從算法實(shí)現(xiàn)到MiniFlow實(shí)現(xiàn),打造機(jī)器學(xué)習(xí)的基礎(chǔ)架構(gòu)平臺(tái)
現(xiàn)到MiniFlow實(shí)現(xiàn),打造機(jī)器學(xué)習(xí)的基礎(chǔ)架構(gòu)平臺(tái)")
基礎(chǔ)架構(gòu)(Infrastructure)相比于大數(shù)據(jù)、云計(jì)算、深度學(xué)習(xí),并不是一個(gè)很火的概念,甚至很多程序員就業(yè)開(kāi)始就在用 MySQL、Django、Spring、Hadoop 來(lái)開(kāi)發(fā)業(yè)務(wù)邏輯,而沒(méi)有真正參與過(guò)基礎(chǔ)架構(gòu)項(xiàng)目的開(kāi)發(fā)。在機(jī)器學(xué)習(xí)領(lǐng)域也是類(lèi)似的,借助開(kāi)源的 Caffe、TensorFlow 或者 AWS、Google CloudML 就可以實(shí)現(xiàn)諸多業(yè)務(wù)應(yīng)用,但框架或平臺(tái)可能因行業(yè)的發(fā)展而流行或者衰退,而追求高可用、高性能、靈活易用的基礎(chǔ)架構(gòu)卻幾乎是永恒不變的。
Google 的王詠剛老師在《為什么 AI 工程師要懂一點(diǎn)架構(gòu)》提到,研究院并不能只懂算法,算法實(shí)現(xiàn)不等于問(wèn)題解決,問(wèn)題解決不等于現(xiàn)場(chǎng)問(wèn)題解決,架構(gòu)知識(shí)是工程師進(jìn)行高效團(tuán)隊(duì)協(xié)作的共同語(yǔ)言。Google 依靠強(qiáng)大的基礎(chǔ)架構(gòu)能力讓 AI 研究領(lǐng)先于業(yè)界,工業(yè)界的發(fā)展也讓深度學(xué)習(xí)、Auto Machine Learning 成為可能,未來(lái)將有更多人關(guān)注底層的架構(gòu)與設(shè)計(jì)。
因此,今天的主題就是介紹機(jī)器學(xué)習(xí)的基礎(chǔ)架構(gòu),包括以下的幾個(gè)方面:
- 基礎(chǔ)架構(gòu)的分層設(shè)計(jì);
- 機(jī)器學(xué)習(xí)的數(shù)值計(jì)算;
- TensorFlow 的重新實(shí)現(xiàn);
- 分布式機(jī)器學(xué)習(xí)平臺(tái)的設(shè)計(jì)。
***部分,基礎(chǔ)架構(gòu)的分層設(shè)計(jì)
大家想象一下,如果我們?cè)?AWS 上使用編寫(xiě)一個(gè) TensorFlow 應(yīng)用,究竟經(jīng)過(guò)了多少層應(yīng)用抽象?首先,物理服務(wù)器和網(wǎng)絡(luò)寬帶就不必說(shuō)了,通過(guò) TCP/IP 等協(xié)議的抽象,我們直接在 AWS 虛擬機(jī)上操作就和本地操作沒(méi)有區(qū)別。其次,操作系統(tǒng)和編程語(yǔ)言的抽象,讓我們可以不感知底層內(nèi)存物理地址和讀寫(xiě)磁盤(pán)的 System call,而只需要遵循 Python 規(guī)范編寫(xiě)代碼即可。然后,我們使用了 TensorFlow 計(jì)算庫(kù),實(shí)際上我們只需調(diào)用最上層的 Python API,底層是經(jīng)過(guò)了 Protobuf 序列化和 swig 進(jìn)行跨語(yǔ)言調(diào)研,然后通過(guò) gRPC 或者 RDMA 進(jìn)行通信,而***層這是調(diào)用 Eigen 或者 CUDA 庫(kù)進(jìn)行矩陣運(yùn)算。
因此,為了實(shí)現(xiàn)軟件間的解耦和抽象,系統(tǒng)架構(gòu)常常采用分層架構(gòu),通過(guò)分層來(lái)屏蔽底層實(shí)現(xiàn)細(xì)節(jié),而每一個(gè)底層都相當(dāng)于上層應(yīng)用的基礎(chǔ)架構(gòu)。
那么我們?nèi)绾卧谝粋€(gè)分層的世界中夾縫生存?
有人可能認(rèn)為,既然有人實(shí)現(xiàn)了操作系統(tǒng)和編程語(yǔ)言,那么我們還需要關(guān)注底層的實(shí)現(xiàn)細(xì)節(jié)嗎?這個(gè)問(wèn)題沒(méi)有標(biāo)準(zhǔn)答案,不同的人在不同的時(shí)期會(huì)有不同的感受,下面我舉兩個(gè)例子。
在《為了 1% 情形,犧牲 99% 情形下的性能:蝸牛般的 Python 深拷貝》這篇文章中,作者介紹了 Python 標(biāo)準(zhǔn)庫(kù)中 copy.deep_copy() 的實(shí)現(xiàn),1% 的情況是指在深拷貝時(shí)對(duì)象內(nèi)部有可能存在引用自身的對(duì)象,因此需要在拷貝時(shí)記錄所有拷貝過(guò)的對(duì)象信息,而 99% 的場(chǎng)景下對(duì)象并不會(huì)直接應(yīng)用自身,為了兼容 100% 的情況這個(gè)庫(kù)損失了 6 倍以上的性能。在深入了解 Python 源碼后,我們可以通過(guò)實(shí)現(xiàn)深拷貝算法來(lái)解決上述性能問(wèn)題,從而優(yōu)化我們的業(yè)務(wù)邏輯。
另一個(gè)例子是阿里的楊軍老師在 Strata Data Conference 分享的《Pluto: 一款分布式異構(gòu)深度學(xué)習(xí)框架》,里面介紹到基于 TensorFlow 的 control_dependencies 來(lái)實(shí)現(xiàn)冷熱數(shù)據(jù)在 GPU 顯存上的置入置出,從而在用戶幾乎不感知的情況下極大降低了顯存的使用量。了解源碼的人可能發(fā)現(xiàn)了,TensorFlow 的 Dynamic computation graph,也就是 tensorflow/fold 項(xiàng)目,也是基于 control_dependencies 實(shí)現(xiàn)的,能在聲明式機(jī)器學(xué)習(xí)框架中實(shí)現(xiàn)動(dòng)態(tài)計(jì)算圖也是不太容易。這兩種實(shí)現(xiàn)都不存在 TensorFlow 的官方文檔中,只有對(duì)源碼有足夠深入的了解才可能在功能和性能上有巨大的突破,因此如果你是企業(yè)內(nèi) TensorFlow 框架的基礎(chǔ)架構(gòu)維護(hù)者,突破 TensorFlow 的 Python API 抽象層是非常有必要的。
大家在應(yīng)用機(jī)器學(xué)習(xí)時(shí),不知不覺(jué)已經(jīng)使用了很多基礎(chǔ)架構(gòu)的抽象,其中最重要的莫過(guò)于機(jī)器學(xué)習(xí)算法本身的實(shí)現(xiàn),接下來(lái)我們將突破抽象,深入了解底層的實(shí)現(xiàn)原理。
第二部分,機(jī)器學(xué)習(xí)的數(shù)值計(jì)算
機(jī)器學(xué)習(xí),本質(zhì)上是一系列的數(shù)值計(jì)算,因此 TensorFlow 定位也不是一個(gè)深度學(xué)習(xí)庫(kù),而是一個(gè)數(shù)值計(jì)算庫(kù)。當(dāng)我們聽(tīng)到了香農(nóng)熵、貝葉斯、反向傳播這些概念時(shí),并不需要擔(dān)心,這些都是數(shù)學(xué),而且可以通過(guò)計(jì)算機(jī)編程實(shí)現(xiàn)的。
接觸過(guò)機(jī)器學(xué)習(xí)的都知道 LR,一般是指邏輯回歸(Logistic regression),也可以指線性回歸(Linear regression),而前者屬于分類(lèi)算法,后者屬于回歸算法。兩種 LR 都有一些可以調(diào)優(yōu)的超參數(shù),例如訓(xùn)練輪數(shù)(Epoch number)、學(xué)習(xí)率(Learning rate)、優(yōu)化器(Optimizer)等,通過(guò)實(shí)現(xiàn)這個(gè)算法可以幫忙我們理解其原理和調(diào)優(yōu)技巧。
下面是一個(gè)最簡(jiǎn)單的線性回歸 Python 實(shí)現(xiàn),模型是簡(jiǎn)單的 y = w * x + b。
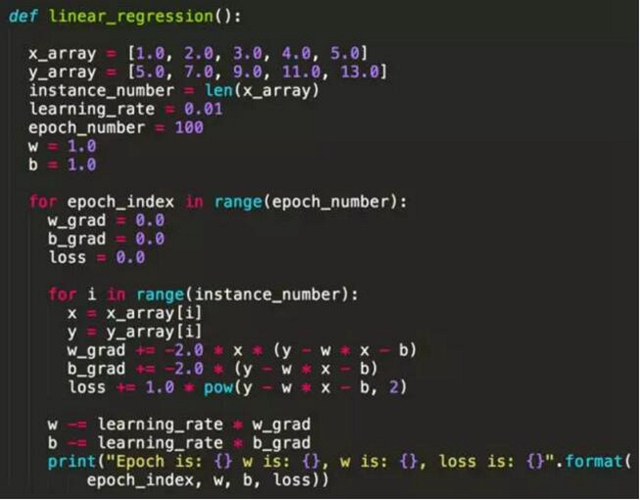
從這個(gè)例子大家可以看到,實(shí)現(xiàn)一個(gè)機(jī)器學(xué)習(xí)算法并不依賴于 Scikit-learn 或者 TensorFlow 等類(lèi)庫(kù),本質(zhì)上都是數(shù)值運(yùn)算,不同語(yǔ)言實(shí)現(xiàn)會(huì)有性能差異而已。細(xì)心的朋友可能發(fā)現(xiàn),為什么這里 w 的梯度(Gradient)是 -2 * x * (y – x * x –b),而 b 的梯度這是 -2 * (y – w * x – b),如何保證經(jīng)過(guò)計(jì)算后 Loss 下降而準(zhǔn)確率上升?這就是數(shù)學(xué)上保證了,我們定義了 Loss 函數(shù)(Mean square error)為 y – w * x – b 的平方,也就是說(shuō)預(yù)測(cè)值越接近 y 的話 Loss 越小,目標(biāo)變成求 Loss 函數(shù)在 w 和 b 的任意取值下的最小值,因此對(duì) w 和 b 求偏導(dǎo)后就得到上面兩條公式。
如果感興趣,不妨看一下線性回歸下 MSE 求偏導(dǎo)的數(shù)學(xué)公式證明。

邏輯回歸與線性回歸類(lèi)似,當(dāng)由于是分類(lèi)問(wèn)題,因此需要對(duì) w * x + b 的預(yù)測(cè)結(jié)果進(jìn)行歸一化(Normalization),一般使用 Sigmoid 方法,在 Python 中可以通過(guò) 1.0 / (1 + numpy.exp(-x)) 這種方式實(shí)現(xiàn)。由于預(yù)測(cè)值不同,Loss 函數(shù)的定義也不同,求偏導(dǎo)得到的數(shù)值計(jì)算公式也不同,感興趣也可以看看我的公式推導(dǎo)。


大家可以看到最終求得的偏導(dǎo)是非常簡(jiǎn)單的,用任何編程語(yǔ)言都可以輕易實(shí)現(xiàn)。但我們自己的實(shí)現(xiàn)未必是***效的,為什么不直接用 Scikit-learn、MXNet 這些開(kāi)源庫(kù)已經(jīng)實(shí)現(xiàn)好的算法呢?
我們對(duì)這個(gè)算法的理解,其實(shí)是在工程上使用它的一個(gè)很重要的基礎(chǔ)。例如在真實(shí)的業(yè)務(wù)場(chǎng)景下,一個(gè)樣本的特征可能有百億甚至千億維,而通過(guò)前面的算法我們了解到,LR 模型的大小和樣本特征的維度是相同的,也就是說(shuō)一個(gè)接受百億維特征的模型,本身參數(shù)就有百億個(gè),如果使用標(biāo)準(zhǔn)的雙精度浮點(diǎn)數(shù)保存模型參數(shù),那么百億維的模型參數(shù)部分至少要超過(guò) 40G,那么千億維的特征更是單機(jī)所無(wú)法加載的。
因此,雖然 Scikit-learn 通過(guò) native 接口實(shí)現(xiàn)了高性能的 LR 算法,但只能滿足在單機(jī)上訓(xùn)練,而 MXNet 由于原生沒(méi)有支持 SpareTensor,對(duì)于超高維度的稀疏數(shù)據(jù)訓(xùn)練效率是非常低的,TensorFlow 本身支持 SpareTensor 也支持模型并行,可以支持百億維特征的模型訓(xùn)練,但沒(méi)有針對(duì) LR 優(yōu)化效率也不是很高。在這種場(chǎng)景下,第四范式基于 Parameter server 實(shí)現(xiàn)了支持模型并行和數(shù)據(jù)并行的超高維度、高性能機(jī)器學(xué)習(xí)庫(kù),在此基礎(chǔ)上的大規(guī)模 LR、GBDT 等算法訓(xùn)練效率才能滿足工程上的需求。
機(jī)器學(xué)習(xí)還有很多有意思的算法,例如決策樹(shù)、SVM、神經(jīng)網(wǎng)絡(luò)、樸素貝葉斯等等,只需要部分?jǐn)?shù)學(xué)理論基礎(chǔ)就可以輕易在工程上實(shí)現(xiàn),由于篇幅關(guān)系這里就不在贅述了。前面我們介紹的其實(shí)是機(jī)器學(xué)習(xí)中的命令式(Imperative)編程接口,我們把求偏導(dǎo)的公式提前推導(dǎo)出來(lái),然后像其他編程腳本一樣根據(jù)代碼那順序執(zhí)行,而我們知道 TensorFlow 提供的是一種聲明式(Declarative)的編程接口,通過(guò)描述計(jì)算圖的方式來(lái)延后和優(yōu)化執(zhí)行過(guò)程,接下來(lái)我們就介紹這方面的內(nèi)容。
第三部分,TensorFlow 的重新實(shí)現(xiàn)
首先大家可能有疑問(wèn),我們需要需要重新實(shí)現(xiàn) TensorFlow?TensorFlow 靈活的編程接口、基于 Eigen 和 CUDA 的高性能計(jì)算、支持分布式和 Hadoop HDFS 集成,這些都是個(gè)人甚至企業(yè)很難完全追趕實(shí)現(xiàn)的,而且即使需要命令式編程接口我們也可以使用 MXNet,并沒(méi)有強(qiáng)需求需要一個(gè)新的 TensorFlow 框架。
事實(shí)上,我個(gè)人在學(xué)習(xí) TensorFlow 過(guò)程中,通過(guò)實(shí)現(xiàn)一個(gè) TensorFlow-like 的項(xiàng)目,不僅驚嘆與其源碼和接口的設(shè)計(jì)精巧,也加深了對(duì)聲明式編程、DAG 實(shí)現(xiàn)、自動(dòng)求偏導(dǎo)、反向傳播等概念的理解。甚至在 Benchmark 測(cè)試中發(fā)現(xiàn),純 Python 實(shí)現(xiàn)的項(xiàng)目在線性回歸模型訓(xùn)練中比 TensorFlow 快 22 倍,當(dāng)然這是在特定場(chǎng)景下壓測(cè)得到的結(jié)果,主要原因是 TensorFlow 中存在 Python 與 C++ 跨語(yǔ)言的切換開(kāi)銷(xiāo)。
這個(gè)項(xiàng)目就是 MiniFlow,一個(gè)實(shí)現(xiàn)了鏈?zhǔn)椒▌t、自動(dòng)求導(dǎo)、支持命令式編程和聲明式編程的數(shù)值計(jì)算庫(kù),并且兼容 TensorFlow Python API。感興趣可以在這個(gè)地址參與開(kāi)發(fā),下面是兩者 API 對(duì)比圖。

了解 TensorFlow 和 MXNet(或者 NNVM)源碼的朋友可能知道,兩者都抽象了 Op、Graph、Placeholer、Variable 等概念,通過(guò) DAG 的方式描述模型的計(jì)算流圖,因此我們也需要實(shí)現(xiàn)類(lèi)似的功能接口。
與前面的 LR 代碼不同,基于 Graph 的模型允許用戶自定義 Loss 函數(shù),也就是用戶可以使用傳統(tǒng)的 Mean square error,也可以自定義一個(gè)任意的數(shù)學(xué)公式作為 Loss 函數(shù),這要求框架本身能夠?qū)崿F(xiàn)自動(dòng)求導(dǎo)的功能,而不是我們根據(jù) Loss 函數(shù)預(yù)先實(shí)現(xiàn)了導(dǎo)數(shù)的計(jì)算方式。
那么用戶可以定義的最小操作,也就是 Op,需要平臺(tái)實(shí)現(xiàn)基本的算子,例如 ConstantOp、AddOp、MultipleOp 等,而且用戶實(shí)現(xiàn)自定義算子時(shí)可以加入自動(dòng)求導(dǎo)的流程中,并不影響框架本身的訓(xùn)練流程。參考 TensorFlow 的 Python 源碼,下面我們定義了 Op 的基類(lèi),所有的 Op 都應(yīng)該實(shí)現(xiàn) forward() 和 grad() 以便于模型訓(xùn)練時(shí)自動(dòng)求導(dǎo),而且通過(guò)重載 Python 操作符可以為開(kāi)發(fā)者提供更便利的使用接口。
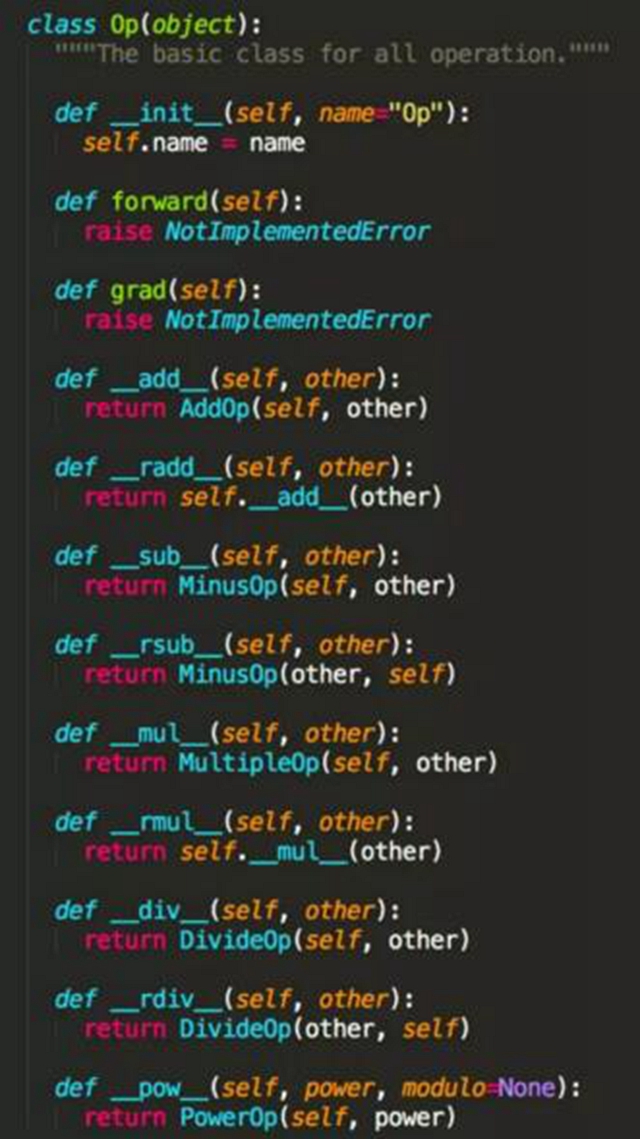
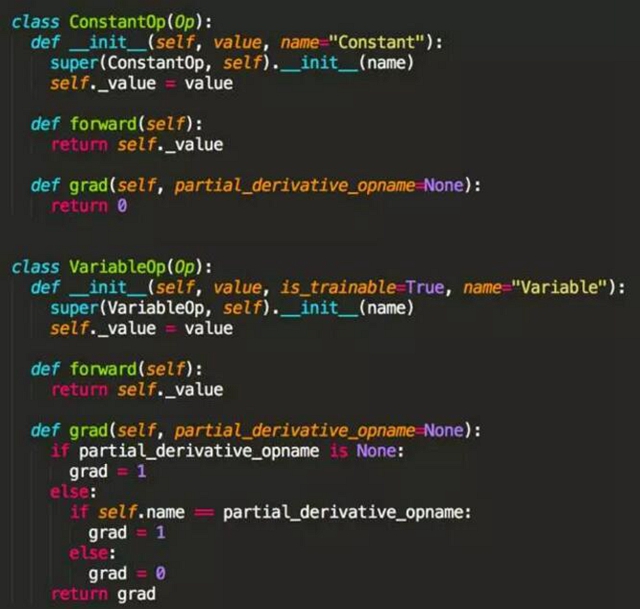
那么對(duì)于常量(ConstantOp)和變量(VariableOp),他們的正向運(yùn)算就是得到的是本身的值,而求導(dǎo)時(shí)常量的導(dǎo)數(shù)為 0,求偏導(dǎo)的變量導(dǎo)數(shù)為 1,其他變量也為 0,具體代碼如下。
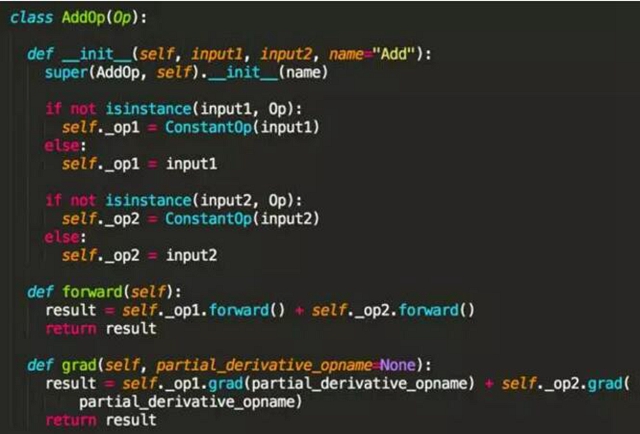
其實(shí)更重要的是,我們需要實(shí)現(xiàn)加(AddOp)、減(MinusOp)、乘(MultipleOp)、除(DivideOp)、平方(PowerOp)等算子的正向運(yùn)算和反向運(yùn)算邏輯,然后根據(jù)鏈?zhǔn)椒▌t,任何復(fù)雜的數(shù)學(xué)公式求導(dǎo)都可以簡(jiǎn)化成這些基本算子的求導(dǎo)。
例如加法和減法,我們知道兩個(gè)數(shù)加法的導(dǎo)數(shù)等于導(dǎo)數(shù)的加法,因此根據(jù)此數(shù)學(xué)原理,我們可以很容易實(shí)現(xiàn) AddOp,而 MinusOp 實(shí)現(xiàn)類(lèi)似就不贅述了。
而乘法和除法相對(duì)復(fù)雜,顯然兩個(gè)數(shù)乘法的導(dǎo)數(shù)不等于導(dǎo)數(shù)的乘法,例如 x 和 x 的平方,先導(dǎo)數(shù)后相乘得到 2x,先相乘后導(dǎo)數(shù)得到 3 倍 x 的平方。因此這是需要使用乘數(shù)法則,基本公式是,而代碼實(shí)現(xiàn)如下。
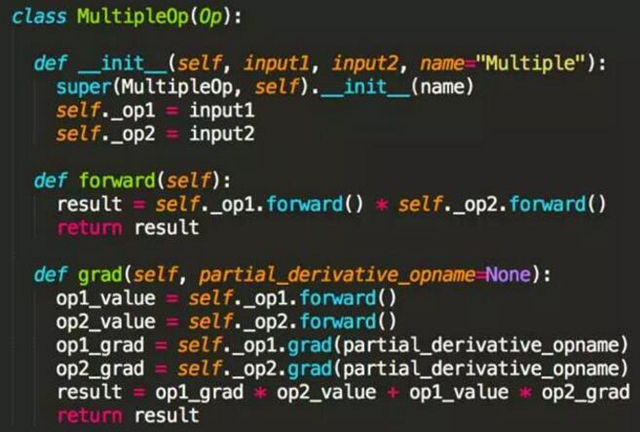
除法和平方的求導(dǎo)方式也是類(lèi)似的,因?yàn)閿?shù)學(xué)上已經(jīng)證明,所以只需要編碼實(shí)現(xiàn)基本的正向和反向運(yùn)算即可。由于篇幅有限,這里不再細(xì)致介紹 MiniFlow 的源碼實(shí)現(xiàn)了,感興趣可以通過(guò)上面的 Github 鏈接找到完整的源碼實(shí)現(xiàn),下面再提供使用相同 API 接口實(shí)現(xiàn)的模型性能測(cè)試結(jié)果,對(duì)于小批量數(shù)據(jù)處理、需要頻繁切換 Python/C++ 運(yùn)行環(huán)境的場(chǎng)景下 MiniFlow 會(huì)有更好的性能表現(xiàn)。
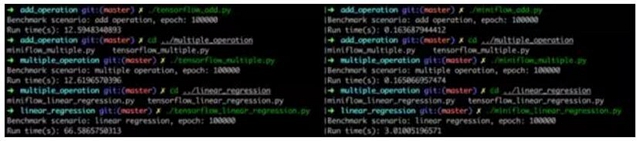
前面介紹了機(jī)器學(xué)習(xí)算法和深度學(xué)習(xí)類(lèi)庫(kù)的實(shí)現(xiàn),并不是所有人都有能力去重寫(xiě)或者優(yōu)化這部分基礎(chǔ)架構(gòu)的,很多時(shí)候我們都只是這些算法的使用者,但從另一個(gè)角度,我們就需要維護(hù)一個(gè)高可用的計(jì)算平臺(tái)來(lái)做機(jī)器學(xué)習(xí)的訓(xùn)練和預(yù)測(cè),下面將從這方面介紹如何打造分布式機(jī)器學(xué)習(xí)平臺(tái)。
第四部分,分布式機(jī)器學(xué)習(xí)平臺(tái)的設(shè)計(jì)
隨著大數(shù)據(jù)和云計(jì)算的發(fā)展,實(shí)現(xiàn)一個(gè)高可用、分布式的機(jī)器學(xué)習(xí)平臺(tái)成為一個(gè)基本需求。無(wú)論是 Caffe、TensorFlow,還是我們自研的高性能機(jī)器學(xué)習(xí)庫(kù),都只是解決數(shù)值計(jì)算、算法實(shí)現(xiàn)以及模型訓(xùn)練的問(wèn)題,對(duì)于任務(wù)的隔離、調(diào)度、Failover 都需要上層平臺(tái)實(shí)現(xiàn)。
那么設(shè)計(jì)一個(gè)針對(duì)機(jī)器學(xué)習(xí)全流程的基礎(chǔ)架構(gòu)平臺(tái),需要涵蓋哪些功能呢?
首先,必須實(shí)現(xiàn)資源隔離。在一個(gè)共享底層計(jì)算資源的集群中,用戶提交的訓(xùn)練任務(wù)不應(yīng)該受到其他任務(wù)的影響,盡可能保證 CPU、內(nèi)存、GPU 等資源隔離。如果使用 Hadoop 或 Spark 集群,默認(rèn)就會(huì)在任務(wù)進(jìn)程上掛載 cgroups,保證 CPU 和內(nèi)存的隔離,而隨著 Docker 等容器技術(shù)的成熟,我們也可以使用 Kubernetes、Mesos 等項(xiàng)目來(lái)啟動(dòng)和管理用戶實(shí)現(xiàn)的模型訓(xùn)練任務(wù)。
其次,實(shí)現(xiàn)資源調(diào)度和共享。隨著通用計(jì)算的 GPU 流行,目前支持 GPU 調(diào)度的編排工具也越來(lái)越多,而部分企業(yè)內(nèi)還存在著 GPU 專(zhuān)卡專(zhuān)用的情況,無(wú)法實(shí)現(xiàn)資源的動(dòng)態(tài)調(diào)度和共享,這必然導(dǎo)致計(jì)算資源的嚴(yán)重浪費(fèi)。在設(shè)計(jì)機(jī)器學(xué)習(xí)平臺(tái)時(shí),需要盡可能考慮通用的集群共享場(chǎng)景,例如同時(shí)支持模型訓(xùn)練、模型存儲(chǔ)以及模型服務(wù)等功能,可以對(duì)標(biāo)的典例就是 Google Borg 系統(tǒng)。
然后,平臺(tái)需要有靈活的兼容性。目前機(jī)器學(xué)習(xí)業(yè)務(wù)發(fā)展迅速,針對(duì)不同場(chǎng)景的機(jī)器學(xué)習(xí)框架也越來(lái)越多,靈活的平臺(tái)架構(gòu)可以兼容幾乎所有主流的應(yīng)用框架,避免基礎(chǔ)架構(gòu)因?yàn)闃I(yè)務(wù)的發(fā)展而頻繁變化。目前 Docker 是一種非常合適的容器格式規(guī)范,通過(guò)編寫(xiě) Dockerfile 就可以描述框架的運(yùn)行環(huán)境和系統(tǒng)依賴,在此基礎(chǔ)上我們可以在平臺(tái)上實(shí)現(xiàn)了 TensorFlow、MXNet、Theano、CNTK、Torch、Caffe、Keras、Scikit-learn、XGBoost、PaddlePaddle、Gym、Neon、Chainer、PyTorch、Deeplearning4j、Lasagne、Dsstne、H2O、GraphLab 以及 MiniFlow 等框架的集成。
***,需要實(shí)現(xiàn)機(jī)器學(xué)習(xí)場(chǎng)景下的 API 服務(wù)。針對(duì)機(jī)器學(xué)習(xí)的模型開(kāi)發(fā)、模型訓(xùn)練和模型服務(wù)三個(gè)主要流程,我們可以定義提交訓(xùn)練任務(wù)、創(chuàng)建開(kāi)發(fā)環(huán)境、啟動(dòng)模型服務(wù)、提交離線預(yù)測(cè)任務(wù)等 API,用熟悉的編程語(yǔ)言來(lái)實(shí)現(xiàn) Web service 接口。要實(shí)現(xiàn)一個(gè) Google-like 的云深度學(xué)習(xí)平臺(tái),大家可以參考下面這三個(gè)步驟。

當(dāng)然,要實(shí)現(xiàn)一個(gè)涵蓋數(shù)據(jù)引入、數(shù)據(jù)處理、特征工程以及模型評(píng)估功能的機(jī)器學(xué)習(xí)平臺(tái),我們還需要集成 HDFS、Spark、Hive 等大數(shù)據(jù)處理工具,實(shí)現(xiàn)類(lèi)似 Azkaban、Oozie 的工作流管理工具,在易用性、低門(mén)檻方面做更多的工作。
總結(jié)
***總結(jié)一下,機(jī)器學(xué)習(xí)的基礎(chǔ)架構(gòu)包含了機(jī)器學(xué)習(xí)算法、機(jī)器學(xué)習(xí)類(lèi)庫(kù)以及機(jī)器學(xué)習(xí)平臺(tái)等多個(gè)層次的內(nèi)容。根據(jù)業(yè)務(wù)的需求,我們可以選擇特定的領(lǐng)域進(jìn)行深入研究和二次開(kāi)發(fā),利用輪子和根據(jù)需求改造輪子同樣重要。
在機(jī)器學(xué)習(xí)與人工智能非常流行的今天,希望大家也可以重視底層基礎(chǔ)架構(gòu),算法研究員可以 理解更多工程的設(shè)計(jì)與實(shí)現(xiàn),而研發(fā)工程師可以了解更多的算法原理與優(yōu)化,在合適的基礎(chǔ)架構(gòu)平臺(tái)上讓機(jī)器學(xué)習(xí)發(fā)揮更大的效益,真正應(yīng)用的實(shí)際場(chǎng)景中。