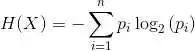機器學習算法實踐:決策樹 (Decision Tree)
前言
最近打算系統(tǒng)學習下機器學習的基礎(chǔ)算法,避免眼高手低,決定把常用的機器學習基礎(chǔ)算法都實現(xiàn)一遍以便加深印象。本文為這系列博客的第一篇,關(guān)于決策樹(Decision Tree)的算法實現(xiàn),文中我將對決策樹種涉及到的算法進行總結(jié)并附上自己相關(guān)的實現(xiàn)代碼。所有算法代碼以及用于相應(yīng)模型的訓練的數(shù)據(jù)都會放到GitHub上(https://github.com/PytLab/MLBox).
本文中我將一步步通過MLiA的隱形眼鏡處方數(shù)集構(gòu)建決策樹并使用Graphviz將決策樹可視化。
正文
決策樹學習
決策樹學習是根據(jù)數(shù)據(jù)的屬性采用樹狀結(jié)構(gòu)建立的一種決策模型,可以用此模型解決分類和回歸問題。常見的算法包括 CART(Classification And Regression Tree), ID3, C4.5等。我們往往根據(jù)數(shù)據(jù)集來構(gòu)建一棵決策樹,他的一個重要任務(wù)就是為了數(shù)據(jù)中所蘊含的知識信息,并提取出一系列的規(guī)則,這些規(guī)則也就是樹結(jié)構(gòu)的創(chuàng)建過程就是機器學習的過程。
決策樹的結(jié)構(gòu)
以下面一個簡單的用于是否買電腦預(yù)測的決策樹為例子,樹中的內(nèi)部節(jié)點表示某個屬性,節(jié)點引出的分支表示此屬性的所有可能的值,葉子節(jié)點表示最終的判斷結(jié)果也就是類型。
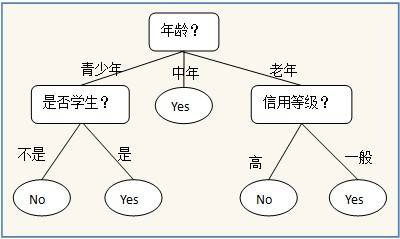
借助可視化工具例如Graphviz,matplotlib的注解等等都可以講我們創(chuàng)建的決策樹模型可視化并直接被人理解,這是貝葉斯神經(jīng)網(wǎng)絡(luò)等算法沒有的特性。
決策樹算法
決策樹算法主要是指決策樹進行創(chuàng)建中進行樹分裂(劃分數(shù)據(jù)集)的時候選取最優(yōu)特征的算法,他的主要目的就是要選取一個特征能夠?qū)⒎珠_的數(shù)據(jù)集盡量的規(guī)整,也就是盡可能的純. 最大的原則就是: 將無序的數(shù)據(jù)變得更加有序
這里總結(jié)下三個常用的方法:
- 信息增益(information gain)
- 增益比率(gain ratio)
- 基尼不純度(Gini impurity)
信息增益 (Information gain)
這里涉及到了信息論中的一些概念:某個事件的信息量,信息熵,信息增益等, 關(guān)于事件信息的通俗解釋可以看知乎上的一個回答
- 某個事件 i 的信息量: 這個事件發(fā)生的概率的負對數(shù)
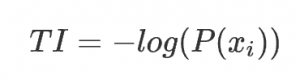
- 信息熵就是平均而言一個事件發(fā)生得到的信息量大小,也就是信息量的期望值

任何一個序列都可以獲取這個序列的信息熵,也就是將此序列分類后統(tǒng)計每個類型的概率,再用上述公式計算,使用Python實現(xiàn)如下:
- def get_shanno_entropy(self, values):
- ''' 根據(jù)給定列表中的值計算其Shanno Entropy
- '''
- uniq_vals = set(values)
- val_nums = {key: values.count(key) for key in uniq_vals}
- probs = [v/len(values) for k, v in val_nums.items()]
- entropy = sum([-prob*log2(prob) for prob in probs])
- return entropy
信息增益
我們將一組數(shù)據(jù)集進行劃分后,數(shù)據(jù)的信息熵會發(fā)生改變,我們可以通過使用信息熵的計算公式分別計算被劃分的子數(shù)據(jù)集的信息熵并計算他們的平均值(期望值)來作為分割后的數(shù)據(jù)集的信息熵。新的信息熵的相比未劃分數(shù)據(jù)的信息熵的減小值便是信息增益了. 這里我在最初就理解錯了,于是寫出的代碼并不能創(chuàng)建正確的決策樹。
假設(shè)我們將數(shù)據(jù)集D劃分成kk 份D1,D2,…,Dk,則劃分后的信息熵為:
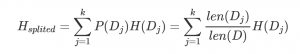
信息增益便是兩個信息熵的差值
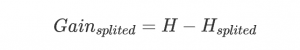
在這里我主要使用信息增益來進行屬性選擇,具體的實現(xiàn)代碼如下:
- def choose_best_split_feature(self, dataset, classes):
- ''' 根據(jù)信息增益確定最好的劃分數(shù)據(jù)的特征
- :param dataset: 待劃分的數(shù)據(jù)集
- :param classes: 數(shù)據(jù)集對應(yīng)的類型
- :return: 劃分數(shù)據(jù)的增益最大的屬性索引
- '''
- base_entropy = self.get_shanno_entropy(classes)
- feat_num = len(dataset[0])
- entropy_gains = []
- for i in range(feat_num):
- splited_dict = self.split_dataset(dataset, classes, i)
- new_entropy = sum([
- len(sub_classes)/len(classes)*self.get_shanno_entropy(sub_classes)
- for _, (_, sub_classes) in splited_dict.items()
- ])
- entropy_gains.append(base_entropy - new_entropy)
- return entropy_gains.index(max(entropy_gains))
增益比率
增益比率是信息增益方法的一種擴展,是為了克服信息增益帶來的弱泛化的缺陷。因為按照信息增益選擇,總是會傾向于選擇分支多的屬性,這樣會是的每個子集的信息熵最小。例如給每個數(shù)據(jù)添加一個第一無二的id值特征,則按照這個id值進行分類是獲得信息增益最大的,這樣每個子集中的信息熵都為0,但是這樣的分類便沒有任何意義,沒有任何泛化能力,類似過擬合。
因此我們可以通過引入一個分裂信息來找到一個更合適的衡量數(shù)據(jù)劃分的標準,即增益比率。
分裂信息的公式表示為:
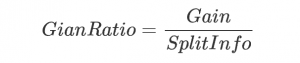
當然SplitInfo有可能趨近于0,這個時候增益比率就會變得非常大而不可信,因此有時還需在分母上添加一個平滑函數(shù),具體的可以參考參考部分列出的文章
基尼不純度(Gini impurity)
基尼不純度的定義:
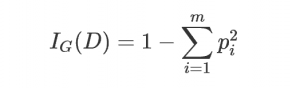
其中m 表示數(shù)據(jù)集D 中類別的個數(shù), pi 表示某種類型出現(xiàn)的概率。可見當只有一種類型的時候基尼不純度的值為0,此時不純度最低。
針對劃分成k個子數(shù)據(jù)集的數(shù)據(jù)集的基尼不純度可以通過如下式子計算:
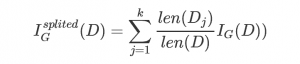
由此我們可以根據(jù)不純度的變化來選取最有的樹分裂屬性
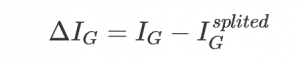
樹分裂
有了選取最佳分裂屬性的算法,下面我們就需要根據(jù)選擇的屬性來將樹進一步的分裂。所謂樹分裂只不過是根據(jù)選擇的屬性將數(shù)據(jù)集劃分,然后在總劃分出來的數(shù)據(jù)集中再次調(diào)用選取屬性的方法選取子數(shù)據(jù)集的中屬性。實現(xiàn)的最好方式就是遞歸了.
關(guān)于用什么數(shù)據(jù)結(jié)構(gòu)來表示決策樹,在Python中可以使用字典很方便的表示決策樹的嵌套,一個樹的根節(jié)點便是屬性,屬性對應(yīng)的值又是一個新的字典,其中key為屬性的可能值,value為新的子樹。
下面是我使用Python實現(xiàn)的根據(jù)數(shù)據(jù)集創(chuàng)建決策樹:
- def create_tree(self, dataset, classes, feat_names):
- ''' 根據(jù)當前數(shù)據(jù)集遞歸創(chuàng)建決策樹
- :param dataset: 數(shù)據(jù)集
- :param feat_names: 數(shù)據(jù)集中數(shù)據(jù)相應(yīng)的特征名稱
- :param classes: 數(shù)據(jù)集中數(shù)據(jù)相應(yīng)的類型
- :param tree: 以字典形式返回決策樹
- '''
- # 如果數(shù)據(jù)集中只有一種類型停止樹分裂
- if len(set(classes)) == 1:
- return classes[0]
- # 如果遍歷完所有特征,返回比例最多的類型
- if len(feat_names) == 0:
- return get_majority(classes)
- # 分裂創(chuàng)建新的子樹
- tree = {}
- best_feat_idx = self.choose_best_split_feature(dataset, classes)
- feature = feat_names[best_feat_idx]
- tree[feature] = {}
- # 創(chuàng)建用于遞歸創(chuàng)建子樹的子數(shù)據(jù)集
- sub_feat_names = feat_names[:]
- sub_feat_names.pop(best_feat_idx)
- splited_dict = self.split_dataset(dataset, classes, best_feat_idx)
- for feat_val, (sub_dataset, sub_classes) in splited_dict.items():
- tree[feature][feat_val] = self.create_tree(sub_dataset,
- sub_classes,
- sub_feat_names)
- self.tree = tree
- self.feat_names = feat_names
- return tree
樹分裂的終止條件有兩個
- 一個是遍歷完所有的屬性
可以看到,在進行樹分裂的時候,我們的數(shù)據(jù)集中的數(shù)據(jù)向量的長度是不斷縮短的,當縮短到0時,說明數(shù)據(jù)集已經(jīng)將所有的屬性用盡,便也分裂不下去了, 這時我們選取最終子數(shù)據(jù)集中的眾數(shù)作為最終的分類結(jié)果放到葉子節(jié)點上.
- 另一個是新劃分的數(shù)據(jù)集中只有一個類型。
若某個節(jié)點所指向的數(shù)據(jù)集都是同一種類型,那自然沒有必要在分裂下去了即使屬性還沒有遍歷完.
構(gòu)建一棵決策樹
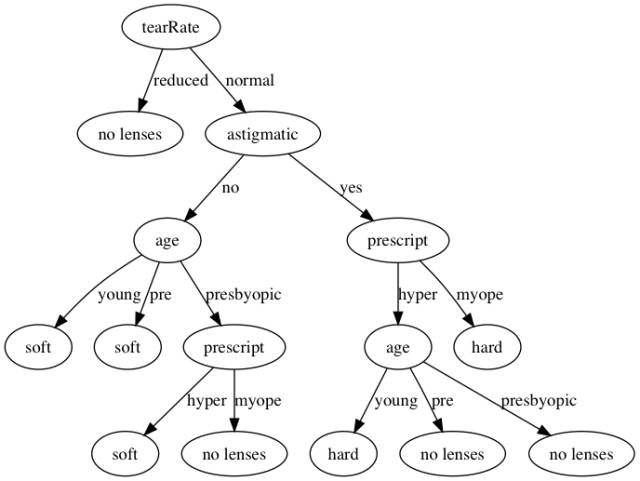
這我用了一下MLiA書上附帶的隱形眼鏡的數(shù)據(jù)來生成一棵決策樹,數(shù)據(jù)中包含了患者眼部狀況以及醫(yī)生推薦的隱形眼鏡類型.
首先先導(dǎo)入數(shù)據(jù)并將數(shù)據(jù)特征同類型分開作為訓練數(shù)據(jù)用于生成決策樹
- from trees import DecisionTreeClassifier
- lense_labels = ['age', 'prescript', 'astigmatic', 'tearRate']
- X = []
- Y = []
- with open('lenses.txt', 'r') as f:
- for line in f:
- comps = line.strip().split('\t')
- X.append(comps[: -1])
- Y.append(comps[-1])
生成決策樹:
- clf = DecisionTreeClassifier()
- clf.create_tree(X, Y, lense_labels)
查看生成的決策樹:
- In [2]: clf.tree
- Out[2]:
- {'tearRate': {'normal': {'astigmatic': {'no': {'age': {'pre': 'soft',
- 'presbyopic': {'prescript': {'hyper': 'soft', 'myope': 'no lenses'}},
- 'young': 'soft'}},
- 'yes': {'prescript': {'hyper': {'age': {'pre': 'no lenses',
- 'presbyopic': 'no lenses',
- 'young': 'hard'}},
- 'myope': 'hard'}}}},
- 'reduced': 'no lenses'}}
可視化決策樹
直接通過嵌套字典表示決策樹對人來說不好理解,我們需要借助可視化工具可視化樹結(jié)構(gòu),這里我將使用Graphviz來可視化樹結(jié)構(gòu)。為此實現(xiàn)了講字典表示的樹生成Graphviz Dot文件內(nèi)容的函數(shù),大致思想就是遞歸獲取整棵樹的所有節(jié)點和連接節(jié)點的邊然后將這些節(jié)點和邊生成Dot格式的字符串寫入文件中并繪圖。
遞歸獲取樹的節(jié)點和邊,其中使用了uuid給每個節(jié)點添加了id屬性以便將相同屬性的節(jié)點區(qū)分開.
- def get_nodes_edges(self, tree=None, root_node=None):
- ''' 返回樹中所有節(jié)點和邊
- '''
- Node = namedtuple('Node', ['id', 'label'])
- Edge = namedtuple('Edge', ['start', 'end', 'label'])
- if tree is None:
- tree = self.tree
- if type(tree) is not dict:
- return [], []
- nodes, edges = [], []
- if root_node is None:
- label = list(tree.keys())[0]
- root_node = Node._make([uuid.uuid4(), label])
- nodes.append(root_node)
- for edge_label, sub_tree in tree[root_node.label].items():
- node_label = list(sub_tree.keys())[0] if type(sub_tree) is dict else sub_tree
- sub_node = Node._make([uuid.uuid4(), node_label])
- nodes.append(sub_node)
- edge = Edge._make([root_node, sub_node, edge_label])
- edges.append(edge)
- sub_nodes, sub_edges = self.get_nodes_edges(sub_tree, root_node=sub_node)
- nodes.extend(sub_nodes)
- edges.extend(sub_edges)
- return nodes, edges
生成dot文件內(nèi)容
- def dotify(self, tree=None):
- ''' 獲取樹的Graphviz Dot文件的內(nèi)容
- '''
- if tree is None:
- tree = self.tree
- content = 'digraph decision_tree {\n'
- nodes, edges = self.get_nodes_edges(tree)
- for node in nodes:
- content += ' "{}" [label="{}"];\n'.format(node.id, node.label)
- for edge in edges:
- start, label, end = edge.start, edge.label, edge.end
- content += ' "{}" -> "{}" [label="{}"];\n'.format(start.id, end.id, label)
- content += '}'
- return content
隱形眼鏡數(shù)據(jù)生成Dot文件內(nèi)容如下:
- digraph decision_tree {
- "959b4c0c-1821-446d-94a1-c619c2decfcd" [label="call"];
- "18665160-b058-437f-9b2e-05df2eb55661" [label="to"];
- "2eb9860d-d241-45ca-85e6-cbd80fe2ebf7" [label="your"];
- "bcbcc17c-9e2a-4bd4-a039-6e51fde5f8fd" [label="areyouunique"];
- "ca091fc7-8a4e-4970-9ec3-485a4628ad29" [label="02073162414"];
- "aac20872-1aac-499d-b2b5-caf0ef56eff3" [label="ham"];
- "18aa8685-a6e8-4d76-bad5-ccea922bb14d" [label="spam"];
- "3f7f30b1-4dbb-4459-9f25-358ad3c6d50b" [label="spam"];
- "44d1f972-cd97-4636-b6e6-a389bf560656" [label="spam"];
- "7f3c8562-69b5-47a9-8ee4-898bd4b6b506" [label="i"];
- "a6f22325-8841-4a81-bc04-4e7485117aa1" [label="spam"];
- "c181fe42-fd3c-48db-968a-502f8dd462a4" [label="ldn"];
- "51b9477a-0326-4774-8622-24d1d869a283" [label="ham"];
- "16f6aecd-c675-4291-867c-6c64d27eb3fc" [label="spam"];
- "adb05303-813a-4fe0-bf98-c319eb70be48" [label="spam"];
- "959b4c0c-1821-446d-94a1-c619c2decfcd" -> "18665160-b058-437f-9b2e-05df2eb55661" [label="0"];
- "18665160-b058-437f-9b2e-05df2eb55661" -> "2eb9860d-d241-45ca-85e6-cbd80fe2ebf7" [label="0"];
- "2eb9860d-d241-45ca-85e6-cbd80fe2ebf7" -> "bcbcc17c-9e2a-4bd4-a039-6e51fde5f8fd" [label="0"];
- "bcbcc17c-9e2a-4bd4-a039-6e51fde5f8fd" -> "ca091fc7-8a4e-4970-9ec3-485a4628ad29" [label="0"];
- "ca091fc7-8a4e-4970-9ec3-485a4628ad29" -> "aac20872-1aac-499d-b2b5-caf0ef56eff3" [label="0"];
- "ca091fc7-8a4e-4970-9ec3-485a4628ad29" -> "18aa8685-a6e8-4d76-bad5-ccea922bb14d" [label="1"];
- "bcbcc17c-9e2a-4bd4-a039-6e51fde5f8fd" -> "3f7f30b1-4dbb-4459-9f25-358ad3c6d50b" [label="1"];
- "2eb9860d-d241-45ca-85e6-cbd80fe2ebf7" -> "44d1f972-cd97-4636-b6e6-a389bf560656" [label="1"];
- "18665160-b058-437f-9b2e-05df2eb55661" -> "7f3c8562-69b5-47a9-8ee4-898bd4b6b506" [label="1"];
- "7f3c8562-69b5-47a9-8ee4-898bd4b6b506" -> "a6f22325-8841-4a81-bc04-4e7485117aa1" [label="0"];
- "7f3c8562-69b5-47a9-8ee4-898bd4b6b506" -> "c181fe42-fd3c-48db-968a-502f8dd462a4" [label="1"];
- "c181fe42-fd3c-48db-968a-502f8dd462a4" -> "51b9477a-0326-4774-8622-24d1d869a283" [label="0"];
- "c181fe42-fd3c-48db-968a-502f8dd462a4" -> "16f6aecd-c675-4291-867c-6c64d27eb3fc" [label="1"];
- "959b4c0c-1821-446d-94a1-c619c2decfcd" -> "adb05303-813a-4fe0-bf98-c319eb70be48" [label="1"];
- }
這樣我們便可以使用Graphviz將決策樹繪制出來
- with open('lenses.dot', 'w') as f:
- dot = clf.tree.dotify()
- f.write(dot)
- dot -Tgif lenses.dot -o lenses.gif
效果如下:
使用生成的決策樹進行分類
對未知數(shù)據(jù)進行預(yù)測,主要是根據(jù)樹中的節(jié)點遞歸的找到葉子節(jié)點即可。z這里可以通過為遞歸進行優(yōu)化,代碼實現(xiàn)如下:
- def classify(self, data_vect, feat_names=None, tree=None):
- ''' 根據(jù)構(gòu)建的決策樹對數(shù)據(jù)進行分類
- '''
- if tree is None:
- tree = self.tree
- if feat_names is None:
- feat_names = self.feat_names
- # Recursive base case.
- if type(tree) is not dict:
- return tree
- feature = list(tree.keys())[0]
- value = data_vect[feat_names.index(feature)]
- sub_tree = tree[feature][value]
- return self.classify(feat_names, data_vect, sub_tree)
決策樹的存儲
通過字典表示決策樹,這樣我們可以通過內(nèi)置的pickle或者json模塊將其存儲到硬盤上,同時也可以從硬盤中讀取樹結(jié)構(gòu),這樣在數(shù)據(jù)集很大的時候可以節(jié)省構(gòu)建決策樹的時間.
- def dump_tree(self, filename, tree=None):
- ''' 存儲決策樹
- '''
- if tree is None:
- tree = self.tree
- with open(filename, 'w') as f:
- pickle.dump(tree, f)
- def load_tree(self, filename):
- ''' 加載樹結(jié)構(gòu)
- '''
- with open(filename, 'r') as f:
- tree = pickle.load(f)
- self.tree = tree
- return tree
總結(jié)
本文一步步實現(xiàn)了決策樹的實現(xiàn), 其中使用了ID3算法確定最佳劃分屬性,并通過Graphviz可視化了構(gòu)建的決策樹。本文相關(guān)的代碼鏈接: https://github.com/PytLab/MLBox/tree/master/decision_tree
參考:
- 《Machine Learning in Action》
- 數(shù)據(jù)挖掘系列(6)決策樹分類算法