站在巨人的肩膀上,深度學習的9篇開山之作

自從2012年CNN首次登陸ImageNet挑戰賽并一舉奪取桂冠后,由CNN發展開來的深度學習一支在近5年間得到了飛速的發展。
今天,我們將帶領大家一起閱讀9篇為計算機視覺和卷積神經網絡領域里帶來重大發展的開山之作,為大家摘錄每篇論文的主要思路、重點內容和貢獻所在。
AlexNet (2012)
https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
這篇論文可謂是CNN的開山鼻祖(當然,有些人也會說Yann LeCun 1998年發表的Gradient-Based Learning Applied to Document Recognition才是真正的開山之作)。該論文題為“ImageNet Classification with Deep Convolutional Networks”,目前已經被引用6184次,是該領域公認影響最為深遠的論文之一。
在這篇論文中,Alex Krizhevsky, Ilya Sutskever, 和Geoffrey Hinton 共同創造了一個“大規模深度神經網絡”,并用它贏得了2012 ImageNet挑戰賽 (ImageNet Large-Scale Visual Recognition Challenge)的冠軍。(注:ImageNet可被視作計算機視覺領域的奧林匹克大賽,每年,來自全世界的各個團隊在這項競賽中激烈競爭,不斷發現用于分類、定位、探測等任務的最優計算機視覺模型。)
2012年,CNN首次登場便以15.4%的錯誤率拔得頭籌,遠遠優于第二名的26.2%。CNN對計算機視覺領域的貢獻可見一斑。自這場比賽后,CNN就變得家喻戶曉了。
這篇論文里討論了AlexNet神經網絡的具體結構。相比現在流行的神經網絡構架,它的結構其實非常簡單:5個卷積層、最大池化層(max pooling layer),dropout層,和3個全連接層(fully connected layers)。但這個結構已經可以被用來分類1000種圖片了。

AlexNet的結構
可能你會注意到,圖上出現了兩個分支,這是因為訓練計算量太大了,以至于他們不得不把訓練過程分到兩個GPU上。
劃重點:
- 訓練集ImageNet data有超過1500萬張標記圖片,共22000個分類。
- 解非線性方程用的是ReLu算法(因為發現ReLu的訓練時間相比卷積tanh函數要快上數倍)。
- 使用了包括圖像平移(image translations),水平翻轉(horizontal reflections),和圖像塊提取(patch extractions)等數據增強技術。
- 使用了dropout層來避免對訓練數據的過度擬合。
- 使用了特定的動量(momentum)和權重衰減(weight decay)參數的批量隨機梯度下降(batch stochastic gradient descent)算法來訓練模型。
- 在兩塊GTX580GPU上訓練了5到6天。
意義總結:
這個由Krizhevsky,Sutskever和Hinton在2012年共同提出的神經網絡開始了CNN在計算機視覺領域的盛宴,因為這是有史以來第一個在ImageNet數據集上表現如此優異的模型。里面用到的一些技術,如數據增強和丟棄(data augmentation and dropout),至今仍然在被廣泛使用。這篇論文詳述了CNN的優勢,而它在比賽上的驚艷表現也讓它名留青史。
ZF Net (2013)
https://arxiv.org/pdf/1311.2901v3.pdf
AlexNet在2012年大放異彩之后,2013年的ImageNet大賽上出現了大量的CNN模型,而桂冠則由紐約大學的Matthew Zeiler和Rob Fergus摘得,折桂模型就是ZF Net。這一模型達到了11.2%的錯誤率。它好比是之前AlexNet的更精確調試版本,但它提出了如何提高準確率的關鍵點。此外,它花了大量篇幅解釋了ConvNets背后的原理,并且正確地可視化了神經網絡的過濾器(filter)和權重(weights)。
作者Zeiler 和 Fergus在這篇題為“Visualizing and Understanding Convolutional Neural Networks”的論文開篇就點出了CNN能夠再次興起的原因:規模越來越大的圖片訓練集,和GPU帶來的越來越高的計算能力。同時他們也點出,很多研究者其實對于這些CNN模型的內在原理認知并不深刻,使得“模型優化過程只不過是不斷試錯”,而這一現象在3年后的今天依舊廣泛存在于研究者當中,盡管我們對CNN有了更加深入的理解!論文的主要貢獻在于細述了對AlexNet的優化細節,及以用一種巧妙的方式可視化了特征圖。

ZF Net 結構
劃重點:
- 除了一些細小的修改,ZF Net模型與AlexNet構架很相似。
- AlexNet使用了1500萬張圖片做訓練,ZF Net只用了130萬張。
- AlexNet在第一層用了11x11的過濾器,而ZF Net用了減小了步長(stride)的7x7過濾器,原因是第一層卷積層用小一點的過濾器可以保留更多原始數據的像素信息。用11x11的過濾器會跳過很多有用信息,尤其在第一個卷積層。
- 過濾器的數目隨著神經網絡的增長而增多。
- 激活函數用了ReLu,誤差函數用了交叉熵損失(cross-entropy loss),訓練使用批量隨機梯度下降方法。
- 在一塊GTX580 GPU上訓練了12天。
- 開發了一種被稱為Deconvolutional Network(解卷積網絡)的可視化技術,能夠檢測不同特征激活與對應輸入空間(input space)間的關系。之所以稱之為“解卷積網”(deconvnet),是因為它能把特征映射回對應的像素點上(正好和卷積層做的事相反)。
這個網絡結構背后的思路就是,在訓練CNN的每一層都加上一個“deconvnet”,從而可以回溯到對應的像素點。一般的前向傳播過程是給CNN輸入一個圖片,然后每一層計算出一個激活函數值。假設現在我們想檢測第四層某一特征的激活,我們就把除了此特征之外的其他特征激活值設為0,再把此時的特征映射矩陣輸入給deconvnet。Deconvnet與原始的CNN有相同的過濾器結構,再針對前三層網絡進行一系列反池化過程(unpool,maxpooling的逆過程)、激活(rectify)和過濾操作,直到回到最初的輸入空間。
這樣做是為了找出圖像中刺激生成某一特征的結構所在。我們來看看對第一層和第二層的可視化結果:

前兩層的可視化結果:每一層演示了兩個結果,第一個是過濾器的可視化,另外一個是圖片中被過濾器激活最明顯的部分。例如圖上Layer2部分展示了16個過濾器
我們在CNN入門手冊(上)里說過,ConvNet的第一層永遠做的是一些最基礎的特征檢測,像是簡單的邊緣和這里的顏色特征。我們能看到,到了第二層,更多的環形結構特征就顯示出來了。再看看第三、四、五層:

3,4,5層的可視化結果
這些層已經能顯示出更高級特征,像是小狗和花朵。別忘了在第一層卷積之后,我們一般會有一個池化層減少圖片的采樣(例如從32x32x3減少到16x16x3)。這樣做能讓第二層對原始圖片有一個更廣闊的視角。如欲獲取更多關于deconvnet和這篇論文的信息,可以看看Zeiler他本人這篇演講(https://www.youtube.com/watch?v=ghEmQSxT6tw)。
意義總結:
ZF Net的意義不僅在于奪得了2013年比賽的第一名,更重要的是它直觀展示了CNN如何工作,并且提出了更多提高CNN表現的方法。這些可視化技術不僅描述了CNN內部的工作原理,同時對神經網絡結構的優化提供了深刻的見解。精妙的deconv可視化展示和里面提到的閉塞實驗(occlusion experiments)都讓其成為我最喜歡的論文之一。
VGG Net (2014)
https://arxiv.org/pdf/1409.1556v6.pdf
簡單、深度,就是這個2014年模型的理念。它由牛津大學的Karen Simonyan 和Andrew Zisserman提出,在ImageNet大賽中達到了7.3%的錯誤率(不過不是當年的第一)。它是一個19層的CNN模型,每一層都由步長和填充(pad)為1的3x3 過濾器,和步長為2的2x2 maxpooling層組成,是不是很簡單呢?
")
劃重點:
- 與AlexNet的11x11過濾器和ZF Net7x7的過濾器非常不同,作者解釋了為什么選擇用只有3x3的結構:兩個3x3的卷積與一個5x5的卷積效果相同,這樣我們可以用很小的過濾器模擬出較大的過濾器的效果。一個直接的好處就是減少了參數數量,同時用兩個卷積層就能用到兩次ReLu
- 3個卷積層與一個7x7的過濾器感受效果相同
- 輸入空間隨著層數增多而減少(因為卷積和池化),但隨著卷積和過濾器的增多,卷積深度不斷加深
- 值得注意的是每次maxpool之后過濾器的數量都翻倍了。這也再次實踐了減少空間維度但加深網絡深度的理念
- 在圖像分類和定位上都表現很好,作者將定位用在了回歸中(論文第10頁)
- 使用Caffe建立模型
- 利用抖動(scale jittering)作為訓練時數據增強的手段
- 每個卷積層后都有一個ReLu,用批量梯度下降來訓練
- 在4個英偉達Titan Black GPU上訓練了2到3周
意義總結:
我認為VGG Net算得上最具影響力的論作之一,因為它強調了卷積神經網絡需要用到深度網絡結構才能把圖像數據的層次表達出來。
GoogLeNet (2015)
http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Szegedy_Going_Deeper_With_2015_CVPR_paper.pdf
還記得我們剛剛談到的網絡架構簡單化的想法嗎?谷歌就把這個想法引入了他們的Inception模塊。 GoogLeNet是一個22層CNN,它憑著6.7%的錯誤率殺入五強并成為2014年ImageNet大賽的優勝者。 據我所知,這是第一個真正不同于原有的簡單疊加順序卷基層和池化層的構建方法的CNN架構之一。 這篇文章的作者還強調這個新模式在內存和功耗方面進行了重要的改進。(這是一個重要注意事項:堆疊層次并添加大量的過濾器都將產生巨大的計算和內存開銷,也更容易出現過度擬合。)

GoogLeNet架構示意圖之一

GoogLeNet架構示意圖之二
Inception模塊
讓我們來看一下GoogLeNet的結構。我們首先要注意到一點:并不是所有的過程都按順序發生。如上圖所示,GoogLeNet里有并行進行的網絡結構。

綠框內顯示GoogLeNet的并行區
上圖綠框里的結構叫做Inception模塊。下面讓我們來仔細看一下它的構成。

展開的Inception模塊
上圖中,底部的綠色框是我們的輸入,而頂部的綠色框是模型的輸出。(將這張圖片右轉90度, 與前一張GoogLeNet全景圖聯系起來一起看,可以看出完整網絡的模型。 )基本上,在傳統ConvNet的每一層里,你都必須選擇是否進行池化操作或卷積操作,以及過濾器的尺寸。 一個Inception模塊允許你并行執行所有這些操作。 事實上這正是作者最初提出的一個“天真”的想法。
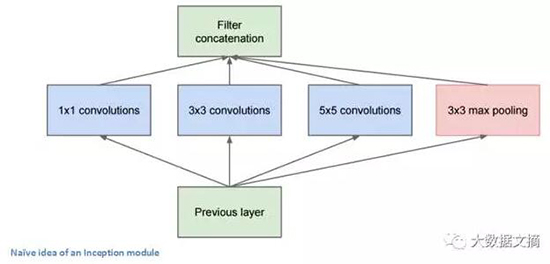
關于Inception模塊的一個“天真”的想法
那么,為什么這樣的設計并不可行?因為這將導致太多太多的輸出,使得我們最終因大輸出量而停留在一個非常深的信道(channel)。 為了解決這個問題,作者在3x3和5x5層之前添加1x1卷積操作。 1x1卷積,又叫作網絡層中的網絡,提供了一種降低維數的方法。 例如,假設您的輸入量為100x100x60(不一定是圖像的尺寸,只是網絡中任意一層的輸入尺寸), 應用1x1卷積的20個過濾器可以將輸入降低到100x100x20,從而3x3和5x5卷積的處理量不會太大。 這可以被認為是一種“特征池化”(pooling of features),因為我們減小了輸入量的深度,這類似于我們通過標準的max-pooling層降低高度和寬度的維度。 另一個值得注意的點是,這些1x1卷積層之后的ReLU單元 的功能, 不會因降維而受到的損害。(參見Aaditya Prakash的博客http://iamaaditya.github.io/2016/03/one-by-one-convolution/以了解更多1x1卷積的效果等信息。) 你可以在這個視頻中看到最終過濾器級聯的可視化https://www.youtube.com/watch?v=_XF7N6rp9Jw。 )
你可能有這樣的疑問“這個架構為什么好用”?這個架構提供了一個模塊,它包括一個網絡層的網絡、一個中等大小的卷積過濾器 、一個大型的卷積過濾器和一個池化操作。 網絡層的網絡的卷積能夠提取關于輸入的非常細節的信息,而5x5濾鏡能夠覆蓋輸入的較大接收場,因此也能夠提取其信息。
你還可以用一個池化操作來減少占用空間大小,并防止過度擬合。 此外,每個卷積層之后都進行ReLUs,這有助于提高網絡的非線性。大體來講,這樣的網絡能夠做到執行各類操作的同時仍保持計算性。 這篇論文還提出了一個高層次的推理,涉及稀疏性(sparsity)和密集連接(dense connections)等主題。(參見論文http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Szegedy_Going_Deeper_With_2015_CVPR_paper.pdf的第3段和第4段。我并不很理解這方面的內容,但很樂意聽到你們在評論中發表自己的見解。)
劃重點:
- 在整個架構中使用了9個inception模塊,共有100多層。現在看來很有深度…
- 不使用完全連接的層 !他們使用平均池化代替,將7x7x1024的輸入量轉換為1x1x1024的輸入量。 這節省了大量的參數。
- 使用比AlexNet少12倍的參數。
- 在測試期間,創建了同一圖像的多個版本,輸入到神經網絡中,并且用softmax概率的平均值給出最終解決方案。
- 在檢測模型中使用了R-CNN的概念(隨后的一篇論文中將討論) 。
- Inception模塊現在有多個更新版本(版本6和7)。
- 在一周內使用“幾個高端GPU”訓練模型。
意義總結:
GoogLeNet是率先引入“CNN層并不需要按順序堆疊”這一概念的模型之一。隨著 Inception模塊的提出, 作者認為有創意的層次結構可以提高性能和計算效率。 這篇文章為接下來幾年出現的一些驚人架構奠定了基礎。
借用李奧納多的一句臺詞“我們需要更深入。”
微軟的ResNet(2015)
https://arxiv.org/pdf/1512.03385v1.pdf
讓我們來想像一個深度CNN架構,對其層數加倍,然后再增加幾層。但是這個CNN結構可能還是比不上微軟亞洲研究院2015年底提出的ResNet體系結構那么深。ResNet是一個新的152層網絡架構,它以一個令人難以置信的架構在分類、檢測和定位等方面創造了新的記錄。 除了層次上的新紀錄之外,ResNet還以令人難以置信的3.6%的錯誤率贏得了2015年ImageNet大賽的桂冠。其他參賽者的錯誤率一般徘徊在5-10%左右。(參見Andrej Karpathy的博客http://karpathy.github.io/2014/09/02/what-i-learned-from-competing-against-a-convnet-on-imagenet/,這篇文章說明了其在ImageNet挑戰賽與競爭對手ConvNets競爭的經歷。)
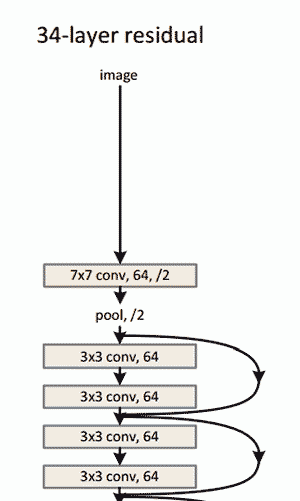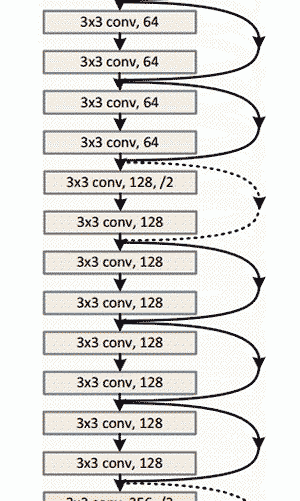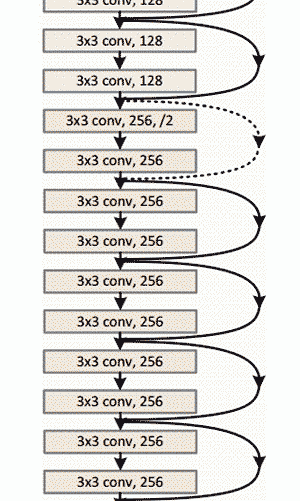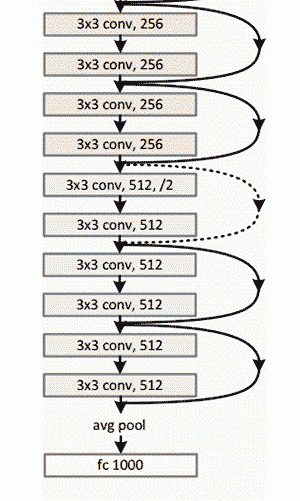
上圖ResNet架構示意圖
Residual Block(殘差塊)
Residual Block背后的想法是把輸入x通過conv-relu-conv序列輸出。 這將先輸出一些F(x),再把這些結果添加到原始輸入x 即H(x)= F(x) + x。 而在傳統的CNN中,H(x)直接等于F(x)。 所以,在ResNet中,我們不僅計算這個簡單轉換(從x到F(x)),還將F(x)加到輸入x中。 在下圖所示的迷你模塊計算中,原輸入x被做輕微變化,從而得到一個輕微改變的輸出 。(當我們考慮傳統CNN時,從x到F(x)是一個全新的表達,不保留關于原始x的任何信息。 作者認為“優化殘差映射比優化原始映射更容易。”)

殘差塊的結構
Residual Block之所以有效的另一個原因是,在反向傳播過程中,由于我們對加法運算分布了梯度,梯度能夠很容易地流過圖。
劃重點:
- “超級深” - Yann LeCun。
- 152層…
- 有趣的是,在僅僅前兩層之后,空間大小從224x224的輸入量壓縮到56x56。
- 作者聲稱,在普通網絡中簡單增加層次,將導致較高的訓練和測試誤差(論文里的圖1)
- 該小組嘗試了一個1202層網絡,但可能由于過擬合而導致測試精度較低。
- 在8個GPU機器上訓練了兩到三周 。
意義總結:
3.6%的錯誤率就足以說服你。 ResNet模型是我們目前擁有的最好的CNN架構,是殘差學習思想的一大創新。 自2012年以來,ResNet模型的錯誤率逐年下降。我相信我們已經到了“堆疊很多層的神經網絡也不能帶來性能提升”的階段了 。接下來肯定會有創新的新架構,就像過去2年一些新嘗試的出現。
推薦閱讀:
ResNets內的ResNets http://arxiv.org/pdf/1608.02908.pdf。
基于區域的CNN
- R-CNN – 2013:https://translate.googleusercontent.com/translate_c?act=url&depth=1&hl=en&ie=UTF8&prev=_t&rurl=translate.google.com&sl=en&sp=nmt4&tl=zh-CN&u=https://arxiv.org/pdf/1311.2524v5.pdf&usg=ALkJrhgwBa8jBFOgSDEuZFOmg5CeahQVSw
- Fast R-CNN – 2015:https://translate.googleusercontent.com/translate_c?act=url&depth=1&hl=en&ie=UTF8&prev=_t&rurl=translate.google.com&sl=en&sp=nmt4&tl=zh-CN&u=https://arxiv.org/pdf/1504.08083.pdf&usg=ALkJrhiMQQ68G9lTdUV9DYnKPAUOb6PDaA
- Faster R-CNN – 2015:https://translate.googleusercontent.com/translate_c?act=url&depth=1&hl=en&ie=UTF8&prev=_t&rurl=translate.google.com&sl=en&sp=nmt4&tl=zh-CN&u=http://arxiv.org/pdf/1506.01497v3.pdf&usg=ALkJrhjfeXGyTfxi4AmeFDqjODJ4qoHN8w
有些人可能會認為,這篇首次描述R-CNN的論文比之前所有創新網絡架構論文都更有影響力。 隨著第一個R-CNN論文被引用超過1600次,Ross Girshick和他在加州大學伯克利分校領導的研究組,實現了計算機視覺領域中最有影響力的進步之一。 他們的標題清楚地表明:Fast R-CNN和Faster R-CNN能使模型更快和更適配的用于當前的目標檢測任務。
R-CNN的目的是解決目標檢測問題。 對給定圖像,我們希望能為圖像里的全部物體繪制邊界框。 這個過程可以分為兩個步驟:區域提取和分類。
作者指出,任何類別不可知的區域提取方法都能用于R-CNN。 其中選擇性搜索(https://ivi.fnwi.uva.nl/isis/publications/2013/UijlingsIJCV2013/UijlingsIJCV2013.pdf)特別適用于R-CNN。選擇性搜索先執行生成 2000個概率最高的含有物體的不同區域的函數。隨后這些被建議的區域都被“扭曲”(warp)成為一個個合適尺寸大小的圖像, 輸入到一個訓練好的CNN(文章里用的是AlexNet)。這個CNN將為每個區域提取出一個特征向量,然后這些向量被輸入到一組針對每類物體分別進行訓練的線性SVM,從而輸出分類結果。 同時這些向量也被輸入給訓練好的邊界框回歸器,以獲得最準確的坐標。

R-CNN流程圖
接下來R-CNN使用非最大值抑制(Non-maxima suppression)來處理明顯重疊的物體邊界框。
Fast R-CNN:
針對三個主要問題,他們對原始模型進行了改進。 模型訓練被分成幾個階段(ConvNets到SVM到邊界框回歸),計算量極其大, 而且非常慢(RCNN在每個圖像上花費 53秒)。 Fast R-CNN基本上通過共享不同方案之間的轉換層計算、交換生成區域提案的順序、和運行CNN,從而解決了速度問題。
在該模型中,圖像首先進入ConvNet, 從ConvNet的最后一個特征圖中獲取用于區域提取的特征(更多詳細信息請參閱該論文的2.1部分),最后還有完全連接層、回歸、和分類開始。
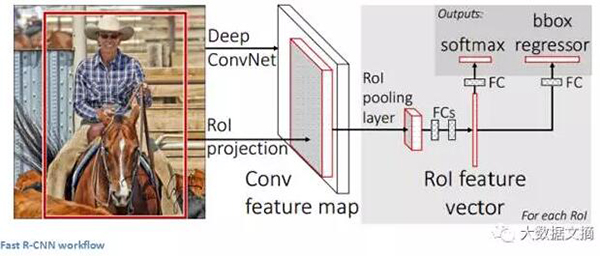
Faster R-CNN可以用于解決R-CNN和Fast R-CNN所使用的復雜的訓練管線 。 作者在最后一個卷積層之后插入了一個區域候選網絡(region proposal network,RPN)。 該網絡能夠在僅看到最后的卷積特征圖后就從中產生區域建議。 從那個階段開始,與R-CNN相同的管道就被使用了(感興趣區域池層 ROI pooling,全連接層FC, 分類classification,回歸regression… )。

Faster R-CNN工作流程
意義總結:
能夠確定特定對象在圖像中是一回事,但是能夠確定對象的確切位置是另外一回事,那是計算機知識的巨大跳躍。 Faster R-CNN已經成為今天對象檢測程序的標準。
生成對抗網絡(2014)
https://arxiv.org/pdf/1406.2661v1.pdf
據Yann LeCun介紹,這些網絡可能是下一個大發展。 在談論這篇文章之前,讓我們談談一些對抗范例。 例如,讓我們考慮一個在ImageNet數據上運行良好的CNN。 我們先來看一個示例圖,再用一個干擾或一個微小的修改使預測誤差最大化,預測的對象類別結果因此而改變,盡管擾動后的圖像相比愿圖像本身看起來相同。 從高層視野 來看,對抗組示例基本上是愚弄ConvNets的圖像。
")
對抗的例子(《神經網絡中的有趣屬性》)肯定讓很多研究人員感到驚訝,并迅速成為一個令人感興趣的話題。現在我們來談一談生成對抗網絡。讓我們來看兩個模型,一個生成模型和一個判別模型。鑒別模型的任務是,確定一個給定的圖像是否看起來自然(來自數據集的圖像)或者看起來像人造的。生成器的任務是創建圖像,使鑒別器得到訓練并產生正確的輸出。這可以被認為是一個雙玩家間的零和博弈(zero-sum)或最大最小策略(minimax)。
該論文中使用的類比是:生成模式就像“一批冒牌者試圖生產和使用假貨”,而判別模式就像“警察試圖檢測假冒貨幣”。生成器試圖愚弄判別器,而判別器試圖不被生成器愚弄。隨著模型的訓練,兩種方法都得到了改進,直到“假冒品與正品無法區分”為止。
意義總結:
聽起來很簡單,但為什么我們關心這些網絡呢?正如Yann LeCun 所說,判別器現在知道“數據的內部表示”是因為它已理解來自數據集的真實圖像和人為創建的之間的差異。 因此,你可以把它作為一個特征提取器用于CNN中 。 此外,您可以創建一些非常酷的人造圖像,而且這些圖像在我看來是很自然的(The Eyescream Project) 。
Generating Image Descriptions (2014)
https://arxiv.org/pdf/1412.2306v2.pdf
當你把CNN與RNN組合起來時會發生什么?不好意思,您不會得到R-CNN的。但是你會得到一個非常棒的應用程序。 作者Andrej Karpathy(我個人最喜歡的作者之一)和Fei-Fei Li一起撰寫了這篇論文, 研究了CNN和雙向RNN (Recurrent Neural Networks)的組合,以生成不同圖像區域的自然語言描述。大體來講,該模型能夠拍攝一張圖像并輸出如下圖片:

這很不可思議!我們來看看這與正常的CNN相比如何。 對于傳統的CNN,訓練數據中每個圖像都有一個明確的標簽。 本論文中所描述的模型,其每個訓練實例都具有一個與各個圖像相關聯的句子或標題 。 這種類型的標簽被稱為弱標簽,其中句子的成分指的是圖像的(未知)部分。 使用這個訓練數據,一個深度神經網絡“推斷出句子的各個部分和他們描述的區域之間的潛在對應”(引自論文)。 另一個神經網絡將圖像作為輸入,并生成文本描述。 讓我們來看看這兩個組件:對準和生成。
1. 對準模型(Alignment Model):
這一部分模型的目標是,對齊視覺數據和文本數據(圖像及其句子描述)。 該模型通過接受圖像和句子作為輸入,輸出它們的匹配 程度得分。
現在讓我們考慮將這些圖像表現出來。 第一步是將圖像送到R-CNN中,以便檢測各個物體。 該R-CNN已對ImageNet數據進行了訓練。 最先的19個(加上原始圖像)對象區域被嵌入到500維的空間中。 現在我們有20個不同的500維向量(在論文中由v表示)。 我們有了關于圖像的信息,現在我們想要有關句子的信息。 我們通過使用雙向循環神經網絡,將單詞嵌入到同一個多模態空間中。 從最高層次來說,這是用來說明給定句子中單詞的上下文信息的。 由于關于圖片和句子的信息都在相同的空間中,我們可以通過計算它們的內積來得到它們的相似度。
2. 生成模型(Generation Model):
對準模型的主要目的是創建一個數據集,其中包括一組圖像區域(由RCNN找到)和其相應的文本(由BRNN找到)。 現在,生成模型將從該數據集中學習,以生成給定圖像的描述。 該模型接收圖像并交給CNN處理。最軟層(softmax layer)被忽略,因為完全連接層的輸出將成為另一個RNN的輸入。 RNN的功能是形成一個句子中不同單詞的概率分布(RNN也需要像CNN那樣訓練)。
免責聲明:這絕對是本章節中詰屈聱牙的論文之一,所以如果有任何更正或其他解釋,我很樂意聽到他們的意見。

意義總結:
組合使用這些看似不同的RNN和CNN模型來創建一個非常有用的應用程序,對我來說是個有趣的想法,這是結合計算機視覺和自然語言處理領域的一種方式。 這開啟了處理跨領域的任務時實現計算機和模型更加智能化的新思路。
Spatial Transformer Networks (2015)
https://arxiv.org/pdf/1506.02025.pdf
最后,讓我們走近一篇最近發表的論文。這篇文章是由Google Deepmind的一個小組在一年多前撰寫的,主要貢獻是引入空間變換模塊。這個模塊的基本思想是, 以一種方式轉換輸入圖像,使得隨后的圖層更容易進行分類。作者擔心的是在將圖像在輸入特定的卷積層之前出現的更改,而不是對CNN主體架構本身進行的更改 。這個模塊希望糾正的兩件事情是,形狀正則化(對象被傾斜或縮放)和空間注意力(引起對擁擠圖像中的正確對象的關注)。對于傳統的CNN,如果你想使模型對不同尺度和旋轉的圖像保持不變性,你需要大量的訓練示例。讓我們來詳細了解這個變換模塊是如何幫助解決這個問題。
傳統CNN模型中,處理空間不變性的實體是最大分池層[1] ( maxpooling layer)[2] 。 這一層背后的直觀原因是,一旦我們知道某一個特定的特征位于原始輸入空間內(任何有高激活值的地方),它的確切位置就不像其他特征的相對位置那樣重要了。 這種新的空間變換器是動態的,它將為每個輸入圖像產生不同的行為(不同的扭曲或變換)。 它不僅僅是一個傳統的maxpool那么簡單和預定義。 我們來看看這個變換模型的工作原理。 該模塊包括:
- 一個本地化網絡,應用參數有輸入量和空間變換輸出。 對于仿射變換(affine transformation),參數 θ可以是6維的。
- 創建一個采樣網格。這是通過在本地化網絡中用創建的仿射變換theta來扭曲常規網格的結果。
- 一個采樣器,其目的是對輸入特征圖做扭曲變換。
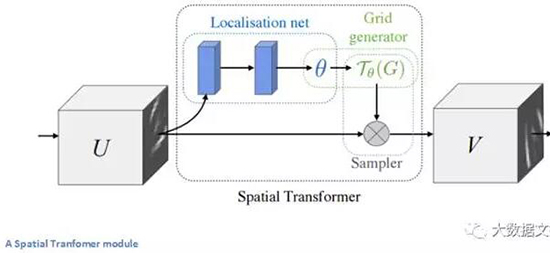
該模塊可以隨時投入CNN,并且會幫助網絡學習如何以在訓練中以最小化成本函數的方式來轉換特征圖。
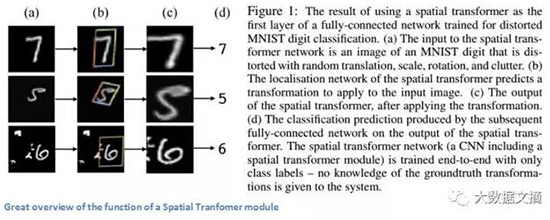
意義總結:
這篇論文之所以引起了我的注意,主要是因為它告訴我們CNN的改進不一定要來自網絡架構的巨大變化,我們不需要創建下一個ResNet或Inception模塊。 這篇論文實現了對輸入圖像進行仿射變換的簡單思想,使得模型對轉換、縮放、旋轉操作變得更加穩定。
【本文是51CTO專欄機構大數據文摘的原創譯文,微信公眾號“大數據文摘( id: BigDataDigest)”】