編者按:在日常工作、學習中,數據科學家最常遇到的問題之一就是過擬合。你是否曾有過這樣一個模型,它在訓練集上表現優秀,在測試集上卻一塌糊涂。你是否也曾有過這樣的經歷,當你參加建模競賽時,從跑分上看你的模型明明應該高居榜首,但在賽方公布的成績榜上,它卻名落孫山,遠在幾百名之后。如果你有過類似經歷,那本文就是專為寫的——它會告訴你如何避免過擬合來提高模型性能。
在這篇文章中,我們將詳細講述過擬合的概念和用幾種用于解決過擬合問題的正則化方法,并輔以Python案例講解,以進一步鞏固這些知識。注意,本文假設讀者具備一定的神經網絡、Keras實現的經驗。
目錄
1. 什么是正則化
2. 正則化和過擬合
3. 深度學習中的正則化
-
L2和L1正則化
-
Dropout
-
數據增強
-
早停法
什么是正則化
在深入探討這個話題之前,請看一下這張圖片:
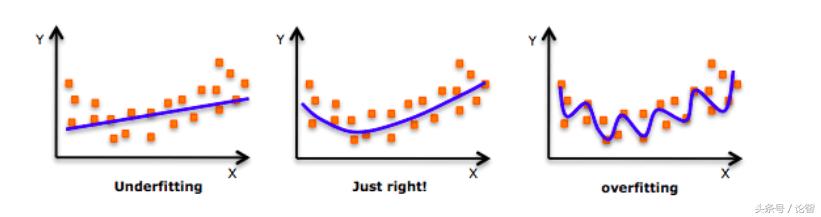
每次談及過擬合,這張圖片就會時不時地被拉出來“鞭尸”。如上圖所示,剛開始的時候,模型還不能很好地擬合所有數據點,即無法反映數據分布,這時它是欠擬合的。而隨著訓練次數增多,它慢慢找出了數據的模式,能在盡可能多地擬合數據點的同時反映數據趨勢,這時它是一個性能較好的模型。在這基礎上,如果我們繼續訓練,那模型就會進一步挖掘訓練數據中的細節和噪聲,為了擬合所有數據點“不擇手段”,這時它就過擬合了。
換句話說,從左往右看,模型的復雜度逐漸提高,在訓練集上的預測錯誤逐漸減少,但它在測試集上的錯誤率卻呈現一條下凸曲線。
來源:Slideplayer
如果你之前構建過神經網絡,想必你已經得到了這個教訓:網絡有多復雜,過擬合就有多容易。為了使模型在擬合數據的同時更具推廣性,我們可以用正則化對學習算法做一些細微修改,從而提高模型的整體性能。
正則化和過擬合
過擬合和神經網絡的設計密切相關,因此我們先來看一個過擬合的神經網絡:
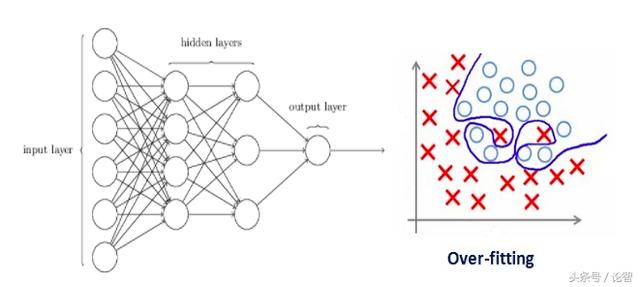
如果你之前閱讀過我們的從零學習:從Python和R理解和編碼神經網絡(完整版),或對神經網絡正則化概念有初步了解,你應該知道上圖中帶箭頭的線實際上都帶有權重,而神經元是儲存輸入輸出的地方。為了公平起見,也就是為了防止網絡在優化方向上過于放飛自我,這里我們還需要加入一個先驗——正則化懲罰項,用來懲罰神經元的加權矩陣。
如果我們設的正則化系數很大,導致一些加權矩陣的值幾乎為零——那***我們得到的是一個更簡單的線性網絡,它很可能是欠擬合的。
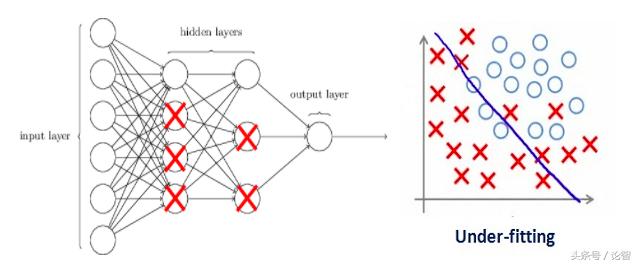
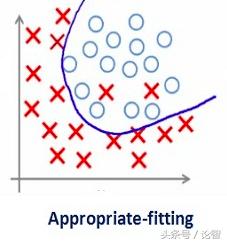
因此這個系數并不是越大越好。我們需要優化這個正則化系數的值,以便獲得一個良好擬合的模型,如下圖所示。
深度學習中的正則化
L2和L1正則化
L1和L2是最常見的正則化方法,它們的做法是在代價函數后面再加上一個正則化項。
代價函數 = 損失(如二元交叉熵) + 正則化項
由于添加了這個正則化項,各權值被減小了,換句話說,就是神經網絡的復雜度降低了,結合“網絡有多復雜,過擬合就有多容易”的思想,從理論上來說,這樣做等于直接防止過擬合(奧卡姆剃刀法則)。
當然,這個正則化項在L1和L2里是不一樣的。
對于L2,它的代價函數可表示為:
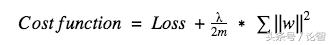
這里λ就是正則化系數,它是一個超參數,可以被優化以獲得更好的結果。對上式求導后,權重w前的系數為1−ηλ/m,因為η、λ、m都是正數,1−ηλ/m小于1,w的趨勢是減小,所以L2正則化也被稱為權重衰減。
而對于L1,它的代價函數可表示為:
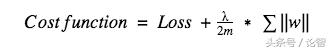
和L2不同,這里我們懲罰的是權重w的絕對值。對上式求導后,我們得到的等式里包含一項-sgn(w),這意味著當w是正數時,w減小趨向于0;當w是負數時,w增大趨向于0。所以L1的思路就是把權重往0靠,從而降低網絡復雜度。
因此當我們想要壓縮模型時,L1的效果會很好,但如果只是簡單防止過擬合,一般情況下還是會用L2。在Keras中,我們可以直接調用regularizers在任意層做正則化。
例:在全連接層使用L2正則化的代碼:
- from keras import regularizersmodel.add(Dense(64, input_dim=64, kernel_regularizer=regularizers.l2(0.01)
注:這里的0.01是正則化系數λ的值,我們可以通過網格搜索對它做進一步優化。
Dropout
Dropout稱得上是正則化方法中最有趣的一種,它的效果也很好,所以是深度學習領域常用的方法之一。為了更好地解釋它,我們先假設我們的神經網絡長這樣:
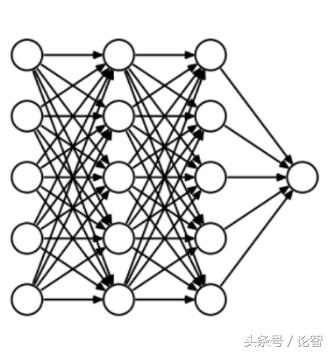
那么Dropout到底drop了什么?我們來看下面這幅圖:在每次迭代中,它會隨機選擇一些神經元,并把它們“滿門抄斬”——把神經元連同相應的輸入輸出一并“刪除”。
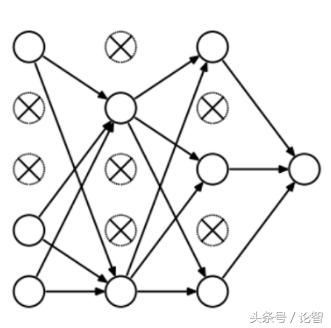
比起L1和L2對代價函數的修改,Dropout更像是訓練網絡的一種技巧。隨著訓練進行,神經網絡在每一次迭代中都會忽視一些(超參數,常規是一半)隱藏層/輸入層的神經元,這就導致不同的輸出,其中有的是正確的,有的是錯誤的。
這個做法有點類似集成學習,它能更多地捕獲更多的隨機性。集成學習分類器通常比單一分類器效果更好,同樣的,因為網絡要擬合數據分布,所以Dropout后模型大部分的輸出肯定是正確的,而噪聲數據影響只占一小部分,不會對最終結果造成太大影響。
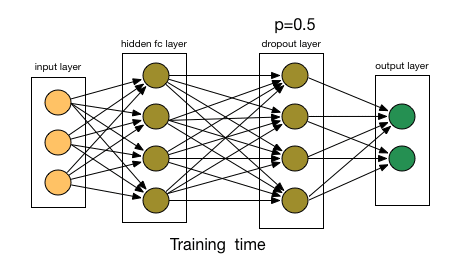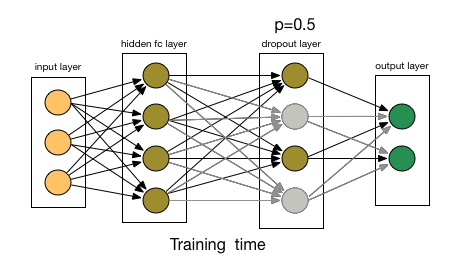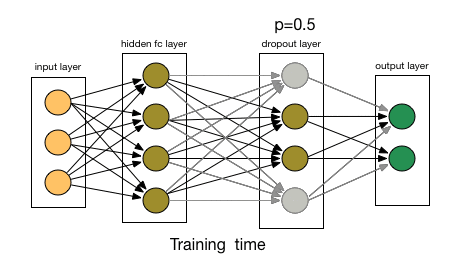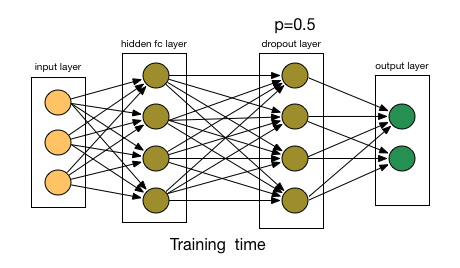
由于這些因素,當我們的神經網絡較大且隨機性更多時,我們一般用Dropout。
在Keras中,我們可以使用keras core layer實現dropout。下面是它的Python代碼:
- from keras.layers.core import Dropoutmodel = Sequential([Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu'),Dropout(0.25),Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),])
注:這里我們把0.25設為Dropout的超參數(每次“刪”1/4),我們可以通過網格搜索對它做進一步優化。
數據增強
既然過擬合是模型對數據集中噪聲和細節的過度捕捉,那么防止過擬合最簡單的方法就是增加訓練數據量。但是在機器學習任務中,增加數據量并不是那么容易實現的,因為搜集、標記數據的成本太高了。
假設我們正在處理的一些手寫數字圖像,為了擴大訓練集,我們能采取的方法有——旋轉、翻轉、縮小/放大、位移、截取、添加隨機噪聲、添加畸變等。下面是一些處理過的圖:

這些方式就是數據增強。從某種意義上來說,機器學習模型的性能是靠數據量堆出來的,因此數據增強可以為模型預測的準確率提供巨大提升。有時為了改進模型,這也是一種必用的技巧。
在Keras中,我們可以使用ImageDataGenerator執行所有這些轉換,它提供了一大堆可以用來預處理訓練數據的參數列表。以下是實現它的示例代碼:
- from keras.preprocessing.image import ImageDataGeneratordatagen = ImageDataGenerator(horizontal flip=True)datagen.fit(train)
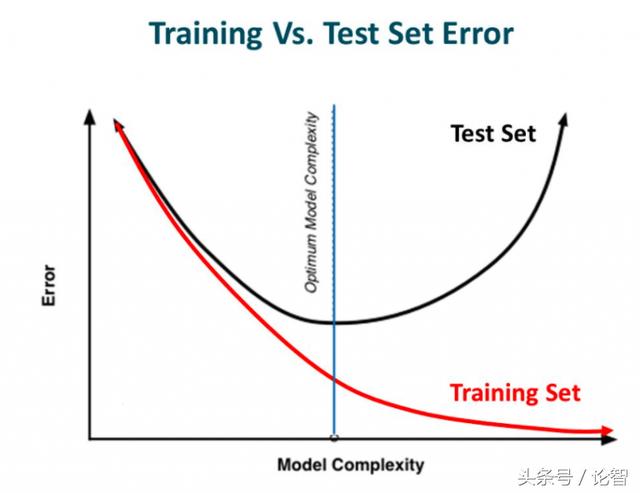
早停法
這是一種交叉驗證策略。訓練前,我們從訓練集中抽出一部分作為驗證集,隨著訓練的進行,當模型在驗證集上的性能越來越差時,我們立即手動停止訓練,這種提前停止的方法就是早停法。
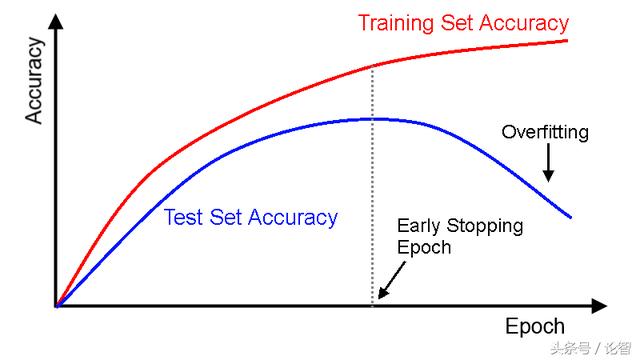
在上圖中,我們應該在虛線位置就停止訓練,因為在那之后,模型就開始過擬合了。
在Keras中,我們可以調用callbacks函數提前停止訓練,以下是它的示例代碼:
- from keras.callbacks import EarlyStoppingEarlyStopping(monitor='val_err', patience=5)
在這里,monitor指的是需要監控的epoch數量;val_err表示驗證錯誤(validation error)。
patience表示經過5個連續epoch后模型預測結果沒有進一步改善。結合上圖進行理解,就是在虛線后,模型每訓練一個epoch就會有更高的驗證錯誤(更低的驗證準確率),因此連續訓練5個epoch后,它會提前停止訓練。