UNIT劃重點—快速掌握對話系統技術原理
人工智能時代的交互特色用一個詞來概括就是“對話”,用人類最自然的交互方式,或者是語音或者是文字,給機器發送指令,與機器進行交互。當然,人機對話系統早在傳統計算機時代就已經出現了,只是在人工智能時代,特別是由于各種機器學習技術尤其是深度學習技術的出現,使我們的系統實用性取得了質的飛躍。
對話系統種類繁多,劃分方式多種多樣。可根據用途分為任務型、問答型、閑聊型對話系統;也可根據場景分為封閉域、開放域對話系統;還可根據使用方法分為檢索式、生成式對話系統。UINT平臺能夠幫助大家方便地構建任務型多輪對話系統。我們重點看任務型多輪對話系統。
任務型人機對話系統
在對話過程中,機器人需執行的操作分為口語理解、對話管理、執行命令、語言生成四個過程。如下圖所示對話系統的基本操作流程:

首先,對話系統需理解用戶的自然語言請求,根據用戶給出的查詢輸入先后經過口語理解、對話管理,然后決定進行語言生成還是指令執行,***給出系統答復。其中,核心模塊為口語理解和對話管理。
口語理解
口語理解的功能為理解用戶請求所包含的語義信息,用于信息查詢或指令執行。其任務難點為自然語言的歧義性,表達方法的多樣性及敘述風格的口語化。那么該如何攻破口語理解的任務難點呢?
UNIT平臺提供兩種經典模式解決:基于語義解析的口語理解模式,基于語義匹配的口語理解模式。
基于語義解析的口語理解模式,是將用戶請求解析為所包含語義信息的結構化表達。其中,最典型的結構化表達是意圖(描述用戶的核心訴求)+ 詞槽(描述意圖的關鍵信息)的模式。常用方法有基于知識規則的方法,基于機器學習的方法,以及基于融合策略的方法。
基于語義匹配的口語理解模式,不需要解析出具體的語義格式化信息,而是需要尋找與其具有***語義匹配程度的問答對。
對話管理
對話管理的功能為基于對話狀態實施對話策略,從而實現多輪對話邏輯。其任務難點為狀態計算的不確定性及不確定環境下的策略選擇。相應的,對話管理存在兩大核心任務:對話狀態跟蹤、對話策略選擇。如下圖為對話管理在整個對話流程中的位置,及狀態位置和對話管理之間相互配合的關系。

對話狀態跟蹤,即根據對話歷史計算當前對話狀態,管理并更新對話歷史。其常用方法為:基于人工規則的方法,基于機器學習的方法。通過建立映射,輸入會話歷史,然后輸出當前對話狀態。
對話策略選擇,即根據當前對話狀態,選擇接下來最恰當的操作。其常用方法為:基于人工規則的方法,基于機器學習的方法,以及基于強化學習的方法。同樣是通過建模映射的過程,輸入當前對話狀態,輸出系統回復和指令執行。
對話系統如何搭建
簡單介紹一下系統搭建的流程,以及每個流程當中開發者需要做什么,以及UINT平臺為大家提供了什么。搭建流程如下:
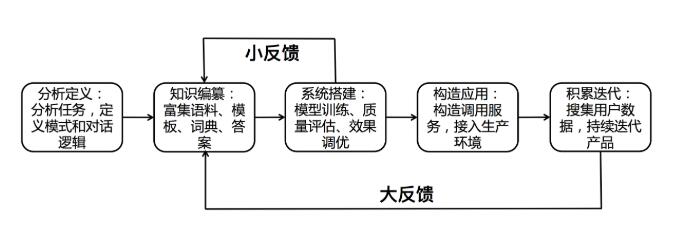
1)首先定義對話系統。就是說這個對話系統包含哪些意圖,這個意圖的關鍵信息是什么。
2)富集數據資源。就是收集、標注、擴充數據資源,包括需要哪些詞典,標注哪些規則,需要寫多少模板,需要標注多少樣本。
3)配置對話邏輯。這個過程可以很方便的用UINT進行搭建,只要把這個對話系統按照UINT提供的方式配置到UINT平臺中,把富集的數據資源輸入到UINT中,點幾個按鈕就可以進行系統的搭建訓練了。
4)訓練模型,效果優化。可以在UNIT平臺進行對話效果的調優。之后可以不斷的重復一個小的循環過程。上線之后,大量的用戶進來使用對話機器人,貢獻了更多數據的樣本,拿到這些樣本之后,根據這些樣本所產生的錯誤等等情況進行分析,再一次富集我們的資源對系統進行改進,使得效果不斷變好。
在這個搭建的過程中,UNIT平臺提供了很多能力,為開發者降低了開發成本。
- 預置技能:分析用戶需求,定義對話系統階段,UNIT平臺直接推出多個場景的預置技能,也有富含資源的技能,開發者可以一鍵獲取,不需再進行富集數據和模型訓練的工作。
- 系統詞槽:UNIT平臺預置的詞槽,包括人名、地名、時間、地點等22個大類的詞槽詞典值,開發者可以直接勾選復用,不需富集人名表、地名表和時間等等這些信息。
- 模板配置:UNIT提供了一套科學的對話理解模板的編撰機制,通過這種對話模板,可以快速實現對話的泛化效果。
- 推薦樣本:UNIT平臺提供了大量的推薦樣本,減少開發者樣本富集的工作,根據開發者提供的樣本,能夠推薦出一些相似的、可以復用的樣本出來。
- 日志分析:UINT提供了數據回流的機制,數據存儲的機制,數據服務加工的機制等,以及日志分析工具,幫助開發者優化對話效果。
系統評估
評估方法分為兩大類:
1. 對單個系統的精度給出量化的指標數據,用于單個系統的精度評估
由于口語理解精度直接影響對話管理運行,進而影響對話系統效果,因此可以通過評估口語理解來評估對話系統。其中有三個指標:準確率(Precision),召回率(Recall),F 值(F-measure)
準確率 = 預測結果中正確的數量 / 預測結果中總的數量
召回率 = 預測結果中正確的數量 / 測試集中應該被識別的數量
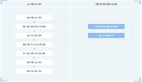
2. 對兩個系統的精度對比給出量化的指標數據,用于系統迭代時給出精度對比。
針對系統迭代需求,比較基線系統 X 和對比系統 Y 的優勢。其中兩個系統的定量對比涉及的指標:
- Diff 面:同一條 query 解析結果不一致的情況在抽樣集合中的占比
- G(變好):針對同一條 query,Y 的結果比 X 好
- S(相同):針對同一條 query,Y 的結果與 X 差不多
- B(變差):針對同一條 query,Y 的結果比 X 差
如果 Y 要替換 X,至少 G>B;同時如果 Diff 面過大,則還需要考慮用戶體驗的波動。