原來的 Keras RL 教程中,我們直接給出數(shù)字向量形式的輸入和輸出。因此,除了全連接層之外,不需要在網(wǎng)絡中使用更復雜的層。具體來說,我們將模型定義為:
- def create_model(self):
- model = Sequential()
- state_shape = self.env.observation_space.shape
- model.add(Dense(24, input_dim=state_shape[0],
- activation="relu"))
- model.add(Dense(48, activation="relu"))
- model.add(Dense(24, activation="relu"))
- model.add(Dense(self.env.action_space.n))
- model.compile(loss="mean_squared_error",
- optimizer=Adam(lr=self.learning_rate))
- return model
并用它來定義模型和目標模型(如下所述):
- def __init__(self, env):
- self.env = env
- self.memory = deque(maxlen=2000)
- self.gamma = 0.95
- self.epsilon = 1.0
- self.epsilon_min = 0.01
- self.epsilon_decay = 0.995
- self.learning_rate = 0.01
- self.tau = .05
- selfself.model = self.create_model()
- # "hack" implemented by DeepMind to improve convergence
- selfself.target_model = self.create_model()
事實上,有兩個單獨的模型,一個用于做預測,一個用于跟蹤「目標值」,這是反直覺的。明確地說,模型(self.model)的作用是對要采取的動作進行實際預測,目標模型(self.target_model)的作用是跟蹤我們想要模型采取的動作。
為什么不用一個模型做這兩件事呢?畢竟,如果預測要采取的動作,那不會間接地確定我們想要模型采取的模式嗎?這實際上是 DeepMind 發(fā)明的深度學習的「不可思議的技巧」之一,它用于在 DQN 算法中獲得收斂。如果使用單個模型,它可以(通常會)在簡單的環(huán)境(如 CartPole)中收斂。但是,在這些更為復雜的環(huán)境中并不收斂的原因在于我們如何對模型進行訓練:如前所述,我們正在對模型進行「即時」訓練。
因此,在每個時間步長進行訓練模型,如果我們使用單個網(wǎng)絡,實際上也將在每個時間步長時改變「目標」。想想這將多么混亂!那就如同,開始老師告訴你要完成教科書中的第 6 頁,當你完成了一半時,她把它改成了第 9 頁,當你完成一半的時候,她告訴你做第 21 頁!因此,由于缺乏明確方向以利用優(yōu)化器,即梯度變化太快難以穩(wěn)定收斂,將導致收斂不足。所以,作為代償,我們有一個變化更慢的網(wǎng)絡以跟蹤我們的最終目標,和一個最終實現(xiàn)這些目標的網(wǎng)絡。
3. DQN 訓練
訓練涉及三個主要步驟:記憶、學習和重新定位目標。***步基本上只是隨著實驗的進行向記憶添加數(shù)據(jù):
- def remember(self, state, action, reward, new_state, done):
- self.memory.append([state, action, reward, new_state, done])
這里沒有太多的注意事項,除了我們必須存儲「done」階段,以了解我們以后如何更新獎勵函數(shù)。轉到 DQN 主體的訓練函數(shù)。這是使用存儲記憶的地方,并積極從我們過去看到的內容中學習。首先,從整個存儲記憶中抽出一個樣本。我們認為每個樣本是不同的。正如我們在前面的等式中看到的,我們要將 Q-函數(shù)更新為當前獎勵之和與預期未來獎勵的總和(貶值為 gamma)。在實驗結束時,將不再有未來的獎勵,所以該狀態(tài)的價值為此時我們收到的獎勵之和。然而,在非終止狀態(tài),如果我們能夠采取任何可能的動作,將會得到的***的獎勵是什么?我們得到:
- def replay(self):
- batch_size = 32
- if len(self.memory) < batch_size:
- return
- samples = random.sample(self.memory, batch_size)
- for sample in samples:
- state, action, reward, new_state, done = sample
- target = self.target_model.predict(state)
- if done:
- target[0][action] = reward
- else:
- Q_future = max(
- self.target_model.predict(new_state)[0])
- target[0][action] = reward + Q_future * self.gamma
- self.model.fit(state, target, epochs=1, verbose=0)
***,我們必須重新定位目標,我們只需將主模型的權重復制到目標模型中。然而,與主模型訓練的方法不同,目標模型更新較慢:
- def target_train(self):
- weights = self.model.get_weights()
- target_weights = self.target_model.get_weights()
- for i in range(len(target_weights)):
- target_weights[i] = weights[i]
- self.target_model.set_weights(target_weights)
4. DQN 動作
***一步是讓 DQN 實際執(zhí)行希望的動作,在給定的 epsilon 參數(shù)基礎上,執(zhí)行的動作在隨機動作與基于過去訓練的預測動作之間選擇,如下所示:
- def act(self, state):
- self.epsilon *= self.epsilon_decay
- self.epsilon = max(self.epsilon_min, self.epsilon)
- if np.random.random() < self.epsilon:
- return self.env.action_space.sample()
- return np.argmax(self.model.predict(state)[0])
5. 訓練 agent
現(xiàn)在訓練我們開發(fā)的復雜的 agent。將其實例化,傳入經(jīng)驗數(shù)據(jù),訓練 agent,并更新目標網(wǎng)絡:
- def main():
- env = gym.make("MountainCar-v0")
- gamma = 0.9
- epsilon = .95
- trials = 100
- trial_len = 500
- updateTargetNetwork = 1000
- dqn_agent = DQN(envenv=env)
- steps = []
- for trial in range(trials):
- cur_state = env.reset().reshape(1,2)
- for step in range(trial_len):
- action = dqn_agent.act(cur_state)
- env.render()
- new_state, reward, done, _ = env.step(action)
- rewardreward = reward if not done else -20
- print(reward)
- new_statenew_state = new_state.reshape(1,2)
- dqn_agent.remember(cur_state, action,
- reward, new_state, done)
- dqn_agent.replay()
- dqn_agent.target_train()
- cur_state = new_state
- if done:
- break
- if step >= 199:
- print("Failed to complete trial")
- else:
- print("Completed in {} trials".format(trial))
- break
五、完整的代碼
這就是使用 DQN 的「MountainCar-v0」環(huán)境的完整代碼!
- import gym
- import numpy as np
- import random
- from keras.models import Sequential
- from keras.layers import Dense, Dropout
- from keras.optimizers import Adam
- from collections import deque
- class DQN:
- def __init__(self, env):
- self.env = env
- self.memory = deque(maxlen=2000)
- self.gamma = 0.85
- self.epsilon = 1.0
- self.epsilon_min = 0.01
- self.epsilon_decay = 0.995
- self.learning_rate = 0.005
- self.tau = .125
- selfself.model = self.create_model()
- selfself.target_model = self.create_model()
- def create_model(self):
- model = Sequential()
- state_shape = self.env.observation_space.shape
- model.add(Dense(24, input_dim=state_shape[0], activation="relu"))
- model.add(Dense(48, activation="relu"))
- model.add(Dense(24, activation="relu"))
- model.add(Dense(self.env.action_space.n))
- model.compile(loss="mean_squared_error",
- optimizer=Adam(lr=self.learning_rate))
- return model
- def act(self, state):
- self.epsilon *= self.epsilon_decay
- self.epsilon = max(self.epsilon_min, self.epsilon)
- if np.random.random() < self.epsilon:
- return self.env.action_space.sample()
- return np.argmax(self.model.predict(state)[0])
- def remember(self, state, action, reward, new_state, done):
- self.memory.append([state, action, reward, new_state, done])
- def replay(self):
- batch_size = 32
- if len(self.memory) < batch_size:
- return
- samples = random.sample(self.memory, batch_size)
- for sample in samples:
- state, action, reward, new_state, done = sample
- target = self.target_model.predict(state)
- if done:
- target[0][action] = reward
- else:
- Q_future = max(self.target_model.predict(new_state)[0])
- target[0][action] = reward + Q_future * self.gamma
- self.model.fit(state, target, epochs=1, verbose=0)
- def target_train(self):
- weights = self.model.get_weights()
- target_weights = self.target_model.get_weights()
- for i in range(len(target_weights)):
- target_weights[i] = weights[i] * self.tau + target_weights[i] * (1 - self.tau)
- self.target_model.set_weights(target_weights)
- def save_model(self, fn):
- self.model.save(fn)
- def main():
- env = gym.make("MountainCar-v0")
- gamma = 0.9
- epsilon = .95
- trials = 1000
- trial_len = 500
- # updateTargetNetwork = 1000
- dqn_agent = DQN(envenv=env)
- steps = []
- for trial in range(trials):
- cur_state = env.reset().reshape(1,2)
- for step in range(trial_len):
- action = dqn_agent.act(cur_state)
- new_state, reward, done, _ = env.step(action)
- # rewardreward = reward if not done else -20
- new_statenew_state = new_state.reshape(1,2)
- dqn_agent.remember(cur_state, action, reward, new_state, done)
- dqn_agent.replay() # internally iterates default (prediction) model
- dqn_agent.target_train() # iterates target model
- cur_state = new_state
- if done:
- break
- if step >= 199:
- print("Failed to complete in trial {}".format(trial))
- if step % 10 == 0:
- dqn_agent.save_model("trial-{}.model".format(trial))
- else:
- print("Completed in {} trials".format(trial))
- dqn_agent.save_model("success.model")
- break
- if __name__ == "__main__":
- main()
原文:
https://medium.com/towards-data-science/reinforcement-learning-w-keras-openai-dqns-1eed3a5338c
【本文是51CTO專欄機構“機器之心”的原創(chuàng)譯文,微信公眾號“機器之心( id: almosthuman2014)”】