我們分析了最流行的歌詞,教你用RNN寫詞編曲(附代碼)
此文展示了基于RNN的生成模型在歌詞和鋼琴音樂上的應用。
介紹
在這篇博文中,我們將在歌詞數據集上訓練RNN字符級語言模型,數據集來自最受歡迎以及最新發布的藝術家的作品。模型訓練好之后,我們會選出幾首歌曲,這些歌曲將會是不同風格的不同藝術家的有趣混合。之后,我們將更新模型使之成為一個條件字符級RNN,使我們能夠從藝術家的歌曲中采樣。最后,我們通過對鋼琴曲的midi數據集的訓練來總結。
在解決這些任務的同時,我們將簡要地探討一些有關RNN訓練和推斷的有趣概念,如字符級RNN,條件字符級RNN,從RNN采樣,經過時間截斷的反向傳播和梯度檢查點。
所有的代碼和訓練模型都已在 github 上開源,并通過 PyTorch 實現。這篇博文同樣也可用jupyter notebook 閱讀。如果你已經熟悉字符級語言模型和循環神經網絡,可以隨意跳過各個部分或直接進入結果部分。
字符級語言模型
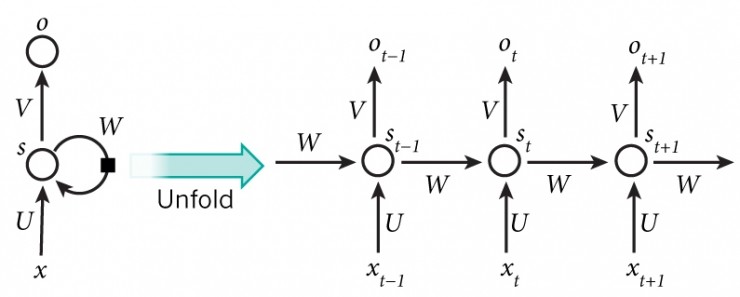
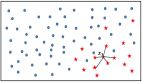
在選擇模型前,讓我們仔細看看我們的任務。基于現有的字母和所有之前的字母,我們將預測下一個字符。在訓練過程中,我們只使用一個序列,除了最后一個字符外,序列中的其他字符將作為輸入,并從第二個字符開始,作為groundtruth(見上圖:源)。我們將從最簡單的模型開始,在進行預測時忽略所有前面的字符,然后改善這個模型使其只考慮一定數量的前面的字符,最后得到一個考慮所有前面的字符的模型。
我們的語言模型定義在字符級別。我們將創建一個包含所有英文字符和一些特殊符號(如句號,逗號和行尾符號)的字典。每個字符將被表示為一個獨熱編碼的張量。有關字符級模型和示例的更多信息,推薦此資源。
有了字符后,我們可以生成字符序列。即使是現在,也可以通過隨機抽樣字符和固定概率p(any letter)=1和字典大小p(any letter)=1dictionary size來生成句子。這是最簡單的字符級語言模型。可以做得更好嗎?當然可以,我們可以從訓練語料庫中計算每個字母的出現概率(一個字母出現的次數除以我們的數據集的大小),并且用這些概率隨機抽樣。這個模型更好但是它完全忽略了每個字母的相對位置。
舉個例子,注意你是如何閱讀單詞的:你從第一個字母開始,這通常很難預測,但是當你到達一個單詞的末尾時,你有時會猜到下一個字母。當你閱讀任何單詞時,你都隱含地使用了一些規則,通過閱讀其他文本學習:例如,你從單詞中讀到的每一個額外的字母,空格字符的概率就會增加(真正很長的單詞是罕見的),或者在字母"r"之后的出現輔音的概率就會變低,因為它通常跟隨元音。有很多類似的規則,我們希望我們的模型能夠從數據中學習。為了讓我們的模型有機會學習這些規則,我們需要擴展它。
讓我們對模型做一個小的逐步改進,讓每個字母的概率只取決于以前出現的字母(馬爾科夫假設)。所以,基本上我們會有p(current letter|previous letter)。這是一個馬爾科夫鏈模型(如果你不熟悉,也可以嘗試這些交互式可視化)。我們還可以從訓練數據集中估計概率分布p(current letter|previous letter)。但這個模型是有限的,因為在大多數情況下,當前字母的概率不僅取決于前一個字母。
我們想要建模的其實是p(current letter|all previous letters)。起初,這個任務看起來很棘手,因為前面的字母數量是可變的,在長序列的情況下它可能變得非常大。結果表明,在一定程度上,利用共享權重和固定大小的隱藏狀態,循環神經網絡可以解決這個問題,因此引出下一個討論RNNs的部分。
循環神經網絡
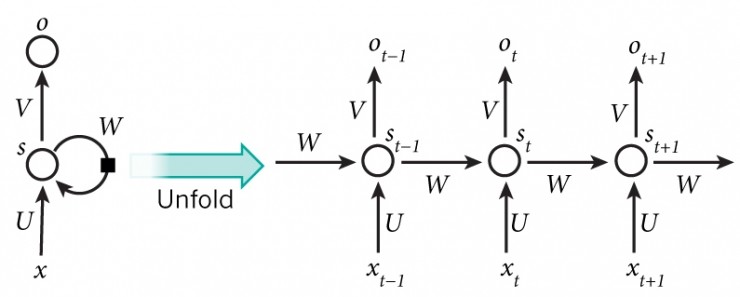
循環神經網絡是一族用于處理序列數據的神經網絡,與前饋神經網絡不同,RNNs可以使用其內部存儲器來處理任意輸入序列。
由于任意大小的輸入序列,它們被簡潔地描述為一個具有循環周期的圖(見上圖:源)。但是如果已知輸入序列的大小,則可以"展開"。定義一個非線性映射,從當前輸入xt 和先前隱藏狀態 st−1 到輸出ot 和隱藏狀態 st。隱藏狀態大小具有預定義的大小,存儲在每一步更新的特征,并影響映射的結果。
現在,將字符級語言模型的前一張圖片與已折疊的RNN圖片對齊,以了解我們如何使用RNN模型來學習字符級語言模型。
雖然圖片描繪了Vanilla RNN,但是我們在工作中使用LSTM,因為它更容易訓練,通常可以獲得更好的結果。
為了更詳細地介紹RNNs,推薦以下資源。
歌詞數據集
在實驗中,我們選擇了55000+ Song Lyrics Kaggle dataset,其中包含了很多近期的藝術家和更多經典的好作品。它存儲為pandas文件,并用python包裝,以便用于培訓。為了使用我們的代碼,你需要自行下載。
為了能夠更好地解釋結果,我選擇了一些我稍微熟悉的藝術家:
- artists = [
- 'ABBA',
- 'Ace Of Base',
- 'Aerosmith',
- 'Avril Lavigne',
- 'Backstreet Boys',
- 'Bob Marley',
- 'Bon Jovi',
- 'Britney Spears',
- 'Bruno Mars',
- 'Coldplay',
- 'Def Leppard',
- 'Depeche Mode',
- 'Ed Sheeran',
- 'Elton John',
- 'Elvis Presley',
- 'Eminem',
- 'Enrique Iglesias',
- 'Evanescence',
- 'Fall Out Boy',
- 'Foo Fighters',
- 'Green Day',
- 'HIM',
- 'Imagine Dragons',
- 'Incubus',
- 'Jimi Hendrix',
- 'Justin Bieber',
- 'Justin Timberlake',
- 'Kanye West',
- 'Katy Perry',
- 'The Killers',
- 'Kiss',
- 'Lady Gaga',
- 'Lana Del Rey',
- 'Linkin Park',
- 'Madonna',
- 'Marilyn Manson',
- 'Maroon 5',
- 'Metallica',
- 'Michael Bolton',
- 'Michael Jackson',
- 'Miley Cyrus',
- 'Nickelback',
- 'Nightwish',
- 'Nirvana',
- 'Oasis',
- 'Offspring',
- 'One Direction',
- 'Ozzy Osbourne',
- 'P!nk',
- 'Queen',
- 'Radiohead',
- 'Red Hot Chili Peppers',
- 'Rihanna',
- 'Robbie Williams',
- 'Rolling Stones',
- 'Roxette',
- 'Scorpions',
- 'Snoop Dogg',
- 'Sting',
- 'The Script',
- 'U2',
- 'Weezer',
- 'Yellowcard',
- 'ZZ Top']
訓練無條件的字符級語言模型
第一個實驗是在整個語料庫上訓練我們的字符級語言模型RNN,在訓練時沒有考慮藝術家的信息。
從RNN采樣
在訓練完模型之后,我們試著抽出幾首歌。基本上,RNN每一步都會輸出logits,我們可以利用softmax函數從分布中取樣。或者可以直接使用Gumble-Max技巧采樣,這和直接使用logits是等價的。
抽樣的一個有趣之處是,我們可以對輸入序列進行部分定義,并在初始條件下開始采樣。舉個例子,我們采樣以"Why"開頭的歌曲:
- Why do you have to leave me?
- I think I know I'm not the only one
- I don't know if I'm gonna stay awake
- I don't know why I go along
- I don't know why I can't go on
- I don't know why I don't know
- I don't know why I don't know
- I don't know why I keep on dreaming of you
那么,這聽起來像是一首歌。
讓我們來看一下以“Well”開頭的歌曲:
- Well, I was a real good time
- I was a rolling stone
- I was a rock and roller
- Well, I never had a rock and roll
- There were times I had to do it
- I had a feeling that I was found
- I was the one who had to go
采樣過程中使用的"temperature"參數控制采樣過程的隨機性。當這個參數接近零時,采樣等于argmax,當它接近無窮時,采樣等同于均勻分布的采樣。可以看一下相關論文中的圖(Jang et al):
當τ=1時,分布不受影響。如果我們減少 τ,分布變得更加明顯,意味著有更大概率質量的值會增加。當τ 接近零時,采樣將相當于argmax,因為該值的概率接近于1。當我們開始增加τ 時,分布變得越來越均勻。
之前的樣本是在"temperature"參數等于0.5的情況下生成的,讓我們看看當我們增加到1.0時會發生什么:
- Why can't we drop out of time?
- We were born for words to see.
- Won't you love this. You're still so amazing.
- This could be that down on Sunday Time.
- Oh, Caroline, a lady floor.
- I thought of love, oh baby.
讓我們進一步增加:
- Why - won't we grow up naked?
- We went quietly what we would've still give
- That girl you walked before our bedroom room
- I see your mind is so small to a freak
- Stretching for a cold white-heart of crashing
- Truth in the universal daughter
- I lose more and more hard
- I love you anytime at all
- Ah come let your help remind me
- Now I've wanted waste and never noticed
- I swear I saw you today
- You needed to get by
- But you sold a hurricane
- Well out whispered in store
我們為什么不直接一次性增加呢?
那么,你可以看到這樣的趨勢:當我們增加"temperature"時,采樣的句子變得越來越隨機。
訓練有條件的字符級語言模型
想象一下,如果我們能夠以某種特定藝術家的風格生成歌詞。讓我們改變我們的模型,以便在訓練期間使用這些信息。
我們將通過為我們的RNN增加一個額外的輸入來做到這一點。到目前為止,我們的RNN模型只接受每步包含one-hot編碼字符的張量。
對我們的模型的擴展將是非常簡單的:我們將擁有和額外的一個熱點編碼張量來代表藝術家。所以每一步RNN都會接受一個張量,這個張量由代表人物和藝術家的連續張量組成。更多信息可以點擊此處查看
從有條件語言模型RNN中抽樣
訓練結束后,我們抽取了一些藝術家的歌曲,部分結果如下所示:
Him:
- My fears
- And the moment don't make me sing
- So free from you
- The pain you love me yeah
- Whatever caused the warmth
- You smile you're happy
- You sit away
- You say it's all in vain
似乎真的有可能,尤其是使用了痛苦這個詞,這在藝術家的歌詞中是很常見的事實。
ABBA:
- Oh, my love it makes me close a thing
- You've been heard, I must have waited
- I hear you
- So I say
- Thank you for the music, that makes me cry
- And you moving my bad as me, ah-hang wind in the hell
- I was meant to be with you, I'll never be playing up
Bob Marley:
- Mercy on judgment, we got so much
- Alcohol, cry, cry, cry
- Why don't try to find our own
- I want to know, Lord, I wanna give you
- Just saving it, learned
- Is there any more?
- All that damage done
- That's all reason, don't worry
- Need a hammer
- I need you more and more
Coldplay:
- Look at the stars
- Into life matter where you lay
- Saying no doubt
- I don't want to fly
- In my dreams and fight today
- I will fall for you
- All I know
- And I want you to stay
- Into the night
- I want to live waiting
- With my love and always
- Have I wouldn't wasted
- Would it hurt you
Kanye West:
- I'm everywhere for you
- The way that it couldn't stop
- I mean it too late and love I made in the world
- I told you so I took the studs full cold-stop
- The hardest stressed growin'
- The hustler raisin' on my tears
- I know I'm true, one of your love
看起來很酷,但請記住,我們沒有跟蹤驗證的準確性,所以一些樣本行可能已經被rnn模型記住了。一個更好的方法是選擇一個模型,在訓練期間給出最好的驗證分數(見下一節我們用這種方式進行訓練的代碼)。
我們也注意到了一件有趣的事情:當你想用一個指定的起始字符串進行采樣時,無條件模型通常更好地表現出來。我們的直覺是,當從一個具有特定起始字符串的條件模型中抽樣時,我們實際上把兩個條件放在我們的模型開始字符串和一個藝術家之間。而且我們沒有足夠的數據來模擬這個條件分布(每個歌手的歌曲數量相對有限)。
我們正在使代碼和模型可用,并且即使沒有gpu,也可以從我們訓練好的模型中采樣歌曲,因為它計算量并不大。
Midi 數據集
接下來,我們將使用由大約700首鋼琴歌曲組成的小型midi數據集。我們使用了諾丁漢鋼琴數據集(僅限于訓練分割)。
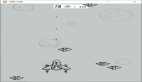
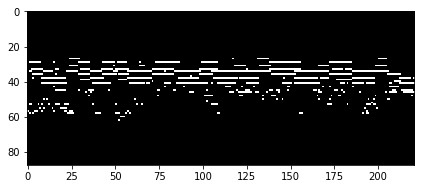
任何MIDI文件都可以轉換為鋼琴鍵軸,這只是一個時頻矩陣,其中每一行是不同的MIDI音高,每一列是不同的時間片。因此,我們數據集中的每首鋼琴曲都會被表示成一個大小的矩陣88×song_length,88 是鋼琴音調的個數。下圖是一個鋼琴鍵軸矩陣的例子:
即使對于一個不熟悉音樂理論的人來說,這種表現方式也很直觀,容易理解。每行代表一個音高:高處的行代表低頻部分,低處的行代表高頻部分。另外,我們有一個代表時間的橫軸。所以如果我們在一定時間內播放一定音調的聲音,我們會看到一條水平線。總而言之,這與YouTube上的鋼琴教程非常相似。
現在,我們來看看字符級模型和新任務之間的相似之處。在目前的情況下,給定以前播放過的所有音調, 我們將預測下一個時間步將要播放的音調。所以,如果你看一下鋼琴鍵軸的圖,每一列代表某種音樂字符,給定所有以前的音樂字符,預測下一個音樂字符。我們注意依一下文字字符與音樂字符的區別。回憶一下,語言模型中的每個字符都是由one-hot向量表示的(意思是我向量中只有一個值是1,其他都是0)。對于音樂字符,可以一次按下多個鍵(因為我們正在處理復音數據集)。在這種情況下,每個時間步將由一個可以包含多個1的向量表示。
培養音高水平的鋼琴音樂模型
在開始訓練之前,根據在前面討論過的不同的輸入,需要調整我們用于語言模型的損失函數。在語言模型中,我們在每個時間步上都有one-hot的編碼張量(字符級)作為輸入,用一個one-hot的編碼張量作為輸出(預測的下一個字符)。由于預測的下一個字符時使用獨占,我們使用交叉熵損失。
但是現在我們的模型輸出一個不再是one-hot編碼的矢量(可以按多個鍵)。當然,我們可以將所有可能的按鍵組合作為一個單獨的類來處理,但是這是比較難做的。相反,我們將輸出向量的每個元素作為一個二元變量(1表示正在按鍵,0表示沒有按鍵)。我們將為輸出向量的每個元素定義一個單獨的損失為二叉交叉熵。而我們的最終損失將是求這些二元交叉熵的平均和。可以閱讀代碼以獲得更好的理解。
按照上述的修改后,訓練模型。在下一節中,我們將執行采樣并檢查結果。
從音調水平的RNN采樣
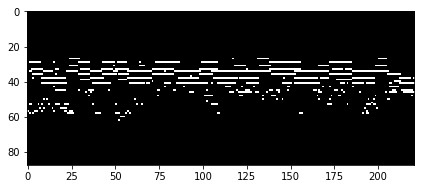
在優化的早期階段,我們采樣了鋼琴鍵軸:
可以看到,模型正在開始學習數據集中歌曲常見的一種常見模式:1首歌曲由2個不同的部分組成。第一部分包含一系列獨立播放的節奏,非常易辨,通常是可唱(也稱為旋律)。如果看著采樣的鋼琴鍵軸圖,這部分在底部。如果觀察鋼琴卷軸的頂部,可以看到一組通常一起演奏的音高 - 這是伴隨著旋律的和聲或和音(在整個歌曲中一起播放的部分)的進行。
訓練結束后,從模型中抽取樣本如下圖所示:
如圖所示,他們和前面章節中的所看到的真實情況相似。
訓練結束后,抽取歌曲進行分析。這里有一個有趣的介紹樣本。而另一個樣本,是具有很好的風格轉換。同時,我們生成了一些低速參數的例子,它們導致歌曲的速度慢了:這里是第一個和第二個。可以在這里找到整個播放列表。
序列長度和相關問題
現在讓我們從GPU內存消耗和速度的角度來看待我們的問題。
我們通過批量處理我們的序列大大加快了計算速度。同時,隨著序列變長(取決于數據集),我們的最大批量開始減少。為什么是這種情況?當我們使用反向傳播來計算梯度時,我們需要存儲所有對內存消耗貢獻最大的中間激活量。隨著我們的序列變長,我們需要存儲更多的激活量,因此,我們可以用更少的樣本在批中。
有時候,我們需要用很長的序列來工作,或者增加批的大小,而你只有1個有少量內存的GPU。在這種情況下,有多種可能的解決方案來減少內存消耗,這里,我們只提到兩種解決方案,它們之間需要取舍。
首先是一個截斷的后向傳播。這個想法是將整個序列拆分成子序列,并把它們分成不同的批,除了我們按照拆分的順序處理這些批,每一個下一批都使用前一批的隱藏狀態作為初始隱藏狀態。我們提供了這種方法的實現,以便能更好地理解。這種方法顯然不是處理整個序列的精確等價,但它使更新更加頻繁,同時消耗更少的內存。另一方面,我們有可能無法捕捉超過一個子序列的長期依賴關系。
第二個是梯度檢查點。這種方法使我們有可能在使用更少內存的同時,在整個序列上訓練我們的模型,以執行更多的計算。回憶,之前我們提到過訓練中的大部分內存資源是被激活量使用。梯度檢查點的思想包括僅存儲每個第n個激活量,并在稍后重新計算未保存的激活。這個方法已經在Tensorflow和Pytorch中實現。
結論和未來的工作
在我們的工作中,我們訓練了簡單的文本生成模型,擴展了模型以處理復調音樂,簡要介紹了采樣如何工作以及溫度參數如何影響我們的文本和音樂樣本 - 低溫提供了更穩定的結果,而高溫增加了更多的隨機性這有時會產生非常有趣的樣本。
未來的工作可以包括兩個方向 - 用訓練好的模型在更多的應用或更深入的分析上。例如,可以將相同的模型應用于Spotify收聽歷史記錄。在訓練完收聽歷史數據后,可以給它一段前一小時左右收聽的歌曲序列,并在當天余下時間為您播放一個播放列表。那么,也可以為你的瀏覽歷史做同樣的事情,這將是一個很酷的工具來分析你的瀏覽行為模式。在進行不同的活動(在健身房鍛煉,在辦公室工作,睡覺)時,從手機中獲取加速度計和陀螺儀數據,并學習分類這些活動階段。之后,您可以根據自己的活動自動更改音樂播放列表(睡眠 - 冷靜的音樂,在健身房鍛煉 - 高強度的音樂)。在醫學應用方面,模型可以應用于基于脈搏和其他數據檢測心臟問題,類似于這項工作。
分析在為音樂生成而訓練的RNN中的神經元激勵是非常有趣的,鏈接在這里。看模型是否隱含地學習了一些簡單的音樂概念(就像我們對和聲和旋律的討論)。 RNN的隱藏表示可以用來聚集我們的音樂數據集以找到相似的歌曲。
讓我們從我們無條件的模型中抽取最后一首歌詞來結束這篇文章:D:
- The story ends
- The sound of the blue
- The tears were shining
- The story of my life
- I still believe
- The story of my life