













手把手教你用 Python 實現查找算法
本文介紹以下查找算法:
線性查找(Linear Search)
二分查找(Binary Search)
插值查找(Interpolation Search)
我們詳細了解一下它們各自的情況。
一. 線性查找
查找數據的最簡單策略就是線性查找,它簡單地遍歷每個元素以尋找目標,訪問每個數據點從而查找匹配項,找到匹配項后,返回結果,算法退出循環,否則,算法將繼續查找,直到到達數據末尾。線性查找的明顯缺點是,由于固有的窮舉搜索,它非常慢。它的優點是無須像其他算法那樣,需要數據排好序。
我們看一下線性查找的代碼:
- def LinearSearch(list, item):
- index = 0
- found = False
- # Match the value with each data element
- while index < len(list) and found is False:
- if list[index] == item:
- found = True
- else:
- index = index + 1
- return found
現在,看一下代碼的輸出(見圖3-15)。
- list = [12, 33, 11, 99, 22, 55, 90]
- print(LinearSearch(list, 12))
- print(LinearSearch(list, 91))
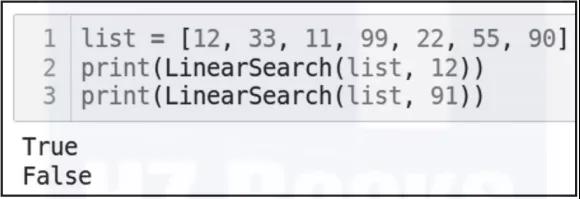
▲圖 3-15
需要注意的是,如果能成功找到數據,運行LinearSearch函數會返回True。
- 線性查找的性能:如上所述,線性查找是一種執行窮舉搜索的簡單算法,其最壞時間復雜度是O(N)。
二. 二分查找
二分查找算法的前提條件是數據有序。算法反復地將當前列表分成兩部分,跟蹤最低和最高的兩個索引,直到找到它要找的值為止:
- def BinarySearch(list, item):
- first = 0
- last = len(list)-1
- found = False
- while first<=last and not found:
- midpoint = (first + last)//2
- if list[midpoint] == item:
- found = True
- else:
- if item < list[midpoint]:
- last = midpoint-1
- else:
- first = midpoint+1
- return found
輸出結果如圖3-16所示。
- list = [12, 33, 11, 99, 22, 55, 90]
- sorted_list = BubbleSort(list)
- print(BinarySearch(list, 12))
- print(BinarySearch(list, 91))

▲圖 3-16
請注意,如果在輸入列表中找到了值,調用BinarySearch函數將返回True。
- 二分查找的性能:二分查找之所以如此命名,是因為在每次迭代中,算法都會將數據分成兩部分。如果數據有N項,則它最多需要O(log N)步來完成迭代,這意味著算法的運行時間為O(log N)。
三. 插值查找
二分查找的基本邏輯是關注數據的中間部分。插值查找更加復雜,它使用目標值來估計元素在有序數組中的大概位置。
讓我們試著用一個例子來理解它:假設我們想在一本英文詞典中搜索一個單詞,比如單詞river,我們將利用這些信息進行插值,并開始查找以字母r開頭的單詞,而不是翻到字典的中間開始查找。一個更通用的插值查找程序如下所示:
- def IntPolsearch(list,x ):
- idx0 = 0
- idxn = (len(list) - 1)
- found = False
- while idx0 <= idxn and x >= list[idx0] and x <= list[idxn]:
- # Find the mid point
- mid = idx0 +int(((float(idxn - idx0)/( list[idxn] - list[idx0])) * ( x - list[idx0])))
- # Compare the value at mid point with search value
- if list[mid] == x:
- found = True
- return found
- if list[mid] < x:
- idx0 = mid + 1
- return found
輸出結果如圖3-17所示。
- list = [12, 33, 11, 99, 22, 55, 90]
- sorted_list = BubbleSort(list)
- print(IntPolsearch(list, 12))
- print(IntPolsearch(list,91))
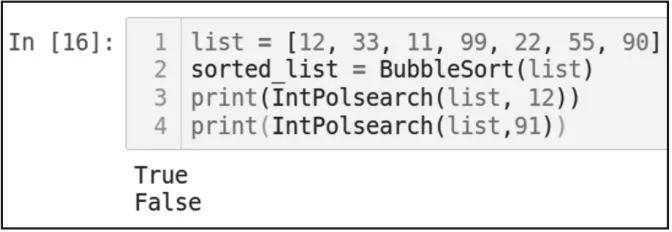
▲圖 3-17
請注意,在使用IntPolsearch函數之前,首先需要使用排序算法對數組進行排序。
- 插值查找的性能:如果數據分布不均勻,則插值查找算法的性能會很差,該算法的最壞時間復雜度是O(N)。如果數據分布得相當均勻,則最佳時間復雜度是O(log(log N))。
關于作者:伊姆蘭·艾哈邁德(Imran Ahmad) 是一名經過認證的谷歌講師,多年來一直在谷歌和學習樹(Learning Tree)任教,主要教授Python、機器學習、算法、大數據和深度學習。他在攻讀博士學位期間基于線性規劃方法提出了名為ATSRA的新算法,用于云計算環境中資源的優化分配。近4年來,他一直在加拿大聯邦政府的高級分析實驗室參與一個備受關注的機器學習項目。
本文摘編自《程序員必會的40種算法》,經出版方授權發布。













