帶你深入剖析遞歸神經網絡
遞歸神經網絡(RNN)是一類神經網絡,包括一層內的加權連接(與傳統(tǒng)前饋網絡相比,連接僅饋送到后續(xù)層)。因為 RNN 包含循環(huán),所以它們可以在處理新輸入的同時存儲信息。這種記憶使它們非常適合處理必須考慮事先輸入的任務(比如時序數(shù)據(jù))。由于這個原因,目前的深度學習網絡均以 RNN 為基礎。本教程將探索 RNN 背后的思想,并從頭實現(xiàn)一個 RNN 來執(zhí)行序列數(shù)據(jù)預測。
神經網絡是基于高度連接的處理元件(神經元)的網絡將輸入映射到輸出的計算結構。要快速了解神經網絡,請閱讀我的另一篇教程“神經網絡深入剖析”,其中分析了感知器(神經網絡的構建塊)以及具有反向傳播學習能力的多層感知器。
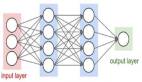
在前面的教程中,我探討了前饋網絡拓撲結構。在此拓撲結構中(如下圖所示),可以通過隱藏層將輸入矢量饋送到網絡中,并最終獲得一個輸出。在這個網絡中,輸入以確定性的方式映射到輸出(每次輸入被應用)

但是,我們假設您在處理時序數(shù)據(jù)。孤立的單一數(shù)據(jù)點并不是完全有用的,因為它缺乏重要的屬性(例如,數(shù)據(jù)序列是否在發(fā)生變化?是增大?還是縮小?)。考慮一個自然語言處理應用程序,其中的字母或單詞表示網絡輸入。當您考慮理解單詞時,字母在上下文中很重要。孤立狀態(tài)下的這些輸入沒有什么用,只有將它們放入之前發(fā)生的事件的上下文中才有用。
時間序列數(shù)據(jù)的應用需要一種可以考慮輸入歷史的新型拓撲結構。這時就可以應用 RNN。RNN 能夠通過反饋來維護內部記憶,所以它支持時間行為。在下面的示例中,會將隱藏層輸出應用回隱藏層。網絡保持前饋方式(先將輸入應用于隱藏層,然后再應用于輸出層),但 RNN 通過上下文節(jié)點保持內部狀態(tài)(這會影響后續(xù)輸入上的隱藏層)。
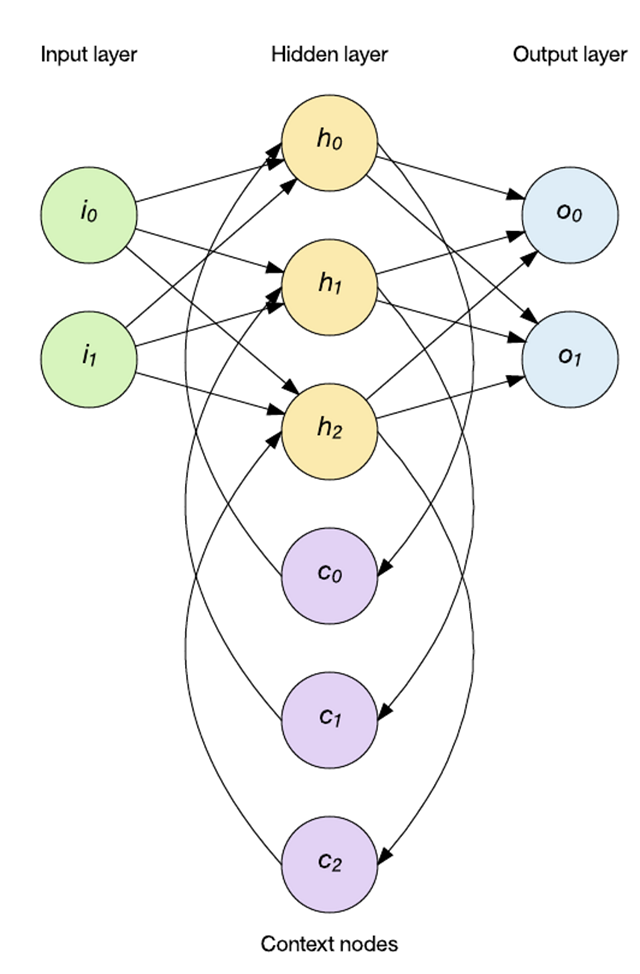
RNN 不是一類網絡,而是一個包含解決不同問題的拓撲結構的集合。遞歸網絡的一個重要方面在于,借助足夠的層和節(jié)點,它們是圖靈完備的,這意味著它們可以實現(xiàn)任何可計算函數(shù)。
RNN 的架構
RNN 是在 20 世紀 80 年代引入的,它們保持對過去輸入記憶的能力為神經網絡開啟了新的問題領域。讓我們看看您可以使用的一些架構。
Hopfield
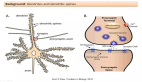
Hopfield 網絡是一種聯(lián)想記憶。給定一種輸入模式,它將獲取與該輸入最相似的模式。這種聯(lián)想(輸入與輸出之間的聯(lián)系)類似于人腦的工作方式。給定一段記憶的一部分,人類能完全回想起該記憶,Hopfield 網絡的工作原理與此類似。
Hopfield 網絡實質上是二進制的,各個神經元要么打開(激活),要么關閉(未激活)。每個神經元都通過一個加權連接與其他每個神經元相連(參見下圖)。每個神經元同時用作輸入和輸出。在初始化時,會在網絡中載入一個部分模式,然后更新每個神經元,直到該網絡收斂(它一定會收斂)。輸出是在收斂(神經元的狀態(tài))時提供的。
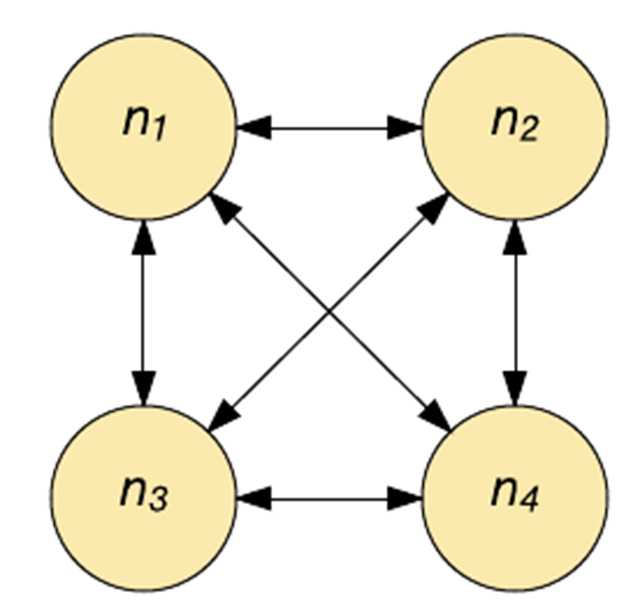
Hopfield網絡能夠學習(通過Hebbian學習)多種模式,并且在輸入中存在噪聲的情況下收斂以回憶最接近的模式。Hopfield 網絡不適合用來解決時域問題,而是經常性的。
簡單遞歸網絡
簡單遞歸網絡是一類流行的遞歸網絡,其中包括將狀態(tài)引入網絡的狀態(tài)層。。狀態(tài)層影響下一階段的輸入,所以可應用于隨時間變化的數(shù)據(jù)模式。
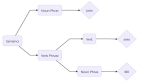
你可以用不同的方式應用狀態(tài),其中兩種流行方法是 Elman 和 Jordan 網絡(參見下圖)。在 Elman 網絡中,隱藏層對保留了過去輸入記憶的上下文節(jié)點狀態(tài)層進行饋送。如下圖所示,存在一組上下文節(jié)點來保持之前的隱藏層結果的記憶。另一種流行的拓撲結構是 Jordan 網絡。Jordan 網絡有所不同,因為它們將輸出層存儲到狀態(tài)層中,而不是保留隱藏層的歷史記錄。
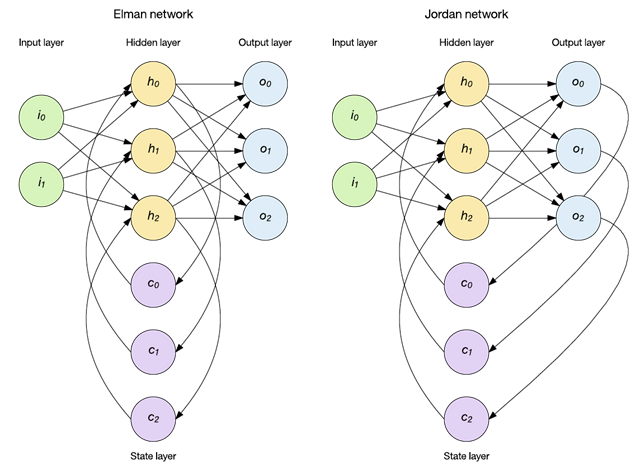
Elman 和 Jordan 網絡可通過標準的反向傳播來訓練,每種網絡都已應用到序列識別和自然語言處理中。請注意,這里僅引入了一個狀態(tài)層,但很容易看出,您可以添加更多狀態(tài)層,在這些狀態(tài)層中,狀態(tài)層輸出可充當后續(xù)狀態(tài)層的輸入。本教程將在 Elman 網絡部分中探討此概念。
其他網絡
遞歸式網絡的研究并沒有停止,如今,遞歸架構正在設立處理時序數(shù)據(jù)的標準。深度學習中的長短期記憶 (LSTM) 方法已經在卷積網絡中得到應用,以便通過生成的語言來描述圖像和視頻的內容。LSTM 包含一個遺忘門,讓您能對各個神經元進行“訓練”,使其了解哪些信息是重要的,以及這保持重要性信息的時間。LSTM 可以處理重要事件間隔時間較長的數(shù)據(jù)。
另一種***的架構稱為門控遞歸單元 (GRU)。GRU 是對 LSTM 的一種優(yōu)化,需要的參數(shù)和資源更少。
RNN 訓練算法
由于 RNN 具有將歷史信息按時序或序列進行合并的性質,所以它們擁有獨特的訓練算法。梯度下降算法已成功應用到 RNN 權重優(yōu)化上(通過與權重的誤差導數(shù)呈一定比例地調節(jié)權重來最小化誤差)。一種流行的技術是時間反向傳播 (BPTT),它應用了權重更新,它通過累加序列中每個元素的累積誤差的權重更新來應用權重更新,,***更新權重。對于大型的輸入序列,此行為可能導致權重消失或爆炸(稱為消失或爆炸梯度問題)。要解決此問題,通常會使用混合方法,并結合使用 BPTT 與實時遞歸學習等其他算法。
其他訓練方法也能成功應用于不斷進化的 RNN。可應用進化算法(比如遺傳算法或模擬退火法)來進化候選 RNN 群體,然后將它們重新組合為它們的適合度(即它們解決給定問題的能力)的函數(shù)。盡管不保證能收斂于一個解決方案,但可以成功地將收斂應用于一系列問題,包括 RNN 進化。
RNN 的一個有用的應用是預測序列。在下一個示例中,我將構建一個 RNN,用它根據(jù)一個小詞匯表來預測某個單詞的***一個字母。我將單詞饋送入 RNN 中,一次加載一個字母,網絡的輸出將表示預測的下一個字母。
遺傳算法流
查看 RNN 示例之前,讓我們看看遺傳算法背后的流程。遺傳算法是一種受自然選擇過程啟發(fā)的優(yōu)化技術。如下圖所示,該算法創(chuàng)建了一個隨機的候選解決方案(稱為染色體)群體,這些解決方案對將要尋找的解決方案的參數(shù)進行編碼。創(chuàng)建它們后,針對相應問題對該群體的每個成員進行測試,并分配一個適合度值。然后從群體中識別父染色體(***具有更高適合度的染色體),并為下一代創(chuàng)建一個子染色體。在子染色體這一代中,應用遺傳運算符(比如從每個父染色體獲取元素 [稱為雜交] 并向子染色體引入隨機變化 [稱為突變])。然后使用新群體再次開始此過程,直到找到合適的候選解決方案。

用染色體組表示神經網絡
一個染色體被定義為群體的一個成員,包含要解決的特定問題的編碼。在進化 RNN 的上下文中,染色體由 RNN 的權重組成,如下圖所示。
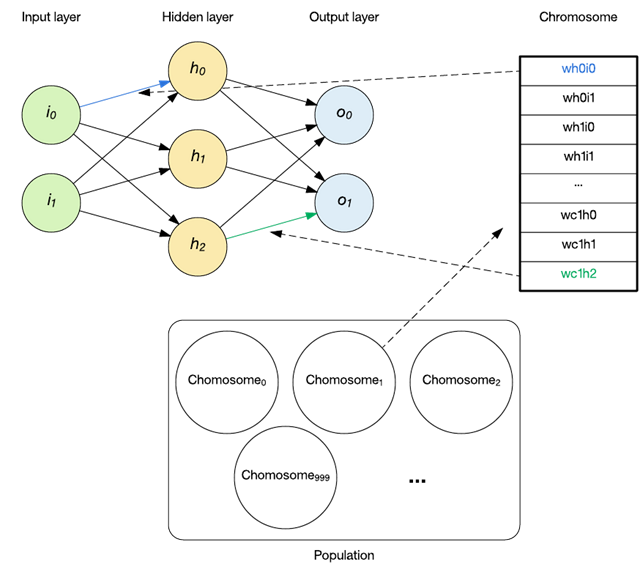
每個染色體包含每個權重的 16 位值。將該值(介于 0 – 65535 之間)轉換為權重,方法是減去該范圍的一半,然后乘以 0.001。這意味著該編碼可以表示 -32.767 到 32.768 之間增量為 0.001 的值。
對于從群體中獲取染色體并生成 RNN 的過程,只需將其定義為使用從染色體轉換而來的權重來初始化網絡的權重。在本例中,這表示 233 個權重。
使用 RNN 預測字母
現(xiàn)在,我們來探討字母在神經網絡中的應用。神經網絡處理的是數(shù)字值,所以需要采用某種表示形式來將字母饋送入網絡中。在本例中,我使用了獨熱編碼。獨熱編碼將一個字母轉換為一個矢量,而且矢量中僅設置一個元素。這種編碼創(chuàng)造了一種可在數(shù)學上使用的獨特特征 — 例如,表示的每個字母都會在網絡中應用自己的權重。盡管在此實現(xiàn)中,我通過獨熱編碼來表示字母;但自然語言處理應用程序也以相同方式表示單詞。下圖演示了這個示例中使用的獨熱矢量和用于測試的詞匯表。

所以,現(xiàn)在我有一種使我的 RNN 能夠處理字母的編碼。現(xiàn)在,讓我們看看如何在 RNN 的上下文中處理字母。下圖演示了字母預測上下文中的 Elman 式 RNN(饋送表示字母 b 的獨熱矢量)。對于測試單詞中的每個字母,我將該字母編碼為獨熱碼,然后將它作為輸入饋送給網絡。然后,以前饋方式執(zhí)行該網絡,并以勝者全得的方式解析輸出,以確定定義獨熱矢量的獲勝元素(在本例中為字母 a)。在此實現(xiàn)中,僅檢查了單詞的***一個字母,驗證中忽略了其他字母,也沒有對它們執(zhí)行適合度計算。
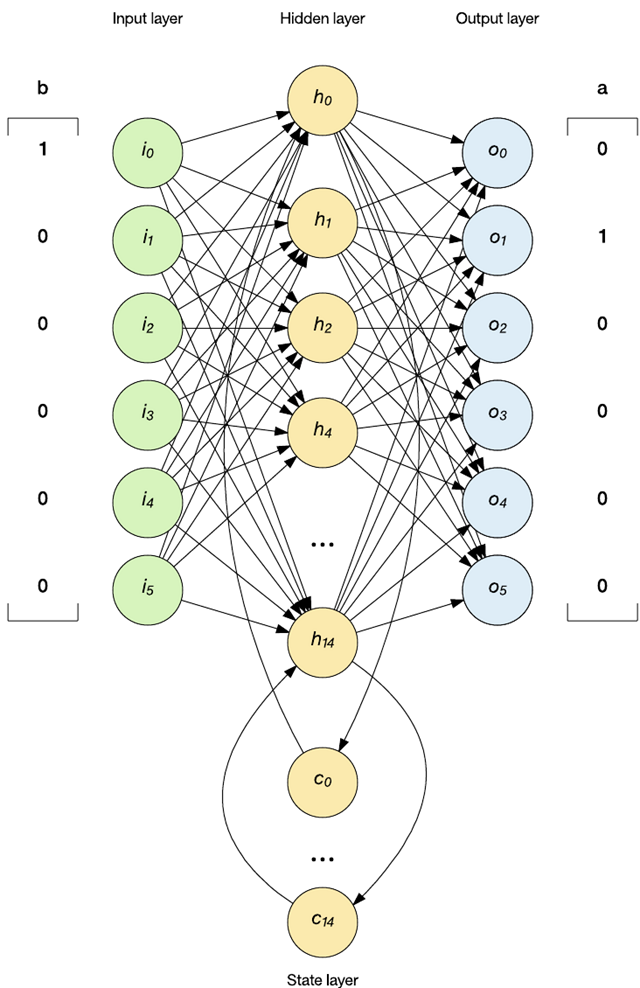
簡單的 Elman 式 RNN 實現(xiàn)
讓我們來看一個通過遺傳算法訓練的 Elman 式 RNN 的樣本實現(xiàn)。可以在 GitHub 上找到此實現(xiàn)的 Linux 源代碼。該實現(xiàn)由 3 個文件組成:
- main.c 提供主循環(huán)、一個用于測試的函數(shù),以及一個用于獲得群體適合度的函數(shù)
- ga.c 實現(xiàn)了遺傳算法函數(shù)
- rnn.c 實現(xiàn)了實際的 RNN
我將重點介紹兩個核心函數(shù):遺傳算法流程和 RNN 評估函數(shù)
RNN 的核心內容可以在 RNN_feed_forward 函數(shù)中找到,該函數(shù)實現(xiàn)了 RNN 網絡的執(zhí)行(參見以下代碼)。該函數(shù)被拆分為 3 個階段,類似于上圖中顯示的網絡。在***階段,計算隱藏層的輸出,隱藏層合并了輸入層和上下文層(每層都有自己的一組權重)。上下文節(jié)點已在測試給定單詞之前初始化為 0。在第二階段,我將計算輸出層的輸出。這一步合并了每個隱藏層神經元與它們自己的獨特權重。***,在第三階段,我將***個上下文層神經元傳播到第二個上下文層神經元,將隱藏層輸出傳播到***個上下文節(jié)點。這一步在網絡中實現(xiàn)了兩個記憶層。
請注意,在隱藏層中,我使用 tan 函數(shù)作為激活函數(shù),并使用 sigmoid 函數(shù)作為輸出層中的激活函數(shù)。tan 函數(shù)在隱藏層中很有用,因為它的范圍是 -1 到 1(它還允許使用來自隱藏層的正輸出和負輸出)。在輸出層中,我感興趣的是激活獨熱矢量的***值,我使用了 sigmoid,因為它的范圍是 0 到 1。
- void RNN_feed_forward( void )
- {
- int i, j, k;
- // Stage 1: Calculate hidden layer outputs
- for ( i = 0 ; i < HIDDEN_NEURONS ; i++ )
- {
- hidden[ i ] = 0.0;
- // Incorporate the input.
- for ( j = 0 ; j < INPUT_NEURONS+1 ; j++ )
- {
- hidden[ i ] += w_h_i[ i ][ j ] * inputs[ j ];
- }
- // Incorporate the recurrent hidden.
- hidden[ i ] += w_h_c1[ i ] * context1[ i ];
- hidden[ i ] += w_h_c2[ i ] * context2[ i ];
- // apply tanh activation function.
- hidden[ i ] = tanh( hidden[ i ] );
- }
- // Stage 2: Calculate output layer outputs
- for ( i = 0 ; i < OUTPUT_NEURONS ; i++ )
- {
- outputs[ i ] = 0.0;
- for ( j = 0 ; j < HIDDEN_NEURONS+1 ; j++ )
- {
- outputs[ i ] += ( w_o_h[ i ][ j ] * hidden[ j ] );
- }
- // apply sigmoid activation function.
- outputs[ i ] = sigmoid( outputs[ i ] );
- }
- // Stage 3: Save the context hidden value
- for ( k = 0 ; k < HIDDEN_NEURONS+1 ; k++ )
- {
- context2[ k ] = context1[ k ];
- context1[ k ] = hidden[ k ];
- }
- return;
- }
我在下面的代碼示例中實現(xiàn)了遺傳算法。可以分 3 部分查看此代碼。***部分計算群體的總適合度(在選擇過程中使用),以及群體中最適合的染色體。第二部分中使用最適合的染色體,僅將此染色體復制到下一個群體。這是一種精英選擇形式,我將維護最適合的染色體,一直到將其復制到下一個群體中。該群體包含 2,000 個染色體。
在遺傳算法的***一部分中,我從群體中隨機選擇兩個父染色體,利用它們?yōu)橄乱粋€群體創(chuàng)建一個子染色體。選擇算法基于所謂的輪盤抽獎選擇方法,染色體是隨機選擇的,但選中更符合的父染色體的幾率更高一些。選擇兩個父染色體后,將它們重新組合成下一個群體的子染色體。此過程蘊含雜交(選擇一位父親的基因來傳播)和突變(可以隨機重新定義一個權重)的可能性。發(fā)生雜交和突變的概率很低(每次重新組合對應一次突變,而雜交次數(shù)則更少)。
- void GA_process_population( unsigned int pop )
- {
- double sum = 0.0;
- double max = 0.0;
- int best;
- int i, child;
- best = 0;
- sum = max = population[ pop ][ best ].fitness;
- // Calculate the total population fitness
- for ( i = 1 ; i < POP_SIZE ; i++ )
- {
- sum += population[ pop ][ i ].fitness;
- if ( population[ pop ][ i ].fitness > max )
- {
- best = i;
- max = population[ pop ][ i ].fitness;
- }
- }
- // Elitist -- keep the best performing chromosome.
- recombine( pop, best, best, 0, 0.0, 0.0 );
- // Generate the next generation.
- for ( child = 1 ; child < POP_SIZE ; child++ )
- {
- unsigned int parent1 = select_parent( pop, sum );
- unsigned int parent2 = select_parent( pop, sum );
- recombine( pop, parent1, parent2, child, MUTATE_PROB, CROSS_PROB );
- }
- return;
- }
樣本執(zhí)行
可以在 Linux 中構建 GitHub 上的樣本源代碼,只需鍵入 make 并使用 ./rnn 來執(zhí)行。執(zhí)行時,會隨機創(chuàng)建群體,然后對一些代進行自然選擇,直到找到準確預測了整個測試詞匯表的***一個字符的解決方案,或者直到模擬未能正確地收斂于一個解決方案上。成敗與否由平均適合度來決定;如果平均適合度達到***適合度的 80%,那么該群體缺乏足夠的多樣性來找到解決方案,并將退出。
如果找到一個解決方案,代碼將發(fā)布整個測試詞匯表并顯示每個單詞的預測結果。請注意,染色體適合度僅基于單詞的***一個字母,所以沒有預測內部字母。下面的代碼提供了一個成功輸出的樣本。
- $ ./rnn
- Solution found.
- Testing based
- Fed b, got s
- Fed a, got b
- Fed s, got e
- Fed e, got d
- Testing baned
- Fed b, got s
- Fed a, got b
- Fed n, got d
- Fed e, got d
- Testing sedan
- Fed s, got s
- Fed e, got d
- Fed d, got s
- Fed a, got n
- ...
- Testing den
- Fed d, got d
- Fed e, got n
- Testing abs
- Fed a, got d
- Fed b, got s
- Testing sad
- Fed s, got s
- Fed a, got d
下圖展示了平均和***適合度的曲線圖。請注意,每個曲線圖都從約為 13 的適合度級別開始。12 個單詞以 d 結尾,所以為任何字母序列發(fā)布 d 的網絡都擁有這一成功級別。 但是,必須進化這些權重,以便考慮前面的字母,針對給定詞匯表進行準確預測。如圖所示,在成功運行時,超過一半的世代需要預測成功運行的***一個測試用例。
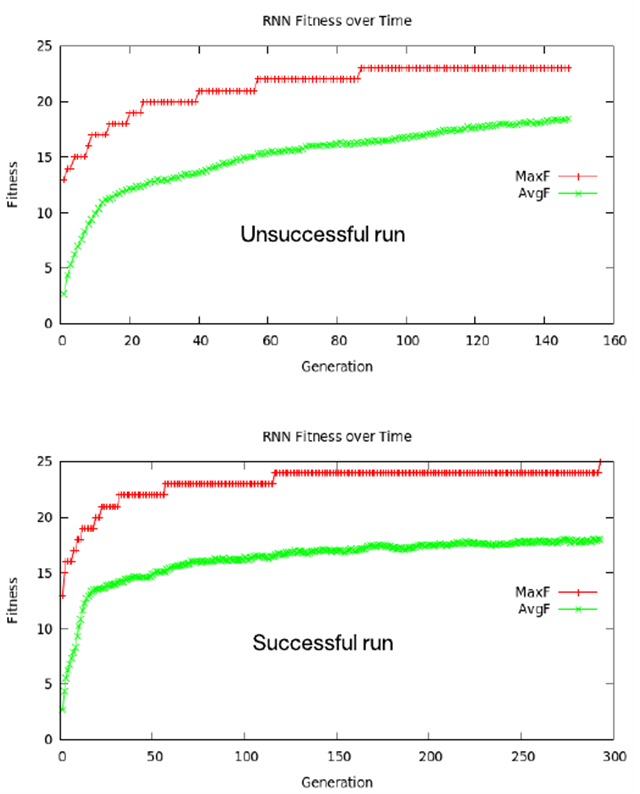
有趣的是,每個曲線圖都演示了進化生物學中的一種稱為間斷平衡的理論,該現(xiàn)象的特征是,一次爆發(fā)性的進化變異打斷了長期的靜態(tài)平衡(總體穩(wěn)定性)。在一種情況下,這種爆發(fā)性的進化會導致停滯在局部最小值上;在另一種情況下,進化會成功(停滯在局部***值上)。
結束語
傳統(tǒng)神經網絡能以確定性方式將輸入矢量映射到輸出矢量。對于許多問題,這是理想選擇,但在必須考慮序列和時序數(shù)據(jù)時,向網絡引入內部記憶使其能夠在制定輸出決策時考慮以前的數(shù)據(jù)。RNN 在傳統(tǒng)前饋網絡中引入了反饋,使它們能包含一個或多個記憶級別。RNN 代表著一種未來的基礎架構,可以在大多數(shù)先進的深度學習技術(比如 LSTM 和 GRU)中找到它。