













吐血整理!絕不能錯過的24個Python庫
Python有以下三個特點:
- 易用性和靈活性
- 全行業高接受度:Python無疑是業界最流行的數據科學語言
- 用于數據科學的Python庫的數量優勢
事實上,由于Python庫種類很多,要跟上其發展速度非常困難。因此,本文介紹了24種涵蓋端到端數據科學生命周期的Python庫。
文中提及了用于數據清理、數據操作、可視化、構建模型甚至模型部署(以及其他用途)的庫。這是一個相當全面的列表,有助于你使用Python開啟數據科學之旅。

用于數據收集的Python庫
你是否曾遇到過這樣的情況:缺少解決問題的數據?這是數據科學中一個永恒的問題。這也是為什么學習提取和收集數據對數據科學家來說是一項非常重要的技能。數據提取和收集開辟了前所未有的道路。
以下是三個用于提取和收集數據的Python庫:
1. Beautiful Soup
傳送門:https://www.crummy.com/software/BeautifulSoup/bs4/doc/
收集數據的最佳方式之一就是抓取網站(當然是以合乎道德和法律的手段!)徒手做這件事需要耗費大量的勞動和時間。Beautiful Soup無疑是一大救星。
Beautiful Soup是一個HTML和XML解析器,可為被解析的頁面創建解析樹,從而用于從web頁面中提取數據。從網頁中提取數據的過程稱為網頁抓取。
使用以下代碼可安裝BeautifulSoup:
- pip install beautifulsoup4
下面是一個可實現從HTML中提取所有錨標記的Beautiful Soup簡單代碼:
- #!/usr/bin/python3
- # Anchor extraction from html document
- from bs4 import BeautifulSoup
- from urllib.request import urlopen
- with urlopen('LINK') as response:
- soup = BeautifulSoup(response, 'html.parser')
- for anchor in soup.find_all('a'):
- print(anchor.get('href', '/'))
建議閱讀下面的文章,學習如何在Python中使用Beautiful Soup:
《新手指南:在Python中使用BeautifulSoup進行網頁抓取》傳送門:
https://www.analyticsvidhya.com/blog/2015/10/beginner-guide-web-scraping-beautiful-soup-python/
2. Scrapy
傳送門:https://docs.scrapy.org/en/latest/intro/tutorial.html
Scrapy是另一個可有效用于網頁抓取的Python庫。它是一個開源的協作框架,用于從網站中提取所需數據。使用起來快捷簡單。
下面是用于安裝Scrapy的代碼:
- pip install scrapy

Scrapy是一個用于大規模網頁抓取的框架。可提供所有需要的工具有效地從網站中抓取數據,且依需要處理數據,并以使用者偏好的結構和格式存儲數據。
下面是一個實現Scrapy的簡單代碼:
- import scrapy
- class Spider(scrapy.Spider):
- name = 'NAME'
- start_urls = ['LINK']
- def parse(self, response):
- for title in response.css('.post-header>h2'):
- yield {'title': title.css('a ::text').get()}
- for next_page in response.css('a.next-posts-link'):
- yield response.follow(next_page, self.parse
下面是一個學習Scrapy并在Python中實現Scrapy的絕佳教程:
《使用Scrapy在Python中進行網頁抓取(含多個示例)》傳送門:
https://www.analyticsvidhya.com/blog/2017/07/web-scraping-in-python-using-scrapy/
3. Selenium
傳送門:https://www.seleniumhq.org/
Selenium是一個倍受歡迎的自動化瀏覽器工具。在業界常用于測試,但對于網頁抓取也非常方便。Selenium在IT領域非常流行。

編寫Python腳本來自動化使用Selenium的web瀏覽器是很容易的。它允許免費高效地提取數據,并將其存儲在首選格式中以備后用。
關于使用Python和Selenium抓取YouTube視頻數據的文章:
《數據科學項目:使用Python和Selenium抓取YouTube數據對視頻進行分類》傳送門:
https://www.analyticsvidhya.com/blog/2019/05/scraping-classifying-youtube-video-data-python-selenium/
用于數據清理和數據操作的Python庫
收集了數據之后,接下來要清理可能面臨的任何混亂數據,并學習如何操作數據,方便數據為建模做好準備。
下面是四個可用于數據清理和數據操作的Python庫。請記住,文中僅指明在現實世界中處理結構化(數值)數據和文本數據(非結構化)——而該庫列表涵蓋了所有內容。
4. Pandas
傳送門:https://pandas.pydata.org/pandas-docs/stable/
在數據操作和數據分析方面,Pandas絕無敵手。Pandas一度是最流行的Python庫。Pandas是用Python語言編寫的,主要用于數據操作和數據分析。
這個名稱來源于術語“面板數據”,“面板數據”是一個計量經濟學術語,指的是包含同一個人在多個時間段內的觀察結果的數據集。
Pandas在Python or Anaconda中已完成預安裝,但以防需要,安裝代碼如下:
- pip install pandas
Pandas有以下特點:
- 數據集連接和合并
- 刪除和插入數據結構列
- 數據過濾
- 重塑數據集
- 使用DataFrame對象來操作數據等
下面是一篇文章以及一份很棒的Cheatsheet,有助于使Pandas技能達標:
- 《Python中用于數據操作的12種有用的Pandas技術》傳送門:https://www.analyticsvidhya.com/blog/2016/01/12-pandas-techniques-python-data-manipulation/
- 《CheatSheet:在Python中使用Pandas進行數據探索》傳送門:https://www.analyticsvidhya.com/blog/2015/07/11-steps-perform-data-analysis-pandas-python/
5. PyOD
傳送門:https://pyod.readthedocs.io/en/latest/
難以發現異常值?這絕非個例。別擔心,PyOD庫就在這里。
PyOD是一個全面的、可伸縮的Python工具包,用于檢測外圍對象。離群值檢測基本上是識別與大多數數據顯著不同的稀有項或觀測值。
以下代碼可用于下載pyOD:
- pip install pyod
PyOD是如何工作的?如何實現PyOD?下面一則指南將回答所有關于PyOD的問題:
《學習在Python中使用PyOD庫檢測異常值的絕佳教程》傳送門:
https://www.analyticsvidhya.com/blog/2019/02/outlier-detection-python-pyod/
6. NumPy
傳送門:https://www.numpy.org/
與Pandas一樣,NumPy也是一個非常受歡迎的Python庫。NumPy引入了支持大型多維數組和矩陣的函數,同時還引入了高級數學函數來處理這些數組和矩陣。
NumPy是一個開源庫,有多方貢獻者。在 Anaconda和Python中已預安裝Numpy,但以防需要,下面是安裝代碼:
- $ pip install numpy

下面是使用NumPy可執行的一些基本功能:
創建數組:
- import numpy as np
- x = np.array([1, 2, 3])
- print(x)
- y = np.arange(10)
- print(y)
- output - [1 2 3]
- [0 1 2 3 4 5 6 7 8 9]
基本運算:
- a = np.array([1, 2, 3, 6])
- b = np.linspace(0, 2, 4)
- c = a - b
- print(c)
- print(a**2)
- output - [1. 1.33333333 1.66666667 4. ]
- [ 1 4 9 36]
以及更多其他功能!
7. SpaCy
傳送門:https://spacy.io/

目前已經討論了如何清理數據和處理數值數據。但是如果正在處理文本數據呢?到目前為止,現有的庫都無法解決該問題。
Spacy是一個非常有用且靈活的自然語言處理( NLP )庫和框架,用于清理創建模型的文本文檔。與類似用途的其他庫相比,SpaCy速度更快。
在Linux中安裝Spacy:
- pip install -U spacy
- python -m spacy download en
其他操作系統上安裝Spacy,請點擊:https://spacy.io/usage
以下是學習spaCy的課程:
《簡化自然語言處理——使用SpaCy(在Python中)》傳送門:
https://www.analyticsvidhya.com/blog/2017/04/natural-language-processing-made-easy-using-spacy-%e2%80%8bin-python/
用于數據可視化的Python庫
下一步是什么呢?數據可視化!此處假設已得到驗證,并且發掘了隱藏的觀點和模式。
下面是三個用于數據可視化的絕佳Python庫。
8. Matplotlib
傳送門:https://matplotlib.org/
Matplotlib是Python中最流行的數據可視化庫。允許生成和構建各種各樣的圖。Matplotlib是筆者的首選庫,可與Seaborn一起用于進行數據可視化研究。
以下是安裝Matplotli的代碼:
- $ pip install matplotlib

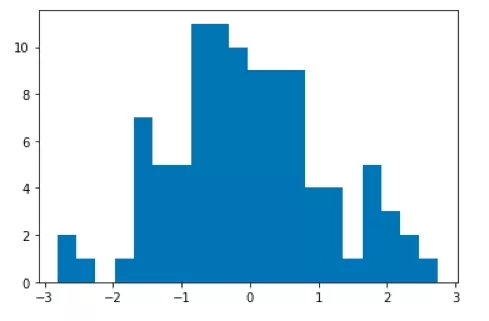
下面是使用Matplotlib構建的不同類型圖示的部分例子:
柱狀圖:
- %matplotlib inline
- import matplotlib.pyplot as plt
- from numpy.random import normal
- x = normal(size=100)
- plt.hist(x, bins=20)
- plt.show()
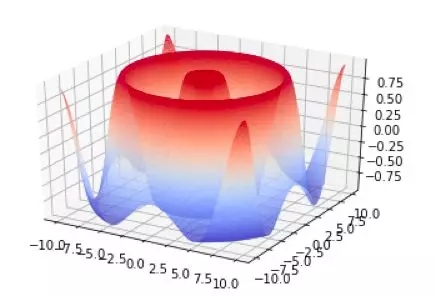
3D 圖表:
- from matplotlib import cm
- from mpl_toolkits.mplot3d import Axes3D
- import matplotlib.pyplot as plt
- import numpy as np
- fig = plt.figure()
- ax = fig.gca(projection='3d')
- X = np.arange(-10, 10, 0.1)
- Y = np.arange(-10, 10, 0.1)
- X, Y = np.meshgrid(X, Y)
- R = np.sqrt(X**2 + Y**2)
- Z = np.sin(R)
- surf = ax.plot_surface(X, Y, Z, rstride=1,cstride=1, cmcmap=cm.coolwarm)
- plt.show()
目前已經介紹了Pandas、NumPy和Matplotlib,那么請查看下面的教程,該教程結合了以上三個庫進行講解:
《使用NumPy、Matplotlib和Pandas在Python中進行數據探索的終極指南》傳送門:
https://www.analyticsvidhya.com/blog/2015/04/comprehensive-guide-data-exploration-sas-using-python-numpy-scipy-matplotlib-pandas/
9. Seaborn
傳送門:https://seaborn.pydata.org/
Seaborn是另一個基于matplotlib的繪圖庫。它是一個為繪制有吸引力的圖像而提供高級接口的python庫。matplotlib能實現功能,Seaborn只是以另一種更吸引人的視覺方式來實現。
Seaborn 的一些特點:
- 作為一個面向數據集的API,可用于查驗多個變量之間的關系
- 便于查看復雜數據集的整體結構
- 用于選擇顯示數據中模式的調色板的工具
下面一行代碼可用于安裝Seaborn:
- pip install seaborn

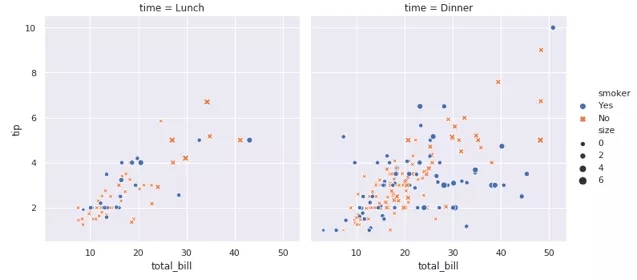
瀏覽下面這些很酷的圖表,看看seaborn能做些什么:
- import seaborn as sns
- sns.set()
- tips =sns.load_dataset("tips")
- sns.relplot(x="total_bill",y="tip", col="time",
- hue="smoker",style="smoker", size="size",
- data=tips);
下面是另外一個例子:
- import seaborn as sns
- sns.catplot(x="day",y="total_bill", hue="smoker",
- kind="violin",split=True, data=tips);
10. Bokeh
傳送門:https://bokeh.pydata.org/en/latest/
Bokeh是一個面向現代網頁瀏覽器的交互式可視化庫,為大量數據集提供優美的通用圖形結構。
Bokeh可用于創建交互式繪圖、儀表板和數據應用程序。
安裝:
- pip install bokeh

了解更多關于Bokeh的知識及其實際應用:
《使用Bokeh的交互式數據可視化(在Python中)》傳送門:
https://www.analyticsvidhya.com/blog/2015/08/interactive-data-visualization-library-python-bokeh/
用于建模的Python庫
現在到了本文最令人期待的部分——建模!這也是大多數人一開始接觸數據科學的原因。
接下來通過這三個Python庫來探索建模。
11. Scikit-learn
傳送門:https://scikit-learn.org/stable/
就像用于數據操作的Pandas和用于可視化的matplotlib一樣,scikit-learn是Python構建模型中的佼佼者。沒有什么能與之媲美。
事實上,scikit-learn建立在NumPy,SciPy和matplotlib之上。它是開放源碼的,每個人都可以訪問,并且可以在各種環境中重用。
Scikit-learn支持在機器學習中執行的不同操作,如分類、回歸、聚類和模型選擇等。命名它——那么scikit-learn會有一個模塊。
建議瀏覽以下鏈接以了解有關scikit-learn的更多信息:
《Python中的Scikit-learn——筆者去年學到的最重要的機器學習工具!》傳送門:
https://www.analyticsvidhya.com/blog/2015/01/scikit-learn-python-machine-learning-tool/
12. TensorFlow
傳送門:https://www.tensorflow.org/
TensorFlow由谷歌開發,是一個流行的深度學習庫,可幫助構建、培訓不同模型。是一個開放源碼的端到端平臺。TensorFlow提供簡單的模型構建,強大的機器學習生產,以及強大的實驗工具和庫。
TensorFlow提供多個抽象級別,可根據需要進行選擇。TensorFlow通過使用高級Keras API來構建和訓練模型,這使TensorFlow入門和機器學習變得容易。
安裝傳送門:https://www.tensorflow.org/install
使用TensorFlow從閱讀這些文章開始:
- 《TensorFlow 101:理解張量和圖像以便開始深入學習》傳送門:https://www.analyticsvidhya.com/blog/2017/03/tensorflow-understanding-tensors-and-graphs/
- 《開始使用Keras和TensorFlow在R中進行深度學習》傳送門:https://www.analyticsvidhya.com/blog/2017/06/getting-started-with-deep-learning-using-keras-in-r/
13. PyTorch
傳送門:https://pytorch.org/
什么是PyTorch?其實,這是一個基于Python的科學計算包,其功能如下:
- NumPy的替代品,可使用GPU的強大功能
- 深度學習研究型平臺,擁有最大靈活性和最快速度
安裝指南傳送門:https://pytorch.org/get-started/locally/
PyTorch提供以下功能:
- 混合前端
- 工具和庫:由研發人員組成的活躍社區已經建立了一個豐富的工具和庫的生態系統,用于擴展PyTorch并支持計算機視覺和強化學習等領域的開發
- 云支持:PyTorch支持在主要的云平臺上運行,通過預構建的映像、對GPU的大規模訓練、以及在生產規模環境中運行模型的能力等,可提供無摩擦的開發和輕松拓展
以下是兩篇有關PyTorch的十分詳細且易于理解的文章:
- 《PyTorch簡介——一個簡單但功能強大的深度學習庫》傳送門:https://www.analyticsvidhya.com/blog/2018/02/pytorch-tutorial/
- 《開始使用PyTorch——學習如何建立快速和準確的神經網絡(以4個案例研究為例)》傳送門:https://www.analyticsvidhya.com/blog/2019/01/guide-pytorch-neural-networks-case-studies/
用于數據解釋性的Python庫
你真的了解模型如何工作嗎?能解釋模型為什么能夠得出結果嗎?這些是每個數據科學家都能夠回答的問題。構建黑盒模型在業界毫無用處。
所以,上文中已經提到的兩個Python庫可以幫助解釋模型的性能。
14. LIME
傳送門:https://github.com/marcotcr/lime
LIME是一種算法(庫),可以解釋任何分類器或回歸量的預測。LIME是如何做到的呢?通過可解釋的模型在局部不斷接近預測值,這個模型解釋器可用于生成任何分類算法的解釋。

安裝LIME很簡單:
- pip install lime
下文將從總體上幫助開發LIME背后的直覺和模型可解釋性:
《在機器學習模型中建立信任(在Python中使用LIME)》傳送門:
https://www.analyticsvidhya.com/blog/2017/06/building-trust-in-machine-learning-models/
15. H2O
傳送門:https://github.com/h2oai/mli-resources
相信很多人都聽說過H2O.ai,自動化機器學習的市場領導者。但是你知道其在Python中也有一個模型可解釋性庫嗎?
H2O的無人駕駛AI,提供簡單的數據可視化技術,用于表示高度特征交互和非線性模型行為,通過可視化提供機器學習可解釋性(MLI),說明建模結果和模型中特征的影響。

通過下文,閱讀有關H2O的無人駕駛AI執行MLI的更多信息。
《機器學習可解釋性》傳送門:
https://www.h2o.ai/wp-content/uploads/2018/01/Machine-Learning-Interpretability-MLI_datasheet_v4-1.pdf
用于音頻處理的Python庫
音頻處理或音頻分析是指從音頻信號中提取信息和含義以進行分析、分類或任何其他任務。這正在成為深度學習中的一種流行功能,所以要留意這一點。
16. LibROSA
傳送門:https://librosa.github.io/librosa/
LibROSA是一個用于音樂和音頻分析的Python庫。它提供了創建音樂信息檢索系統所需的構建塊。
安裝指南傳送門:https://librosa.github.io/librosa/install.html
這是一篇關于音頻處理及其工作原理的深度文章:
《利用深度學習開始音頻數據分析(含案例研究)》傳送門:
https://www.analyticsvidhya.com/blog/2017/08/audio-voice-processing-deep-learning/
17. Madmom
傳送門:https://github.com/CPJKU/madmom
Madmom是一個用于音頻數據分析的很棒的Python庫。它是一個用Python編寫的音頻信號處理庫,主要用于音樂信息檢索(MIR)任務。
以下是安裝Madmom的必備條件:
- NumPy
- SciPy
- Cython
- Mido
以下軟件包用于測試安裝:
- PyTest
- Fyaudio
- PyFftw
安裝Madmom的代碼:
- pip install madmom
下文可用以了解Madmom如何用于音樂信息檢索:
《學習音樂信息檢索的音頻節拍追蹤(使用Python代碼)》傳送門:
https://www.analyticsvidhya.com/blog/2018/02/audio-beat-tracking-for-music-information-retrieval/
18. pyAudioAnalysis
傳送門:https://github.com/tyiannak/pyAudioAnalysis
pyAudioAnalysis是一個用于音頻特征提取、分類和分段的Python庫,涵蓋廣泛的音頻分析任務,例如:
- 對未知聲音進行分類
- 檢測音頻故障并排除長時間錄音中的靜音時段
- 進行監督和非監督的分割
- 提取音頻縮略圖等等
可以使用以下代碼進行安裝:
- pip install pyAudioAnalysis

用于圖像處理的Python庫
如果想要在數據科學行業有一番成就,那么必須學習如何使用圖像數據。隨著系統能夠收集越來越多的數據(主要得益于計算資源的進步),圖像處理越來越無處不在。
因此,請確保熟悉以下三個Python庫中的至少一個。
19. OpenCV-Python
傳送門:
https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_setup/py_intro/py_intro.html
談到圖像處理,OpenCV首先浮現在腦海中。OpenCV-Python是用于圖像處理的Python API,結合了OpenCV C ++ API和Python語言的最佳特性。主要用于解決計算機視覺問題。
OpenCV-Python使用了上文提到的NumPy。所有OpenCV陣列結構都與NumPy數組相互轉換。這也使得與使用Numpy的其他庫(如SciPy和Matplotlib)集成變得更加容易。

在系統中安裝OpenCV-Python:
- pip3 install opencv-python
以下是兩個關于如何在Python中使用OpenCV的流行教程:
- 《基于深度學習的視頻人臉檢測模型建立(Python實現)》傳送門:https://www.analyticsvidhya.com/blog/2018/12/introduction-face-detection-video-deep-learning-python/
- 《16個OpenCV函數啟動計算機視覺之旅(使用Python代碼)》傳送門:https://www.analyticsvidhya.com/blog/2019/03/opencv-functions-computer-vision-python/
20. Scikit-image
傳送門:https://scikit-image.org/
Scikit-image是另一個用于圖像處理的python庫,是用于執行多個不同圖像處理任務的算法集合。可用于圖像分割、幾何變換、色彩空間操作、分析、過濾,形態學、特征檢測等等。
在安裝scikit-image前,請先安裝以下軟件包:
- Python(> = 3.5)
- NumPy(> = 1.11.0)
- SciPy(> = 0.17.0)
- joblib(> = 0.11)
這就是在機器上安裝scikit-image的方法:
- pip install -U scikit-learn

21. Pillow
傳送門:https://pillow.readthedocs.io/en/stable/
Pillow是PIL(Python Imaging Library)的新版本。它是從PIL派生出來的,在一些Linux發行版(如Ubuntu)中被用作原始PIL的替代。
Pillow提供了幾種執行圖像處理的標準程序:
- 逐像素操作
- 掩模和透明處理
- 圖像過濾,例如模糊,輪廓,平滑或邊緣監測
- 圖像增強,例如銳化,調整亮度、對比度或顏色
- 在圖像上添加文字等等
安裝Pillow:
- pip install Pillow

查看以下關于在計算機視覺中使用Pillow的AI漫畫:
《AI漫畫:Z.A.I.N —— 第二期:使用計算機視覺進行面部識別》傳送門:
https://www.analyticsvidhya.com/blog/2019/06/ai-comic-zain-issue-2-facial-recognition-computer-vision/
用于數據庫的Python庫
學習如何從數據庫存儲、訪問和檢索數據是數據科學家必備的技能。但是如何在不首先檢索數據的情況下做到建模呢?
接下來介紹兩個與SQL相關的Python庫。
22. psycopg
傳送門:http://initd.org/psycopg/

Psycopg是Python編程語言中最流行的PostgreSQL(高級開源代碼關系數據庫)適配器。Psycopg的核心是完全實現Python DB API 2.0規范。
目前的psycopg2實現支持:
- Python版本2.7
- Python 3版本(3.4到3.7)
- PostgreSQL服務器版本(7.4到11)
- PostgreSQL客戶端庫版本(9.1以上)
以下是安裝psycopg2的方法:
- pip install psycopg2
23. SQLAlchemy
傳送門:https://www.sqlalchemy.org/
SQL是最流行的數據庫語言。SQLAlchemy是pythonSQL工具包和對象關系映射器,它為應用程序開發人員提供了SQL的全部功能,且極具靈活性。

SQL旨在實現高效、高性能的數據庫訪問。SQLAlchemy將數據庫視為關系代數引擎,而不僅僅是表的集合。
要安裝SQLAlchemy,可以使用以下代碼行:
- pip install SQLAlchemy
用于部署的Python庫
你知道哪些模型部署?部署模型意味著將最終模型放入最終應用程序(技術上稱為生產環境)。
24. Flask
傳送門:http://flask.pocoo.org/docs/1.0/
Flask是一個用Python編寫的Web框架,廣泛用于部署數據科學模型。Flask由兩個部分組成:
- Werkzeug:Python編程語言的實用程序庫
- Jinja:Python的模板引擎

查看下面的示例以打印“Hello world”:
- from flask import Flask
- app = Flask(__name__)
- @app.route("/")
- def hello():
- return "HelloWorld!"
- if __name__ == "__main__":
- app.run()
以下文章是學習Flask的良好開端:
《在生產中將機器學習模型部署為API的教程(使用Flask)》傳送門:
https://www.analyticsvidhya.com/blog/2017/09/machine-learning-models-as-apis-using-flask/



















