李鬼見李逵,用Python“死磕”翟天臨的博士論文
都說今年的瓜特別多(葫蘆娃的那種),但是過年期間最甜的我想非翟天臨的“知網是什么?”莫屬了吧。
近期,翟天臨因“論文抄襲、學術造假”被推上風口浪尖,甚至連自己參演并準備播出的六部電視劇,也被央視要求全部刪減,至此人設徹底崩塌,輿論嘩然。

我平常不怎么關注娛樂圈,所以剛開始并沒有把這件事放在心上,直到網上爆出翟的論文大篇幅抄襲陳坤論文的消息,我才對這位娛樂圈博士的文章起了興趣。

目前北京電影學院已經撤銷翟天臨博士學位,取消陳浥博士研究生導師資格。
接下來就讓我們以一個 Coder 的角度來硬核分析下翟的論文吧。
實驗環境
工欲善其事,必先利其器,在開始分析之前,我先說明此次分析所處的實驗環境,以免出現異常:
- MacOS 10.14.3
- Python 3.6.8(Anaconda)
- Visual Studio Code
- 使用的包有:
- pkuseg(分詞)
- matplotlib(繪圖)
- wordcloud(詞云)
- numpy(數學計算)
- Sklearn(機器學習)
數據獲取
說實話,起初我以為就算翟不知“知網”為何物,“知網”也該收錄翟的文章吧,可我在知網搜了好久也沒能找到翟的論文,好在我在今日頭條上找到了他的文章,保存在 data/zhai.txt 中。

說到這,還真要感謝翟天臨啊,都是因為他,大家才變得這么有學術精神,開始研究起本科碩士博士論文了。
數據清理
上一節我們已經將他的論文保存到一個 txt 中了,所以我們需要先將文章加載到內存中:
- # 數據獲取(從文件中讀取)
- def readFile(file_path):
- content = []
- with open(file_path, encoding="utf-8") as f:
- content = f.read()
- return content
我統計了下,除去開頭的標題和末尾的致謝,總共 25005 個字。接下來我們來進行數據清理,在這里我用了 pkuseg 對內容進行分詞處理,同時去掉停用詞后輸出分詞的結果。
所謂停用詞就是在語境中沒有具體含義的文字,例如這個、那個,你我他,的得地,以及標點符合等等。
因為沒人在搜索的時候去用這些沒意義的停用詞搜索,為了使得分詞效果更好,我就要把這些停用詞過濾掉。
- # 數據清理(分詞和去掉停用詞)
- def cleanWord(content):
- # 分詞
- seg = pkuseg.pkuseg()
- text = seg.cut(content)
- # 讀取停用詞
- stopwords = []
- with open("stopwords/哈工大停用詞表.txt", encoding="utf-8") as f:
- stopwords = f.read()
- new_text = []
- # 去掉停用詞
- for w in text:
- if w not in stopwords:
- new_text.append(w)
- return new_text
執行結果如下:

這里我提兩點,為什么分詞工具用的是 pkuseg 而不是 jieba?pkuseg 是北大推出的一個分詞工具。官方地址是:
- https://github.com/lancopku/pkuseg-python
它的 README 中說它是目前中文分詞工具中效果***的。
為什么用哈工大的停用詞表?停用詞表的下載地址在:
- https://github.com/YueYongDev/stopwords
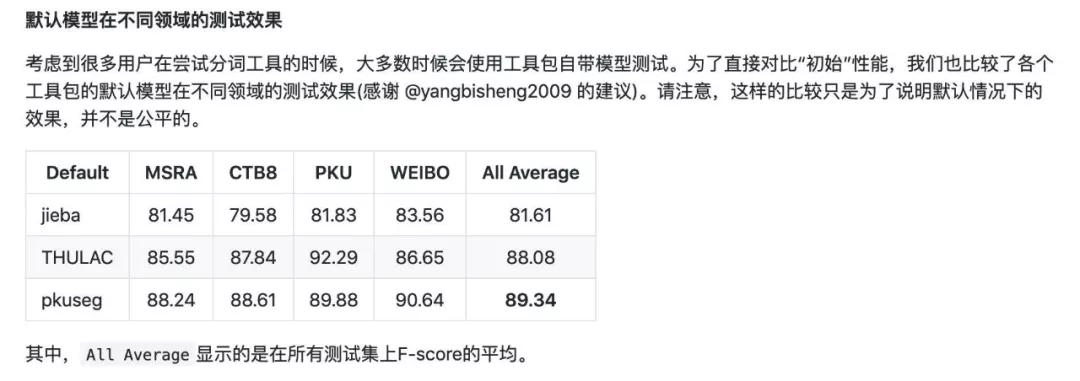
以下是幾個常用停用詞表的對比:
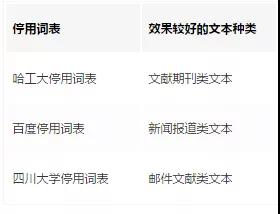
參考文獻:官琴, 鄧三鴻, 王昊. 中文文本聚類常用停用詞表對比研究[J]. 數據分析與知識發現, 2006, 1(3).
停用詞表對比研究:
- https://github.com/YueYongDev/stopwords
數據統計
說是數據統計,其實也沒什么好統計的,這里簡單化一下,就是統計下各個詞出現的頻率,然后輸出詞頻***的 15 個詞:
- # 數據整理(統計詞頻)
- def statisticalData(text):
- # 統計每個詞的詞頻
- counter = Counter(text)
- # 輸出詞頻***的15個單詞
- pprint.pprint(counter.most_common(15))
打印的結果如下:

真的是個***的“好演員”啊,能將角色帶入生活,即使肚中無貨卻仍用自己的表演能力為自己設立一個“學霸”人設,人物形象如此飽滿,興許這就是創作的藝術吧!
文章中說的最多的就是生活、角色、人物、性格這些詞,這些正是一個好演員的精神所在,如果我們將這些詞做成詞云的話,可能效果會更好。
生成詞云
詞云生成這個部分我采用的是 wordcloud 庫,使用起來非常簡單,網上教程也有很多。
這里需要提一點的就是:為了防止中文亂碼情況的發生,需要配置 font_path 這個參數。
中文字體可以選用系統的,也可以網上找,這里我推薦一個免費的中文字體下載的網址:
- http://www.lvdoutang.com/zh/0/0/1/1.html
下面是生成詞云的代碼:
- # 數據可視化(生成詞云)
- def drawWordCloud(text, file_name):
- wl_space_split = " ".join(text)
- # 設置詞云背景圖
- b_mask = plt.imread('assets/img/bg.jpg')
- # 設置詞云字體(若不設置則無法顯示中文)
- font_path = 'assets/font/FZZhuoYTJ.ttf'
- # 進行詞云的基本設置(背景色,字體路徑,背景圖片,詞間距)
- wc = WordCloud(background_color="white",font_path=font_path, mask=b_mask, margin=5)
- # 生成詞云
- wc.generate(wl_space_split)
- # 顯示詞云
- plt.imshow(wc)
- plt.axis("off")
- plt.show()
- # 將詞云圖保存到本地
- path = os.getcwd()+'/output/'
- wc.to_file(path+file_name)

真假李逵(文章對比)
分析完了“李鬼”,我們有必要請出他的真身“李逵”兄弟了,同樣還是和之前一樣的套路,先找到數據,然后分詞統計詞頻,這里就不重復操作了,直接放出詞云圖。

看到這圖是不是覺得和翟的詞云圖異常相似,那么,這“真假李逵”之間到底有多像呢?接下來我們來計算下兩篇文章的相似度吧。
TF-IDF
文章相似度的比較有很多種方法,使用的模型也有很多類別,包括 TF-IDF、LDA、LSI 等,這里方便起見,就只使用 TF-IDF 來進行比較了。
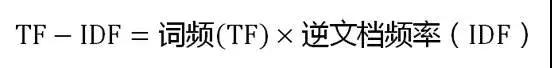
TF-IDF 實際上就是在詞頻 TF 的基礎上再加入 IDF 的信息,IDF 稱為逆文檔頻率。
不了解的可以看下阮一峰老師的講解,里面對 TFIDF 的講解也是十分透徹的。
- https://www.ruanyifeng.com/blog/2013/03/tf-idf.html
Sklearn
Scikit-Learn 也簡稱 Sklearn,是機器學習領域當中最知名的 Python 模塊之一,官方地址為:
- https://github.com/scikit-learn/scikit-learn
其包含了很多種機器學習的方式,下面我們借助于 Sklearn 中的模塊 TfidfVectorizer 來計算兩篇文章之間的相似度。
代碼如下:
- # 計算文本相似度
- def calculateSimilarity(s1, s2):
- def add_space(s):
- return ' '.join(cleanWord(s))
- # 將字中間加入空格
- s1, s2 = add_space(s1), add_space(s2)
- # 轉化為TF矩陣
- cv = TfidfVectorizer(tokenizer=lambda s: s.split())
- corpus = [s1, s2]
- vectors = cv.fit_transform(corpus).toarray()
- # 計算TF系數
- return np.dot(vectors[0], vectors[1]) / (norm(vectors[0]) * norm(vectors[1]))
除了 Sklearn,我們還可以使用 gensim 調用一些模型進行計算,考慮到文章篇幅,就由讀者自己去搜集資料實現吧。
我們將翟的論文和陳的論文分別傳入該函數后,輸出結果為:
- 兩篇文章的相似度為:
- 0.7074857881770839
其實這個結果我還是挺意外的,只知道這“李鬼”長得像,卻沒想到相似度竟然高達 70.7%。
當然,作為弟弟,翟的這個事和吳秀波的事比起來,那都不是個事。