私藏UNIT學習筆記—輕松入門對話系統搭建
搭建對話系統是一個相對專業而復雜的過程,通常分三個主要的階段。首先是需求分析,然后是使用平臺搭建技能,***是持續優化。
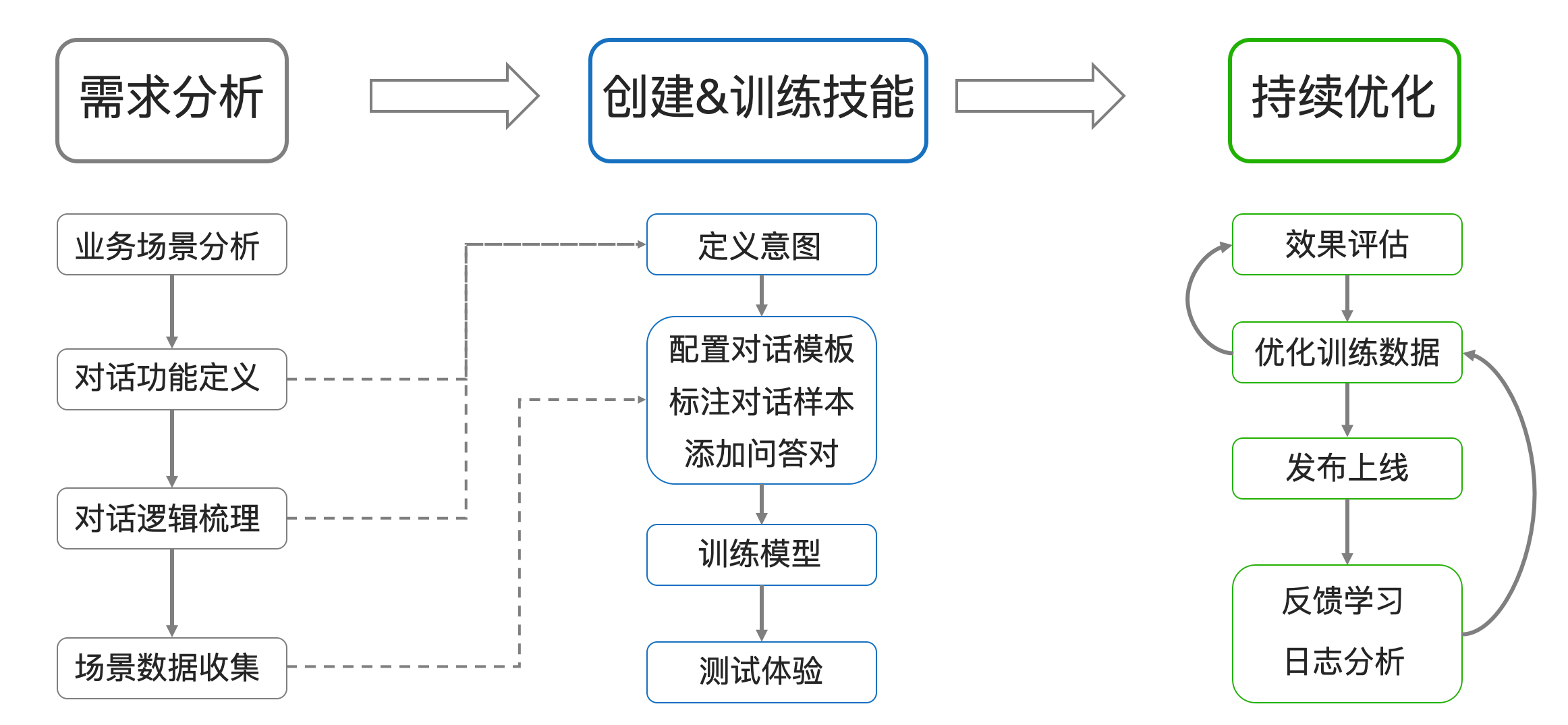
需求分析
***階段需求分析,這個階段應該有產品經理或需求分析師這樣的角色參與。
- 首先要分析業務場景;
- 然后進行對話機器人的功能定義;
- 接著要梳理業務場景里的對話邏輯;
- ***要收集場景里的對話數據。
下面以訂火車票的場景來講解整個流程要做哪些工作。
業務場景分析:確定邊界,明確目標
首先進行業務場景的分析,確定一個場景下機器人應該做什么,不應該做什么。
火車票場景中,應該做訂票、退票、改簽、查詢以及一些火車票相關的規章制度等常見問題解答。而毫無目標的閑聊是不應該做的。
功能定義:確定優先級及關鍵信息要素
在確定邊界和目標后,就可以對火車票對話機器人的功能進行定義了。
在功能定義的階段,要先確定各功能的優先級,并確定每個功能對應的實體要素。顯而易見的,火車票這個場景,訂票、退票、改簽、查詢都是***優的功能。
完成功能的定義后,接下來還需要對業務場景下的對話邏輯進行梳理,包括正常的對話邏輯和異常的對話邏輯。另外,關于問答型對話,其實都是用戶對一些規則、規則制度的提問,這些問題都是標準、固定答案的。這類型的對話邏輯梳理其實就是要對問題進行分類,或者叫知識分類。
場景數據收集:在真實場景下用戶會怎么問?
完成對話的邏輯梳理后,還要進行需求分析***一個環節的工作,即數據收集。
針對任務型的對話,要收集真實場景下用戶買票的各種問法,越多越好。而對問答型的對話,要根據前面的知識分類去收集每個分類下的問題與答案,即問答對。
在這個階段收集的數據將在后面技能搭建的第二個階段使用。
搭建技能
注冊百度賬號,打開(http://unit.baidu.com),進入 UNIT:
1. 新建 技能
在 UNIT 平臺搭建對話技能的***步是創建技能。
2. 定義自定義技能:新建對話 / 問答意圖
創建完后就進入技能定義的階段,技能又分自定義技能和預置技能

每個技能都是由多個相關的意圖組成,這個階段的新建意圖就對應需求分析階段的功能定義。比如訂票功能就可以轉化為訂票意圖 BOOK_TICKET,訂票的關鍵信息可以定義為實現訂票意圖的詞槽,這里簡單一些,僅定義出發時間、出發站點、到達站點、車次四個詞槽;分別命名為user_time、user_from、user_to、trainnumber。
具體操作步驟如下:
2.1 新建對話意圖
點擊【火車票】技能,進入技能模塊,在自定義技能中【新建對話意圖】:

2.2 添加詞槽
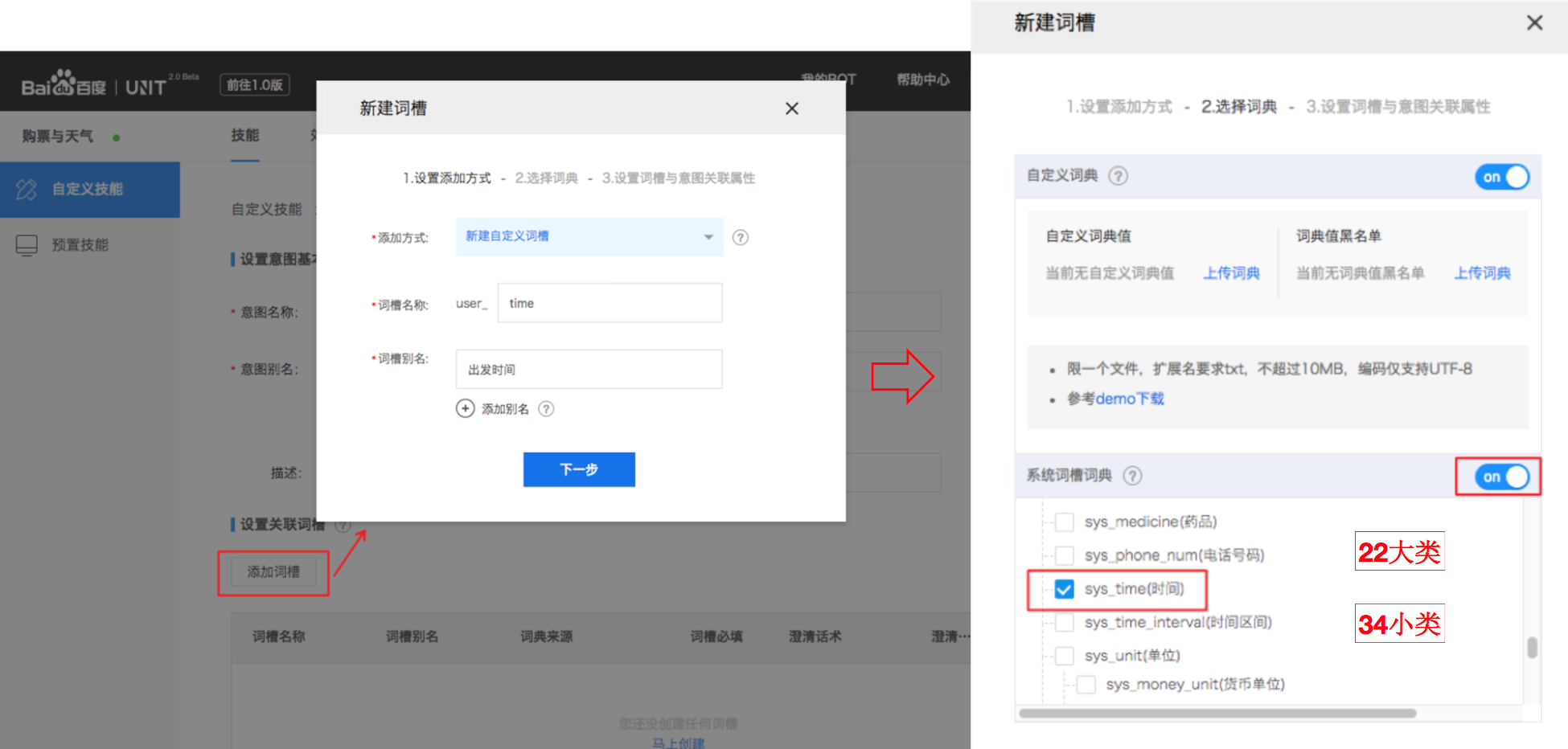
***步是選擇【添加方式】,選 「新建自定義詞槽」,并設置詞槽名(user_time)和詞槽別名 (出發時間),
第二步先打開【系統詞槽詞典】的開關,然后選擇系統詞典 sys_time(時間)
- UNIT 平臺中詞槽的識別依賴詞槽對應的詞典。支持自定義詞典,也可以選擇系統預置詞典,建議在能選擇系統詞典的情況下盡量選擇使用系統詞典,當系統詞典里沒有你需要的類型時可以添加自定義詞典。
第三步設置詞槽與意圖關聯屬性,這里火車票的出發時間是訂票里必須的關鍵信息,所以選擇必填。澄清話術就是當用戶表達訂票需求的語句里缺少出發時間時 對話技能主動讓用戶澄清的話術。還可以設置讓用戶澄清多少輪后放棄要求澄清,默認是 3 次。
添加完所有詞槽后如下圖:

在詞槽列表中可以調整詞槽澄清的順序。
2.3 設置答復

技能回應就是當技能識別出用戶的意圖和所有必填詞槽值時給用戶的反饋。
有三種回應方式:【答復】、【引導至對話意圖】、【引導值問答意圖】
2.4 新建問答意圖
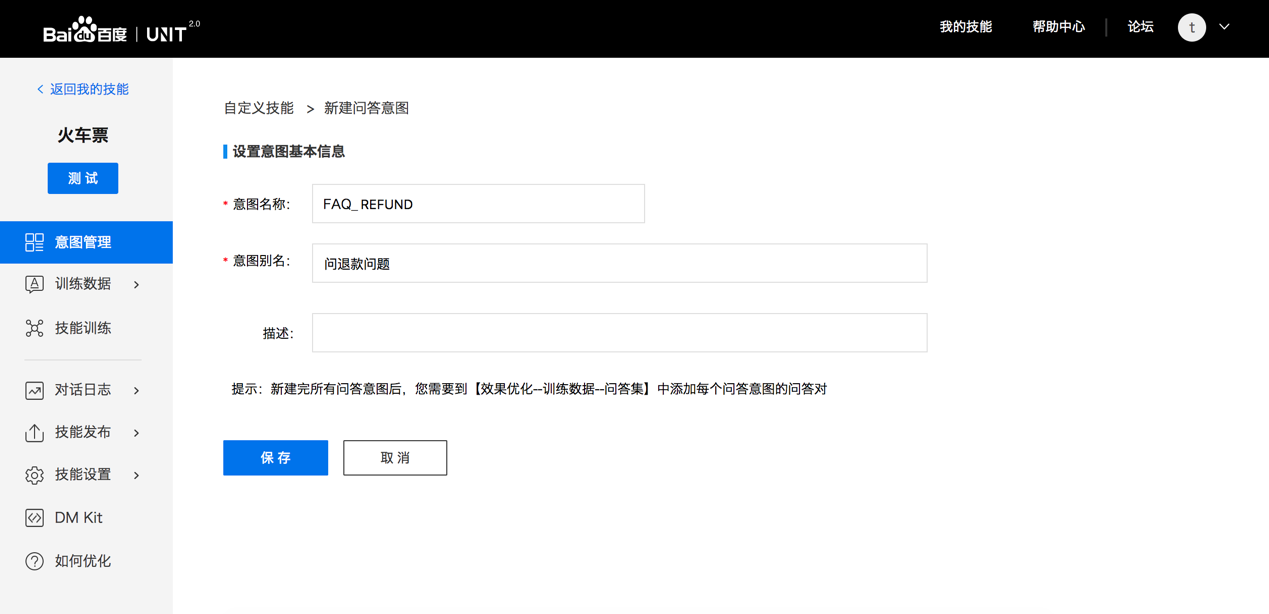
3. 添加訓練數據
完成技能定義后,進入第二個環節,給技能添加訓練數據,讓模型能理解用戶query的意圖。
3.1 配置對話模板
首先是配置對話模板,對話模板是對用戶需求表達的一種規則抽象,可以通過對模板片段的必填選填,前后順序,閾值大小的配置,使其快速具備一定的泛化能力。

當我們有多個對話模板時,它們之間是有優先級的,在列表的位置越靠前,優先級越高,可以選中一條對話模板,然后執行上移、下移的操作來調整優先級。
3.2 標注對話樣本
這部分要把需求分析***一個階段收集到的對話數據添加到 UNIT 平臺,然后給他們逐條標注意圖、詞槽。經過深度學習的策略訓練后,讓對話模型獲得更好的對話理解能力,而且數據越豐富,模型的泛化效果越好。

然后在對話樣本集中新建 『買火車票』樣本集,將數據添加進去:
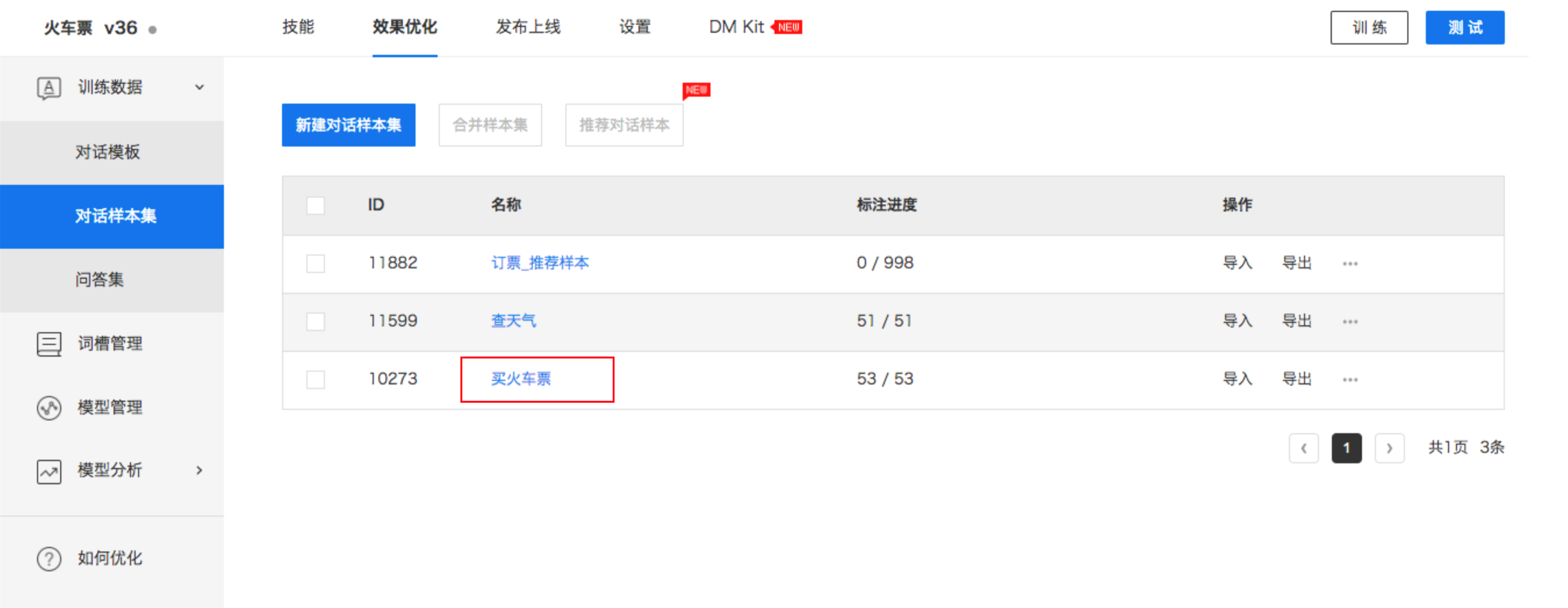
機器學習會隨著數據的不斷豐富,擁有越來越強的泛化能力,而當你很難收集到大量的對話樣本時怎么辦?UNIT 平臺提供了推薦對話樣本的工具,只需要你收集 50 條真實場景的對話樣本后就可以用它作為種子樣本來推薦類似的樣本,種子樣本質量越高,推薦的樣本質量越好。
3.3 添加問答對
在需求分析階段就收集整理的問答對數據在問答集中導入即可

并不是每個場景都必須添加上面的三種訓練數據才可以進行對話,這要根據您自己場景中的對話類型和數據收集情況來定。
- 假如你的場景是任務型的又缺少對話樣本,這時你就可以先去配置對話模板,快速達到一定效果后再從日志中篩選更多的對話樣本;
- 假如你一開始就有對話樣本,這時你可以對話模板、對話樣本一起上,這樣可以快速達到一個更好的效果;
- 而如果你還有問答行的對話時,只要添加問答對就可以了,這個最簡單。
3.4 訓練模型
訓練技能有兩種方式,一種是指訓練上面配置的對話模板,另外一種是訓練對話樣本同時訓練對話模板。

系統默認必須訓練對話模板,不論你有沒有標注對話模板。選擇快速生效策略,訓練模型并生效到沙盒,會需要 15~30 秒的時間。
也可以選擇對話樣本集,并使用深度訓練策略,則對應后端的訓練將采用深度學習的策略進行模型訓練,這時訓練的速度會與標注的對話樣本量成正比。這里建議選擇系統自帶的「閑聊負例樣本」,這樣可以降低技能的誤召回情況,就是告訴技能哪些 query 是閑聊而不是買票。
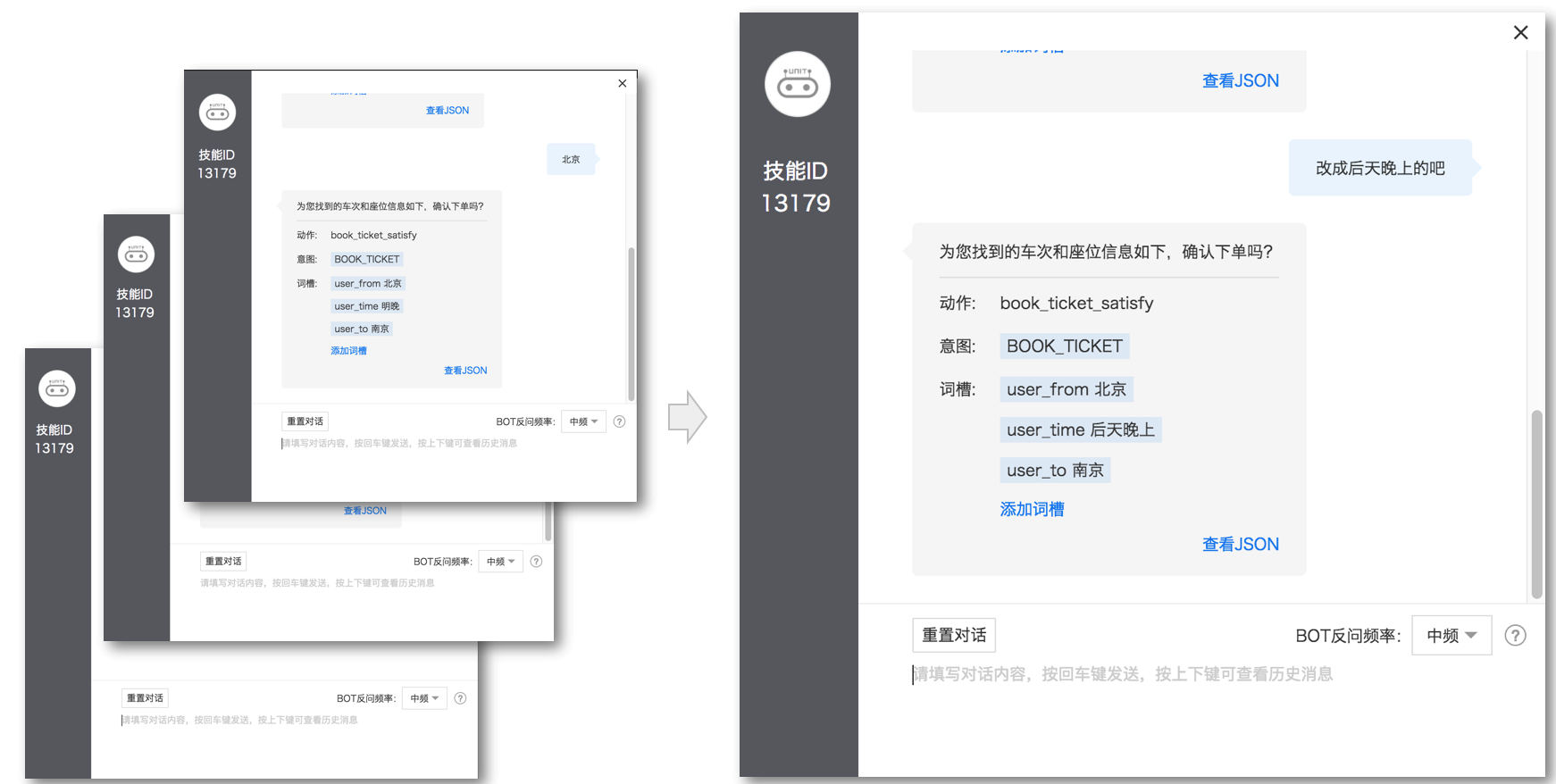
4. 測試體驗
完成模型的訓練后,就可以在測試窗口跟技能聊一聊,看看最終的效果了:
UNIT 使用技巧與持續優化
準確理解領域問題
- 任務型場景,該場景特點是有任務目標,需要把請求參數化,并且在多輪對話之間,參數還可以繼承。
- 問答型場景,該場景特點是有任務目標,不需要把請求參數化
- 聊天型場景,該場景特點是沒有任務目標
高效建設領域資源
高效建設詞槽
首先看內置詞槽與自定義詞典、規則的關系
- 自定義詞典、規則的優先級高于系統內置,但是系統詞槽如果包含了自定義詞,會按系統詞槽識別。
- 自定義此點之間優先級相等,如果一個詞屬于多個詞典,會相應的識別出多個詞槽候選。因此,不必擔心自定義詞典之間的沖突與歧義,一切都有模板兜底。
- 規則的形式是正則表達式,要注意控制通配的范圍,善用捕捉功能加以限制。不加約束的通配,是 badcase 的重要來源。
那么該如何定義詞槽以及如何高效地擴充系統內沒有包含的詞槽呢?
擴展法:針對每個詞槽 / 特征詞至少產出 3-5 個實例,可進行基于資源的擴展(樹形結構、結構化信息、開放分類),基于相關度的擴展(上下文相似度、Word embedding),基于語料的擴展(Set expansion 算法)。
挖掘法:可在垂直網站爬取詞槽,或者在離線知識庫 Dump。
當然,也可采取挖掘 + 擴展的方法,先挖掘出詞槽,隨后再進行擴展。另外,質檢工作很重要,當挖掘的量很大時,可以選擇使用眾包。
自然語言理解配置對話模板配置技巧
- 關鍵詞可以抽象上下文的表達方式
- 基于模板的意圖推到,有隊詞槽進行消歧的能力
- 善用模板片段,增強模板泛化能力
- 模板的定義順序決定了意圖的解析順序
對話樣本配置技巧
- 關于數據量:100 可訓;1000 可用
- 所有已標注樣本都會進入 K-V 字典,K-V 字典保證樣本一定會按標注的方式解析,當詞槽識別出現不穩定時,注意看看樣本
定期評估與優化
定期評估指定期隨機業務日志,人工評估效果,其重點關注情況為以下幾點:
- 意圖解析失敗 / 錯誤、詞槽缺失
- 可能的原因:出現了之前沒見過的說法,出現了當前不覆蓋的詞槽
- 應對方案:新增模板,標注樣本,擴展詞槽
- 詞槽解析錯誤、歸一化錯誤
- 可能的原因:系統詞槽 badcase,用戶詞槽出現了歧義,用戶詞典覆蓋了系統詞槽
- 應對方案:向 UNIT 吐槽,調整詞典 / 模板,少量 case 可以直接通過標注樣本強制解決
- 存在新需求不能滿足
- 應對方案:分析是否需要支持——是:新增技能;否:引導用戶的功能預期。