基礎|認識機器學習中的邏輯回歸、決策樹、神經網絡算法
1、 邏輯回歸
邏輯回歸。它始于輸出結果為有實際意義的連續值的線性回歸,但是線性回歸對于分類的問題沒有辦法準確而又具備魯棒性地分割,因此我們設計出了邏輯回歸這樣一個算法,它的輸出結果表征了某個樣本屬于某類別的概率。邏輯回歸的成功之處在于,將原本輸出結果范圍可以非常大的θTX 通過sigmoid函數映射到(0,1),從而完成概率的估測。sigmoid函數圖像如下圖所示:
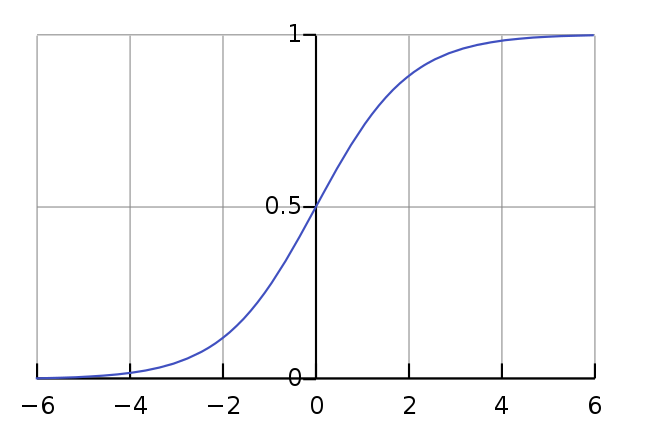
直觀地在二維空間理解邏輯回歸,是sigmoid函數的特性,使得判定的閾值能夠映射為平面的一條判定邊界,當然隨著特征的復雜化,判定邊界可能是多種多樣的樣貌,但是它能夠較好地把兩類樣本點分隔開,解決分類問題。求解邏輯回歸參數的傳統方法是梯度下降,構造為凸函數的代價函數后,每次沿著偏導方向(下降速度最快方向)邁進一小部分,直至N次迭代后到達最低點。利用Scikit-Learn對數據進行邏輯回歸分析。 首先進行特征篩選, 特征篩選的方法有很多,主要包含在Scikit_Learn的feature_selection庫中, 比較簡單的有通過F檢驗(f_regression) 來給出各個特征的F值和p值, 從而可以篩選變量(選擇F值大的或者p值小的特征)其次有遞歸特征消除(Recursive Feature Elimination, RFE) 和穩定性選擇(Stability Selection) 等比較新的方法。之后就可以利用篩選后的特征建立邏輯回歸模型。
遞歸特征消除的主要思想是反復的構建模型(如SVM或者回歸模型) 然后選出最好的(或者最差的) 的特征(可以根據系數來選) , 把選出來的特征放到一邊, 然后在剩余的特征上重復這個過程, 直到遍歷所有特征。 這個過程中特征被消除的次序就是特征的排序。 因此, 這是一種尋找最優特征子集的貪心算法。 Scikit-Learn提供了RFE包, 可以用于特征消除, 還提供了RFECV, 可以通過交叉驗證來對特征進行排序。
代碼體驗
- import pandas as pd
- input_file='./bankloan.xls'
- data=pd.read_excel(input_file)
- data.head()
- X=data.iloc[:,:8].as_matrix()#將矩陣轉換為Numpy數組
- Y=data.iloc[:,8].as_matrix()
- from sklearn.linear_model import LogisticRegression as LR
- from sklearn.linear_model import RandomizedLogisticRegression as RLR
- rlr=RLR()#建立隨機邏輯回歸模型,篩選變量
- rlr.fit(X,Y) #訓練模型
- rlr.get_support()#獲取特征篩選結果,也可以通過.scores_方法獲取各個特征的分數
- x=data.iloc[:,0:8]
- X = x[x.columns[rlr.get_support()]].as_matrix() #篩選好特征
- lr=LR()#建立邏輯回歸模型
- lr.fit(X,Y)
- print("正確率:%s" % lr.score(X,Y))
- x.columns[rlr.get_support()]
2、決策樹
決策樹(decision tree):是一個樹結構(可以是二叉樹或非二叉樹)。其每個非葉節點表示一個特征屬性上的測試,每個分支代表這個特征屬性在某個值域上的輸出,而每個葉節點存放一個類別。使用決策樹進行決策的過程就是從根節點開始,測試待分類項中相應的特征屬性,并按照其值選擇輸出分支,直到到達葉子節點,將葉子節點存放的類別作為決策結果。
決策樹構造:使用屬性選擇度量來選擇將元組最好地劃分成不同的類的屬性。所謂決策樹的構造就是進行屬性選擇度量確定各個特征屬性之間的拓撲結構。構造決策樹的關鍵步驟是分裂屬性。所謂分裂屬性就是在某個節點處按照某一特征屬性的不同劃分構造不同的分支,其目標是讓各個分裂子集盡可能地“純”。盡可能“純”就是盡量讓一個分裂子集中待分類項屬于同一類別。分裂屬性分為三種不同的情況:
- 屬性是離散值且不要求生成二叉決策樹。此時用屬性的每一個劃分作為一個分支。
- 屬性是離散值且要求生成二叉決策樹。此時使用屬性劃分的一個子集進行測試,按照“屬于此子集”和“不屬于此子集”分成兩個分支。
- 屬性是連續值。此時確定一個值作為分裂點split_point,按照>split_point和<=split_point生成兩個分支。
構造決策樹的關鍵性內容是進行屬性選擇度量,屬性選擇度量是一種選擇分裂準則,是將給定的類標記的訓練集合的數據劃分D“最好”地分成個體類的啟發式方法,它決定了拓撲結構及分裂點split_point的選擇。
屬性選擇度量算法有很多,一般使用自頂向下遞歸分治法,并采用不回溯的貪心策略。
代碼體驗
- import pandas as pd
- input_file='./sales_data.xls'
- data=pd.read_excel(input_file,index_col='序號')
- data[data=="好"]=1
- data[data=="是"]=1
- data[data=="高"]=1
- data[data!=1]=-1
- #注意類型,上面輸出可以看出是object類型,要轉換成int類型
- X=x.as_matrix().astype(int)
- Y=y.as_matrix().astype(int)
- from sklearn.tree import DecisionTreeClassifier as DTC#導入分類樹
- dtc=DTC()
- dtc.fit(X,Y)
- from sklearn.tree import export_graphviz
- from sklearn.externals.six import StringIO
- with open("tree.dot", 'w') as f:
- f = export_graphviz(dtc, feature_names = x.columns, out_file = f)
3、神經網絡
人工神經網絡(ANN)
人工神經網絡(Artificial Neural Network,即ANN ),是20世紀80 年代以來人 工智能領域興起的研究熱點。它從信息處理角度對人腦神經元網絡進行抽象, 建立某種 簡單模型,按不同的連接方式組成不同的網絡。在工程與學術界也常直接簡稱為神 經網絡或類神經網絡。神經網絡是一種運算模型,由大量的節點(或稱神經元)之間相 互聯接構成。每個節點代表一種特定的輸出函數,稱為激勵函數(activation function)。每兩個節點間的連接都代表一個對于通過該連接信號的加 權值,稱之為權重,這相當于人工神經網絡的記憶。網絡的輸出則依網絡的連接方式, 權重值和激勵函數的不同而不同。而網絡自身通常都是對自然界某種算法或者函數 的逼近,也可能是對一種邏輯策略的表達。
Keras簡介
Keras:基于Python的深度學習庫
Keras是一個高層神經網絡API,Keras由純Python編寫而成并基Tensorflow、Theano以及CNTK后端。Keras 為支持快速實驗而生,能夠把你的idea迅速轉換為結果 。
常用模塊簡介:
1.optimizers
包:keras.optimizers :
這個是用來選用優化方法的,里面有SGD,Adagrad,Adadelta,RMSprop,Adam可選 。
2.objectives
包:keras.objectives
該模塊主要負責為神經網絡附加損失函數,即目標函
這個定義了用什么形式的誤差來優化,有
mean_squared_error / mse:平均方差
mean_absolute_error / mae:絕對誤差
mean_absolute_percentage_error / mape:平均絕對百分差
mean_squared_logarithmic_error / msle:對數誤差
squared_hinge
hinge
binary_crossentropy: Also known as logloss.
categorical_crossentropy:使用這個目標函數需要設置label為二進制數組的形式。
3.model
包:keras.models 這是Keras中最主要的一個模塊,用于對各個組件進行組裝
from keras.model import Sequential
model = keras.models.Sequential() 初始化一個神經網絡
model.add(......)#add方法進行組裝
4.layers
包:keras.layers
該模塊主要用于生成神經網絡層,包含多種類型,如Core layers、Convolutional layers等
from keras.layers import Dense
model.add(Dense(input_dim=3,output_dim=5)#加入隱藏層
5.Initializations
包:keras.initializations
該模塊主要負責對模型參數(權重)進行初始化,初始化方法包括:uniform、lecun_uniform、normal、orthogonal、zero、glorot_normal、he_normal等
model.add(Dense(input_dim=3,output_dim=5,init='uniform')) #加入帶初始化(uniform)的隱含層
6.Activations
包:keras.activations、keras.layers.advanced_activations(新激活函數)
該模塊主要負責為神經層附加激活函數,如linear、sigmoid、hard_sigmoid、tanh、softplus、relu、 softplus以及LeakyReLU等比較新的激活函數
Keras的Sequential模型
Keras的核心數據結構是“模型”,模型是一種組織網絡層的方式。Keras中主要的模型是Sequential模型,Sequential是一系列網絡層按順序構成的棧。你也可以查看函數式模型來學習建立更復雜的模型。
Sequential模型如下:
- from keras.models import Sequential
- model = Sequential()
將一些網絡層通過.add()堆疊起來,就構成了一個模型:
- from keras.layers import Dense, Activation
- model.add(Dense(units=64, input_dim=100))
- model.add(Activation("relu"))
- model.add(Dense(units=10))
- model.add(Activation("softmax"))
完成模型的搭建后,我們需要使用.compile()方法來編譯模型:
- model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
編譯模型時必須指明損失函數和優化器,如果你需要的話,也可以自己定制損失函數。Keras的一個核心理念就是簡明易用同時,保證用戶對Keras的絕對控制力度,用戶可以根據自己的需要定制自己的模型、網絡層,甚至修改源代碼。
- from keras.optimizers import SGD
- model.compile(loss='categorical_crossentropy', optimizer=SGD(lr=0.01, momentum=0.9, nesterov=True))
完成模型編譯后,我們在訓練數據上按batch進行一定次數的迭代來訓練網絡
- model.fit(x_train, y_train, epochs=5, batch_size=32)
當然,我們也可以手動將一個個batch的數據送入網絡中訓練,這時候需要使用:model.train_on_batch(x_batch, y_batch)
隨后,我們可以使用一行代碼對我們的模型進行評估,看看模型的指標是否滿足我們的要求:
- loss_and_metrics = model.evaluate(x_test, y_test, batch_size=128)
或者,我們可以使用我們的模型,對新的數據進行預測:
- classes = model.predict(x_test, batch_size=128)
搭建一個問答系統、圖像分類模型,或神經圖靈機、word2vec詞嵌入器就是這么快。支撐深度學習的基本想法本就是簡單的,現在讓我們把它的實現也變的簡單起來!
代碼體驗
- import pandas as pd
- #讀取數據
- input_file='./sales_data.xls'
- data=pd.read_excel(input_file,index_col='序號')
- #將數據的類別標簽轉換為數據
- data[data=='好']=1
- data[data=='是']=1
- data[data=='高']=1
- data[data!=1]=0
- x=data.iloc[:,:3].as_matrix().astype(int)#選取訓練集,轉換為矩陣形式,并且注意類型
- y=data.iloc[:,3].as_matrix().astype(int)
- from keras.models import Sequential
- from keras.layers.core import Dense,Activation
- model=Sequential()#建立模型
- model.add(Dense(input_dim=3,output_dim=10))
- model.add(Activation('relu'))#用relu作為激活函數
- model.add(Dense(input_dim=10,output_dim=1))
- model.add(Activation('sigmoid'))#輸出分類0或1
- model.compile(loss = 'binary_crossentropy', optimizer = 'adam')
- model.fit(x,y,nb_epoch = 1000, batch_size = 10) #訓練模型,學習一千次yp=model.predict_classes(x).reshape(len(y)) #分類預測
- yp = model.predict_classes(x).reshape(len(y)) #分類預測
- import matplotlib.pyplot as plt #導入作圖庫
- from sklearn.metrics import confusion_matrix #導入混淆矩陣函數
- def cm_plot(y, yp):
- cm = confusion_matrix(y, yp) #混淆矩陣
- plt.matshow(cm, cmap=plt.cm.Greens) #畫混淆矩陣圖,配色風格使用cm.Greens,更多風格請參考官網。
- plt.colorbar() #顏色標簽
- for x in range(len(cm)): #數據標簽
- for y in range(len(cm)):
- plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center')
- plt.ylabel('True label') #坐標軸標簽
- plt.xlabel('Predicted label') #坐標軸標簽
- return plt
- cm_plot(y,yp).show() #顯示混淆矩陣可視化結果
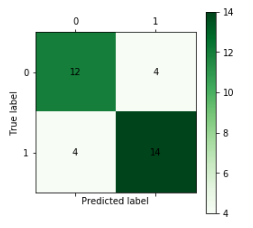
從圖可以看出, 檢測樣本為34個, 預測正確的個數為26個, 預測準確率為76.4%, 預測準確率較低, 是由于神經網絡訓練時需要較多樣本, 而這里是由于訓練數據較少造成的。
需要指出的是, 這里的案例比較簡單,我們并沒有考慮過擬合的問題。事實上,神經網絡的擬合能力是很強的,容易出現過擬合現象。跟傳統的添加“懲罰項”的做法不同, 目前神經網絡(尤其是深度神經網絡)中流行的防止過擬合的方法是隨機地讓部分神經網絡節點休眠,也就是dropout,dropout可參考文章http://mp.weixin.qq.com/s/OB3xBKWHH1lAo-yBdlJVFg。
參考文獻:
1、http://blog.csdn.net/han_xiaoyang/article/details/49123419
2、https://www.cnblogs.com/leoo2sk/archive/2010/09/19/decision-tree.html
3、Python數據分析與挖掘實戰
4、http://www.coin163.com/it/x7874130266141340969
5、http://keras-cn.readthedocs.io/en/latest/