高達99.5%準確率,火眼金睛的“鑒黃系統”背后技術大揭秘
悟空鑒黃系統在京東上線已一年多,在京東云上提供接口也有數月,同時服務于京東主圖、曬單圖及京東公有云網站的圖片審核,并向外部提供通用鑒黃功能。
其中通用鑒黃算法在大于 99.5% 準確率下,可以節省 90% 以上的審核人工。主圖和曬單圖每日調用量超過千萬次,京東云相關每日調用量達到了數百萬次。
本篇將講解鑒黃問題的特點和難點,并為大家揭秘悟空鑒黃系統背后的技術。
圖像分類和鑒黃任務
圖像分類是計算機視覺中的基礎任務之一,悟空鑒黃系統背后的算法解決的就是一個分類問題,判斷待審核的圖像中包含的物體/內容屬于哪一類:
- 色情:露點,明顯性行為。
- 性感:非色情,但是暴露,或是帶有性暗示的肢體挑逗畫面。
- 其他:其他。
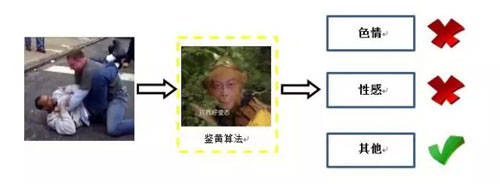
圖1:鑒黃算法流程示意
注:這里的“性感”和描述女神男神時的“性感”含義并不完全重合。
01鑒黃問題自身特有的難點
雖然看上去是個簡單的三分類問題,但是和常見的 MNIST/CIFAR/ImageNet 等分類任務不同,鑒黃問題有自身特有的難點:
多標簽數據
和 ImageNet 等單標簽數據集不同,鑒黃模型面對的圖片沒有特定類型,畫面中包含的物體也沒有限制。
比如穿著暴露的人和全裸露點的人物同時出現在畫面內,輸出的最終結果不能是色情+性感,而是判定為色情圖片。也就是說是個帶優先級的分類任務:色情>性感>其他。
非符號化(Non-iconic)圖像
在 ImageNet/CIFAR 等數據集中,圖像內容往往是比較明確的,比如下圖中第一行的狗和人物肖像,圖像信息明確,主題占比通常較大。而鑒黃任務中,面向的是真實場景中的圖像,包含大量的非符號化數據,比如下圖中第二行的例子。
在這種圖像中,哪怕是畫面中不引人注意的位置上,很小的一部分畫面出現了色情信息,也需要被判別為色情圖片。

圖2:Iconic 和 Non-iconic 圖片示意
數據特殊性
鑒黃任務中,色情和性感圖片在像素空間占據的只是很小的區域,其他類別占據了絕大部分像素空間。而在模型中,我們則是期望模型學習到的特征主要是和色情和性感圖片相關的特征。
在用于分類的特征空間中,因為其他類別圖片種類非常豐富,所以和色情/性感類別的分類邊界是難以捉摸的,另一方面色情/性感類別圖片因為常常很相似,所以分類邊界的求解非常有難度。
針對鑒黃問題的特點和難點,我們進行了一系列技術上的嘗試和探索,下面為大家一一道來。
02卷積神經網絡
在當前,卷積神經網絡(Convolutional Neural Network,CNN)已經成為幾乎所有圖像分類任務的標配。
早在 1989 年,Yann LeCun 就發明了卷積神經網絡,并且被廣泛應用于美國的很多銀行系統中,用來識別支票上的手寫數字。
2012 年,一個加強版的卷積神經網絡 AlexNet 在 ILSVRC 比賽中的圖像分類指標超越了基于傳統算法近 10 個百分點,自此卷積神經網絡就逐漸成了識別相關的計算機視覺任務中的標配。
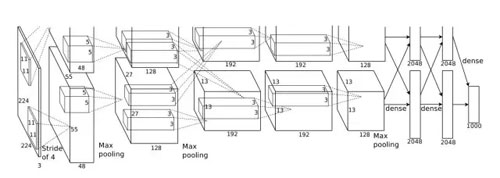
圖3:AlexNet
2014 年,Network in Network 被提出,1x1 卷積和 Global Pooling 被廣泛應用。
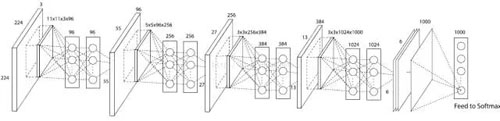
圖4:NIN
同年的 GoogLeNet 開始把“并聯”卷積路徑的方式發揚光大,并在 ILSVRC 中拿下了分類指標的冠軍。
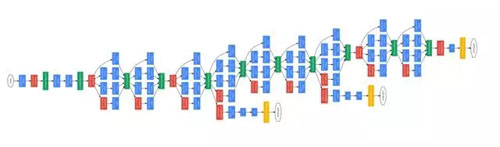
圖5:GoogLeNet
2015 年,為了解決深度網絡隨著層數加深性能卻退化的問題,當時還在 MSRA 的何愷明,提出了 Residual Block 并基于此和前人經驗推出了 ResNet 這個大殺器,在 ISLVRC 和 COCO 上橫掃了所有對手。
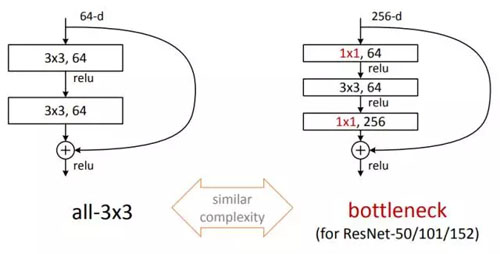
圖6:Residual Block
ResNet 雖然看上去更深了,直觀來理解其實是不同深度網絡的一個 ensemble,Cornell 的 Serge Belongie 教授專門用一篇論文討論了這個問題。
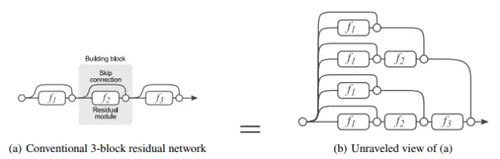
圖7:Residual Block 的 Ensemble 解釋
沿著這個思路,清華、Cornell 和 FAIR 在 2016 年合作提出了 DenseNet,并獲得了 2017 年 CVPR 的最佳論文。
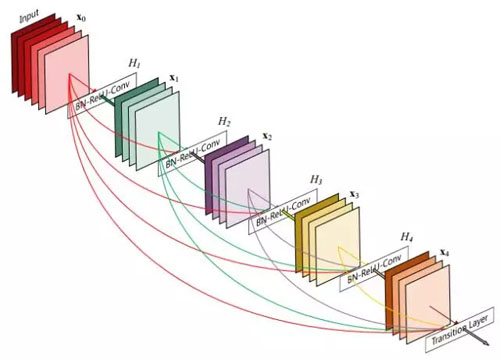
圖8:DenseNet
也有沿著 GoogLeNet 繼續把“并聯”卷積研究到極致的,同樣是發表在 CVPR2017 的 Xception。作者的觀點是,卷積核的維度和學習難度也直接相關,讓卷積響應圖之間去掉關聯,既能學習到沒有相關性的特征,還能降低卷積核學習的難度。
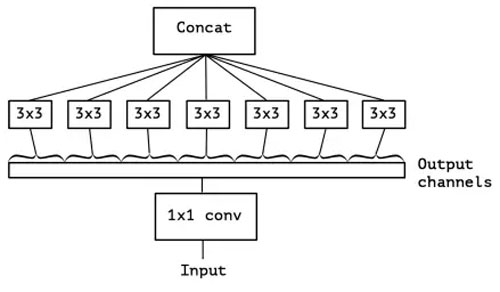
圖9:Xeception Depthwise Convolutions
總之研究者們在優化網絡結構的道路上還在繼續,不過從實用的角度看,越是復雜的網絡,訓練的難度也常常越高。
在鑒黃模型研發的長時間摸索中,我們發現 ResNet 是在訓練難度和模型性能上最平衡的一種結構。所以目前悟空鑒黃算法是在 ResNet 基礎上進行了優化和改進的一種結構。
03遷移學習
萬事開頭難,盡管網絡上的十八禁資源到處都是,數據的積累卻常常不是一蹴而就。在悟空系統的起步階段,遷移學習是快速得到可用模型的法寶之一。
具體到鑒黃算法上,我們的方法是基于其他經過大量數據訓練過的卷積神經網絡模型基礎上,利用有限的數據進行參數微調。
微調的思想是,在神經網絡中,特征是分層一步步組合的。低層參數學習的一般是線條,紋理,顏色等信息,再高一些的層學習到簡單圖案,形狀等,最高層的參數學習到的是由底層特征組合成的語義信息。
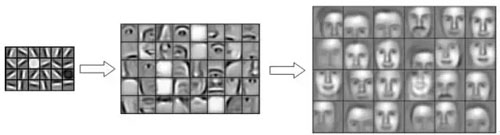
圖10:CNN 特征的分層表達示意
所以在不同任務中,低層的特征往往是差不多的,那么只需要改變高層的參數就可以在不同任務間最大化共享信息,并達到很好的泛化。
直觀來理解,色情圖片的檢測中,背景畫面部分就是一般的圖片,色情內容其實也是人,很多信息是和一般數據集,比如 ImageNet 數據共享的。
所以只需要學習到針對色情圖片的高層語義信息就可以用少量數據訓練一個良好泛化的模型。
為了實現微調,我們首先會找一個常見的基礎模型,比如 ImageNet 預訓練好的各種流行網絡結構。然后凍結低層參數的學習率,只讓模型高層和語義相關的參數在少量樣本上進行學習。
那么,怎么知道哪些層需要凍結,哪些層需要學習呢?我們探索過兩種基于可視化的辦法,一種是 2013 年 ILSVRC 分類冠軍 Matthew Zeiler 的 Deconvolution,通過從上至下的 Transposed Convolution 把響應圖和特定圖片中的相應區域關聯在一起,可以觀察響應圖激活對應的區域。

圖11:基于 Deconvolution 的卷積核可視化
不過這種方法實現較麻煩,而且需要對給定圖片進行觀察,有時候難以幫助發現模型本身的特點。
另一種方法是直接在圖像空間上以最大化激活特定卷積核得到的響應圖作為目標(Activation Maximization),對輸入圖像進行優化,看最后得到的圖案,這種方法最早是 Bengio 組在 2009 年的一個 Tech report:《Visualizing Higher-Layer Features of a Deep Network》,后來被用到了很多地方,包括可視化、對抗樣本生成和 DeepDream。

圖12:基于激活最大化的卷積層可視化
這個方法的優點是簡單易操作,缺點是圖像常常看不出是什么,有時需要腦補。所以即使有了可視化手段的輔助,決定如何微調參數仍是個經驗活,如果機器資源足夠可以寫個腳本自動訓練所有可能情況進行暴力搜索。
除了基于圖像分類模型,VOC 和 COCO 等數據集訓練出的檢測模型的網絡也是很好的微調基礎。
檢測和分類雖然是不同的任務,但關系十分緊密,尤其是鑒黃應用中,露點是決定是否色情的關鍵標準之一,而露出的“點”是個位置屬性很強的信息。
在悟空鑒黃研發的過程中,我們也基于遷移學習的思想,嘗試了很多分類和檢測結合的手段,對最終模型的效果也起到了很大的促進。
04類別響應圖可視化
當一個模型訓練好之后,為了提升指標,我們會探索一些模型本身的特性,然后做針對性的改進,可視化是這一步驟中最常見的手段之一。
上一部分中,已經提到了激活最大化的方法,在訓練好的模型中,這也是非常有效的一個手段。
舉個例子,對于 ImageNet 訓練出的模型,如果我們對啞鈴進行激活最大化的可視化,會看到下面的圖像:

圖13:ImageNet 預訓練模型中啞鈴類別的最大激活圖像
除了啞鈴,還會出現手,而手并不是目標的特征。在黃圖中,比如某類數據中露點的部位 A(例:大長腿)常常伴隨著一個其他特定圖案 B(例:露點)出現,就會發生類似的情況。
這樣的后果是一些沒有包含露點部位 A 的正常圖片,因為包含了特定圖案 B,就會有被誤判為色情圖片的傾向。通過可視化的手段,如果發現了這樣的情形,就可以在數據層面進行改進,讓真正 A 的特征被學習到。
從直觀角度講,基于激活最大化的方法并不是很好,所以更常用的一個辦法是類別激活響應圖(Class Activation Map,CAM)。
CAM 自從 NIN 中提出 1x1 卷積和 Global Pooling 就被很多人使用過,不過第一次比較明確的探討是在 MIT 的 Bolei Zhou 的論文《Learning Deep Features for Discriminative Localization》中。
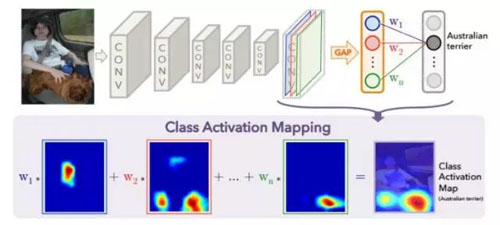
圖14:類別激活響應圖
這種方法的基本思想是把 Global Pooling 之后,特定類別的權重應用在 pooling 之前的 feature channel上,然后按照像素加權求和,得到該類別激活在不同位置上的響應。
這種方法非常直觀地告訴我們,當前類別中圖像的哪些部分是主要的激活圖案。在分析模型的漏檢和誤檢樣本的時候,我們通過這種方法分析模型對圖像中人一眼就能識別的圖案是否敏感,決定改進模型時更新數據的策略。
05Loss Function
一般來說,我們在進行機器學習任務時,使用的每一個算法都有一個目標函數,算法便是對這個目標函數進行優化,特別是在分類或者回歸任務中,便是使用損失函數(Loss Function)作為其目標函數,又稱為代價函數(Cost Function)。
損失函數是用來評價模型的預測值 Y^=f(X) 與真實值 Y 的不一致程度,它是一個非負實值函數。通常使用 L(Y,f(x)) 來表示,損失函數越小,模型的性能就越好。
設總有 N 個樣本的樣本集為 (X,Y)=(xi,yi),yi,i∈[1,N] 為樣本i的真實值,yi^=f(xi),i∈[1,N] 為樣本 i 的預測值,f 為分類或者回歸函數。那么總的損失函數為:
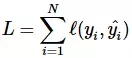
選擇一個合適的損失函數,是成功訓練一個深度學習模型的關鍵,也是機器學習從業者研究和專注改進的目標。
各種各樣的損失函數層出不窮,其中包括:適用于訓練回歸任務的歐式距離損失函數(Euclidean Loss),適用于 Siamese 網絡的對比損失函數(Contrastive loss),適用于一對多分類任務的鉸鏈損失函數(Hinge Loss),預測目標概率分布的 Sigmoid 交叉熵損失函數(Sigmoid Cross Entropy Loss),信息增益損失函數(InformationGain Loss),多項式邏輯損失函數(Multinomial Logistic Loss),Softmax損失函數 (SoftmaxWithLoss) 等等。
TripletLoss 是一種基于歐式距離的損失函數,自從 Google 提出后,在人臉識別等領域得到了廣泛應用。
優化 TripletLoss 時,算法盡量減小正樣例對的歐氏距離,增大負樣例對的歐式距離。廣為人知的是,基于歐式距離的分類,對銳化圖像和模糊圖像缺少區分能力。
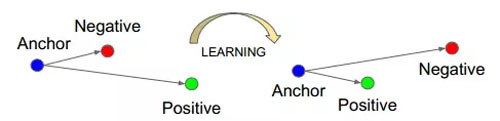
圖15:Triplet 訓練示意
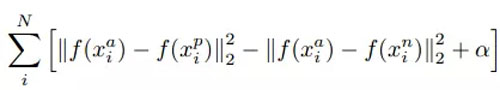
SoftmaxWithLoss 是深度學習分類任務中最常用的損失函數,softmax 采用了連續函數來進行函數的逼近,最后采用概率的形式進行輸出,這樣弱化了歐氏距離損失函數帶來的問題。
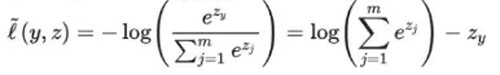
對抗樣本及 GAN 在鑒黃算法中的應用
在鑒黃算法的研發過程中,我們也做了一些在學術界前沿和熱門算法落地的嘗試,主要包括對抗訓練和生成式對抗網絡。
01對抗樣本和對抗訓練
對抗樣本是指專門針對模型產生的讓模型失敗的樣本。深度學習雖然在圖像分類任務上大幅超越了其他各種算法,但是作為一種非局部泛化的參數模型,卻是非常容易被攻擊的模型。
比如一幅圖,加上一個針對模型產生的攻擊“噪聲”之后,就會被以非常高的置信度分為錯誤的類別。

圖16:攻擊樣本示意
![]()
對抗樣本實際上會對模型的分類邊界進行改善,在悟空鑒黃算法的研發中,我們引入了對抗訓練,來提高模型的泛化性。
02生成式對抗網絡(GAN)簡介
生成式對抗網絡是 2017 年視覺和機器學習領域的絕對熱點。生成式對抗網絡包含兩部分,一個是用于生成樣本的生成式模型 G,另一個是用于區分生成樣本和真實樣本的判別模型 D。
從思想上來說,生成模型的思路是讓一個簡單分布(比如多維高斯分布)經過模型的變換生成一個較為復雜的分布,這個分布要盡量逼近目標數據的分布,這樣就可以利用生成模型得到目標數據的樣本了。
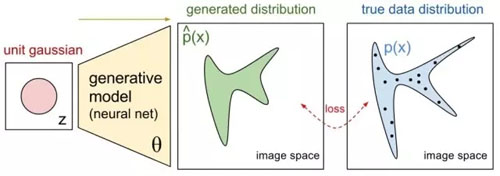
圖17:生成式模型示意
所以目標是要讓兩個分布貼近,最基礎的想法就是學習參數讓樣本似然最大,比如 MLE;或者變換另一個思路,讓兩個分布的差異盡量小,GAN 就屬于這一類。
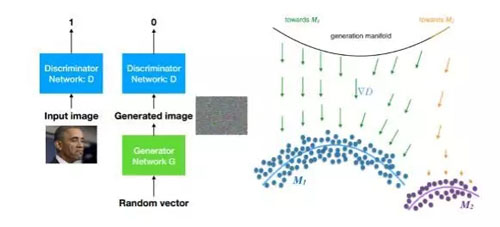
圖18:GAN 示意
GAN 中由 G 產生的樣本會盡量朝著數據所在的流形貼近,目標是讓 D 分不出來,而 D 也會在每次訓練中讓自身能力提升,盡量區分哪些樣本是真實的、哪些是 G 產生的,相當于一個零和博弈,這就是對抗的由來。
理想情況下,最后 D 再也無法提升,G 學習到真實的數據分布,并且和輸入分布所在空間建立一種對應。
03半監督學習
具體到鑒黃算法中,GAN 的作用主要體現在通過改善數據的分類邊界,對少量類型數據的提升。
吳恩達提到過,深度學習中,算法是引擎,數據是燃料。雖然現在悟空鑒黃系統已經達到千萬級海量數據,但是數據總是越多越好,并且對于有些特定類型的數據,數量未必高到可以單純訓練就達到很好效果。這種情況下,半監督學習是改善模型性能的一個選項。
2016 年,在鑒黃算法研發初期,我們就嘗試過用 GAN 學習特定類別的數據,并生成數據,作為偽色情和偽性感類別加入到模型當中進行更多類別的半監督模型訓練,使用的時候再拋棄偽類別。
定性來看,在數據很少的時候,每個類別之間的分類邊界會非常粗糙,傾向于“原理”數據所在的流形,而用 GAN 生成的數據中,和真實數據有一定的相似性(紋理,局部圖案),肉眼卻一眼就能分辨不同于真實數據(因為目前非條件 GAN 只能生成一些簡單數據比如人臉、火山、星球等)。
這相當于產生了一批更靠近真實數據的偽數據,讓判別器學習真實數據和這種數據之間的分類邊界就可以讓邊界離真實數據靠的更近。數據量少的時候,這種方法能帶來非常大的泛化性能提高。
不過需要注意的是這種方法有個假設:G 網絡不能生成很完美的圖像,否則 G 網絡就相當于一個數據發生器,會導致分類網絡崩潰。后來和我們做法類似的方法開始出現在論文里,比如NVIDIA的《Semi-Supervised Learning with Generative Adversarial Networks》。
04數據的模擬和生成
在鑒黃算法的研發中,我們也嘗試了一些看上去比較超前的算法,比如 Image-to-Image Translation。
鑒黃問題中色情和性感類別因為有很高的相似性是非常難區分的,比如一個險些露點的圖片就是性感類別,而一旦露點了,即使畫面其他部分幾乎一樣,也是色情類別。
為了針對這種情況提高準確率,我們的思路如果能生成圖片對,一幅是色情一幅是性感,就可以針對這樣的圖片對進行訓練,達到對色情/性感類別更強的分類能力。
沿著這個思路,我們嘗試了 UC Berkeley 發表的 Pix2Pix:《Image-to-Image Translation with Conditional Adversarial Networks》和 Cycle-GAN:《Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks》。
利用 Pix2Pix,我們可以把帶馬賽克的圖片(標注為性感)中的馬賽克去掉(標注為色情)。Pix2Pix 其實就是一種單純的對圖像進行變換的 CNN 結構,模型的訓練上就是把圖片配好對,訓練輸入圖片盡量生成和輸出差不多的圖片。
傳統的類似結構中,都是用重建誤差來作為訓練目標,不過基于重建誤差的目標往往會導致重建的圖片非常模糊,而 GAN 中的 Adversarial loss 正好可以解決模糊問題,所以被廣泛應用于需要生成豐富細節的圖像的應用,Pix2Pix 是其中之一。
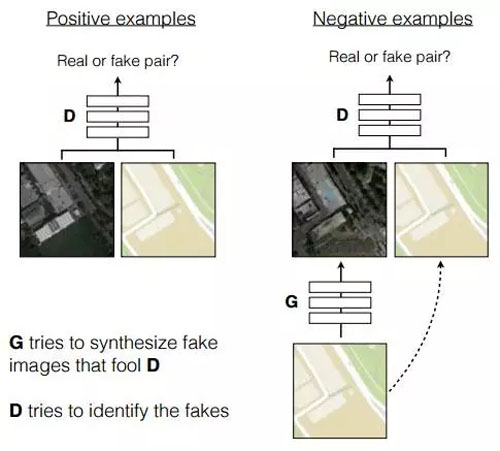
圖19:Pix2Pix
Pix2Pix 去除馬賽克的效果大致貼出來大家感受一下(左邊是馬賽克圖片,右邊是 Ground Truth,中間是模型生成圖片):
圖20:Pix2Pix 去除馬賽克效果展示
帶馬賽克的圖片算是比較小眾的一種圖像,在實際場景中未必會對模型有很大幫助,如果能有穿衣服-不穿衣服的圖像對,對泛化能力的提升應該會更有意義,所以我們又嘗試了 Cycle-GAN。
Cycle-GAN 其實也只是用到了 Adversarial loss,和生成模型沒什么關系,主要的貢獻還是把對偶學習結合 Adversarial loss 用到了圖像翻譯上。
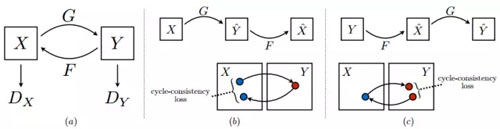
在 Cycle-GAN 中,每一次訓練會把一個 domain 中的圖像翻譯到另一個 domain,然后在翻譯回來,并檢查一致性,同時每次被翻譯的圖像是否和該 domain 真實樣本可區分,通過 adversarial loss 實現:
最后穿衣服的效果如下(左圖馬賽克為手動加上):
圖21:Cycle-GAN 穿衣服效果展示
因為生成圖片的成功率較低,最后并沒有應用到實際的訓練中。不過隨著整個 AI 領域技術的不斷進步,各種開腦洞的辦法會越來越多,我們也會持續探索和改進,讓我們的鑒黃算法更加準確、高效和可靠,成為真正的“火眼金睛”。