一個百億級日志系統(tǒng)是怎么設(shè)計出來的?
日志是記錄系統(tǒng)中各種問題信息的關(guān)鍵,也是一種常見的海量數(shù)據(jù)。
日志平臺為集團所有業(yè)務(wù)系統(tǒng)提供日志采集、消費、分析、存儲、索引和查詢的一站式日志服務(wù)。
主要為了解決日志分散不方便查看、日志搜索操作復(fù)雜且效率低、業(yè)務(wù)異常無法及時發(fā)現(xiàn)等等問題。
隨著有贊業(yè)務(wù)的發(fā)展與增長,每天都會產(chǎn)生百億級別的日志量(據(jù)統(tǒng)計,平均每秒產(chǎn)生 50 萬條日志,峰值每秒可達(dá) 80 萬條)。日志平臺也隨著業(yè)務(wù)的不斷發(fā)展經(jīng)歷了多次改變和升級。
本文跟大家分享有贊在當(dāng)前日志系統(tǒng)的建設(shè)、演進以及優(yōu)化的經(jīng)歷,這里先拋磚引玉,歡迎大家一起交流討論。
原有日志系統(tǒng)
有贊從 2016 年就開始構(gòu)建適用于業(yè)務(wù)系統(tǒng)的統(tǒng)一日志平臺,負(fù)責(zé)收集所有系統(tǒng)日志和業(yè)務(wù)日志,轉(zhuǎn)化為流式數(shù)據(jù)。
通過 Flume 或者 Logstash 上傳到日志中心(Kafka 集群),然后供 Track、Storm、Spark 及其他系統(tǒng)實時分析處理日志。
并將日志持久化存儲到 HDFS 供離線數(shù)據(jù)分析處理,或?qū)懭?ElasticSearch 提供數(shù)據(jù)查詢。
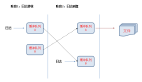
整體架構(gòu)如圖 2-1 所示:
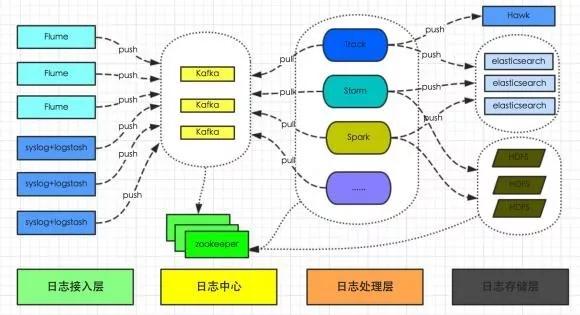
圖 2-1:原有日志系統(tǒng)架構(gòu)
隨著接入的應(yīng)用越來越多,接入的日志量越來越大,逐漸出現(xiàn)一些問題和新的需求,主要在以下幾個方面:
- 業(yè)務(wù)日志沒有統(tǒng)一的規(guī)范,業(yè)務(wù)日志格式各式各樣,新應(yīng)用接入無疑大大的增加了日志的分析、檢索成本。
- 多種數(shù)據(jù)日志數(shù)據(jù)采集方式,運維成本較高。
- 日志平臺收集了大量用戶日志信息,當(dāng)時無法直接的看到某個時間段,哪些錯誤信息較多,增加定位問題的難度。
- 存儲方面。
關(guān)于存儲方面:
- 采用了 ES 默認(rèn)的管理策略,所有的 Index 對應(yīng) 3*2 Shard(3 個 Primary,3 個 Replica)。
有部分 Index 數(shù)量較大,對應(yīng)單個 Shard 對應(yīng)的數(shù)據(jù)量就會很大,導(dǎo)致有 Hot Node,出現(xiàn)很多 bulk request rejected,同時磁盤 IO 集中在少數(shù)機器上。
- 對于 bulk request rejected 的日志沒有處理,導(dǎo)致業(yè)務(wù)日志丟失。
- 日志默認(rèn)保留 7 天,對于 SSD 作為存儲介質(zhì),隨著業(yè)務(wù)增長,存儲成本過于高昂。
- 另外 Elasticsearch 集群也沒有做物理隔離,ES 集群 OOM 的情況下,使得集群內(nèi)全部索引都無法正常工作,不能為核心業(yè)務(wù)運行保駕護航。
現(xiàn)有系統(tǒng)演進
日志從產(chǎn)生到檢索,主要經(jīng)歷以下幾個階段:
- 采集
- 傳輸
- 緩沖
- 處理
- 存儲
- 檢索
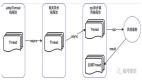
詳細(xì)架構(gòu)如圖 3-1 所示:
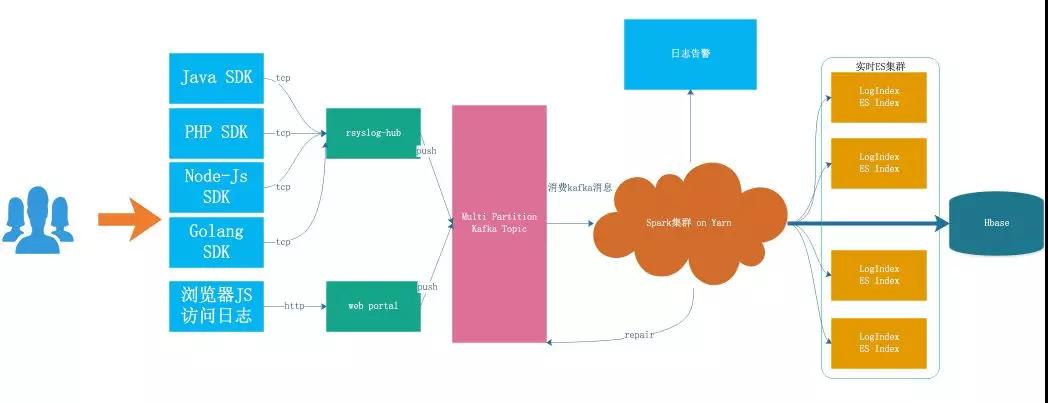
圖 3-1:現(xiàn)有系統(tǒng)架構(gòu)
日志接入
日志接入目前分為兩種方式:
- SDK 接入:日志系統(tǒng)提供了不同語言的 SDK,SDK 會自動將日志的內(nèi)容按照統(tǒng)一的協(xié)議格式封裝成最終的消息體,并通過 TCP 的方式發(fā)送到日志轉(zhuǎn)發(fā)層(Rsyslog-Hub)。
- HTTP Web 服務(wù)接入:有些無法使用 SDK 接入日志的業(yè)務(wù),可以通過 HTTP 請求直接發(fā)送到日志系統(tǒng)部署的 Web 服務(wù),統(tǒng)一由 Web Protal 轉(zhuǎn)發(fā)到日志緩沖層的 Kafka 集群。
日志采集
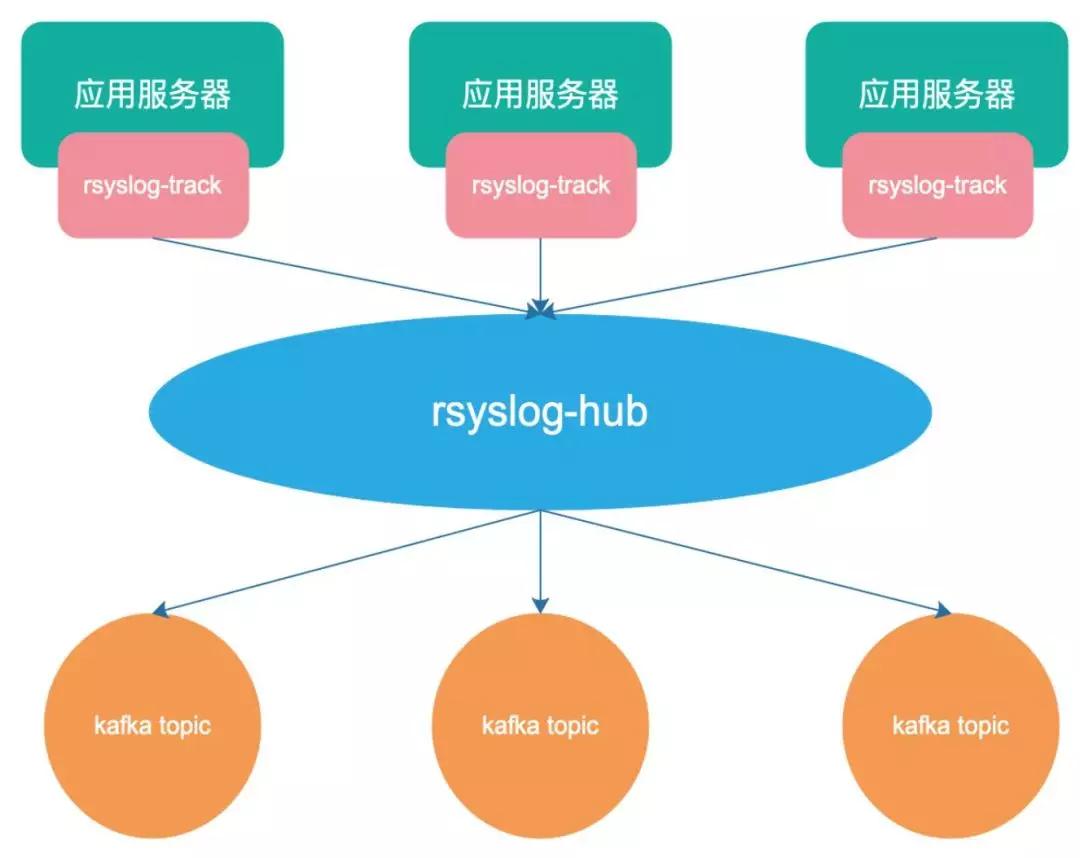
現(xiàn)在有 Rsyslog-Hub 和 Web Portal 做為日志傳輸系統(tǒng),Rsyslog 是一個快速處理收集系統(tǒng)日志的程序,提供了高性能、安全功能和模塊化設(shè)計。
之前系統(tǒng)演進過程中使用過直接在宿主機上部署 Flume 的方式,由于 Flume 本身是 Java 開發(fā)的,會比較占用機器資源而統(tǒng)一升級為使用 Rsyslog 服務(wù)。
為了防止本地部署與 Kafka 客戶端連接數(shù)過多,本機上的 Rsyslog 接收到數(shù)據(jù)后,不做過多的處理就直接將數(shù)據(jù)轉(zhuǎn)發(fā)到 Rsyslog-Hub 集群。
通過 LVS 做負(fù)載均衡,后端的 Rsyslog-Hub 會通過解析日志的內(nèi)容,提取出需要發(fā)往后端的 Kafka Topic。
日志緩沖
Kafka 是一個高性能、高可用、易擴展的分布式日志系統(tǒng),可以將整個數(shù)據(jù)處理流程解耦。
將 Kafka 集群作為日志平臺的緩沖層,可以為后面的分布式日志消費服務(wù)提供異步解耦、削峰填谷的能力,也同時具備了海量數(shù)據(jù)堆積、高吞吐讀寫的特性。
日志切分
日志分析是重中之重,為了能夠更加快速、簡單、精確地處理數(shù)據(jù)。日志平臺使用 Spark Streaming 流計算框架消費寫入 Kafka 的業(yè)務(wù)日志。
Yarn 作為計算資源分配管理的容器,會跟不同業(yè)務(wù)的日志量級,分配不同的資源處理不同日志模型。
整個 Spark 任務(wù)正式運行起來后,單個批次的任務(wù)會將拉取到的所有的日志分別異步的寫入到 ES 集群。
業(yè)務(wù)接入之前可以在管理臺對不同的日志模型設(shè)置任意的過濾匹配的告警規(guī)則,Spark 任務(wù)每個 Excutor 會在本地內(nèi)存里保存一份這樣的規(guī)則。
在規(guī)則設(shè)定的時間內(nèi),計數(shù)達(dá)到告警規(guī)則所配置的閾值后,通過指定的渠道給指定用戶發(fā)送告警,以便及時發(fā)現(xiàn)問題。
當(dāng)流量突然增加,ES 會有 bulk request rejected 的日志重新寫入 Kakfa,等待補償。
日志存儲
原先所有的日志都會寫到 SSD 盤的 ES 集群,LogIndex 直接對應(yīng) ES 里面的索引結(jié)構(gòu)。
隨著業(yè)務(wù)增長,為了解決 ES 磁盤使用率單機最高達(dá)到 70%~80% 的問題,現(xiàn)有系統(tǒng)采用 Hbase 存儲原始日志數(shù)據(jù)和 ElasticSearch 索引內(nèi)容相結(jié)合的方式,完成存儲和索引。
Index 按天的維度創(chuàng)建,提前創(chuàng)建 Index 會根據(jù)歷史數(shù)據(jù)量,決定創(chuàng)建明日 Index 對應(yīng)的 Shard 數(shù)量,也防止集中創(chuàng)建導(dǎo)致數(shù)據(jù)無法寫入。
現(xiàn)在日志系統(tǒng)只存近 7 天的業(yè)務(wù)日志,如果配置更久的保存時間的,會存到歸檔日志中。
對于存儲來說,Hbase、ES 都是分布式系統(tǒng),可以做到線性擴展。
多租戶
隨著日志系統(tǒng)不斷發(fā)展,全網(wǎng)日志的 QPS 越來越大,并且部分用戶對日志的實時性、準(zhǔn)確性、分詞、查詢等需求越來越多樣。
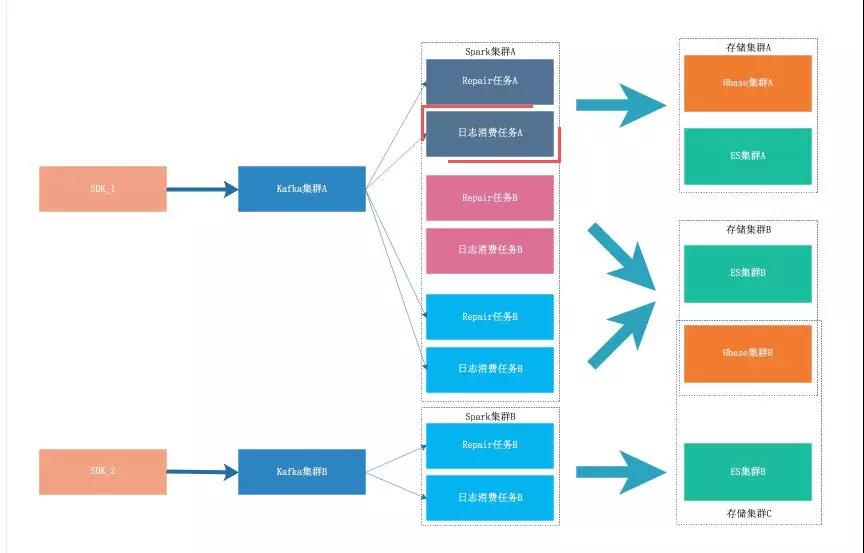
為了滿足這部分用戶的需求,日志系統(tǒng)支持多租戶的的功能,根據(jù)用戶的需求,分配到不同的租戶中,以避免相互影響。
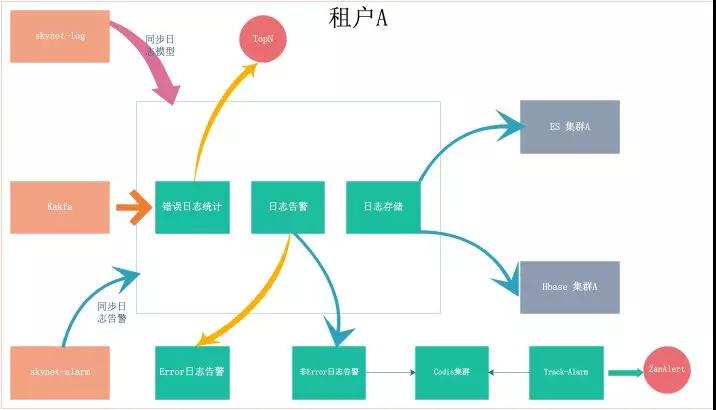
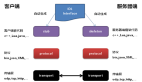
針對單個租戶的架構(gòu)如下:
- SDK:可以根據(jù)需求定制,或者采用天網(wǎng)的 TrackAppender 或 SkynetClient。
- Kafka 集群:可以共用,也可以使用指定 Kafka 集群。
- Spark 集群:目前的 Spark 集群是在 Yarn 集群上,資源是隔離的,一般情況下不需要特地做隔離。
- 存儲:包含 ES 和 Hbase,可以根據(jù)需要共用或單獨部署 ES 和 Hbase。
現(xiàn)有問題和未來規(guī)劃
目前,有贊日志系統(tǒng)作為集成在天網(wǎng)里的功能模塊,提供簡單易用的搜索方式,包括時間范圍查詢、字段過濾、NOT/AND/OR、模糊匹配等方式。
并能對查詢字段高亮顯示,定位日志上下文,基本能滿足大部分現(xiàn)有日志檢索的場景。
但是日志系統(tǒng)還存在很多不足的地方,主要有:
- 缺乏部分鏈路監(jiān)控:日志從產(chǎn)生到可以檢索,經(jīng)過多級模塊,現(xiàn)在采集,日志緩沖層還未串聯(lián),無法對丟失情況進行精準(zhǔn)監(jiān)控,并及時推送告警。
- 現(xiàn)在一個日志模型對應(yīng)一個 Kafka Topic,Topic 默認(rèn)分配三個 Partition。
由于日志模型寫入日志量上存在差異,導(dǎo)致有的 Topic 負(fù)載很高,有的 Topic 造成一定的資源浪費,且不便于資源動態(tài)伸縮。
Topic 數(shù)量過多,導(dǎo)致 Partition 數(shù)量過多,對 Kafka 也造成了一定資源浪費,也會增加延遲和 Broker 宕機恢復(fù)時間。
- 目前 Elasticsearch 中文分詞我們采用 ikmaxword,分詞目標(biāo)是中文,會將文本做最細(xì)粒度的拆分,但是日志大部分都是英文,分詞效果并不是很好。
上述的不足之處也是我們以后努力改進的地方,除此之外,對于日志更深層次的價值挖掘也是我們探索的方向,從而為業(yè)務(wù)的正常運行保駕護航。