如何使用深度學習去除人物圖像背景
近日,Medium 上出現了一篇題為《Background removal with deep learning》的文章,講述的是 greenScreen AI 在利用深度學習去除圖像人物背景方面的工作與研究。本著開發一個有意義的深度學習產品的初衷,他們把任務鎖定在了自拍和人物肖像上,并最終在已稀釋的 COCO 數據集上取得了 84.6 的 IoU,而當下最佳水平是 85。

簡介
在研究機器學習的最近幾年里,我一直想著打造真正的機器學習產品。數月之前,在學習完 Fast.AI 上的深度學習課程之后,我清晰地意識到機會來了:深度學習技術的進步可以使很多之前不可能的事情變成現實,新工具被開發出來,它們可以讓部署變的比以前更便捷。在前面提到的課程中,我結識了 Alon Burg,他是一位很有經驗的網頁開發者,我們達成一致來共同完成這個目標。我們一起設定了以下目標:
- 提升我們的深度學習技巧
- 提升我們的人工智能產品部署技巧
- 開發一款有用的、具有市場需求的產品
- 有趣(不僅對我們而言,也對用戶而言)
- 分享我們的經驗
基于以上目標,我們探索了一些想法:
- 之前沒有被做過的(或是沒有被正確做過)
- 規劃和實現的難度不大——我們計劃兩到三個月完成,每周一個工作日。
- 具有簡單并且吸引人的用戶接口——我們旨在做出人們能夠使用的產品,而不僅僅停留在演示的目標上。
- 要有方便獲取的訓練數據——眾所周知,有時候數據比算法更加昂貴
- 使用到前沿的深度學習技術(要是那種還未被 Google Allo、亞馬遜以及其云平臺上的合作者商業化的技術),但是也不能太前沿(這樣的話我們可以在網絡上找到一些例子)
- 要擁有實現「生產就緒」(production ready)結果的潛力
我們的前期想法是做一些醫療項目,因為這個領域與我們內心所設想、所感受的東西更相近,醫療領域還有著大量唾手可得的成果。然而,我們意識到我們可能會在收集數據上碰到一些問題,也有可能會觸及到法律,這是我們最后放棄醫療項目的原因。我們的第二個選擇就是圖像背景去除。
背景去除是一個很容易手動或者半手動實現的任務(Photoshop,甚至 Power Point 都有這類工具),如果你使用某種「標記」或者邊緣檢測,這里有一個實例
(https://clippingmagic.com/)。然而,全自動化的背景去除是一個相當有挑戰性的任務,據我們所知,目前還沒有一個產品具有令人滿意的效果,盡管有人在嘗試。
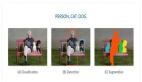
我們要去除什么背景呢?這是一個重要的問題,因為就對象、角度而言,一個模型越是具體,分離的質量就會越高。我們的工作開始時,想法很龐大:就是要做一個通用的能夠識別所有類型的圖像中的前景和背景的背景去除器。但是當我們訓練完第一個模型之后,我們明白了,集中力量在某類特定的圖像集上會更好一些。所以,我們決定集中在自拍和人物肖像上。
肖像的背景去除")
人物(類人)肖像的背景去除
自拍有明顯的和更為集中的前景(一個或者多個人物),這使得我們能夠很好地將對象(人臉+上身)與背景分離,同時還有一個相對固定的角度,以及總是同一個對象(人物)。
有了這些假設之后,我們踏上了研究、實現以及花數小時訓練得到一個簡便易用的背景去除產品的旅程。
我們的主要工作是訓練模型,但是我們不能低估正確部署的重要性。好的分割模型仍然不如分類模型那么緊密(例如 SqueezeNet),我們主動地檢查了服務器模型和瀏覽器模型的部署選擇。
如果你想閱讀關于我們產品的部署過程的諸多細節,你可以去瀏覽我們關于服務器端和客戶端的博文。
如果你想讀到更多關于模型和訓練的東西,那就繼續吧。
語義分割
我們查看了和我們的任務類似的深度學習和計算機視覺任務,不難發現,我們的最佳選擇就是語義分割任務。
其他策略,比如通過深度檢測來做分割也存在,但是對我們的目標而言并不成熟。
語義分割是一個計算機視覺經典任務,它是計算機視覺領域的三大主題之一,其他兩個分別是分類和目標檢測。從將每一個像素歸為一個類別來講,分割實際上也是一個分類任務。然而與圖像分類和目標檢測不一樣的是,分割模型事實上表現出了某種對圖像的「理解」,在像素層面上不僅能區分「這張圖像上有一只貓」,還能指出這是什么貓。
所以,分割是如何工作的呢?為了更好地理解它,我們必須梳理一下這個領域的一些早期工作。
最早的想法是采用一些早期的分類神經網絡,例如 VGG、Alexnet。回溯到 2014 年,VGG 是圖像分類任務中最領先的網絡,它在今天也相當有用,因為它有著簡單直接的結構。在查看 VGG 的前幾層的時候,你可能會注意到從每一條目到類別都有高激活值。更深的層甚至還有更高的激活值,但是由于其重復池化動作,本質上它們是很粗糙的。有了這些理解之后,可以假定,在經過一些處理之后,分類訓練也能用在尋找/分割對象的任務中。
早期的語義分割結果是和分類算法一起出現的。在本文中,你可以看到我們使用 VGG 得出的一些簡單的分割結果:
后邊層的結果:

對 buss 圖像的分割,淺紫色區域(29)代表校巴類別
雙線性上采樣之后:
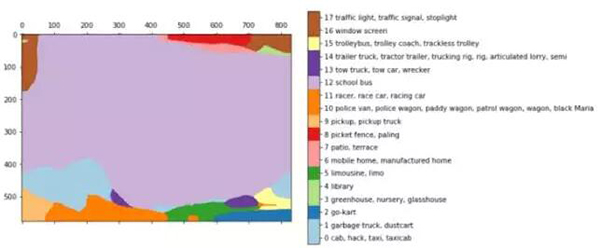
這些結果僅來自于簡單地將全連接層轉換(或者修改)為它最初的形態,修改它的空間特征,得到一個全連接的卷積神經網絡。在上面的例子中,我們把一張 768*1024 的圖像輸入到 VGG,然后就得到了 24*32*1000 的一個層,24*32 是圖像的池化版本,1000 是 image-net 的類別數目,從這里我們能夠得到上述的分割結果。
為了使預測結果更加平滑,研究者還使用了簡單的雙線性上采樣層。
在全連接神經網絡的論文中
(Fully Convolutional Networks for Semantic Segmentation,https://arxiv.org/abs/1411.4038),研究者提升了上述的想法。為了具有更加豐富的解釋,他們把一些層連接在一起,根據上采樣的比例,它們被命名為 FCN-32、FCN-16 和 FCN-8。
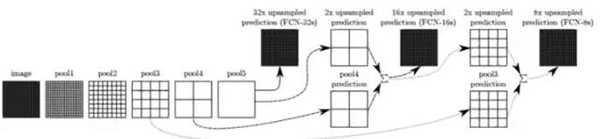
在層之間添加一些跳躍連接使得從原始圖像到編碼的預測更加精細。進一步訓練模型會讓結果更好。
這個技術表現出的效果并不像預料中的那么差勁,并且證明利用深度學習進行語義分割確實是有潛力的。

FCN 論文中全連接神經網絡的結果
全連接神經網絡開啟了分割的概念,研究者為這個任務嘗試了不同的架構。主要思想是類似的:使用已知的架構、上采樣以及使用跳躍連接,這些仍然在新模型中占據主要部分。
回到我們的項目
經過調研之后,我們選擇了三個合適的模型開始研究:FCN、Unet 以及 Tiramisu——這是一個非常深層的編碼器-解碼器架構。我們還在 mask-RCNN 上有一些想法,但是實現這個似乎不在我們這個項目的范圍之內。
FCN 看上去并不相關,因為它的結果和我們想要的結果(即便是初始點的結果)不一樣,但是我們提到的其他兩個模型卻表現出了不錯的結果:CamVid 數據集上的 tiramisu 模型和 Unet 模型主要的優點是緊湊性和速度。在實現方面,Unet 是相當直接的(使用 keras),并且 Tiramisu 也是可實現的。我們使用 Jeremy Howard 上一次的深度學習課程中對 Tiramisu 較好的實現來開始我們的項目。
我們使用這兩個模型開始在一些數據集上訓練。不得不說的是,當我第一次訓練完 Tiramisu 之后,發現它的結果對我們而言更有優勢,因為它有能力捕捉圖像中的尖銳邊緣,然而,Unet 看上去并不是那么好,甚至有一點搞笑。

Unet 的結果稍有遜色
數據
在利用模型設定好我們的基礎目標之后,我們就開始尋找合適的數據集。分割數據并不像分類和檢測那樣常見。此外,人工標注也不現實。最常用于分割的數據集是 COCO(http://mscoco.org/),這個數據集大約包括 8 萬張圖像(有 90 類),VOC pascal 數據集有 1.1 萬張圖像(有 20 類),以及更新的數據集 ADE20K。
我們選擇使用 COCO 數據集,因為其中「人」類的圖像更多,這恰好是我們的興趣所在。
考慮到我們的任務,我們思考是否僅僅使用和我們的任務超級相關的圖像,或者使用更加通用的數據集。一方面,一個更通用的數據集擁有更多的圖像和類別,這使得我們能夠應付更多的場景和挑戰。另一方面,一次徹夜不歇的訓練可以處理大約 15w 張的圖像。如果我們在整個 COCO 數據集上引入模型的話,結果會是,模型處理每張圖像的平均次數是 2 次,所以稍作修改是有益處的。此外,這會使得模型更聚焦于我們的目標。
另一件值得提及的事情是 Tiramisu 模型最初是在 CamVid 數據集上訓練的,它有一些缺陷,但最重要的是其圖像很單調:所有圖像都是道路上的車輛。你不難理解,從這樣的數據集中學習對我們的任務并沒有好處(即使圖像中包含了人物),所以在短暫的實驗之后,我們便改變了數據集。

CamVid 數據集中的圖像
COCO 數據集附帶相當直接的 API,這些 API 可以讓我們知道每一張圖像中是哪種類型的對象。
在一些實驗之后,我們決定稀釋一下數據集:首先我們過濾出其中有人的圖像,最終得到了 4 萬張。然后,丟棄了有很多人在里面的圖像,留下了只有一個或者兩個人的圖像,因為這是產品所需要的。最后,我們留下了 20%-70% 被標注為人的圖像,去掉那些在背景中有一小部分是人的圖像,還有那些具有奇怪的建筑的圖像也一并去掉了(不過不是所有的都去掉)。我們最終得到的數據集只有 1.1 萬張圖像,我們覺得在目前這個階段已經夠用了。
左:正常圖像;中:有太多東西的圖像;右:目標太小了
Tiramisu 模型
之前說過,我們使用了 Jeremy Howard 的課程中講述的 Tiramisu 模型。盡管它的名字「100 層 Tiramsiu」顯得它很龐大,但是實際上它卻是一個相當經濟的模型,僅僅有 900 萬個參數。相比之下,VGG-16 有 130M 個參數。
Tiramisu 模型是基于 DensNet 的,DensNet 是一個最新的圖像分類模型,所有的層都是相互連接的。此外,與 Unet 類似,Tiramisu 模型在上采樣層上添加了跳躍連接。
回想一下前文你就會發現,這個架構和 FCN 中呈現的思想是一致的:使用分類架構、上采樣并且為精調添加跳躍連接。

通用的 Tiramisu 架構
DenseNet 模型可以看作是一個自然進化的 Reset 模型,但是,DenseNet 不是簡單地把一層的信息「記憶到」下一層,而是在整個模型中記憶所有層。這些連接被稱作高速連接。它造成了過濾器數目的膨脹,這被定義為「增長率」。Tiramisu 的增長率是 16,所以我們會給每一層添加 16 個過濾器,直至到達具有 1072 個過濾器的那一層。你也許期望著具有 1600 個過濾器的那一層,因為這是 100 層的 Tiranisu,然而,上采樣會舍棄一些過濾器。
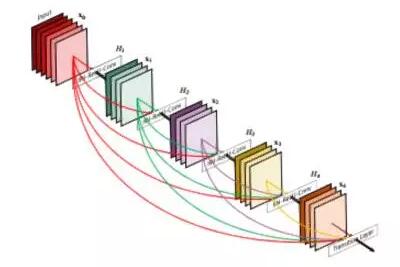
DenseNet 模型框架——在整個模型中,前邊層的過濾器是堆疊的
訓練
我們遵循原始論文中的計劃來訓練模型:標準交叉熵損失,學習率為 0.001 的 RMSProp 優化器,較小的衰減。我們將數據的 70% 用來訓練,20% 用來驗證,10% 用來測試。下面的所有圖像都來自我們的測試集。
為了讓我們的訓練過程與原始論文一致,我們把 epoch 大小設置為 500 張圖像。這也使得我們能夠在結果中的每一次進展中周期地保存模型,因為我們是在很大的數據上訓練模型的(那篇文章中用到的 CamVid 數據集僅有不到 1000 張圖像)。
此外,我們訓練的模型只有兩個類:背景和人物,然而那篇論文中的模型有 12 個類。我們首先嘗試著在部分 COCO 類上訓練,但是我們隨后就發現這對我們的訓練沒多大作用。
1. 數據問題
一些數據集的缺陷阻礙了我們模型的評分:
- 動物—我們的模型有時候會分割動物,這也自然導致了較低的 IOU,會將動物添加到我們的主要分類中。
- 身體部分—由于我們有計劃地過濾了我們的數據集,所以沒辦法區分圖像中的人是一個真實的人還是某個身體部位,例如手、腳。這些圖像雖然不在我們的考慮范圍之內,但是還是會處處出現。
動物、身體部分以及手持物體
手持物體——數據集中的很多圖像都是和運動相關的。到處都是棒球拍、羽毛球拍以及滑雪板。從某種程度來說,我們的模型已經困惑于應該如何分割它們。與動物的例子一樣,我們認為將它們添加到主分類或者獨立的分類中會對模型的性能有所幫助。
有一個物體的運動圖像
粗糙的真實情況——COCO 數據集中的很多圖像都不是按照像素標注的,而是用多邊形標注的。有時候這很好,但是其余時候真實情況過于粗糙,這可能會阻礙模型學習一些微妙的細節。

真實情況很粗糙的圖像
2. 結果
我們的結果是令人滿意的,盡管不太完美:我們在測試集上達到了 84.6 的 IoU,而當下最佳水平是 85。但是這個數字是微妙的:它會隨著不同的數據集和類別浮動,有的類別本身就很容易分割,例如房屋、道路,在這些例子中很多模型都能很容易地達到 90 的 IoU。其他的更具挑戰性的類別是樹和人物,在這些類別中很多模型只能達到大約 60 的 IoU。為了克服這個困難,我們幫助我們的網絡集中在某個單獨的類別上,并且在有限種類型的圖像中。
我們仍然沒有覺得我們的工作是「產品就緒」的,就像我們當初想讓它成為的樣子一樣,但是現在恰恰是停下來討論我們的結果的時間,因為在大約 50% 的圖像上都能給出較好的結果。
下面是一些很好的實例,給人的感覺就是一個不錯的應用。
")
圖像、真實數據、我們的結果(來自我們的測試集)
調試和日志
訓練神經網絡時非常重要的一部分就是調試。立馬開始是很吸引人的,得到數據和網絡,開始訓練,看一下會得到什么結果。然而我們會發現,追蹤每一個動作是非常重要的,這樣就能夠為我們自己創建能夠檢查每一步的結果的工具。
這里是一些常見的挑戰以及我們的應對方法:
- 前期問題—模型可能不能訓練。有可能是因為一些本質原因,或者是一些預處理的錯誤,例如忘記了標準化某些數據塊。無論如何,對結果的簡單可視化是很有幫助的。關于這個主題,這里有一篇博客(https://blog.slavv.com/37-reasons-why-your-neural-network-is-not-working-4020854bd607)。
- 調試網絡本身—在確定沒有關鍵問題之后,訓練通過預定義損失和指標開始。在分割中,主要舉措是 IoU——在聯合中交叉。把 IoU 作為模型(而不是交叉熵損失)的主要手段確實花了一些時間。另一個有幫助的實踐是在每個 epoch 展示一些模型的預測。這里有一篇調試機器學習模型的好文章(https://hackernoon.com/how-to-debug-neural-networks-manual-dc2a200f10f2)。注意,IoU 并不是 keras 中標準的指標/損失,但是你可以輕易在網上找到,比如這里(https://github.com/udacity/self-driving-car/blob/master/vehicle-detection/u-net/README.md)。我們還使用這個要點繪制損失和每個 epoch 的預測。
- 機器學習版本控制—在訓練一個模型的時候,會面臨很多參數,其中的一些是很微妙的。不得不說的是,除了熱切地寫下我們的配置(如下,使用 keras 的 callback 寫下最佳模型),我們仍然沒有發現完美的方法。
- 調試工具—在做完上述所有步驟之后,我們就可以逐步檢查我們的工作了,然而并不是無縫的,所以,最重要的就是把上述所有步驟結合在一起,創建一個 jupyter notebook 會讓我們無縫地加載每一個模型和每一張圖片,并且快速檢查結果。這樣的話我們就能容易地發現模型之間的不同、陷阱以及其他問題。
這里是我們通過調整參數和額外訓練之后得到的模型性能提升的例子:

保存目前驗證過程中的最佳模型:(keras 提供了一個非常好的 callback 函數,讓這一步驟變得容易多了)
- callbacks = [keras.callbacks.ModelCheckpoint(hist_model, verbose=1,save_best_only =True, monitor= ’val_IOU_calc_loss’), plot_losses]
除了對可能出現的代碼錯誤的正常調試之外,我們還注意到模型的錯誤是「可預測的」,就像把看似在正常身體之外的身體部分切掉一樣,大型分段上的「缺口」,非必要的擴展身體部分,糟糕的光照,低質量圖像,以及很多細節。其中的一些注意事項在從數據集中添加具體的圖片的時候就已經被處理了,但是其他的仍然是有待解決的難題。為了提升下一個版本的結果,我們會在「硬」圖像上為我們的模型使用具體的擴展。
我們在前面的數據集問題早就提到過這個問題。現在讓我們來了解一下我們模型中的困難吧:
1. 衣服—非常深色或者淺色的衣服容易被解釋為背景
2. 「缺口」—即使是好的結果,里面也會有缺口

衣服和缺口
3. 光照——較差的光照條件和模糊在圖像中是很常見的,然而 COCO 數據集中并不是這樣的,所以,除了模型要處理的這些事情中的正常困難以外,我們的模型甚至還沒有為更硬的圖像做準備。這可以通過得到更多的數據來解決,此外,最好不要在晚上使用我們的應用。

較差的光照條件的實例
進一步處理的選項
1. 進一步的訓練
我們的產品結果來自 300 個 epoch 的訓練。在這一階段之后,這個模型開始過擬合了。我們的這些結果已經非常接近發布的版本了,所以也不可能再去做數據擴增了。
在將圖像調整到 224*224 之后,我們開始訓練模型。使用更多更大的數據集進行進一步的訓練也有希望提升結果(原始尺寸是 COCO 數據集上的 600*1000 的圖像)。
2. CRF 和其他的增強
在某些階段,我們發現我們的結果在邊緣有一些噪聲。能夠精調這種問題的一個模型就是 CRF。在下面這篇博客中,作者展示了使用 CRF 的一個實例
(http://warmspringwinds.github.io/tensorflow/tf-slim/2016/12/18/image-segmentation-with-tensorflow-using-cnns-and-conditional-random-fields/)。
然而,這對我們的工作并不是很有用,也許是因為它通常在結果比較粗糙的時候才會奏效。
3. 摳圖
即便是我們現在的結果中,分割也不是完美的。頭發、衣服、樹枝和其他物體都不可能被完美地分割,甚至是因為實況中也沒有包含這些細節的標注。對這些片段的分割任務被稱作摳圖,這又是一個新的挑戰。這里是一個今年年初在 NVIDIA 的會議上發表的最先進的摳圖技術的例子
(https://news.developer.nvidia.com/ai-software-automatically-removes-the-background-from-images/)。

摳圖實例——輸入也包含 trimap
摳圖任務和其余圖像相關的任務是不一樣的,因為它的輸入不僅僅包含圖片,還有 trimap——也就是圖像邊緣的輪廓,這使得這個任務成為了一個「半監督」問題。
我們用摳圖做了一小部分實驗,使用我們的分割作為 trimap,然而并沒有得到顯著的結果。
另一個問題就是缺少一個用于訓練的合適的數據庫。
總結
正如剛開始的時候說到的一樣,我們的目標是開發一個有意義的深度學習產品。正如你在 Alon 的博客
(https://medium.com/@burgalon)中看到的一樣,部署總是快速且容易的。然而,訓練一個模型確實困難,尤其是在進行整夜的訓練時,需要仔細地計劃、調試和記錄結果。
做好調研、嘗試新事物以及平常的訓練和改進之間的平衡也是不容易的。因為我們使用深度學習,所以我們總是覺得最佳的模型或者是最準確的模型離我們很近,并且還覺得谷歌搜索或者論文會指引我們。但是,實際上,我們的實際提升僅僅來自于更多地壓榨原始模型。如上所述,我們仍舊覺得可以從原始模型中壓榨出更多的提升空間。
原文:
https://medium.com/towards-data-science/background-removal-with-deep-learning-c4f2104b3157
【本文是51CTO專欄機構“機器之心”的原創譯文,微信公眾號“機器之心( id: almosthuman2014)”】