詳解知乎反作弊垃圾文本識別的深度學習實踐
原創背景
截止今年 8 月,知乎注冊用戶量已突破 2 億。對于垃圾信息的治理,我們面臨著更大的挑戰和考驗。過去我們通過不斷升級「悟空」的策略引擎,通過在行為、環境、資源、文本等多維度組合應用,已經取得了非常不錯的效果。近期我們嘗試引入深度學習識別垃圾文本,「悟空」對 Spam 的治理能力又邁上了一個新的臺階。
問題分析
我們對當前站內垃圾文本進行了梳理,發現目前主要包括四種形式:
- 導流內容:這類內容大概能占到社區中垃圾文本的 70%-80%,比較典型的包括培訓機構,美容,保險,代購相關的。導流內容會涉及到 QQ,手機號,微信,URL甚至座機,在一些特殊時間節點還會出現各類的專項垃圾文本,比如說世界杯,雙十一,雙十二,都是黑產大賺一筆的好時機。
- 品牌內容:這類內容會具有比較典型的 SEO 特色,一般內容中不會有明顯的導流標識,作弊形式以一問一答的方式出現,比如提問什么牌子怎么樣?哪里的培訓學校怎么樣?然后在對應的回答里面進行推薦。
- 詐騙內容:這類內容一般以冒充名人,機構的方式出現,比如單車退款類,在內容中提供虛假的客服電話進行詐騙。
- 騷擾內容:比如一些誘導類,調查類的批量內容,非常嚴重影響知友體驗。

這些垃圾文本的核心獲益點一方面是面向站內的傳播,另一方面,面向搜索引擎,達到 SEO 的目的。
算法介紹
從算法角度可以把這個問題看做一個文本分類問題,把站內的內容分為垃圾文本和正常文本兩個類別。常用文本分類算法有很多,我們不打算詳細介紹每一個分類算法,只是分享我們在處理實際問題中遇到的一些問題和權衡。
我們遇到的第一個問題是使用CNN 還是 RNN。一般來說,CNN 是分層架構,RNN 是連續結構。CNN 適合由一些關鍵詞來決定的任務;RNN適合順序建模任務 ,例如語言建模任務,要求在了解上下文的基礎上靈活建模。這一結論非常明顯,但是目前的 NLP 文獻中并沒有支持性的文章。
另外一般來說,CNN 訓練速度和預測速度都快于RNN。考慮到上述站內垃圾文本的主要形式,導流和品牌內容中都會出現關鍵詞,同時對于垃圾文本檢測的速度要求比較高,我們最終使用 CNN。一個典型的 CNN 文本分類模型如下圖所示。

接下來,我們遇到的一個問題是,使用字還是詞語作為輸入。詞語具有比字更高的抽象等級,更豐富的含義。但是導流內容中的 QQ、手機號、微信、URL、座機等,通常不會出現在已有詞庫中,品牌詞也具有類似的特點,一般是未登錄詞。而且,導流內容通常會出現變體詞,使用詞語作為輸入,不能很好地捕捉類似特征。所以,我們最終使用的是字作為輸入。
在決定使用字作為輸入之后,需要考慮使用在知乎站內語料上預訓練的字向量初始化模型的Embedding層,還是直接在分類模型中隨機生成初始字向量。這里考慮的是垃圾文本的數據分布和知乎站內文本的數據分布具有比較大的區別,垃圾文本相對于站內正常文本是一個比較特定的領域。因此我們使用隨機初始化字向量。
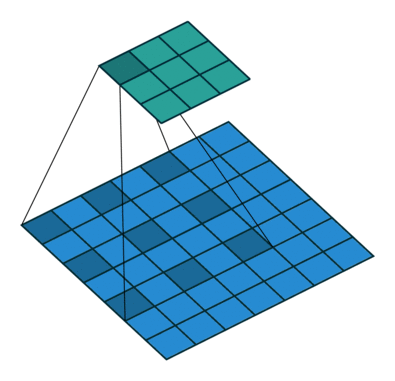
在決定使用字向量之后,我們觀察到“有意者加我咨詢:2839825539”、“找北京·合·合·天·下”等關鍵信息,按字來計算通常都很長。因此,CNN需要更大的感受域來提取相關文本特征,如果簡單增加卷積核大小,會增加參數數量。我們考慮使用空洞卷積(Dilated Convolution),來增加卷積的感受域,同時不增加網絡參數數量。一個典型的空洞卷積如下圖所示。
另外我們觀察到需要識別的垃圾文本并不都是短文本,還有一部分是長文本。由于文本長度的關系,如果簡單將卷積層的輸出取平均,輸出到全連接層,那么文本能決定是否是垃圾文本的關鍵特征很可能被其他特征所淹沒,導致模型精度難以提升。因此,我們加入了一個 Attention 層,通過它給予關鍵特征更大的權重。Attention 計算方法如下圖所示。

通過上述分析,我們最終采用的模型結構如下圖所示。
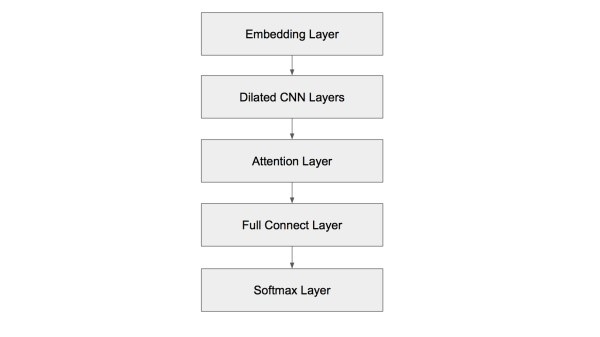
垃圾文本分類算法結構
模型效果
目前,垃圾文本模型會對知乎站內的所有內容進行評分,輸出 0-1 之間的分數,系統會對高分內容進行處理。
模型分數在知乎部分業務線上的表現:
|
文本分數 |
>=0.9準確率 |
>=0.8準確率 |
>=0.7準確率 |
|
回答 |
100.0% |
99.8% |
95.6% |
|
提問 |
100.0% |
99.1% |
97.7% |
|
評論 |
100.0% |
99.6% |
98.0% |
當前情況下,模型結合其他反作弊維度,可實現對垃圾評分 0.5 分以上的內容進行刪除,同時準確率達到 97% 以上。上線以來,每天刪除垃圾內容數千條。

模型實時處理
另外值得一提的是端午期間,知乎站內涌現了一波違法違規的 spam,垃圾文本模型覆蓋了 98% 以上內容,使得這波攻擊大概持續了 1000 條左右就停了。

端午 spam 攻擊
后續計劃
垃圾文本識別是一個長期攻防的過程,站內垃圾文本會隨著時間不斷演變,現有模型的效果也會隨之變化。為了應對站內垃圾文本的挑戰,我們將一直收集 badcase,進一步優化模型的效果。
最后
由于本人的水平有限,如有錯誤和疏漏,歡迎各位同學指正。
作者:孫俊,知乎內容質量團隊的算法工程師。主要負責導流信息識別,垃圾文本識別和文本情感分析模型的開發和維護。