Boosting和Bagging: 如何開發(fā)一個魯棒的機器學(xué)習(xí)算法
導(dǎo)讀
機器學(xué)習(xí)和數(shù)據(jù)科學(xué)需要的不僅僅是將數(shù)據(jù)放入python庫中并利用得到的結(jié)果。數(shù)據(jù)科學(xué)家需要真正理解數(shù)據(jù)和數(shù)據(jù)背后的過程,才能實現(xiàn)一個成功的系統(tǒng)。這篇文章從Bootstraping開始介紹,讓你聽懂什么是Boosting,什么是Bagging。
機器學(xué)習(xí)和數(shù)據(jù)科學(xué)需要的不僅僅是將數(shù)據(jù)放入python庫中并利用得到的結(jié)果。
數(shù)據(jù)科學(xué)家需要真正理解數(shù)據(jù)和數(shù)據(jù)背后的過程,才能實現(xiàn)一個成功的系統(tǒng)。
實現(xiàn)這個的一個關(guān)鍵方法是知道模型何時可以從使用bootstrapping中受益。這些就是所謂的集成模型。集成模型的例子有AdaBoost和隨機梯度提升。
為什么使用集成模型?
它們可以幫助提高算法的準確性或提高模型的魯棒性。這方面的兩個例子是Boosting和Bagging。對于數(shù)據(jù)科學(xué)家和機器學(xué)習(xí)工程師來說,Boosting和Bagging是必須知道的主題。特別是如果你打算參加數(shù)據(jù)科學(xué)/機器學(xué)習(xí)面試。
本質(zhì)上,集成學(xué)習(xí)遵循集成這個詞。不同的是,不是讓幾個人用不同的八度來創(chuàng)造一個優(yōu)美的和聲(每個聲音填補另一個的空白)。集成學(xué)習(xí)使用同一算法的數(shù)百到數(shù)千個模型,這些模型一起工作以找到正確的分類。
另一種考慮集成學(xué)習(xí)的方法是盲人與大象的寓言。每個盲人都發(fā)現(xiàn)了大象的一個特征,他們都認為這是不同的東西。然而,如果他們聚在一起討論這個問題,他們也許能夠弄明白他們在看什么。
使用諸如Boosting和Bagging這樣的技術(shù)可以提高統(tǒng)計模型的魯棒性并減少方差。
現(xiàn)在的問題是,這些不同的“B”開頭的詞,都有什么區(qū)別呢?
Bootstrapping
首先我們來討論一下bootstrapping的重要概念。這一點有時會被忽略,因為許多數(shù)據(jù)科學(xué)家會直接去解釋“Boosting”和“Bagging”。這兩者都需要bootstrapping。
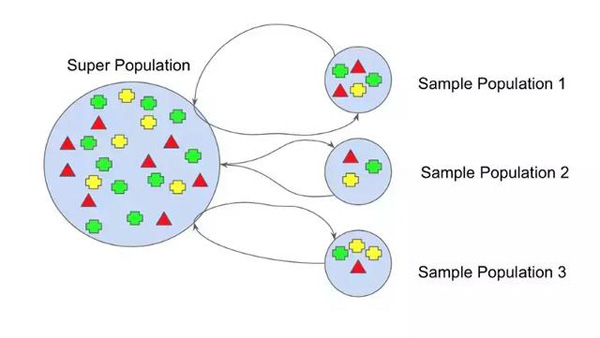
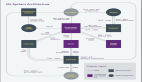
Figure 1 Bootstrapping
在機器學(xué)習(xí)中,bootstrap方法是指隨機抽樣和替換。這種樣本稱為重采樣。這使得模型或算法能夠更好地理解重采樣中存在的各種偏差、方差和特征。從數(shù)據(jù)中提取一個樣本允許重新采樣包含不同的特征,而這些特征可能是作為一個整體包含的。如圖1所示,其中每個樣本總體都有不同的部分,而且沒有一個是相同的。這將影響數(shù)據(jù)集的總體均值、標準差和其他描述性指標。反過來,它可以開發(fā)更健壯的模型。
Bootstrapping對于小型數(shù)據(jù)集來說也非常有用,這些數(shù)據(jù)集可能有過擬合的趨勢。事實上,我們向一家公司推薦了這個,因為他們的數(shù)據(jù)集離“大數(shù)據(jù)”還很遠。在這種情況下,Bootstrapping 是一種解決方案,因為利用Bootstrapping 的算法可以更加健壯,并根據(jù)所選擇的方法(Boosting或Bagging)處理新的數(shù)據(jù)集。
使用bootstrap方法的原因是它可以測試解的穩(wěn)定性。通過使用多個樣本數(shù)據(jù)集,然后測試多個模型,可以提高魯棒性。也許一個樣本數(shù)據(jù)集的均值比另一個樣本數(shù)據(jù)集的均值大,或者有不同的標準差。這可能會破壞過擬合并且沒有使用有不同變化的數(shù)據(jù)集進行測試過的模型。
bootstrapping 變得非常普遍的原因之一是計算能力的增強。這使得使用不同的重采樣可以進行比以前多很多倍的排列。Bootstrapping在Bagging和boost中都有使用,下面將對此進行討論。
Bagging
Bagging實際上是指(Bootstrap Aggregators)。大多數(shù)使用bagging算法引用的論文或帖子都會引用Leo Breiman[1996年]的一篇論文“bagging Predictors”。
Leo將Bagging描述為:
“Bagging predictors是一種生成一個預(yù)測器的多個版本并使用這些版本來獲得一個聚合預(yù)測器的方法”
Bagging所做的是幫助減少方差,這些模型可能非常準確,但只基于它們所訓(xùn)練的數(shù)據(jù)。這也被稱為過擬合。
過擬合是指一個函數(shù)太適合數(shù)據(jù)。這通常是因為實際的方程太復(fù)雜,無法考慮每個數(shù)據(jù)點和離群值。

Figure 2 Overfitting
另一個容易過擬合算法的例子是決策樹。使用決策樹開發(fā)的模型需要非常簡單的啟發(fā)式。決策樹由一組if-else語句組成,這些語句按照特定的順序執(zhí)行。因此,如果將數(shù)據(jù)集更改為新的數(shù)據(jù)集,那么與前一個數(shù)據(jù)集相比,底層特征的分布可能會有一些偏差或差異。這是因為數(shù)據(jù)不適合模型。
Bagging通過采樣和替換數(shù)據(jù)來在數(shù)據(jù)中創(chuàng)建自己的方差,從而繞過這個問題。Bagging同時測試多個假設(shè)(模型)。反過來,這通過使用多個很可能由具有各種屬性(中值、平均值等)的數(shù)據(jù)組成的樣本來減少噪聲。
一旦每個模型都有了假設(shè)。模型使用投票進行分類或平均進行回歸。這就是“Bootstrap Aggregating”中的“Aggregating”發(fā)揮作用的地方。每個假設(shè)的權(quán)重都是一樣的。當我們稍后討論boost時,這是這兩種方法不同的地方之一。
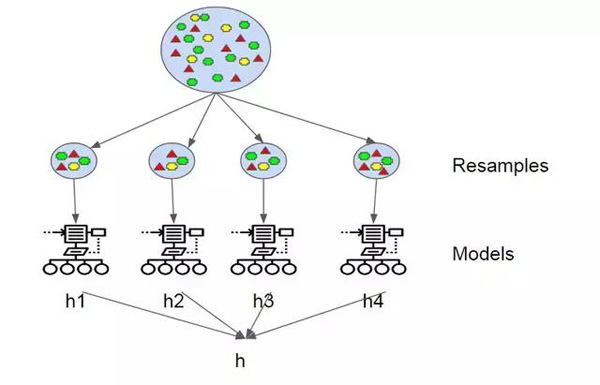
Figure 3 Bagging
本質(zhì)上,所有這些模型同時運行,并對哪個假設(shè)最準確進行投票。
這有助于減少方差,即減少過擬合。
Boosting
Boosting 是指一組利用加權(quán)平均使弱學(xué)習(xí)器變成強學(xué)習(xí)器的算法。與bagging不同,bagging讓每個模型獨立運行,然后在最后聚合輸出,而不優(yōu)先于任何模型。Boosting 全靠“團隊合作”。每個運行的模型都規(guī)定了下一個模型將關(guān)注的特性。
Boosting也需要bootstrapping。然而,這里還有另一個區(qū)別。與bagging不同,增加每個數(shù)據(jù)樣本的權(quán)重。這意味著一些樣本將比其他樣本運行得更頻繁。
為什么要對數(shù)據(jù)樣本進行加權(quán)呢?
Figure 4 Boosting
當boost運行每個模型時,它會跟蹤哪些數(shù)據(jù)樣本是最成功的,哪些不是。輸出分類錯誤最多的數(shù)據(jù)集被賦予更重的權(quán)重。這些數(shù)據(jù)被認為更復(fù)雜,需要更多的迭代來正確地訓(xùn)練模型。
在實際分類階段,boosting處理模型的方式也有所不同。在boosting中,模型的錯誤率被跟蹤,因為更好的模型被賦予更好的權(quán)重。
這樣,當“投票”發(fā)生時,就像bagging一樣,結(jié)果更好的模型對最終的輸出有更的強拉動力。
總結(jié)
Boosting 和bagging 都是減少方差的好方法。集成方法通常比單個模型效果好。這就是為什么許多Kaggle贏家使用集成方法的原因。這里沒有討論的是stacking。但是,這需要它自己的post。
然而,他們不會解決所有的問題,他們自己也有自己的問題。有很多不同的原因。bagging 在模型過擬合時對減小方差有很大的作用。然而,在這兩種方法中,Boosting 更有可能是更好的選擇。Boosting 也更有可能導(dǎo)致performance問題。這對于減少不匹配模型中的偏差也很有幫助。
這就是經(jīng)驗和專家的用武之地!可以很容易地跳到第一個有效的模型上。然而,重要的是分析算法及其選擇的所有特性。例如,如果決策樹設(shè)置了特定的葉節(jié)點,那么問題來了:為什么要這么設(shè)置呢?如果不能用其他數(shù)據(jù)點可視化的方法來支持這個觀點,那么可能就不應(yīng)該這樣去實現(xiàn)。
這不僅僅是在各種數(shù)據(jù)集上嘗試AdaBoost或隨機森林。根據(jù)算法得到的結(jié)果,以及有什么支持,驅(qū)動最終的算法。