













引入多感官數據學習,華人學者摘得2021 UT-Austin最佳博士論文獎
在本年度的評選中,華人學者 Ruohan Gao 的博士學位論文《Look and Listen: From Semantic to Spatial Audio-Visual Perception》獲得了 Michael H. Granof 獎。

杰出博士論文獎設立于 1979 年,旨在表彰出色的研究以及鼓勵最高的研究、寫作、學術水平。每年頒發三個獎項,其中一篇會被選中獲得該校的最佳論文獎「Michael H. Granof 獎」。杰出論文獎獲得者將獲得 5000 美元獎金,Granof 獎獲得者獲得 6000 美元獎金。
Ruohan Gao
Ruohan Gao2015 年于香港中文大學(CUHK)信息工程系獲得一等榮譽學位,導師為劉永昌(Wing Cheong Lau)教授。
博士期間,Ruohan Gao 師從 Kristen Grauman 教授。他的研究興趣是計算機視覺、機器學習、數據挖掘等,特別是視頻中的多模態學習和多模態下的 embodied learning。2021 年初,Ruohan Gao 從德克薩斯大學奧斯汀分校獲得博士學位。
目前,Ruohan Gao 是斯坦福大學視覺與學習實驗室(SVL)的博士后研究員。
此外,Ruohan Gao 還獲得過谷歌博士生獎研金(Google Ph.D Fellowship)、Adobe 研究獎研金(Adobe Research Fellowship)等榮譽。
這篇論文研究了什么?

論文鏈接:https://ai.stanford.edu/~rhgao/Ruohan_Gao_dissertation.pdf
理解場景和事件本質上是一種多模態經驗。人們通過觀察、傾聽 (以及觸摸、嗅和品嘗) 來感知世界,特別是物體發出的聲音,無論是主動產生的還是偶然發出的,都提供了關于自身物理屬性和空間位置的有價值的信號,正如鈸在舞臺上撞擊,鳥在樹上鳴叫,卡車沿著街區疾馳,銀器在抽屜里叮當作響……
盡管通過「看」,也就是根據物體、行為或人的外表檢測的識別取得了重大進展,但它往往不能夠「聽」。在這篇論文中,作者證明了與視覺場景和事件同步的音頻可以作為豐富的訓練信號來源,用于學習 (視聽) 視覺模型。此外,作者開發了計算模型,利用音頻中的語義和空間信號,從連續的多模態觀測中理解人、地點和事物。
當前大多數計算機視覺系統的現狀是從大量「無聲」數據集的標記圖像中學習,而該論文研究目標是既要會傾聽,又要了解視覺世界。
作者表示,受到人類利用所有感官對世界進行感知的啟發,自己的長期研究目標是建立一個系統,通過結合所有的多感官輸入,能夠像人類一樣感知世界。在論文的最后一章,作者概述了在此博士論文之外希望追求的未來研究方向。
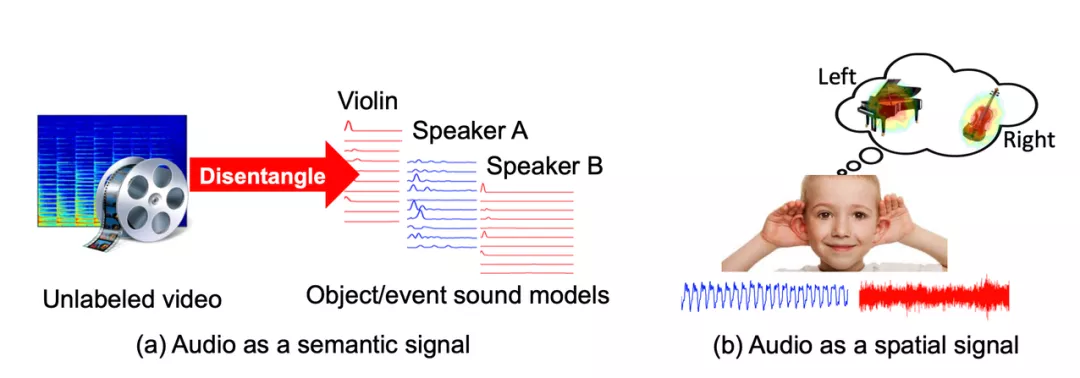
圖 1.2: 音頻本身是一個監督信號,用于語義和空間理解。
研究的首要目標是從視頻和嵌入智能體中復現視聽模型: 當多個聲源存在時,算法如何知道發聲對象是什么以及在哪里?這些視聽模型如何在傳統的視聽任務有所提升?為了解決這些問題,該研究利用了音頻中的語義和空間信號,從連續的多模態觀測中理解人、地點和事物(圖 1.2)。
這篇論文研究了以下四個重要問題,以逐步接近視聽場景綜合理解的最終目標:
- 同時觀看和聆聽包含多個聲源的未標記視頻,以學習音視頻源分離模型(第 3 章、第 4 章和第 5 章);
- 利用音頻作為預覽機制,在未修剪的視頻中實現高效的動作識別(第 6 章);
- 利用未標記視頻中的視覺信息推斷雙耳音頻,將平面單聲道音頻「提升」為空間化的聲音(第 7 章);
- 通過回聲定位學習空間圖像表征,監測來自與物理世界的聲學互動(第 8 章)。
作者表示,本論文對視聽學習的研究,體現了無監督或自監督的多感官數據學習對人工智能的未來發展具有積極而重要的意義。
更多細節請參見論文原文。
























