學習一個魯棒多智體RL駕駛策略來減少交通堵塞

2021年12月3日在arXiv上傳的論文“Learning a Robust Multiagent Driving Policy for Traffic Congestion Reduction“,作者是美國德州奧斯丁分校和GM研發實驗室。

自動和自主駕駛汽車(AV)的出現為系統級目標創造了機會,例如減少交通擁堵。可以在各種模擬場景中學習多智體減少擁塞的駕駛策略。雖然最初POC是集中控制器的小型封閉交通網絡,但最近現實的環境已經證明成功,其中分散控制策略運行在車輛進入和離開的開放道路網絡。然而,這些駕駛策略大多是訓練的相同條件下進行測試的,尚未經過不同交通狀況的魯棒性全面測試,而這是實際場景的關鍵要求。本文提出了一種可學習的多智體駕駛策略,對各種開放網絡交通條件具有魯棒性,包括車輛流量、自動駕駛車在交通中的比例、布局和各種合并道路幾何等。
考慮一個有主路和合并路的道路網絡,如圖所示。有車輛加入和離開網絡,交通由人工駕駛和自動駕駛車輛組成。

假設人類駕駛員是自私的,并最優自己的出行時間,而自動駕駛車輛(AV)則是利他的(altruistic),愿意減少交通擁堵。目標是制定一種駕駛策略,控制每個AV,提高交通吞吐量(流出量)。策略可以通過手工編程或學習編碼。強化學習(RL)已被證明能產生更好的策略,因此是首選方法。
減少擁堵的駕駛政策既可以是集中式,根據全球系統信息同時控制所有車輛,也可以是分散式的,每輛車根據其局部觀測獨立控制。沒有車-車通信的分散式策略最現實,主要依賴于自身感知和駕駛能力,該文就采用這個。為了提高數據和計算效率,降低過擬合的風險,所有AV都學習并執行單一共享的駕駛策略,學習的參數量相對較少。
該多智體交通擁堵緩解問題可以描述為一個離散時間、有限的分散式部分可觀測馬爾可夫決策過程(DecPOMDP)。一個分散式、共享的駕駛策略是,在行動空間的一個概率密度函數,隨機地將每個智體的局部觀測映射至駕駛行為。
狀態轉換隱式地由開源軟件SUMO的模擬環境控制。SUMO模擬人類駕駛模型對人類車輛運動進行建模,參數化并改變駕駛特性,如變道時的攻擊性。SUMO還有強制車輛遵守安全規則和限速的機制。用加州大學伯克利分校的Flow軟件與SUMO進行交互,Flow提供OpenAI Gym環境做為SUMO的包裝,便于與各種強化學習(RL)算法實現交互,可指定進入每條道路的車輛數(流入量,車輛/小時),獲取網絡中車輛的位置和速度,控制每輛車的加速度,并測量流入量、流出量(車輛/小時)和平均速度(米/秒)。
基于與SUMO交互的Flow框架,使用近策略優化(PPO)算法開發分散式駕駛策略。本文根據作者以前論文(“Scalable multiagent driving policies for reducing traffic congestion“,arXiv,2021)采用的AV模型,對每個AV使用觀測和獎勵設計。每個AV的觀測結果如下所示:
- 自車前后的最近車速度和距離,
- 當前車輛的速度,
- 從智體到下一個合并點的距離,
- 下一輛合并車輛的速度及其到合并路口的距離(假設其由車輛的攝像頭/雷達得到,或由一些全球基礎設施計算得到,與所有車輛共享)。
每個觀測值,都通過其最大可能值,規范化成[0,1]的范圍。而獎勵函數定義為:

為了證明性能,將每個經過訓練的策略與人類基準方法進行比較,其中網絡中的所有車輛,都由SUMO提供的人類駕駛模型控制。每個人駕駛的車輛貪婪地最大化其速度,同時保持跟其領車預期的時間間隔。這種明確制定的策略不能很好地處理緊急合流車輛,可能導致潛在交通擁堵。
該文重點學習一種魯棒的AV控制策略,可在一系列現實交通條件下減少交通擁堵,其特點是:
- 主流入率:主干道的流入交通量(車輛/小時);
- 合并流入率:合并路的流入交通量(車輛/小時);
- AV位置:AV在交通流中出現的位置;AV,可以在模擬的人類駕駛車輛中,均勻或隨機地出現;
- AV滲入率:自主控制車輛的百分比;
- 合并道路幾何:兩個合并交叉點之間的距離。
將合并流入速率固定為 200 車輛/小時,并將主流入率范圍設置為 [1600, 2000] 車輛/小時(模擬中造成從低到高的擁塞),AV 滲透率 (AVP) 在 [0, 40]% 以內。AV位置可以是隨機的,也可以是均勻的。為均勻放置,每N輛人類駕駛車輛就會放置一個AV。對隨機放置,AV被隨機放置在模擬的人類駕駛車輛中。合并道路幾何包括距離在 [200, 800] 米之間變化的一次或兩次合并。
雖然現實世界中減少擁堵駕駛策略需要在各種交通條件下有效地運行,但大多數工作,在和策略訓練相同的條件下,進行測試。在現實世界中,對每種條件組合,部署單獨的策略是不切實際的。因此這里主要目標是,要了解學習對現實世界交通條件變化采取魯棒性的單一駕駛策略是否可行,明白如何找到此類策略。
基于RL駕駛策略的性能,取決于訓練時的交通狀況。做改變此類訓練條件的詳細實驗發現,在高流入量、中等AV滲透率和隨機車輛放置條件下,訓練的策略對各種實際感興趣的現實條件具有魯棒性。結果是在比較了30個策略后得出的,每項策略都是在多種交通條件組合下進行訓練的。在3.7 GHz Intel 12核i7處理器上,每個策略的訓練大約需要7小時。每個策略使用相同的100個隨機種子進行100次評估,每次評估大約需要1小時。
將交通條件沿其定義維度離散化為總共30種具有代表性的條件組合:考慮主流入為1650, 1850和2000車輛/小時,車輛在主路上“均勻”或“隨機”布置。在均勻車輛布置中,兩輛RL車輛之間的車輛數量是固定的,而在隨機車輛布置中,所有車輛隨機分布在主路上。將訓練AV滲透率分為五個級別:10%、30%、50%、80%、100%。基于3×2×5離散化,訓練了30個策略,每種條件組合一個策略。
然后,在前面提到的交通條件對每個經過訓練的策略進行評估,得出相應的數據點,描述產生的流出量和平均速度。這些數據點用以下約定進行標記。數據點的標簽由兩部分組成:(i)待評估策略的訓練條件,以及(ii)策略的評估條件。這個策略的訓練條件表示車輛安置、主流入量、合并流入量和AV滲透率,以“-”分隔。例如,“random-2000-200-30”表示在隨機車輛安置下訓練的策略,主流入量為2000輛/小時,合并流入量為200輛/小時,AV滲透率為30%。
在訓練和評估期間,AV可以均勻或隨機地放置在交通中。在現實世界部署經過訓練的策略時,典型的AV布局是隨機的,除非AV運營商特意地均勻分布AV。雖然均勻布局很難部署,但可能更容易訓練,因為生成數據的熵較低。
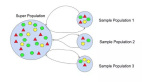
這些策略子集性能如圖所示:


紅色曲線表示在隨機車輛放置情況下訓練策略的評估結果,藍色曲線表示在均勻車輛放置情況下訓練策略的結果。在隨機車輛布置(圖a)和均勻車輛布置(圖b)下,用流出量和平均速度這兩個指標對這些策略策進行評估。在評估隨機放置或均勻放置時,隨機放置訓練的策略優于人類基準方法以及均勻放置訓練的策略。具體而言,圖a中的結果證實了一種直覺,即隨機車輛安置進行評估時,在隨機車輛安置下訓練策略應比在均勻車輛安置下訓練的政策具有更好的性能。然而,與直覺相反,訓練時隨機放置也會在均勻放置測試時產生更穩健的策略。假設這種性能的提高是由于隨機放置RL車輛時收集的數據更加多樣化。
先驗而言,目前尚不清楚AV滲透率對于提高訓練策略魯棒性的理想方法是什么。一方面,由于更多AV收集更多的數據,訓練期間較高的AV滲透率有望通過收集更多訓練數據找到更好的策略。另一方面,一個較小AV滲透率在訓練過程中學習一個控制之下系統的策略,并且當添加更多AV時,期望它與一個過度控制之下系統一起工作。
在一系列AV滲透率下訓練了不同的策略,對其在不同AV滲透率和主流入量下的表現進行全面比較。評估結果的代表如圖所示:
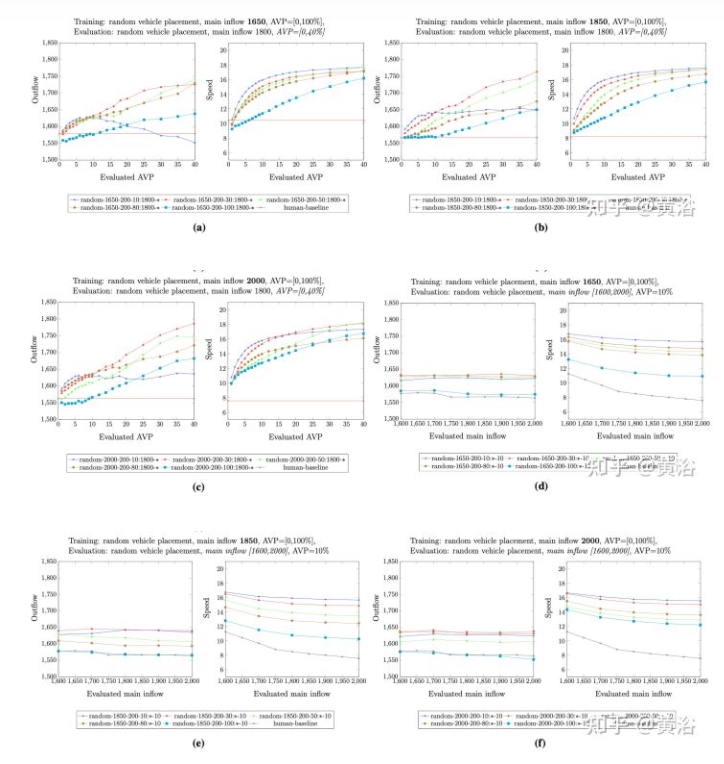
圖a–圖c顯示,當確定主流入量時,在AV滲透率 30%(紅色曲線)下訓練策略在不同AV滲透率下評估,其流出量和平均速度都具有競爭力,在各種評估AV滲透率中都具有最佳性能。如果修正AV滲透率,但在評估期間改變主流入量,那么圖d–圖f表明,在AV滲透率30%下訓練策略,與不同AV滲透率下訓練策略相比,仍然具有顯著優勢。
可以假設,這些中等AV滲透率在訓練期間表現最好,因為(i)策略經過良好訓練,有足夠的AV收集訓練數據;(ii)有一定數量的人類駕駛車輛,所學的策略,對減少這些人類駕駛車輛造成的交通擠塞,是有用的。
對于所選擇的車輛布置和AV滲透率,剩下的問題是,是否能夠確定訓練期間使用的最佳主流入量。實驗發現較高的主流入量帶來更魯棒的策略。
根據AV滲透率30%和不同主流入量,對經過訓練策略進行全面比較。評估結果的代表如圖所示:
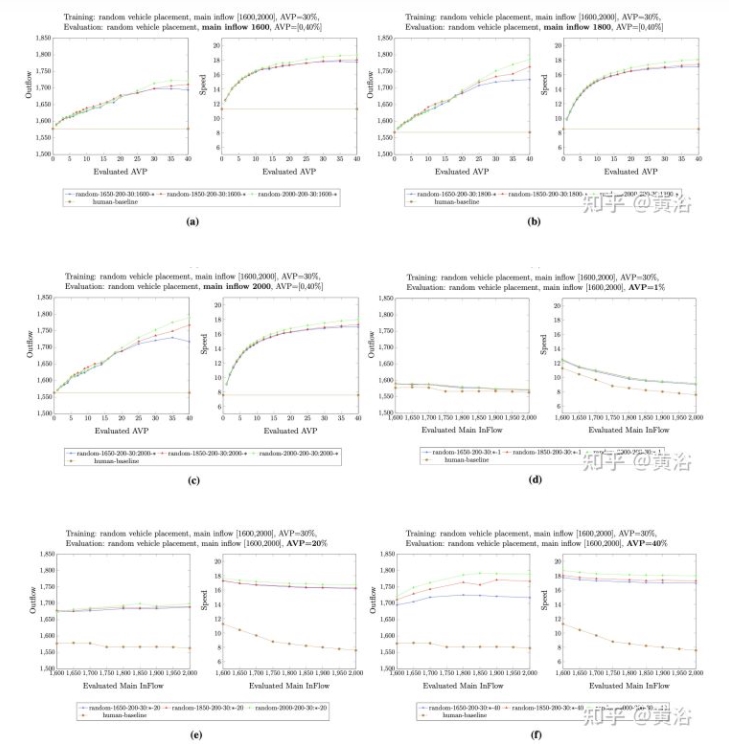
在評估期間確定主流入量和不同的AV滲透率時,圖a–圖c顯示,在主流入量2000輛/小時(綠色曲線)下訓練的策略,在流出量和平均速度方面,都比在AV滲透率 30%和不同主流入量下訓練的其他策略,有更好的表現。類似地,如果在評估期間固定AV滲透率但改變主流入量,則在主流入量2000輛/小時下訓練的策略在所有用AV滲透率 30%訓練的策略也具有最佳性能。
可以假設,在最高流入量下訓練策略優于其他策略,因為較高的主流入量在訓練時產生更多不同的車輛密度。具體而言,模擬動力學可導致高流入量,包括密集車輛放置和稀疏車輛放置,而較低的主流入量往往導致稀疏車輛分布。
進一步分析策略對其他現實條件的魯棒性。
自動駕駛車輛充當駕駛策略的控制器,用來影響交通流。如果道路上AV太少,該策略可能無法影響交通流。隨著AV數量的增加,影響流量的能力增加。一個實際問題是,為了實現統計上顯著的擁塞減少效果,需要多少AV。
為進行敏感性分析,首先采用先前的最佳策略(random-2000-200-30),然后將其性能與不同評估AV穿透率下的人類基準方法進行比較。在相同流入量和AV滲透率情況下評估,收集選定策略和人類基準方法的流出量。結果如圖所示:
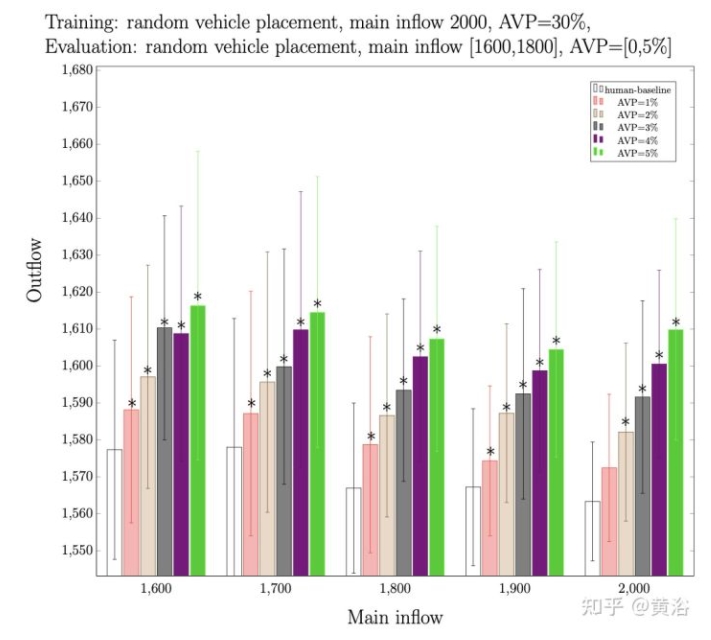
隨著在評估期間增加AVs數量,流出量性能也會增加。與純人類基準方法相比,為了確定顯著改善所需的最小AV量,進行獨立樣本t-test,收集p-value,其確定所選策略流出量是否比純人類基準方法統計上顯著改善。用p- value 0.001作為顯著性截斷,當部署時AV滲透率量大于或等于2%時,所選策略的性能明顯優于人類基準方法。
發現最魯棒的策略,即random-2000-200-30,是在單車道、單合并場景中學習的。選更復雜道路結構,兩條不同距離的合并路,測試該策略對此的魯棒性。考慮圖中兩條合并道路的交通網絡。

實驗中,第一個合并匝道位于模擬主路起點500米處,第二個合并匝道位于第一個合并匝道之后200、400、600或800米處,主路總長1500米,合并路總長250米。測試random-2000-200-30策略,采用隨機AV放置,主流入量為1800輛/小時,合并流入量為200輛/小時,采取一系列AV滲透率和兩條合并路之間的上述間距。
結果如圖所示:

其中藍色曲線顯示待測試策略的性能,紅色曲線顯示人類基準方法的性能。random-2000-200-30策略比人類基準方法更好,即使合并閘道距離僅200米。當增加這兩個入口匝道之間距離時,性能會提高。當距離較小時,第二個合并匝道處的交通擁堵會干擾第一個合并匝道處的交通流,但是靠近第一個匝道的RL車輛無法觀測這些。隨著增加這兩個合并匝道之間的距離,這種干擾會減少,靠近這兩個合并匝道的交通流AV可以越來越獨立地處理。因此,當這兩個合并匝道距離變得更遠時,AV的決策過程類似于單一合并道路的決策過程—只需要考慮下一個進入路口的交通流。相應地,所選擇的策略有效地減少雙匝道場景的交通擁堵;隨著這兩個閘道之間距離的增加,其性能也會提高。
本文提出了一種學習減少擁堵的駕駛策略,在道路合并場景中,在實際感興趣的交通條件下魯棒地執行。具體而言,該策略降低了AV滲透率0%-40%的擁堵,減少了1600輛/小時(輕度擁堵)至2000輛/小時(重度擁堵)的交通流量,還有交通中隨機AV設置以及兩條不同距離合并的道路。發現該策略的過程包括(i)通過掃描實際感興趣的交通條件空間來生成測試基準,(ii)在隨機AV放置和掃描車輛流入空間和AV滲透率產生的條件組合上訓練30個駕駛策略,以及(iii)選擇性能最高的策略。
雖然最近人們對開發通用的魯棒RL訓練方法越來越感興趣,但是實驗發現,隨機化AV設置,以及交通條件空間上搜索有效的訓練設置,可以有效地實現魯棒性。