跟Facebook學反欺詐 看CopyCatch算法如何搞定Lockstep
譯文【51CTO.com快譯】自從有互聯網以來,網絡上便流傳著各種垃圾和惡意信息。應對各種垃圾,作弊乃至欺詐信息成了各個互聯網公司必須解決的問題。特別是隨著各種社交網絡網站的興起,反作弊和互聯網安全成為了研究界和工業界都面臨的挑戰。各大互聯網公司都成立了專門的反作弊團隊,應對每天出現的反作弊情況。
反作弊中最常用到的技術之一就是圖論算法,反作弊問題經常可以歸約為圖論問題。例如可以利用 SVD 分解圖的鄰接矩陣的方法,還可以利用圖遍歷算法進行反欺詐檢驗。具體到金融領域,圖論算法可以用來進行風控和失聯修復方面的工作。
作為全球***的社交媒體網站,Facebook 一直在設法積極應對網站上的欺詐和作弊行為。CopyCatch 是 Facebook 2013 年發表在知名國際會議 WWW 上的反作弊論文,講述了 Facebook 處理一類叫作 Lockstep 欺詐行為的算法。
Lockstep 行為是指存在這樣的頁面,大量的用戶都在較短的時間窗口內給這個頁面點過贊。檢測 Lockstep 行為也就變成了檢測這樣的用戶和頁面的集合。下面我們就來看一下 Facebook 是如何設計反作弊算法的:
首先構建一個二部圖。二部圖的節點有兩類:一類是用戶,另一類是 Facebook 的頁面。當 Facebook 的用戶給某個頁面點贊時,便會在代表用戶的節點和代表頁面的節點之間構建一條邊。Lockstep 行為可以用如下數學公式來描述:

這個問題本身可以轉化為在二部圖中檢測二部核(Bipartite Core)的問題。檢測二部核問題本身是 NP-hard 問題,因此需要設計近似算法來解決這個問題。Facebook 把這個問題設計為***化問題。
首先重新定義一下問題描述:
的問題")
這個問題可以歸約為如下***化問題:
的問題")
其中 L 代表用戶點擊頁面的時間矩陣,c 是欺詐用戶發生欺詐行為的中心向量,而 P’ 是欺詐頁面集合。這個***化問題的實質是: 選擇聚類中心 c 和頁面子空間 P’ 來***化聚類中給定的時間窗口內用戶和用戶喜歡行為的數量。解決該問題采用迭代的算法,算法的***步是選定聚類中心 c ,算法的第二步是根據 c 來選定 P’。算法的框架如下所示:

其中 UpdateCenter 函數的流程如下:

UpdateCenter 函數的基本思想是在當前聚類中心的 范圍內重新選擇聚類中心,使得新的聚類中心能夠覆蓋更多的用戶和更多的點贊行為。
FindUsers 函數的流程如下:
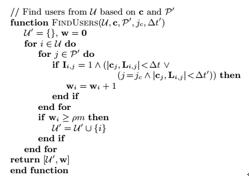
FindCenter 函數的流程如下:

FindCenter 函數的基本思想是將二部圖中與某個頁面關聯的用戶根據頁面點贊時間進行排序,然后考察在給定時間窗口內用戶子集合的點贊行為的***值。將新的聚類中心點設置為用戶子集合的中心。
UpdateSubspace 函數的流程如下:

UpdateSubspace 函數的基本思想是考察當前欺詐頁面子集合之外的頁面,看是否存在欺詐可能性更高的頁面(也就是關聯欺詐用戶是當前欺詐頁面對應用戶的超集),如果存在,則將當前頁面替換為新頁面。
作者提供了 Map-Reduce 版本如下:

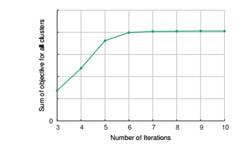
CopyCatch算法的收斂速度很快,在 Facebook 的數據集上大約10個迭代算法就可以收斂:
Facebook 的 CopyCatch 算法思路和實現均較為簡單, 并且經過線上運行確認算法效果滿足線上要求, 是非常優秀的算法。雖然算法發表距離今天已經有一段時間,但是仍然具有現實的參考意義。
CopyCatch 算法用到了圖論的相關知識。截至今天,圖論已被廣泛的應用在反欺詐/反作弊/信息安全等領域。熟練的掌握圖論相關知識已經成為大數據和人工智能從業者的必備技能。希望本文能夠給互聯網行業的相關從業者提供寶貴的經驗。
原文標題:CopyCatch : Stopping Group Attacks by Spotting Lockstep Behavior in Social Networks
作者:Alex Beutel , Wanhong Xu , Venkatesan Guruswami , Christopher Palow , Christos Faloutsos
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】