圖像識別沒你想的那么難!看完這篇你也能成專家
原創【51CTO.com原創稿件】本地生活場景中包含大量極富挑戰的計算機視覺任務,如菜單識別,招牌識別,菜品識別,商品識別,行人檢測與室內視覺導航等。
這些計算機視覺任務對應的核心技術可以歸納為三類:物體識別,文本識別與三維重建。
2018 年 11 月 30 日-12 月 1 日,由 51CTO 主辦的 WOT 全球人工智能技術峰會在北京粵財 JW 萬豪酒店隆重舉行。
本次峰會以人工智能為主題,阿里巴巴本地生活研究院人工智能部門的負責人李佩和大家分享他們在圖像識別的過程中所遇到各種問題,以及尋求的各種解法。
什么是本地生活場景

我們所理解的本地生活場景是:從傳統的 O2O 發展成為 OMO(Online-Merge-Offline)。
對于那些打車應用和餓了么外賣之類的 O2O 而言,它們的線上與線下的邊界正在變得越來越模糊。
傳統的線上的訂單已不再是只能流轉到線下,它們之間正在發生著互動和融合。

在 2018 年,我們看到滴滴通過大量投入,組建并管理著自己的車隊。他們在車里裝了很多監控設備,試圖改造線下的車與人。
同樣,對于餓了么而言,我們不但對線下物流的配送進行了改造,而且嘗試著使用機器人,來進行無人配送、以及引入了智能外賣箱等創新。
可見在本地生活場景中,我們的核心任務就是將智能物聯(即 AI+IoT)應用到 OMO 場景中。
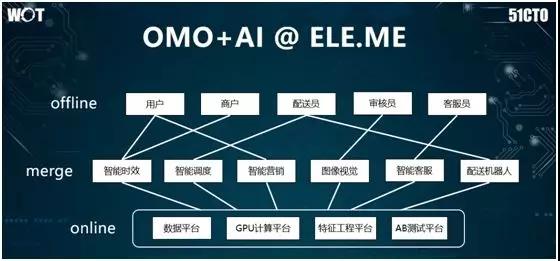
上圖是阿里巴巴本地生活餓了么業務的人工智能應用的邏輯架構。和其他所有人工智能應用計算平臺類似,我們在底層用到了一些通用的組件,包括:數據平臺、GPU 平臺、特征工程平臺、以及 AB 測試平臺。
在此之上,我們有:智能配送、分單調度和智能營銷等模塊。同時,算法人員也進行了各種數據挖掘、機器學習和認準優化。

目前對于阿里巴巴的本地生活而言,我們的圖像視覺團隊承擔著整個本地生活集團內部,與圖像及視覺相關的所有識別和檢測任務。而所有的圖像處理都是基于深度學習來實現的。
我將從如下三個方面介紹我們的實踐:
- 物體的識別。
- 文本的識別。此處特指對于菜單、店鋪招牌、商品包裝圖片文字的識別,而非傳統意義上對于報紙、雜志內容的識別。
- 三維重建。
物體識別

在我們的生活場景中,有著大量對于物體識別的需求,例如:
- 餓了么平臺需要檢測騎手的著裝是否規范。由于騎手眾多,光靠人工管控,顯然是不可能的。
因此在騎手的 App 中,我們增加了著裝檢測的功能。騎手每天只需發送一張包含其帽子、衣服、餐箱的自拍照到平臺上,我們的圖像算法便可在后臺自動進行檢測與識別。
通過人臉的檢測,我們能夠認清是否騎手本人,進而檢查他的餐箱和頭盔。
- 場景目標識別。通過檢測行人、辦公區的桌椅、以及電梯的按鈕,保障機器人在無人配送的生活場景中認識各種物體。
- 合規檢測。由于餓了么平臺上有著大量的商品、餐品和招牌圖片,營業執照,衛生許可證,以及健康證等。
因此我們需要配合政府部門通過水印和二維碼,來檢查各家餐館的營業執照和衛生許可證是否被篡改過。
另外,我們也要求餐館的菜品圖片中不能出現餐館的招牌字樣。這些都會涉及到大量的計算機視覺處理。
- 場景文本識別。在物體識別的基礎上,通過目標檢測的應用,對物體上的文字進行識別,如:菜單里的菜品和菜價。

對于圖片目標的檢測評價,目前業界有兩個指標:
- 平均檢測精度。即物體框分類的準確性。先計算每個類別的準確性,再求出所有類別的準確性。
- IOU(交并比)。即預測物體框與實際標準物體框之間覆蓋度的比例,也就是交集和并集的比例。
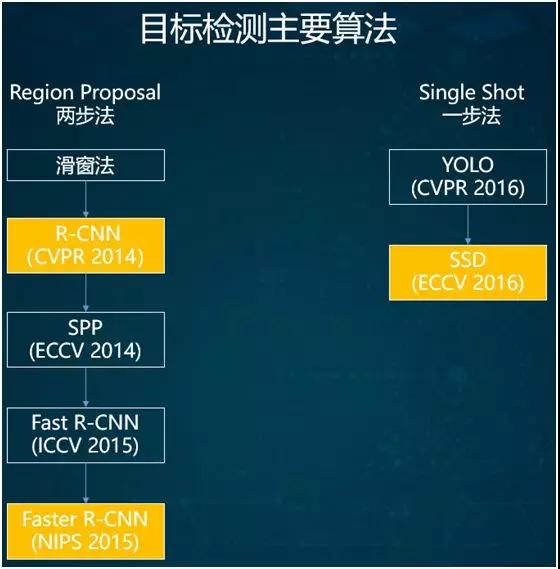
上圖列出了目標檢測的常用基礎算法,它們分為兩類:
- 兩步法
- 一步法
兩步法歷史稍久一些,它源于傳統的滑窗法。2014 年,出現了采用深度學習進行目標檢測的 R-CNN。
之后又有了金字塔池化的 SPP 方法,以及在此之上研發出來的 Fast R-CNN 和 Faster R-CNN 兩個版本。
當然,Faster R-CNN 算法在被運用到機器人身上進行實時檢測時,為了達到毫秒級檢測結果的反饋,它往往會給系統的性能帶來巨大的壓力。
因此,有人提出了一步法,其中最常用的是在 2016 年被提出的 SSD 算法。
雖然 2017 年、2018 年也出現了一些新的算法,但是尚未得到廣泛的認可,還需進一步的“沉淀”。
下面,我們來討論那些針對不同場景目標的解決算法。在此,我不會涉及任何的公式,也不會涉及任何的推導,僅用簡單淺顯的語言來描述各個目標檢測算法背后的核心思想。
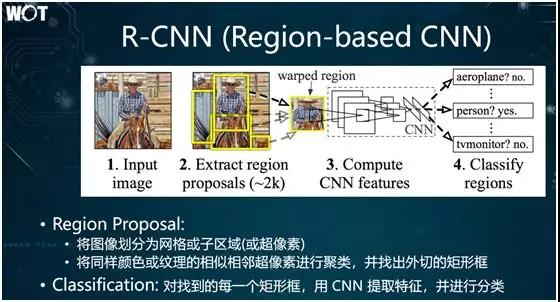
R-CNN 的簡單思路是:
- Region Proposal。首先,將目標圖像劃分成許多個網格單元,這些網格被稱為超像素;然后,將同樣顏色或紋理的相似相鄰超像素進行聚類,并找出外切的矩形框。該矩形框便稱為 Region Proposal。
- Classification。首先用 CNN 提取特征;再得到卷積的線性圖,然后再用 SoftMax 或者其他的分類方法進行普通分類。

各種上述 R-CNN 流程的問題在于:產生的候選框數量過多。由于矩形框的形狀,包括長度、寬度、中心坐標等各不相同,因此如果一張圖中包含的物體過多,則找出來的矩形框可達成千上萬個。
鑒于每個候選框都需要單獨做一次 CNN 分類,其整體算法的效率并不高。當然,作為后期改進算法的基礎,R-CNN 提供了一種全新的解決思路。
SPP(空間金字塔池化)的特點是:
- 所有的候選框共享一次卷積網絡的前向計算。即:先將整張圖進行一次性 CNN 計算,并提取特征后,然后在特征響應圖上進行后續的操作。由于僅作卷積計算,其性能提升了不少。
- 通過金字塔結構獲得在不同尺度空間下的 ROI 區域。即:通過將圖片分成許多不同的分辨率,在不同的尺度上去檢測物體。
例如:某張圖片上既有大象,又有狗,由于大象與狗的體積差異較大,因此傳統 R-CNN 檢測,只能專注大象所占的圖像面積。
而 SPP 會將圖像縮小,以定位較小的圖片。它可以先檢測出大象,再通過圖像放大,檢測出狗。可見它能夠獲取圖像在不同尺度下的特征。
- FastR-CNN 在簡化 SPP 的同時,通過增加各種加速的策略,來提升性能。不過,它在算法策略上并無太大的變動。
- FasterR-CNN 創造性地提出了使用神經網絡 RPN(Region Proposal Networks),來代替傳統的 R-CNN 和 SPP,并得到了廣泛的應用。
它通過神經網絡來獲取物體框,然后再使用后續的 CNN 來對物體框進行檢測,進而實現了端到端的訓練。
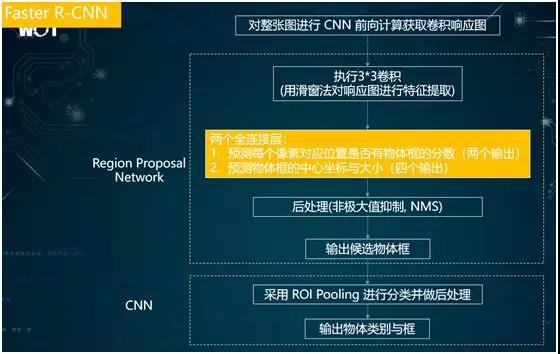
上圖是我整理的 Faster R-CNN 執行邏輯框架圖,其流程為:
- 使用 CNN 計算出圖像的卷積響應圖。
- 執行 3×3 的卷積。
- 使用兩個全連接層,預測每個像素所對應的位置是否有物體框的出現,進而產生兩個輸出(“是”的概率和“否”的概率)。
如果有物體框的輸出,則預測物體框中心坐標與大小。此處有四個輸出(中心坐標的 X 和 Y,以及長和寬)。因此,對于每個物體框來說,共有六個輸出。
- 使用通用的 NMS 進行后處理,旨在對一些重疊度高的物體框進行篩選。例如:圖中有一群小狗,那么檢測出來的物體框就可能會重疊在一起。
通過采用 NMS,我們就能對這些重合度高的框進行合并或忽略等整理操作,并最終輸出物體的候選框。
- 采用 CNN 進行分類。
可見,上述提到的各種兩步方法雖然精度高,但是速度較慢。而在許多真實場景中,我們需要對目標進行實時檢測。
例如:在無人駕駛時,我們需要實時地檢測周圍的車輛、行人和路標等。因此,一步方法正好派上用場。YOLO 和 SSD 都屬于此類。

YOLO 方法的核心思想是:對于整張圖片只需要掃描一次,其流程為:
- 使用 CNN 獲取卷積響應圖。
- 將該響應圖劃分成 S*S 個格子。
- 使用兩個全連接層來預測物體框的中心坐標與大小,以及格子在物體類別上的概率。
- 將圖片中所有關于物體檢測的信息存入一個 Tensor(張量)。
- 使用后處理,輸出物體的類別與框。
由于此方法較為古老,因此在實際應用中,一般不被推薦。
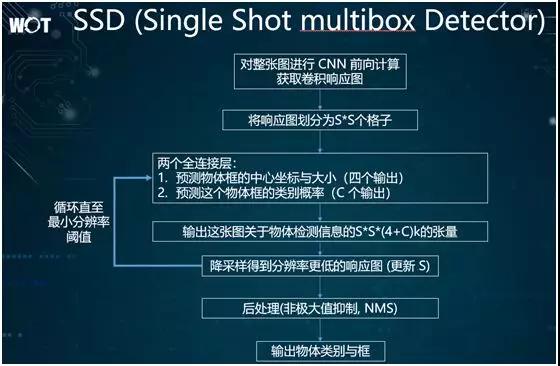
SSD 采用了一種類似于金字塔結構的處理方法。它通過循環來對給定圖片不斷進行降采樣,進而得到分辨率更低的另外一張圖片。
同時,在降采樣之后的低分辨率圖片上,該方法還會反復進行物體檢測,以發覺物體的信息。
因此,SSD 的核心思想是:將同一張圖片分成了多個級別,從每個級別到其下一個級別采用降采樣的方式,從而檢測出每個級別圖片里的物體框,并予以呈現。
可見,對于 YOLO 而言,SSD 能夠發現不同分辨率的目標、發掘更多倍數的候選物體框,在后續進行重排序的過程中,我們會得到更多條線的預定。
當然 SSD 也是一種非常復雜的算法,里面含有大量有待調整的細節參數,因此大家可能會覺得不太好控制。
另外,SSD 畢竟還是一種矩形框的檢測算法,如果目標物體本身形狀并不規則,或呈現為長條形的話,我們就需要使用語音分割來實現。
文本識別

除了通過傳統的 OCR 方法,來對健康證、營業執照進行識別之外,我們還需要對如下場景進行 OCR 識別:
- 通過識別店鋪的招牌,以保證該店鋪上傳的照片與其自身描述相符。
- 通過對小票和標簽之類票據的識別,把靠人流轉的傳統物流過程,變成更加自動化的過程。
- 對各式各樣的菜單進行識別。

傳統的 OCR 流程一般分為三步:
- 簡單的圖像處理。例如:根據拍攝的角度,進行幾何校正。
- 提取數字圖像的特征,進行逐個字符的切割。
- 對于單個字符采用 AdaBoost 或 SVM 之類的統計式機器學習,進而實現光學文字識別。
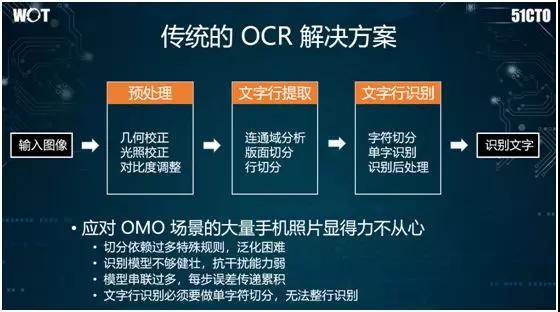
但是鑒于如下原因,該流程并不適合被應用到店鋪的菜單識別上:
- 由于過多地依賴于攝像角度和幾何校正之類的規則,因此在處理手機拍攝時,會涉及到大量半人工的校正操作。
- 由于目標文字大多是戶外的廣告牌,會受到光照與陰影的影響,同時手機的抖動也可能引發模糊,所以傳統識別模型不夠健壯,且抗干擾能力弱。
- 由于上述三步走的模型串聯過多,因此每一步所造成的誤差都可能傳遞和累積到下一步。
- 傳統方法并非端到端模式,且文字行識別必須進行單字符切分,因此無法實現對整行進行識別。

因此,我們分兩步采取了基于深度學習的識別方案:文字行檢測+文字行識別。
即先定位圖片中的文字區域,再采用端到端的算法,實現文字行的識別。
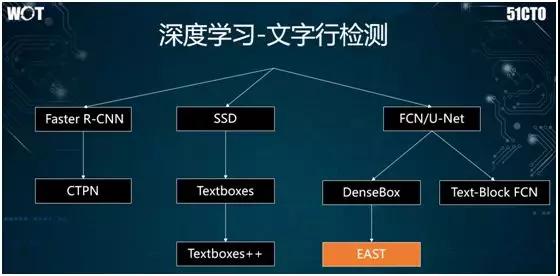
如上圖所示,文字行的檢測源于物體識別的算法,其中包括:
- 由 Faster R-CNN 引發產生了 CTPN 方法,專門進行文字行的檢測。
- 由 SSD 引出的 Textboxes 和 Textboxes++。
- 由全卷積網絡或稱為 U-Net 引出的 EAST 等。
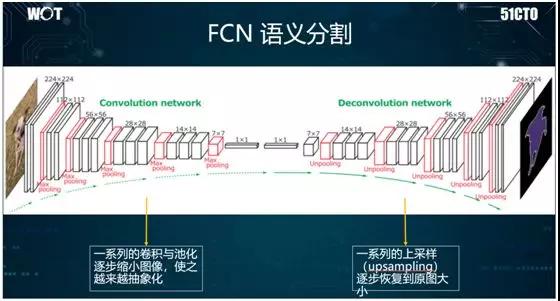
說到全卷積網絡(FCN),它經常被用來進行語義分割,而且其 OCR 的效果也不錯的。
從原理上說,它采用卷積網絡,通過提取特征,不斷地進行卷積與池化操作,使得圖像越來越小。
接著再進行反卷積與反池化操作,使圖像不斷變大,進而找到圖像物體的邊緣。因此,整個結構呈U字型,故與 U-Net 關聯性較強。
如上圖所示:我們通過將一張清晰的圖片不斷縮小,以得到只有幾個像素的藍、白色點,然后再將其逐漸放大,以出現多個藍、白色區域。
接著,我們基于該區域,使用 SoftMax 進行分類。最終我們就能找到該圖像物體的邊緣。

經過實踐,我們覺得基于全卷積網絡的 EAST效果不錯。如上圖所示,其特點是能夠檢測任意形狀的四邊形,而不局限于矩形。
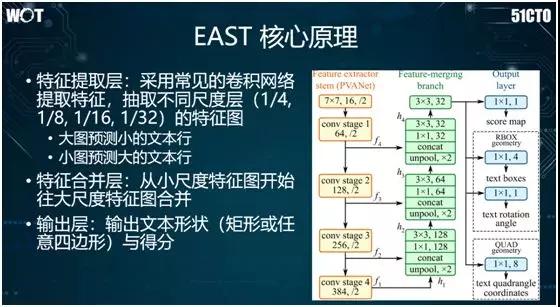
EAST 的核心原理為:我們對上圖左側的區域不斷地進行卷積操作,讓圖像縮小。在中間綠色區域,我們將不同尺度的特征合并起來。
而在右側藍色區域中,我們基于取出的特征,進行兩種檢測:
- RBOX(旋轉的矩形框),假設某個文字塊仍為矩形,通過旋轉以顯示出上面的文字。
- QUAD(任意四邊形),給定四個點,連成一個四邊形,對其中的文字進行檢測。
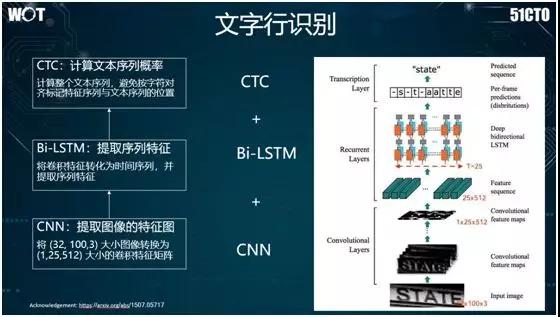
對于文字行的識別,目前業界常用的方法是 CTC+Bi-LSTM+CNN。如上圖所示,我們應該從下往上看:首先我們用 CNN 提取給定圖像的卷積特征響應圖。
接著將文字行的卷積特征轉化為序列特征,并使用雙向 LSTM 將序列特征提取出來;然后采用 CTC 方法,去計算該圖像的序列特征與文本序列特征之間所對應的概率。

值得一提的是,CTC 方法的基本原理為:首先通過加入空白字符,采用 SoftMax 進行步長特征與對應字符之間的分類。
籍此,對于每個圖像序列,它都能得到字符序列出現的概率。然后通過后處理,將空白字符和重復符號刪除掉,并最終輸出效果。
三維重建
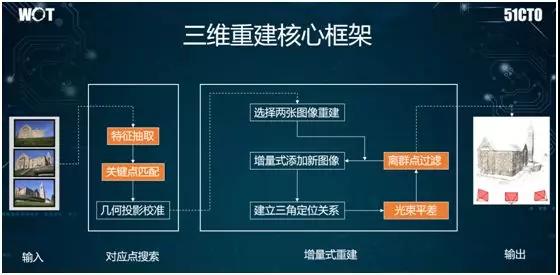
在無人駕駛的場景中,我們有時候可能需要通過移動攝像頭,將采集到的數據構建出建筑物的三維結構。
如上圖所示,其核心框架為:首先對各種給定的圖片進行不只是 CNN 的特征提取,我們還可以用 SIFT 方法(見下文)提取其中的一些角點特征。
然后,我們對這些角點進行三角定位,通過匹配找到攝像頭所在的空間位置。
我們使用光束平差,來不斷地構建空間位置與攝像頭本身的關系,進而實現三維構建。
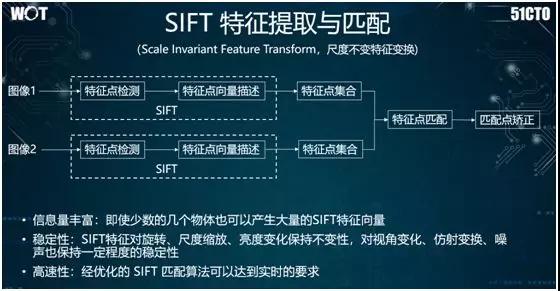
上面提到了 SIFT 特征提取,它的特點是本身的速度比較慢。因此為了滿足攝像頭在移動過程中進行近實時地三維構建,我們需要對該算法進行大量的調優工作。
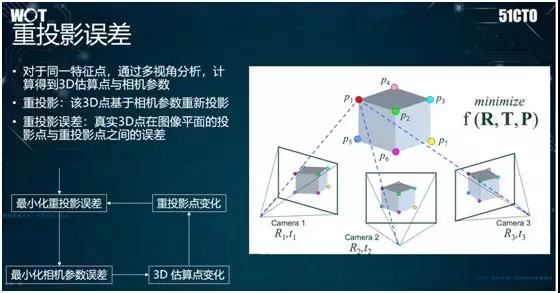
同時,在三維重建中,我們需要注意重投影誤差的概念。其產生的原因是:通常,現實中的三維點落到攝像機上之后,會被轉化成平面上的點。
如果我們想基于平面的圖像,構建出一個三維模型的話,就需要將平面上的點重新投放到三維空間中。
然而,如果我們對攝像機本身參數的估算不太準確,因此會造成重新投放的點與它在三維世界的真正位置之間出現誤差。
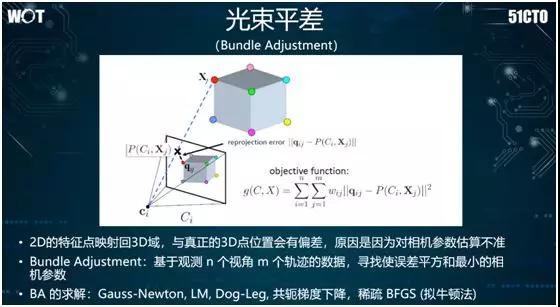
如前所述,我們還可以使用光束平差來求解矩形的線性方程組。通常它會用到稀疏 BFGS(擬牛頓法)去進行求解,進而將各個三維的點在空間上予以還原。
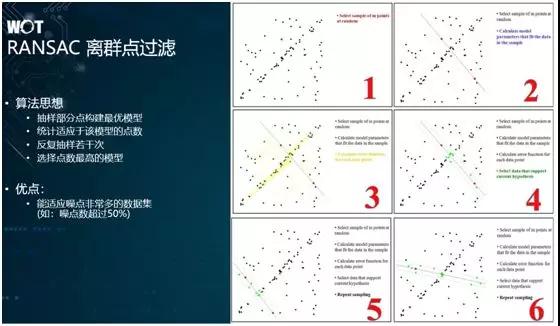
關于離群點的過濾。由于我們在做三維重建的過程中,會碰到大量的噪點,那么為了過濾它們,我們會使用 RANSAC 方法來進行離群點的過濾。
從原理上說,它會不斷隨機地抽取部分點,并構建自由模型,進而評比出較好的模型。

如上圖所示,由于上方兩張圖里有著大量的邊緣位置特征,我們可以通過 RANSAC 離群點過濾,將它們的特征點對應起來,并最終合成一張圖。而且通過算法,我們還能自動地發覺第二張圖在角度上存在著傾斜。
總的說來,我們在物體識別、文本識別、以及三維重建領域,都嘗試了大量的算法。希望通過上述分析,大家能夠對各種算法的效果有所認識與了解。
作者:李佩
簡介:阿里巴巴本地生活研究院人工智能部門負責人

【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】