百萬騎手“火速送達”背后的人工智能應用實踐
大部分人都點過外賣,現在外賣成了中國人吃飯的另一種方式,今天分享的主題是人工智能在 “餓了么” 的應用實踐。
今天的內容主要分為三個部分:
- “餓了么” 簡介。
- AI 在“餓了么” 的應用場景。
- 運籌優化與機器學習的應用實例。
關于“餓了么”
大部分人都點過外賣,現在外賣成了中國人吃飯的另一種方式。點外賣是什么樣的量級,說起來嚇大家一跳。
中國最大領域是電商,淘寶、京東,其次就是出行行業,滴滴、UBER,緊接著是共享單車,這幾家公司加起來是一天兩三千萬的訂單量左右。
而在外賣行業,到今天為止已經每天達到 2500 萬單,可以看到這個行業正在飛速發展。
為什么數據和算法能起到那么大的作用?因為我們都知道在“互聯網+”的背景下,有這么大的訂單量,至少是在數據行業我們有非常多事情要做。
2500 萬訂單量里面 “餓了么” 是什么樣的場景?我們把手機 APP 打開,可以找到自己喜歡的餐廳,大家選擇一個餐廳,選擇喜歡吃的東西,這個行為雖然是點一個菜,但是實際上跟大家在淘寶買衣服和在攜程買機票是一樣的。
前面是電商交易平臺所交易的食品,現在不僅是食品,還可以在上面買鮮花、買藥品,同時還有本地的幫買幫送等等。所以電商只是第一部分,電商到了什么規模?
“餓了么”C 端注冊用戶 2.6 億,B 端商家目前已經是 130 萬,每年是千萬級別的定單情況,這個是我們外賣行業的一部分,基于電商交易平臺。
第二部分就是大家可以看見上圖中騎手小哥拿著箱子,要么走路或者騎著電動車,這就是本地物流平臺。

為什么要強調本地,因為我們行業的特殊性跟其他物流行業不一樣。他們幾天時間到達,我們這個行業的本地物流是希望 30 分鐘能送到用戶手里。
所以我們在設計這個架構的時候就有很大的挑戰,這個有一些不同,一會兒講到算法模型的時候就清楚了,我們是做一些本地的物流,所以時間上有非常嚴格的限制。
到今天為止,我們配送員已經達到 300 萬,平均每天在任何時刻,全國都有 30 萬到 40 萬的騎手活躍線下,隨時準備接單。這個跟滴滴是一樣的運營模式,現在已經覆蓋了全國 2 千多個城市。
AI 在“餓了么”的應用場景
外賣這個行業為什么需要人工智能呢?作為本地生活的平臺,我們都知道衣食住行是非常需要的。
在每個方向都有很多大的商家,他們在技術上的挑戰有什么不同,一定取決于他們的業務形態。

首先是淘寶,淘寶是大家在線上買東西最常用的一個平臺,里面主要是以用戶和商戶為主,線下是同城當日達,更多定單是走開放平臺。
大家下了定單,東西送到大家的手里,這個是三通一達。也可以是菜鳥或者順豐,它們是開放平臺,最重要的一點是時效性,通常以天來計算,超時不會有所謂的賠償,這個是淘寶的情況。
我們再看攜程,它可以定旅館、酒店,線上以用戶和商戶為主,不會有線下的訂單。
跟外賣行業特別接近的就是滴滴,從業務形態來講,像滴滴這類出行和外賣是非常接近的。
滴滴線下線上始終是用戶和司機,定單形式也是眾包的形式,要么通過加盟商,要么通過司機網上注冊來承擔運力,超時也不會懲罰司機。
因為誰也不會預料到會不會出現車禍,這個時效沒有保證,所以說它和餓了么是極其相似的。
最后提到 “餓了么” 和外賣行業。首先線上以用戶和商戶為主,線下訂單部分比較多,藍色騎手有一部分是 “餓了么” 的員工,就是自營,還有團隊和加盟商的形式,當然還有一種是眾包。
比如說今天開一個會,下午還有四個小時,我可以送幾單,這是一種眾包的形式。
時效性是以分鐘來計算的,我們的目標在很長時間已經做到了,全國平均半個小時可以把訂單送到手里。
還有超時賠付,如果 30 分鐘之后超過 10 分鐘沒有送到,就有一個紅包的賠償,超時賠付的壓力是比較大的,不過這樣做對客戶來說算是一種服務不足的補償。
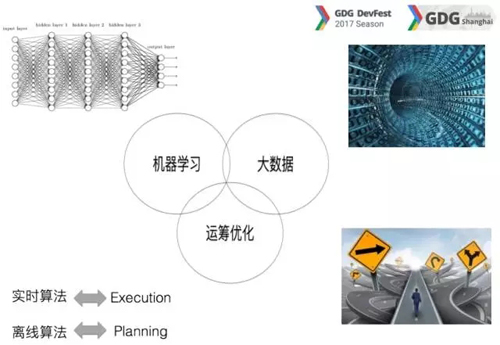
根據上面所述,我們進入了一個大的框架,就是在外賣這個行業是三個大框架,一個是機器學習,一個是大數據,再一個運籌優化跟機器學習也是密不可分的。
講到運籌優化,大數據作為運籌優化的基礎起到了非常關鍵的作用,現在大家看這個圖挺有意思,我會多花兩分鐘講一講在業務中的算法問題,大概有三個層面。
底層的外賣行業希望 30 分鐘把食物送到用戶手里,不可能送到二十或者三十公里之外,除非你會飛,否則半個小時不可能送 10 公里。
基于這種情況,所有行業都是基于當前打開 APP 的位置,定位可能 3 公里或者 5 公里的半徑,LBS 保證在運營商網絡做各種推薦或者搜索為基礎,再往上兩層就是機器學習和優化,所以具體講一下這三部分。
交易
如下圖,大家可以看到中間這個模塊是用戶商戶分層,推薦搜索以及智能補貼,這幾個大的方向是任何電商都必須做的。
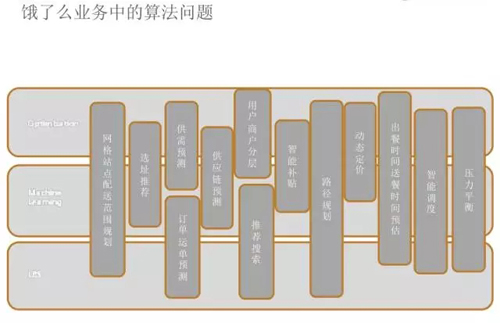
在有很精細的用戶畫像體制上,我們希望對用戶和商戶的生命周期做嚴格的管理,在這個基礎上我們做相應的推薦、搜索、補貼。
比如說有一個用戶進入沉睡期,我們會通過一定的方式對客戶進行刺激。
線下
當交易行為發生時,我們希望 30 分鐘將外賣送到用戶手里,這里面涉及到機器學習的規劃,我會詳細講智能的調度,也會詳細講到出餐時間和送餐時間的預估,以及動態定價等這幾個模塊。
智能調度是調度的一部分,我們這 30 分鐘包括了準備的時間和路上的時間,甚至保證了送到樓下,等電梯到你手上的時間等等。所以這 30 分鐘有很多不可預估的東西。
那么壓力平衡是什么意思?大家都知道,線上交易和我們物流是矛盾的,對于線上交易來說我們當然希望訂單越多越好,我們希望有上千萬的用戶幾秒鐘一下子全進來。
但是 30 分鐘內把訂單全部送出去,這個是不太可能一下子解決的問題,為了達到壓力平衡,就要保證交易和物流、配送等保持平衡,既達到交易質量,也不損失用戶的積極性。
底層
講到交易和線下這兩個之后就是一些底層的東西,現在讓我們看上面那張圖,左邊包括選址推薦等等。
剛才講到配送是本地,當一個商家定下準備配送的地方就會畫一個圈,比如說我送一個圓圈或者六邊形,這個不是隨便畫的。
首先有可能這個地方是高速路或者高架橋,不是每個人的平臺都是一樣的,有的用戶也有可能老是定便宜訂單,我們在網格和站點規劃的時候會考慮所有因素。
這個涉及很多運籌優化的問題,最后一個例子就會講到選址和網格規劃的問題。
下面簡單講一下我們在人工智能方面所有的一些嘗試,這對我們業務是非常重要的。
運籌優化與機器學習的應用實例
這一部分我會分兩種來說:
- 機器學習的應用案例。
- 機器學習應酬優化的案例。
案例 1 : 出餐時間預估
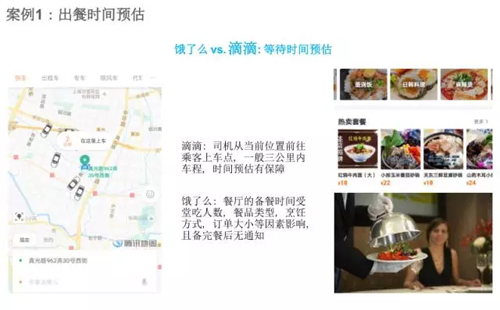
第一個是出餐時間的預估,我在這里用滴滴做比較,什么是等待時間預估。
比如我們在滴滴場景下下了一個訂單,說我想去浦東機場,它會告訴你這個車離這里兩公里,3 分鐘會到,這個3 分鐘就是等待時間預估。
“餓了么” 相當于下了一個單,大概 20 分鐘才能做好,我們希望的是來的早不如來的巧。
作為我們平臺的騎手剛好在 20 分鐘就到,如果早了騎手等在那兒是浪費,但是去晚了,就可能訂單超過了時間。
這個出餐時間的準確性是關鍵,當訂單完成之后,怎么知道訂單花多長時間完成?
這個餐廳受很多因素的影響,餐廳的備餐時間和食堂吃的用戶數、餐品類型、烹飪方式、訂單大小等且備完餐后無通知。
比如說餐廳客戶特別多,平時可能 5 分鐘做出來,可能人多了就 5 分鐘做不出來。
還有產品品類的問題,甚至包括一天的天氣各種原因,包括餐廳的出勤率,餐廳廚師請假突然少了幾個人,這些都是造成預估不準確的原因之一。
我們想過為什么不讓餐廳做好了后直接告訴我們,然后我們就去取餐,這個理論是可行。
但是大家想象一下在餐廳場景里面,廚房是什么樣的情況?你想象一下一個廚師滿手都是油,出來點一下這個訂單好了,然后看下一個訂單,這個是很難想象的事情,我們沒有得到這方面的數據。
這個是一個前提,我們的解決方案毫無疑問是機器學習,最簡單版本就是線性模型。
一開始效果不是特別好,但逐漸演進到后面的 GBDT ,在場景下做到平均不是特殊平均,加上出餐時間是 10 分鐘,我們可以固定 7 分鐘到 13 分鐘,這個準確率比較高。
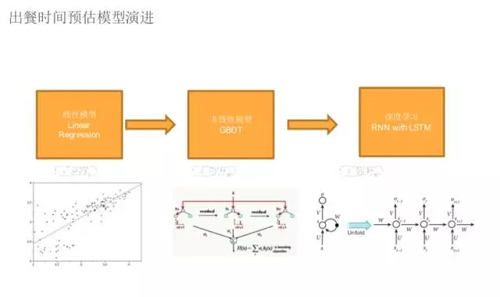
我強調是平均,因為有很多特殊場景,如果廚師出了什么事情,我們也不知道,因為機器學習只能根據過去的事情來預測將來。
在突發事件有一些產品的方案,比如說看到這個餐廳出餐量和訂單量并沒有呈線性的增長,前面出現了堵塞情況,我們根據數據對平臺進行實時調整。
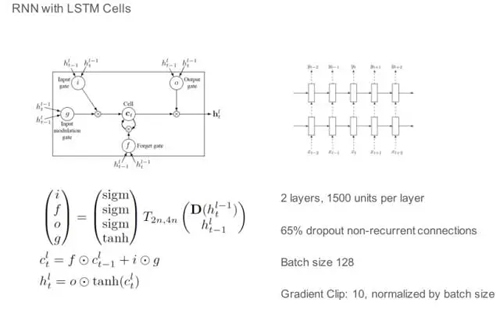
最后我們的方法是深度學習,用的是 LSTM。我們通過時間相關性把預測做的更加準確,毫無疑問出餐時間一定會跟過去訂單有關系,這個不用解釋。
但是為什么跟未來有關系,我們預估未來 3 到 5 分鐘有新的訂單,但是跟現有的訂單有共同之處,有可能是同樣的菜品,有可能是共同的地方,同樣的菜品對廚房是一個訂單,可以把菜一起做。
我們學到了,通過這個模型也可以捕捉這些特征,對訂單分配有一定的幫助,同樣對訂單打包也有一定的幫助。
案例 2 :行程時間預估
行程時間的預估就是當訂單完成了以后,騎手把訂單拿到手里,他會跑到辦公室或者家里也好,這個是行程時間的預估。
例如滴滴從 A 點到 B 點,交通方式肯定就是車,而且有大量的地圖數據,像高德或者谷歌地圖或者百度地圖,這些數據會實時上傳給服務器。

在這種交通情況預測已經是比較準確的,但是相對 “餓了么” 場景遠遠沒有那么多的信息。
首先騎手可能步行,走電梯、走上下樓梯、騎電動車或者換交通工具,這個直接造成了我們的數據搜集是極不準確的,還有一點在樓宇內的交通復雜,這個數據很難獲取。
我們上班的時候,餐廳和顧客都是在大樓里面,大樓里面沒有 GPS 信號或者信號不大好,我們收到的數據或者定位誤差高達幾百米。
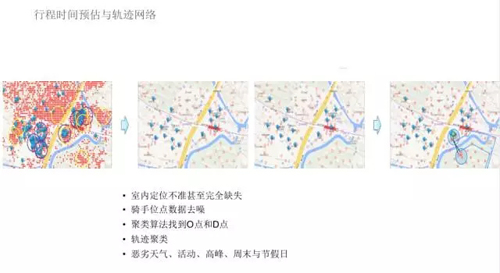
所以提前時間預估,我們需要把軌跡建立起來,因為時間預估在高德地圖或者騰訊百度地圖是基于歷史數據的。
我們第一步做的是歷史數據清洗,室內定位不準甚至完全缺失,這個情況下我們想了各種各樣的辦法,我們用 WiFi 信號,GPS 信號或者大家互相定位,最大程度減少定位缺失的問題。
其次,即使定位有了,它的位點也是有 GPS 軌跡的,也有很多的噪音,所以需要去噪。我們通過定位的算法把相關的時間,把 O 點和 D 點合起來,最后進行軌跡聚類。
案例 3 :智能分單
滴滴與我們的分單難度不一樣,滴滴場景下要配一個司機,最多接兩三單。
在 “餓了么” ,一個騎手一個包同時背 5 到 10 單,而且訂單之間有時間限制,涉及大量的時效要求。

我講兩個方案,第一個方案是路徑規劃的問題,很傳統的 VIP。
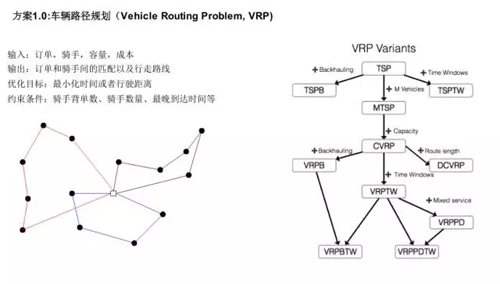
當你給一個訂單,在騎手容量和成本固定的情況下,我們需要找到匹配的線路,每個訂單承諾時間是不一樣的,就是保證不能超時。
默認模式下, 一個騎手可以同時送 5 到 10 單, 每單都有嚴格的時效要求, 并且訂單在午間高峰爆發式增加。
方案 1 就是車輛路徑規劃:
- 輸入:訂單,騎手,容量,成本。
- 輸出:訂單和騎手間的匹配以及行走路線。
- 優化目標:最小化時間或者行駛距離。
- 約束條件:騎手背單數、騎手數量、最晚到達時間等。
我們用了模擬退火算法,模擬退火算法 ( Simulated Annealing,SA ) 是基于 Monte-Carlo 迭代求解策略的一種隨機尋優算法。
通過賦予搜索過程一種時變且最終趨于零的概率突跳性,從而可有效避免陷入局部極小并最終趨于全局最優的串行結構的優化算法。
從理論上來說這個算法具有概率的全局優化性能,目前已在工程中得到了廣泛應用,諸如 VLSI ,生產調度、控制工程、機器學習、神經網絡、信號處理等領域就是用它來做訂單的分配。
但是最后結果不是特別好,因為時間預估存在不準備性,在路徑規劃的時候,先走 A 單還是 B 單,在時間一旦出現誤差的情況下,這個路徑規劃會非常差。

最后用的是第二個算法,也是一種基于大量函數的組合算法。
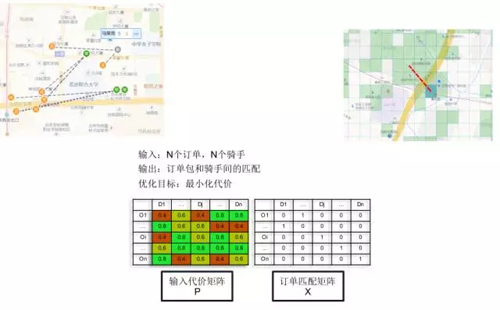
左下角是個矩陣,每一行是一個訂單,每一列是一個騎手,我們希望通過一些規則和一些機器學習的算法算出來,右邊是一個定單匹配的結果。
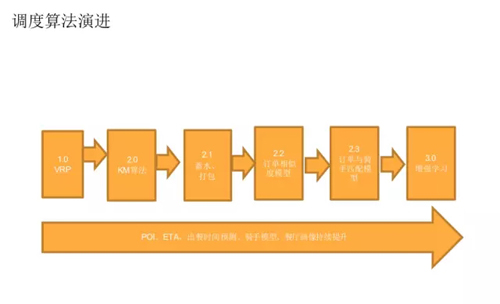
最優匹配就是 KM 算法,調度算法的演進最早是 VRP。
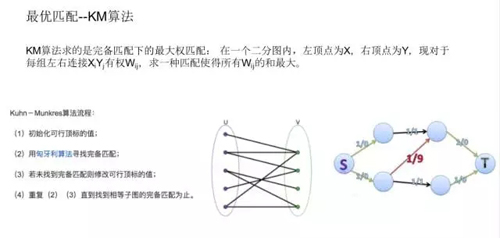
后來采用的是 KM 算法,但是這個基礎框架界定了以后,還有很多工作需要做。
訂單實際上有相似性,因為訂單是可以打包的,一個人稍微等幾分鐘,也許這個訂單出來跟那個訂單很相似的性質,就是去同一個地方,就可以把訂單給同一個人拿走。
所以訂單打包和吸水是我們做的第一件事情,但是訂單靠什么規則在高峰期和非高峰期的時候是不一樣的,這里存在兩個方向的路和兩個方向的夾角不一樣的地方,所以定單匹配模型是在 2.2 版本之上做出來的。
用機器學習通過歷史數據來訓練,在這里我們也碰到一些挑戰,由于在不同的站點配送員習慣不一樣,我們推廣的時候會遇到一個問題,在 A 站點大家覺得是 OK,但是在 B 站點不行。
我們現在做到千站千面的東西,根據類似的站點歷史過去分擔一些情況,我們把這些模型用來做訓練,做到類似的站點它有類似分單的方式。
所以不會出現說你特別不喜歡這個分單的方式,多多少少有一點類似性,后來做到了 2.3 這個版本。
現在做的版本就是增強學習,我們根據實時的情況來進行動態地調整。
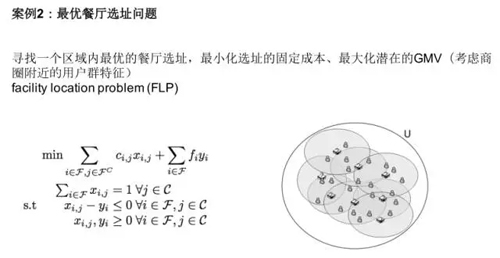
餐廳選址就不詳細講了,我們也和商家開始合作開一些餐廳,我們都希望選最好的地方,餐廳覆蓋最多的用戶,菜品不一樣,用戶群不一樣,所以這個選址是很重要的。
總結

我做機器學習十幾年,個人感受,工作挑戰是來自于基礎數據的完整性和準確性。
剛才講到數據不準確,餐廳不規則的情況,我們無法知道一些準確的情況,我們花了大量時間來做基礎數據的調整。
第二點我講到算法的提升和對人的行為的理解比較重要,因為在外賣行業都需要人去執行,以前人工分配通過打電話,有大量溝通在里面。
現在機器一下子分攤了,他們難以理解,而且機器考慮全局最優而不是局部最優,人是做不到這點。
在算法提升和產品運營綜合起來,才能把這個事情最后推下去讓大家形成習慣。
第三點優化算法與機器學習在我們行業是相輔相成的,不僅是機器學習,更重要的是我們在這么短時間怎么樣把人力分布最好,在最少的時間情況下把訂單完成。
張浩,餓了么技術副總裁,曾任滴滴研究院高級總監,美國 Uber 大數據部、LinkedIn 搜索與分析部資深數據科學家、Microsoft 語音識別組高級數據工程師,現負責餓了么人工智能與大數據建設,帶領團隊將機器學習應用在物流調度、壓力平衡、推薦搜索等場景,通過數據挖掘建立完整的數據運營體系,提高運營效率,用數據和智能驅動業務發展,擁有十余年機器學習、數據挖掘、分布式計算的實際經驗。