機器學習:基于密度的異常值檢測算法
異常值檢測(也稱為異常檢測)是機器學習中查找具有與期望非常不同的行為的數據對象的過程。這些對象稱為離群值或異常。
最有趣的對象是那些與普通對象明顯不同的對象。離群值不是由與其他數據相同的機制生成的。
異常檢測在許多應用中很重要,例如:
- 財務數據欺詐
- 通信網絡中的入侵
- 假新聞和錯誤信息
- 醫療分析
- 行業損壞檢測
- 安全和監視
- 等等
離群值檢測和聚類分析是兩個高度相關的任務。聚類在機器學習數據集中查找多數模式并相應地組織數據,而離群值檢測嘗試捕獲那些與多數模式大不相同的異常情況。
在本文中,我將介紹異常值檢測的基本方法,并重點介紹一類Proximity-based算法方法。我還將提供LOF算法的代碼實現。
異常值和噪聲數據
首先在機器學習中,您需要將離群值與噪聲數據區分開來。
應用離群檢測時應去除噪音。它可能會扭曲正常對象并模糊正常對象和離群值之間的區別。它可能有助于隱藏離群值并降低離群值檢測的有效性。例如,如果用戶考慮購買他過去經常購買的更昂貴的午餐,則應將此行為視為“噪音交易”,如“random errors”或“variance”。
異常值的類型
通常,異常值可以分為三類,即全局異常值,上下文(或條件)異常值和集體異常值。
- 全局異常值 - 對象顯著偏離數機器學習據集的其余部分
- 上下文異常值 - 對象根據選定的上下文顯著偏離。例如,28⁰C是莫斯科冬季的異常值,但在另一個背景下不是異常值,28⁰C不是莫斯科夏季的異常值。
- 集合異常值 - 即使單個數據對象可能不是異常值,數據對象的子集也會顯著偏離整個機器學習數據集。例如,短期內小方的同一股票的大量交易可以被視為市場操縱的證據。
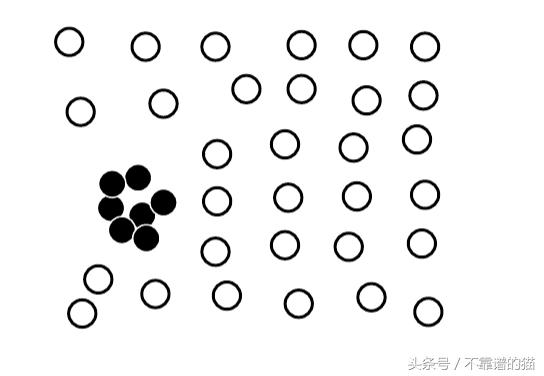
集合異常值
通常,數據集可以包含不同類型的異常值,并且同時可以屬于不止一種類型的異常值。
異常值檢測方法
文獻中涵蓋了許多異常值檢測方法,并在實踐中使用。首先,異常值檢測方法根據用于分析的數據樣本是否與領域專家提供的標簽一起給出,該標簽可用于構建異常值檢測模型。其次,可以根據關于正常對象與異常值的假設將方法分成組。
如果可以獲得正常和/或異常對象的專家標記示例,則可以使用它們來構建異常值檢測模型。使用的方法可以分為監督方法,半監督方法和無監督方法。
監督方法
我們將離群值檢測建模為分類問題。由領域專家檢查的樣本用于訓練和測試。
挑戰:
- 類不平衡。也就是說,異常值的數量通常遠小于普通對象的數量。可以使用處理不平衡類的方法,例如過采樣。
- 捕獲盡可能多的異常值,即,召回比準確性更重要(即,不將正常對象誤標記為異常值)
無監督的方法
在某些應用程序方案中,標記為“正常”或“異常”的對象不可用。因此,必須使用無監督學習方法。無監督異常值檢測方法做出了一個隱含的假設:正常對象在某種程度上是“聚類的”。換句話說,無監督異常值檢測方法期望正常對象比異常值更頻繁地遵循模式。
挑戰:
- 普通對象可能不共享任何強模式,但是集合異常值可能在小區域中具有高相似性
- 如果正常活動是多樣的并且不屬于高質量聚類,則無監督方法可能具有高誤報率并且可能使許多實際異常值不受影響。
最新的無監督方法開發了智能想法,直接解決異常值而無需明確檢測聚類。
半監督方法
在許多應用中,雖然獲得一些標記的示例是可行的,但是這種標記的示例的數量通常很小。如果有一些標記的普通對象可用:
- 使用帶標簽的示例和鄰近的未標記對象來訓練普通對象的模型
- 那些不適合普通對象模型的對象被檢測為異常值
- 如果只有一些標記的異常值可用,則少量標記的異常值可能無法很好地覆蓋可能的異常值。
統計方法
統計方法(也稱為基于模型的方法)假設正常數據遵循一些統計模型(隨機模型)。我們的想法是學習適合給定數據集的生成模型,然后將模型的低概率區域中的對象識別為異常值。
參數方法
參數方法假設通過參數θ的參數分布生成正常數據對象。參數分布f(x, θ )的概率密度函數給出了通過分布生成對象x的概率。該值越小,x越可能是異常值。
正常對象出現在隨機模型的高概率區域中,而低概率區域中的對象是異常值。
統計方法的有效性在很大程度上取決于分配的假設。
例如,考慮具有正態分布的單變量數據。我們將使用最大似然法檢測異常值。
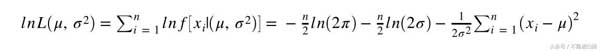
估計參數μ和σ的最大似然法
取μ和σ²的導數并求解所得的一階條件系統導致以下最大似然估計
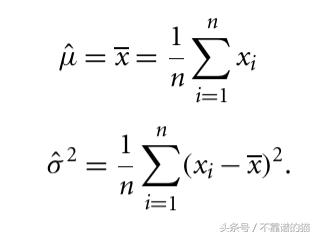
μ和σ²的最大似然估計
看下Python示例:
- import numpy as np
- avg_temp = np.array([24.0, 28.9, 28.9, 29.0, 29.1, 29.1, 29.2, 29.2, 29.3, 29.4]) mean = avg_temp.mean()
- std = avg_temp.std()
- sigma = std^2
- print (mean, std, sigma) //28.61 1.54431214461 2.3849
最偏離的值是24⁰,遠離平均值4.61。我們知道μ+/-3σ區域在正態分布假設下包含97%的數據。因為4.61 / 1.54> 3我們認為24⁰是異常值。
我們還可以使用另一種統計方法,稱為Gribbs測試并計算z得分。
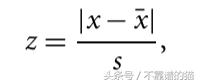
s - 標準偏差
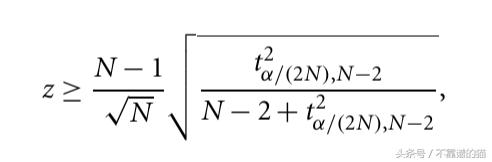
但是我們很少使用只有一個屬性的數據。涉及兩個或多個屬性的數據稱為多變量。這些方法的核心思想是將多變量數據轉換為單變量異常值檢測問題。
流行的方法之一是 ² -statistics。
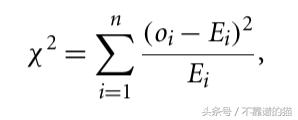
Oi - 第i維度中O的值。Ei - 所有對象中第i維的平均值,n維度。
如果χ²-大,則對象是異常值。
參數模型的主要缺點是在許多情況下,數據分布可能是未知的。
例如,如果我們有兩個大的集合,那么關于正態分布的假設就不會很好。

相反,我們假設正常數據對象由多個正態分布Θ(μ1,σ1)和Θ(μ2,σ2)生成,并且對于數據集中的每個對象o,我們計算由分布的混合生成的概率。
Pr(o |Θ1,Θ2)=fΘ1(o)+fΘ2(o)
其中fΘ1(o) - Θ1和Θ2的概率密度函數。要學習參數μ和σ,我們可以使用EM算法。
非參數方法
在用于離群值檢測的非參數方法中,從輸入數據中學習“正常數據”模型,而不是先驗地假設。非參數方法通常對數據做出較少的假設,因此可適用于更多場景。作為一個例子,我們可以使用直方圖。
在最簡單的方法中,如果對象在一個直方圖箱中失敗,則認為是正常的。缺點 - 很難選擇垃圾箱尺寸。
Proximity-based算法
給定特征空間中的一組對象,可以使用距離度量來量化對象之間的相似性。直覺上,遠離其他對象的對象可被視為異常值。Proximity-based方法假設異常值對象與其最近鄰居的接近度明顯偏離對象與數據集中的大多數其他對象的接近度。
Proximity-based算法可以分為基于距離(如果對象是沒有足夠的點,則對象是異常值)和基于密度的方法(如果對象的密度相對遠低于其鄰居,則對象是異常值)
基于密度
基于距離的離群值檢測方法參考對象的鄰域,該對象由給定半徑定義。如果對象的鄰域沒有足夠的其他點,則該對象被視為異常值。
閾值的距離,可以定義為對象的合理鄰域。對于每個對象,我們可以找到對象的合理neighbours數量。
令r(r> 0)為距離閾值,π (0 <π<1)為分數閾值。對象o是DB(r, π )
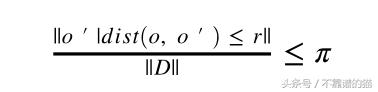
DIST -距離測量
需要O(n²)時間。
挖掘基于距離的異常值的算法:
- 基于索引的算法
- 嵌套循環算法
- 基于單元的算法
基于密度的方法
基于密度的離群點檢測方法研究對象的密度及其相鄰對象的密度。在這里,如果一個對象的密度相對于其相鄰對象的密度要低得多,那么這個對象就是一個離群值。
許多真實世界的數據集展示了一個更復雜的結構,其中對象可能被視為與其局部neighbours相關的離群值,而不是與全局數據分布相關的離群值。

考慮上面的例子,基于距離的方法能夠檢測到o3,但是對于o1和o2,它并不那么明顯。
基于密度的想法是我們需要將對象周圍的密度與其局部neighbours周圍的密度進行比較。基于密度的離群值檢測方法的基本假設是,非離群對象周圍的密度類似于其neighbours周圍的密度,而離群對象周圍的密度與其鄰近對象周圍的密度明顯不同。
dist_k(o)——對象o與k近鄰之間的距離。o的k-distance鄰域包含所有到o的距離不大于o的k-th距離dist_k(o)
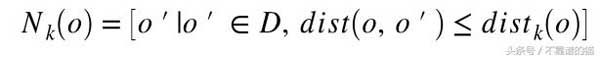
我們可以用Nk(o)到o的平均距離作為o的局部密度的度量,如果o有非常接近的鄰域o',使得dist(o,o')非常小,那么距離度量的統計波動可能會非常高。為了克服這個問題,我們可以通過添加平滑效果切換到以下可達距離測量。
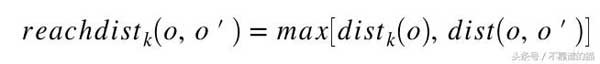
k是用戶指定的參數,用于控制平滑效果。基本上,k指定要檢查的最小鄰域以確定對象的局部密度。可達距離是不對稱的。
對象o的局部可達性密度是
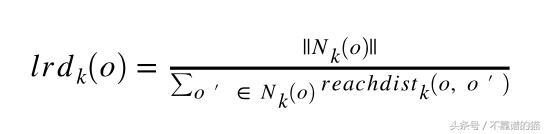
我們計算對象的局部可達性密度,并將其與其相鄰的可比性密度進行比較,以量化對象被視為異常值的程度。
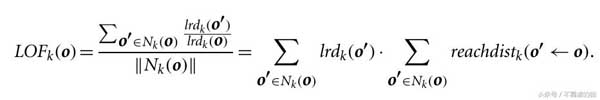
局部異常因子是o的局部可達性密度與o的 k近鄰的比率的平均值。o的局部可達性密度越低,k的最近鄰點的局部可達性密度越高,LOF值越高。這恰好捕獲了局部密度相對較低的局部密度相對較低的局部異常值。它的k近鄰。
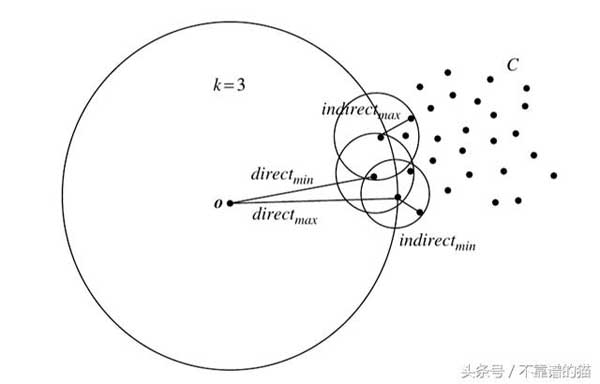
LOF算法
基于data.csv中的點擊流事件頻率模式,我們將應用LOF算法來計算每個點的LOF,并具有以下初始設置:
- k = 2并使用曼哈頓距離。
- k = 3并使用歐幾里德距離。
結果,我們將找到5個異常值及其LOF_k(o)
可以從github 存儲庫下載數據(https://github.com/zkid18/Machine-Learning-Algorithms)
Python實現如下:
- import pandas as pd
- import seaborn as sns
- from scipy.spatial.distance import pdist, squareform
- data_input = pd.read_csv('../../data/clikstream_data.csv')
- #Reachdist function
- def reachdist(distance_df, observation, index):
- return distance_df[observation][index]
- #LOF algorithm implementation from scratch
- def LOF_algorithm(data_input, distance_metric = "cityblock", p = 5):
- distances = pdist(data_input.values, metric=distance_metric)
- dist_matrix = squareform(distances)
- distance_df = pd.DataFrame(dist_matrix)
- k = 2 if distance_metric == "cityblock" else 3
- observations = distance_df.columns
- lrd_dict = {}
- n_dist_index = {}
- reach_array_dict = {}
- for observation in observations:
- dist = distance_df[observation].nsmallest(k+1).iloc[k]
- indexes = distance_df[distance_df[observation] <= dist].drop(observation).index
- n_dist_index[observation] = indexes
- reach_dist_array = []
- for index in indexes:
- #make a function reachdist(observation, index)
- dist_between_observation_and_index = reachdist(distance_df, observation, index)
- dist_index = distance_df[index].nsmallest(k+1).iloc[k]
- reach_dist = max(dist_index, dist_between_observation_and_index)
- reach_dist_array.append(reach_dist)
- lrd_observation = len(indexes)/sum(reach_dist_array)
- reach_array_dict[observation] = reach_dist_array
- lrd_dict[observation] = lrd_observation
- #Calculate LOF
- LOF_dict = {}
- for observation in observations:
- lrd_array = []
- for index in n_dist_index[observation]:
- lrd_array.append(lrd_dict[index])
- LOF = sum(lrd_array)*sum(reach_array_dict[observation])/np.square(len(n_dist_index[observation]))
- LOF_dict[observation] = LOF
- return sorted(LOF_dict.items(), key=lambda x: x[1], reverse=True)[:p]
- LOF_algorithm(data_input, p = 5)
- # [(19, 11.07),
- # (525, 8.8672286617492091),
- # (66, 5.0267857142857144),
- # (638, 4.3347272196829723),
- # (177, 3.6292633292633294)]
- LOF_algorithm(data_input, p = 5, distance_metric = 'euclidean')
- # [(638, 3.0800716645705695),
- # (525, 3.0103162562616288),
- # (19, 2.8402916620868903),
- # (66, 2.8014102661691211),
- # (65, 2.6456528412196416)]