深度策略梯度算法是真正的策略梯度算法嗎?
近期深度強化學習取得了很多成功,但也存在局限性:缺乏穩定性、可復現性差。來自 MIT 和 Two Sigma 的研究者重新檢驗了深度強化學習方法的概念基礎,即目前深度強化學習的實踐多大程度上反映了其概念基礎框架的原則?該研究重點探討深度策略梯度方法。
深度強化學習是現代機器學習最為人所知的成就,它造就了 AlphaGO 這樣廣為人知的應用。對很多人來說,該框架展示了機器學習對現實世界的影響力。但是,不像當前的深度(監督)學習框架,深度強化學習工具包尚未支持足夠的工程穩定性。的確,近期的研究發現當前***的深度強化學習算法對超參數選擇過于敏感,缺乏穩定性,且可復現性差。
這表明或許需要重新檢驗深度強化學習方法的概念基礎,準確來說,該研究要解決的重要問題是:目前深度強化學習的實踐多大程度上反映了其概念基礎框架的原則?
該論文重點研究深度策略梯度方法,這是一種廣泛使用的深度強化學習算法。研究目標是探索這些方法的當前***實現多大程度上體現了通用策略梯度框架的關鍵基元。
該論文首先檢驗重要的深度策略梯度方法近端策略優化(PPO)。研究發現 PPO 的性能嚴重依賴于非核心算法的優化,這表明 PPO 的實際成功可能無法用其理論框架來解釋。
這一觀察促使研究者進一步檢查策略梯度算法及其與底層框架之間的關系。研究者對這些算法在實踐中展示的關鍵強化學習基元進行了細致地檢查。具體而言,研究了:
- 梯度估計(Gradient Estimation):研究發現,即使智能體的獎勵有所提升,用于更新參數的梯度估計通常與真實梯度不相關。
- 價值預測(Value Prediction):實驗表明價值網絡能夠訓練并成功解決監督學習任務,但無法擬合真正的價值函數。此外,將價值網絡作為基線函數僅能稍微降低梯度估計的方差(但能夠顯著提升智能體的性能)。
- ***化 Landscape:研究發現***化 Landscape 通常無法反映其真正獎勵的潛在 Landscape,后者在相關的采樣方案(sample regime)中通常表現不佳。
- 置信域:研究發現深度策略梯度算法有時會與置信域產生理論沖突。實際上,在近端策略優化中,這些沖突來源于算法設計的基礎問題。
研究者認為以上問題以及我們對相關理論知識的缺乏是深度強化學習脆弱性和低復現性的主要原因。這表明構建可信賴的深度強化學習算法要求拋棄之前以基準為中心的評估方法,以便多角度地理解這些算法的非直觀行為。
論文:Are Deep Policy Gradient Algorithms Truly Policy Gradient Algorithms?

論文鏈接:https://arxiv.org/pdf/1811.02553.pdf
摘要:本文研究了深度策略梯度算法對促進其發展的底層概念框架的反映程度。我們基于該框架的關鍵要素對當前***方法進行了精細分析,這些方法包括梯度估計、價值預測、***化 landscape 和置信域分析。我們發現,從這個角度來看,深度策略梯度算法的行為通常偏離其概念框架的預測。我們的分析開啟了鞏固深度策略梯度算法基礎的***步,尤其是,我們可能需要拋棄目前以基準為中心的評估方法。
檢查深度策略梯度算法的基元
1. 梯度估計的質量
策略梯度方法的核心前提是恰當目標函數上的隨機梯度上升帶來優秀的策略。具體來說,這些算法使用(代理)獎勵函數的梯度作為基元:

這些方法的理論背后的底層假設是,我們能夠獲取對梯度的合理估計,即我們能夠使用有限樣本(通常大約 103 個)的經驗平均值準確估計上面的期望項。因此研究者對實踐中該假設的有效性很感興趣。
我們計算出的梯度估計準確度如何?為了解決該問題,研究者使用了評估估計質量最自然的度量標準:經驗方差(empirical variance)和梯度估計向「真正」梯度的收斂情況。

圖 2
圖 2:梯度估計的經驗方差在 MuJoCo Humanoid 任務中可作為狀態-動作對關于數量的函數,x 軸為狀態-動作對,y 軸是梯度估計的經驗方差。
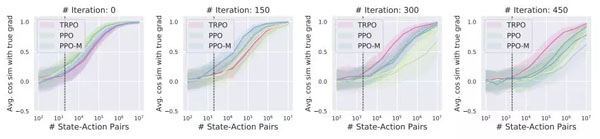
圖 3
圖 3:MuJoCo Humanoid 任務中梯度估計向「真正」期望梯度的收斂情況。
2. 價值預測

圖 4
圖 4:對于訓練用于解決 MuJoCo Walker2d-v2 任務的智能體,在留出狀態-動作對上的價值預測質量(度量指標為平均相對誤差 MRE)。
3. 探索***化 landscape
策略梯度算法的另一個基礎假設是對策略參數使用一階更新可以帶來性能更好的策略。因此接下來我們就來看該假設的有效性。
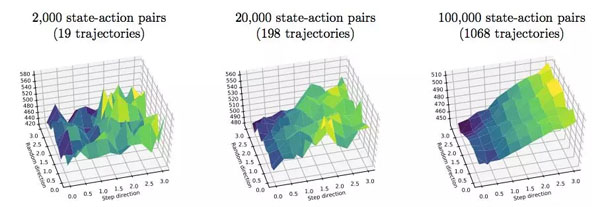
圖 6:在 Humanoid-v2 MuJoCo 任務上,TRPO 的真正獎勵函數 Landscape。
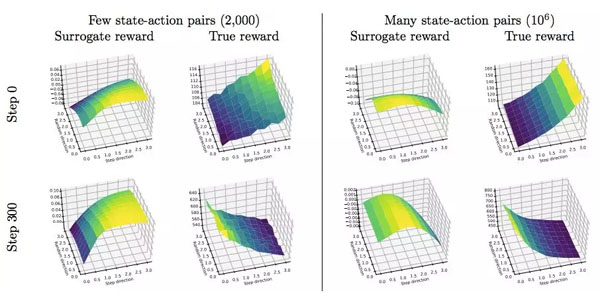
圖 8:在 Humanoid-v2 MuJoCo 任務上,PPO 的真正和代理獎勵函數 Landscape。
4. 置信域的優化

圖 9
圖 9:對于訓練用于解決 MuJoCo Humanoid 任務的智能體,每一步的平均獎勵、***速率(maximum ratio)、平均 KL 和 maximum versus mean KL 情況。
為深度強化學習奠定更好的基礎
深度強化學習算法根植于基礎穩固的經典強化學習框架,在實踐中展示了巨大的潛力。但是,該研究調查顯示,該底層框架無法解釋深度強化學習算法的很多行為。這種分裂妨礙我們深入理解這些算法成功(或失敗)的原因,而且成為解決深度強化學習所面臨重要挑戰的極大障礙,比如廣泛的脆弱性和薄弱的可復現性。
為了解決這種分類,我們需要開發更加貼近底層理論的方法,或者構建能夠捕捉現有策略梯度算法成功原因的理論。不管哪種情況,***步都要準確指出理論和實踐的分岔點。這部分將分析和鞏固前一章的發現和結果。
- 梯度估計。上一章的分析表明策略梯度算法使用的梯度估計的質量很差。即使智能體還在提升,此類梯度估計通常與真正的梯度幾乎不相關(見圖 3),彼此之間也不相關(見圖 2)。這表明遵循現有理論需要算法獲取更好的梯度估計。或者,我們需要擴展理論,以解釋現代策略梯度算法為什么在如此差的梯度估計情況下還能取得成功。
- 價值預測。研究結果說明兩個關鍵問題。一,盡管價值網絡成功解決了接受過訓練的監督學習任務,但它無法準確建模「真正」的價值函數。二,將該價值網絡作為基線會降低梯度方差。但與「真」價值函數提供的方差減少程度對比來說則太少了。這些現象促使我們發問:建模真價值函數的失敗是在所難免的嗎?價值網絡在策略梯度方法中的真正作用是什么?
- ***化 Landscape。由上一章可知,現代策略梯度算法的***化 Landscape 通常無法反映底層真正獎勵的 Landscape。事實上,在策略梯度方法使用的采樣方案中,真獎勵的 Landscape 有噪聲,且代理獎勵函數通常具備誤導性。因此我們需要深入理解為什么這些方有這么問題還能成功,更寬泛一點來看,如何更準確地展現真獎勵函數的 Landscape。
- 置信域近似。該研究的發現表明策略需要局部類似可能存在大量原因,包括帶噪聲的梯度估計、較差的基線函數和代理 Landscape 未對齊。底層理論的置信域優化不僅未察覺到這些因素,將該理論轉換成高效算法也非常困難。因此深度策略梯度方法放松對置信域的約束,這使得其性能難以理解和分析。因此,我們需要一種更加嚴格地執行置信域的技術,或者對于置信域放松的更嚴謹理論。
【本文是51CTO專欄機構“機器之心”的原創譯文,微信公眾號“機器之心( id: almosthuman2014)”】