人工智能通過多域卷積神經網絡定位JPEG雙重壓縮圖像偽造區域
人工智能通過多域卷積神經網絡定位JPEG雙重壓縮圖像偽造區域人簡介:當攻擊者想要偽造圖像時,在大多數情況下,他/她將執行JPEG再壓縮。根據不同的理論假設開發了不同的技術,但尚未開發出非常有效的解決方案。最近,基于機器學習的方法已經開始出現在圖像取證領域,以解決各種任務,如采集源識別和偽造檢測。在最后一種情況下,未來的目標是獲得一個訓練有素的神經網絡,在給定待檢查圖像的情況下,可以可靠地定位偽造區域。考慮到這一點,我們的論文通過分析如何使用卷積神經網絡(CNN)揭示和定位單個或雙個JPEG壓縮,從而向這個方向邁出了一步。已經考慮了對CNN的不同類型的輸入,并且已經進行了各種實驗以試圖證明將要進一步研究的潛在問題。

現在,圖像和視頻作為主要信息來源的普遍性已經導致圖像預測界越來越多地質疑其可靠性和完整性。涉及圖片的上下文是不同的。一本雜志,一個社交網絡,一個保險實踐,一個審判的證據。這些圖像可以通過使用強大的編輯軟件輕松改變,通常不會對任何修改留下任何視覺痕跡,因此可靠地回答它們的完整性將成為最基本的。圖像取證技術通過開發技術手段來處理這些問題,這些技術手段只能根據圖像確定該資產是否已被修改,并且有時需要了解本地化篡改發生的情況。關于偽造品個性化,三種是迄今為止研究的主要類別的檢測器:基于特征描述符[1,6,7],基于不一致陰影[10]和最后基于雙倍JPEG壓縮。
通過多域卷積神經網絡定位JPEG雙重壓縮圖像偽造區域人工智能貢獻:近年來,機器學習和神經網絡(如卷積神經網絡(CNN))顯示出能夠提取復雜的統計特征并有效地學習其表示,從而能夠很好地在各種計算機視覺任務包括圖像識別和分類等。這些網絡在很多領域的廣泛使用促使和引導多媒體取證社區理解這些技術解決方案是否可以用于利用源識別[20,3]或用于圖像和視頻操縱檢測。特別是,王等人。 [23]使用離散余弦變換(DCT)系數的直方圖作為CNN的輸入來檢測單個或雙重JPEG壓縮,以檢測篡改圖像。 背后的主要思想是開發一種預處理模塊,用于在訓練CNN之前抑制圖像內容;而在[16]CNN體系結構在沒有預處理的情況下被提供補丁,被篡改區域的鉆石被篡改。雖然對圖像取證領域的神經網絡的興趣正在增長,但對其可能完成的一個真正的理解仍處于早期階段。
本文向這個方向邁出了一步。我們的目標是訓練一個神經網絡,在給定待檢查圖像的情況下,通過分析單個或雙重JPEG壓縮區域的存在,能夠可靠地定位可能的偽造區域。具體而言,已經提出了不同種類的基于CNN的方法,并給出了網絡的不同輸入。首先,利用基于空間域的CNN從RGB彩色圖像開始執行圖像偽造檢測;既不進行預處理,也不采用邊界信息。 CNN經過訓練能夠區分未壓縮的單張和雙張JPEG壓縮圖像,以顯示主要(隱藏)JPEG壓縮,然后定位偽造區域。其次,引入另一個基于頻域CNN作為輸入到網絡的DCT系數的直方圖,類似[23]。所提出的第三種方法是基于多域的CNN能夠加入前面關于RGB補丁和DCT直方圖的兩個輸入信息。這項工作的主要貢獻是探索空間域CNN及其與圖像偽造檢測任務的頻域組合的使用。已經進行了不同的實驗測試,試圖證明有待進一步調查和改進的潛在問題。
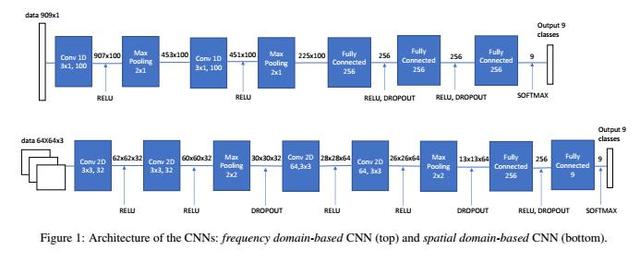
通過多域卷積神經網絡定位JPEG雙重壓縮圖像偽造區域人工智能基于CNN的提議方法在這項工作中,我們的目標是調查識別未壓縮的單個或雙重壓縮圖像的可能性,意圖檢測拼接攻擊中涉及的圖像區域。除此之外,我們的第二個目標是在應用二次壓縮之前揭示應用于圖像或貼片的主要品質因數。為了完成這項任務,基于給予網絡和網絡本身的輸入數據設計了三種不同的基于CNN的方法。卷積神經網絡由幾個級聯的卷積層和池層組成,后面是一個或多個完全連接的層。在所提出的方法中,每個被考慮的CNN在網絡的組成部分如何組合在一起以及來自所使用的層數方面與其他方面不同,正如下面詳細描述的那樣。為了直接從數據中學習判別特征,訓練階段需要一套一致的標記圖像。出于這個原因,對于所有考慮的方法,不同大小的圖像被分成不同大小的片段(不重疊),然后將它們中的每一個都送入網絡。與輸入不同的是,這些方法不同,網絡的輸出是相同的。特別是,三種不同的CNN能夠識別9類:未壓迫的,單壓縮的和雙壓縮的貼片(7個質量因子從60到95,逐步考慮5)。
通過多域卷積神經網絡定位JPEG雙重壓縮圖像偽造區域人工智能空間域CNN:在第一種基于CNN的方法中,命名為基于空間域的CNN,網絡的輸入是三個顏色通道(RGB)上的N×N尺寸補丁,預處理根本不被考慮,并且僅僅是數據的規范化在0和1之間)被執行。首先設計卷積網絡[12],并在圖1(上)中進行了總結。這個特定的網絡由兩個卷積塊和兩個完全連接的層組成。每個卷積塊由兩個卷積層組成,其中ReLU激活后面跟著一個匯聚層。所有卷積層使用3x3的內核大小,而共享層內核大小為2×2。為了防止過度擬合,我們使用Dropout,在完全連接的層次上隨機丟棄訓練時的單位。特別是,這種類型的CNN針對每個考慮的二次質量因子QF2 = 60:5:95進行訓練。因此,我們獲得了與QF2的每個值相對應的八個不同的分類器。每個分類器都需要為輸入補丁輸出兩級分類。首先是未壓縮的單壓縮和雙壓縮補丁之間的類間分類。其次是QF1的內部類別(在60:5:95的范圍內,不包括QF1 = QF2)在雙重壓縮補丁的情況下。因此,我們選擇為每個QF1輸出9個普通類,未壓縮類,單個壓縮類和一個類。結果,CNN的最后一個完全連接的層被發送到九路軟最大連接,這產生了每個樣本應被分類到每個類中的概率。作為損失函數,我們使用分類交叉熵函數[22]。我們注意到,錯誤分類雙重壓縮補丁的內部類型是錯誤的,而錯誤地將補丁的類別分類。因此,我們調整損失以將類內錯誤加權為類間錯誤的1/9。在我們的初步實驗中,這改善了課堂內分類的準確性。所提出的CNN模型是基于來自由未壓縮的單壓縮貼片或雙壓縮貼片構成的訓練集(即QF2 = 90和QF1從60變化到95)組成的標簽貼片樣本進行訓練的。在測試階段,八個訓練的CNN中的一個(根據保存在JPEG格式的EXIF頭中的質量因子進行選擇)用于通過將補丁大小的滑動窗口應用于掃描來提取測試圖像的基于補丁的特征整個圖像,為每個補丁分配一個類,從而在圖像級執行定位。
通過多域卷積神經網絡定位JPEG雙重壓縮圖像偽造區域人工智能頻域CNN:在第二種提出的方法中,基于頻域的CNN,根據[23]擴展評估系數數目的想法,對給定的補丁執行預處理,以計算DCT系數的直方圖。詳細地說,給定一個N×N片,提取DCT系數,并且對于每個8×8塊,選擇以之字形掃描順序(DC被跳過)的前9個空間頻率。對于每個空間頻率i,j,建立表示量化的DCT值的絕對值的出現的直方圖hi,j。具體而言,hi,j(m)是m =(50..0,+50)的i,j DCT系數的直方圖中的值m的數量。因此,該網絡共有909個元素(101個直方圖箱×9個DCT頻率)的矢量作為輸入。再次,如前所述,訓練8個CNN的陣列,它們中的每一個對應于第二壓縮品質因子QF2的不同值。然后使用特征向量來訓練每個CNN,以便區分之前定義的9個類別(未壓縮,單一壓縮和雙重壓縮,QF2固定和主要質量因子在QF1 = 60:5:95中變化)。所提出的CNN模型的架構如圖1所示(下圖)。它包含兩個卷積層,然后是兩個池連接和三個完整連接。輸入數據的大小是909x1,輸出是九個類的分布。每個完全連接的層有256個神經元,最后一個層的輸出發送到九路softmax,這產生了每個樣本應該被分類到每個類中的概率。在我們的網絡中,每層都使用整流線性單元(ReLU)f(x)= max(0,x)作為激勵函數。在兩個完全連接的層中,使用Dropout技術。
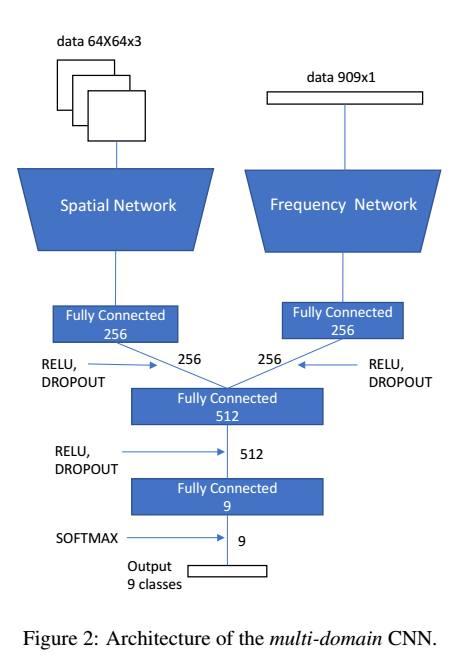
通過多域卷積神經網絡定位JPEG雙重壓縮圖像偽造區域人工智能多域CNN:第三個考慮的方法是一個多域CNN,其中三個通道色塊和在該色塊上計算的DCT系數的直方圖用作網絡的輸入以便結合前兩種方法。在圖2中,提出的網絡被描繪出來,它由一個基于空間域的CNN和一個基于頻域的CNN組成,直到它們的第一個完全連接的層。基于多域的CNN學習來自R,G,B域和來自DCT的直方圖的特征之間的模式間關系,將兩個網絡的完全連接層(每個256維)的輸出連接在一起。通過這種方式,最后一個完全連接的層有512個神經元,并且輸出被發送到九路softmax連接,這產生了每個樣本也使用一個丟失層分類到每個類中的概率。因此,與之前一樣,根據QF2的每個值設計八個不同的9類分類器。訓練和測試階段與以前一樣進行。
通過多域卷積神經網絡定位JPEG雙重壓縮圖像偽造區域人工智能多域結論:在本文中,我們提出了采用卷積神經網絡來檢測拼接偽造的一個步驟。我們開始探索美國有線電視新聞網的能力,對未經壓縮的單張和雙張壓縮圖像進行分類和本地化。在最新的案例中,我們的方法也能夠恢復原始壓縮質量因素。我們提出了基于空間域的CNN及其與基于頻率的CNN的組合,并將其應用于基于多域的方法。實驗結果表明,空間域可以直接使用,并且當與頻域相結合時,可以在DCT方法通常較弱(例如QF2 <QF1)的情況下導致優越的性能。一些尚未解決的問題仍有待探討。首先,CNN體系結構的選擇可能導致與在對象分類任務[11,18]中看到的非常不同的性能[11,18],其中使用更深的體系結構。其次,應該通過收集一個更大的數據集來探索需要多少數據來訓練一個好的CNN模型。我們的結果表明,空間信息可以幫助DCT方法需要至少64x64的補丁來構建有用的統計信息。第三,應該提供CNN檢測不同類型壓縮(如JPEG 2000或有損PNG)的能力。我們有希望的結果表明,該工具可以檢測以前壓縮的細微特征,并學習預測再壓縮時使用的第一個質量因子。