Lambda架構已死,基于IOTA模型的“秒算平臺”架構實踐
原創【51CTO.com原創稿件】經過多年的發展,從大數據1.0的BI/Datawarehouse時代,到大數據2.0的Web/App過渡期間,再進入到IOT的大數據3.0時代,隨之而來的是數據架構的變化。
2018 年 5 月 18-19 日,由 51CTO 主辦的全球軟件與運維技術峰會在北京召開。在“大數據處理技術”分會場,來自易觀智庫的CTO郭煒先生為我們帶來了《Lambda架構已死,新一代的去ELT化IOTA架構》的主題演講。
他就Lambda與Kappa架構的發展及優缺點展開,分享IOTA大數據架構的思路及優缺點,以及易觀在IOTA架構領域的實踐經驗。
IOTA架構的背景

首先介紹我們遇到過的各種數據問題和提出IOTA架構的背景。
我們的數據來源于手機的SDK。上圖是易觀當前的數據規模。如今月活數已經達到了5.5個億,其中包含有大概20多億個用戶畫像(Profile),并且已“打上了”各種維度的標簽。
那么面對這么多維度的數據量,以及層出不窮的新數據,我們該如何支持好各種數據的運作呢?

我們先來看看IOTA架構的提出背景。上圖右側是易觀在前兩年構建的大數據架構,底層是SDK采集各類數據的過程。
由于每天都會有幾百億條的數據量,因此我們在SDK上采取的是“云+端”的控制策略,以避免底層SDK淪為導流層。
目前我們使用的接收帶寬已達到6個GB。當有并發數據傳到我們的接收端時,可能會出現幾個GB以上的流量爆增,因此我們要避免這種類似DDoS情況的出現。
在底層上面,我們基于Kafka自行定制了各種內部使用的隊列與分發。與此同時,我們實現了多方的HDFS查詢,并基于此構建了批量查詢的Hive。
對于前端的各種產品,我們用Greenplum實現了Ad—hoc查詢。同時,我們用Presto來滿足內部分析師的各種查詢需求。
圖中的右側部分是內部的一些數據治理服務,包括對源數據的管理、數據口徑與質量的檢測、以及左側綠色的各種調度服務。
上述便是我們在前兩年構建的內部大數據結構。當然,我們也遇到了如下各種問題:
- 如今IoT的時代已經來臨,各種智能硬件設備接踵而至,包括智能手環,醫用糖尿病篩查設備、智能WiFi、BCON和智能攝像頭等。隨著數據越來越復雜,簡單的移動客戶端已經無法滿足我們采集和分析數據的需求了。
- 隨著IoT設備的面市和產生的巨大數據量級,其采集頻次遠大于人工點擊,這給整個架構帶來了更大的挑戰。
- 數據格式不統一,例如一種云攝像頭的數據格式,就不一定與其他廠商的IoT攝像頭相同。
- 數據格式多變,會導致業務查詢的頻繁變更。我們易觀的70多名分析師,他們所要求的數據類型,每天都不盡相同。
- 數據需要能夠被實時地查詢到。
我們以轉化查詢為例:某公司要在雙十一大促的活動中,查詢一下自己前一個小時廣告投放的效果、以及價格波動對于用戶***購買的影響。這些都屬于Ad-hoc式查詢。
Lambda架構
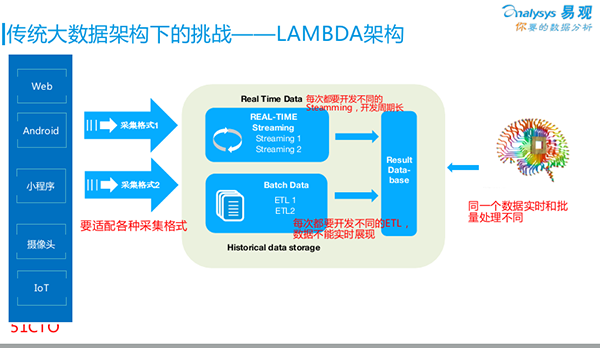
我們回頭來看Lambda架構。如今80%~90%的企業都在使用Lambda架構進行自己的大數據分析,包括我們自己也是從Lambda架構過渡而來。
如圖所示,所有的數據采集都是從最左側進入架構的。根據不同的SDK,各種數據源所采集到的數據格式會有所不同。它們在此匯聚到我們云端的大數據平臺。
我們通過兩條線來保證數據的實時性和有效性:
- 通過傳統的ETL,我們將數據做成批量任務—Batch Data,每晚運行一次,次日早上我們去查看相關的數據結果。
- 為了保證實時地采集,例如:需要根據銷售量來做出智能推薦的決策,或是查看當日的PV/UV,那么我們就去“跑”一些Data Streaming(數據流)。
上述兩條線的結果,最終都被放入一個Result Database(結果數據庫,如某個MySQL)中,以方便我們的前端應用,通過該數據庫,來查詢后端的數據。
但是,該架構存在著如下問題:
1. 業務方會發現,次日看到的數據比昨晚看到的要少。原因在于:數據在被放入Result Database時,走了兩條線的計算方式:一條線是ETL按照某個口徑“跑”過來,得到更為準確的批量處理結果;另一條線是通過Streaming“跑”過來,依靠Hadoop Hive或其他算法得出的實時性結果。當然它犧牲了部分的準確性。可見,這兩個來自批量的和實時的數據結果是對不上的,因此大家覺得很困惑。
2. 針對每一次實時分析的需求,都需要用Data Streaming重新開發一次。無論您是用Storm、Spark Streaming還是Flink,只要你想查看某個結果,就必須開發一次流式計算。也就是說,我們要按需做各種各樣的ETL開發,這顯然效率不高。
3. 我們做數據清洗的目的就是為了得到更好的數據格式,然后放到大數據平臺之上。但是由于平臺需要通過處理,來適配不同的采集格式,因此,我們無法迅速地呈現不同領域的實時數據。
KAPPA架構

后來LinkedIn提出了一個新的架構:KAPPA。它的理念是:鑒于大家認為批量數據和實時數據對不上是個問題,它直接去掉了批量數據;而直接通過隊列,放入實時數據之中。
例如:將所有的數據直接放到原來的Kafka中,然后通過Kafka的Streaming,去直接面向***的查詢結果。
當然,該架構也存在著一些問題:
1. 不能及時查詢和訓練。例如:我們的分析師想通過一條SQL語句,來查詢前五秒的狀態數據。這對于KAPPA架構是很難去實現的。
2. 面對各種需求,它同樣也逃不過每次需要重新做一次Data Streaming。也就是說,它無法實現Ad—hoc查詢,我們必需針對某個需求事先準備好,才能進行數據分析。
3. 新數據源的結構問題。例如:要新增一臺智能硬件設備,我們就要重新開發一遍它對應的適配格式、負責采集的SDK、以及SDK的接收端等,即整體都要重復開發一遍。
因此,雖然KAPPA架構比Lambda好的方面是不必實時地把ETL數據做兩遍,但是它仍然存在著結構上的問題。
IOTA架構

至此,我們提出了IOTA架構。在取名上,它是基于希臘字母的順序,即:從IOTA、到KAPPA、再到Lambda的。
我們首先來看看IOTA架構的基本思路。鑒于大家既需要支持實時數據、又要支持Ad—hoc查詢,還要支持各種數據的適配,因此該架構必然會有一些“約束”。
***個約束:我們應事先確定好通用的數據模型(Common Data Model)。例如:我們在做用戶行為分析時,可以通過一種“主-謂-賓”的模型去描述:“誰對什么做了什么”。而剩下的其他修飾詞,則完全可以被作為其他的列和參數。
在此模型基礎上,所有的數據其實并非在中央被處理,而是在最開始的SDK端被操作。在此我們可以引入邊緣計算的概念,即:不是在云端加工數據,而是把所有數據分散到從數據產生到***存儲整個過程之中。
另外,由于一般公司的業務并不會天天發生變化,因此我們可以抽象出一套完整的業務模型,進而實現在邊緣端做數據統一,而不是在云端進行。

如上圖中所提到的Common Data Model的示例。我們可以用“主-謂-賓”模型,即“X用戶 – 事件1 – A頁面(2018/4/11 20:00)”來進行抽象。
當然,我們也可以根據業務的不同需求,使用“產品-事件”、或“地點-時間”模型。

第二個約束:對于同樣的硬件設備而言,我們完全可以將“X用戶的MAC 地址-出現- A樓層(2018/4/11 18:00)”模型,與前面提到的“主-謂-賓”模型統一成一種。
也就是說,無論是App小程序、Web頁面、攝像頭、還是IoT智能WiFi,只要數據模型是統一的,你就能夠在數據產生端,統一整體的數據格式。
第三個約束:由于云端的數據只負責存儲和查詢,而不再負責做加工。
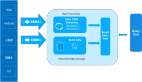
因此在IOTA架構中,有著如下主要的組成部分:
- Real Time Data Cache,對于海量的實時數據,我們會存儲到云端,但是在將它們直接導入數據庫的時候則會產生延遲,因此我們需要選用Hbase或Kudu之類的組件,來實現簡單的列式存儲。
- Historical Data,針對的是大量歷史數據的底層存儲,我們可以在云端用到HDFS。而之所以不將實時數據直接接入HDFS,是為了避免產生大量的碎片文件,而影響到最終的查詢效率。
- Dumper,該程序實現并銜接了從Real Time Data Cache到數據的存儲。我們可以按照既定的規則(每五分鐘、或到達一百萬條數據時),將Real Time Data Cache“落”到HDFS文件中。同時,我們也可以添加相關的索引,為后面的Query Engine做好準備。
- Query Engine,它可以用到的計算引擎包括:Spark、Presto、Impala等。通過Query Engine,我們既可以查詢存儲在HDFS的底層數據,又可以查詢幾分鐘前的實時數據。另外,通過兩者的合并,分析師還能夠實現智能分析。
因此,基本的流程是:底層的SDK先將數據的格式予以統一,接著先存放在Cache里,然后再放入Historical Data中。
而在查詢時,我們可以暴露一個SQL接口(如:Presto或SparkSQL),以供分析師們直接查看到幾秒之前的各種數據狀態。
例如:我們可以通過Query Engine查詢到:用戶是如何從登錄頁面最終點擊到了購買頁面,他們所經歷的智能路徑和觸發過的事件等。這些一連串的前后相關的數據都能夠被實時地顯示出來,甚至包括一些Ad-hoc的查詢。
總結
我們再回顧一下上面提到的重要方面:
- 通用數據模型非常重要,它貫穿整個業務的始終,從SDK的產生直至***的存儲,以及按需查詢。當然,如果模型本身上無法固定,我們則可以用Protobuf在SDK中先行定義一個模型。在做好了協議架構的基礎上,如果后期需求固定下來了,我們只要保持從底層到上層的模型統一,那么修改起來就十分方便,甚至都不會涉及到云端存儲的改動。
- 數據緩沖區,主要用來減少索引的延遲和歷史數據的碎片等問題。
- 歷史數據沉浸區,主要是為了Ad-hoc查詢,其包括建立好各種相關的索引,以實現秒級的結果返回。
- SDK,過去我們只是讓SDK進行簡單地埋點和采集,而如今,我們在SDK上增加了一些簡單的計算,讓數據在產生端就完成了轉化。
- 如果產生端(如攝像頭)的性能不夠,我們可以為它添加一臺專門用作轉化的EdgeAIServer服務器,從而實現上述提到的“主-謂-賓”模型的格式輸出。當然,對于App和H5頁面來說,由于沒有計算的工作量,因此只要求埋點格式即可。

根據上述對于IOTA模型的介紹,我們對原來的大數據系統做了相應的調整。
具體情況如下:
- 我們的數據查詢已不再需要ETL,而是通過Query Engine實現了數據的各種留存、轉化、營銷和分析等操作。
- 針對查詢服務,我們基于Presto進行了二次開發,并構建出了“秒算平臺”。
- 對應上面提到過的“主-謂-賓”模型,我們相應地制定了兩個主要的數據存儲結構:“用戶/事件”,即:“誰在哪發生了什么”。
- 為了保證緩存中的數據能夠被順利地“灌”入Historical Data所對應的存儲區域,我們配置了DumpMR服務模塊。
- 針對“灌入”的數據會被分成很多個文件,如:每十分鐘產生一個文件的情況,我們配置了MergerMR服務模塊,它能夠將這些碎片化的多個文件合并成為一個大的存儲塊。另外,我們還為這些數據重新添加了索引,以方便實時地進行計算。
- 在“秒算平臺”上,我們運用Hbase來對實時數據進行緩存,并用HDFS來對歷史數據進行存儲。
- 由于我們將Presto作為查詢服務引擎,為了能讓它能夠連接HDFS和Hbase,我們自行研發了一些Connector。通過我們的二次開發,它能夠支持諸如MySQL、Redis和MongoDB等各種第三方數據庫的查詢。
- 我們對從用戶處收集來的大數據,根據上面提到的“用戶/事件”和“主-謂-賓”模型,直接放到SDK里,進行相關的計算。
眾所周知,任何一種軟件只有經歷了開放源代碼,才能夠不斷地促進自己的完善與發展。雖然我們的系統目前尚屬內部版本,但是我們計劃在今年底,將上述提到的基于IOTA架構模型的“秒算平臺”開源出來,以供大家使用。
有了這樣的平臺,大家可以基于其存儲引擎來快速地進行二次開發,而不必自己去寫HDFS、Connector、DumpMR、MergerMR、以及一大堆Profile相關的代碼。我們會把這些“坑”事先幫大家“填好”,大家直接用它去做用戶級別的數據分析便可。

目前,就易觀大數據混合云的數據規模和性能而言,已經能夠根據我們分析師的各種Ad-hoc數據查詢需求,實現了秒級的結果返回。同時,我們內部的秒算服務引擎,也能夠支持并提供帶有各種分析結果的分析報告。
郭煒,現任易觀CTO,負責易觀整體技術架構及分析產品線。北大計算系本科與研究生,在Teradata,IBM,中金負責大數據方向架構師或研發總監,后任萬達電商數據部總經理,聯想研究院大數據總監。在電商、移動互聯網、商業地產、百貨、移動通信、零售、院線等多個業務領域大數據方面具有搭建團隊、系統以及分領域的分析與算法經驗。
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】