神話還是現實?Docker 和 Kubernetes 架構
在 Docker 和 Kubernetes 時代,軟件開發的世界發生了怎樣的變化?有可能使用這些技術一勞永逸地構建一個放之四海而皆準的架構嗎?當所有東西都“打包”在容器中時,有可能統一開發和集成的過程嗎?這些決策有什么要求?它們會帶來什么限制?它們會讓開發人員的生活變得更輕松,還是會增加不必要的復雜性?
是時候討論和闡明這些(以及其它一些)問題了!(在本文和原創插圖中)
本文將帶你踏上從現實到開發過程到架構再回到現實的旅程,在沿途的每一站回答最重要的問題。我們將嘗試確定一些應該成為體系架構一部分的組件和原則,并在不過多深入實現細節的情況下展示一些示例。
這篇文章的結論可能會讓你不高興或高興。這完全取決于你的個人經驗,你對這個分為三章的故事的看法,甚至可能取決于你閱讀時的心情。請在文末發表評論或提出問題,讓我知道你的想法!
一、從現實到開發流程
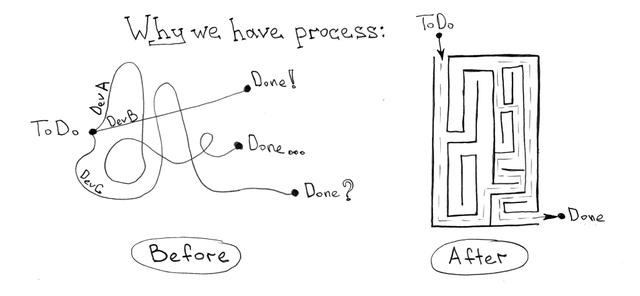
在很大程度上,我所見過或有幸參與建立的所有開發過程都服務于一個簡單的目標 —— 降低將一個想法變成現實、并交付生產的時間,同時保持一定程度的代碼質量。
這個想法是好是壞并不重要。壞主意來來去去,你可能只是嘗試一下,然后拒絕它們,讓它們自生自滅。值得一提的是,從一個壞主意中 回退(rolling back)的責任落在將你的開發流程自動化的機器人肩上。
持續集成和交付(CI/CD)似乎是軟件開發世界中的一根救命稻草。畢竟,還有什么比這更簡單的呢?你有想法,你有代碼,所以去做吧!如果不是存在一個小問題的話,這將會是完美無缺的 —— 如果與貴公司特有的技術和業務流程相分離,集成和交付流程將很難正規化。
然而,盡管這個任務看起來很復雜,生活還是在不斷引入優秀的想法,讓我們(當然是我自己)更接近于建立一個幾乎在任何場合都有用的完美機制。對我來說,實現這種機制的最近一步是 Docker 和 Kubernetes,它們的抽象層次和意識形態方法讓我認為現有問題中的 80% 都可以通過幾乎相同的方法來解決。
剩下的 20% 我們也無法忽視。但是這正是你可以把你內在的創造性天才集中于其上的有趣的工作,而不是用于處理重復性的日常任務。專注于 “架構框架”(architectural framework)可以讓你忘記那 80% 已經解決掉的問題。
所有這些意味著什么,Docker 是如何解決開發流程中的問題的?讓我們來看一個簡單的流程,這對于大多數工作環境來說也是足夠的:
通過適當的方法,你可以自動化和統一以下序列中的所有內容,并在未來幾個月內忘掉它。
建立開發環境
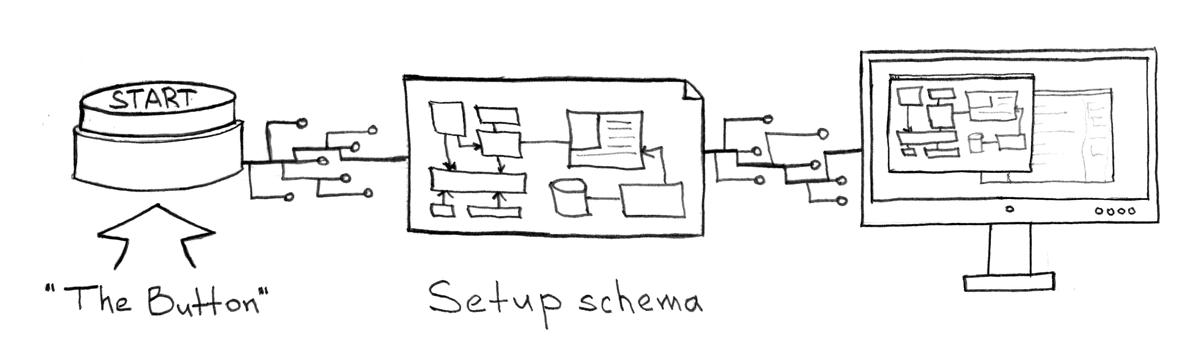
一個項目應該包含一個 docker-compose.yml 文件,這樣你就不用考慮在本地機器上運行應用程序/服務需要做什么和怎么做了。一個簡單的 docker-compose up 命令就能啟動你的應用程序及其所有依賴項、用預制數據填充數據庫、上傳本地代碼到容器內、啟用代碼跟蹤以便動態編譯,并最終在預期的端口開始接收和響應請求。即使是在設置新服務時,你也不必擔心如何啟動、向哪里提交代碼更改或使用哪些框架。所有這些都應該在標準說明中預先描述,并由不同配置的服務模板決定: frontend、backend 和 worker。
自動化測試
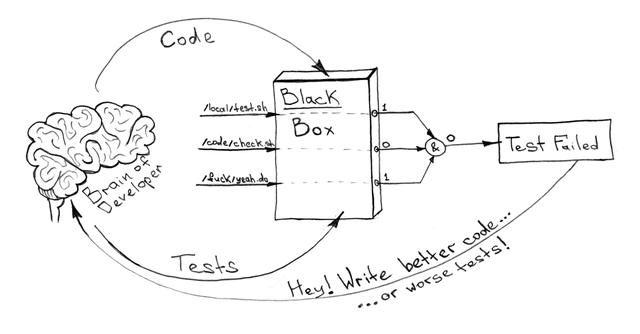
關于“黑盒”你只需要知道,所有該有的東西都已經打包到里面了。是或否,1 或 0。更多關于我為什么將容器稱為黑盒的信息,將在本文的后面介紹。有了數量有限的可以在容器內執行的命令,以及描述其所有依賴關系的 docker-compose.yml,你就可以輕松地自動化和統一測試工作,而無需過多關注實現細節。
例如, 像這樣 !
在這里,測試不僅意味著單元測試,還意味著功能測試、集成測試、檢查代碼風格和重復代碼、檢查過時的依賴關系、可能使用違反許可證的軟件包以及許多其他事情。關鍵是所有這些都應該封裝在你的 Docker 鏡像中。
系統交付

你想在何時何地安裝項目并不重要。結果,就像安裝過程一樣,應該總是相同的。至于你將安裝整個生態系統中的哪個部分,或者從哪個 git 代碼庫中獲取代碼,也沒有任何區別。這里最重要的組成部分是 冪等性(idempotence)。唯一應該指定的是控制安裝的變量。
以下是在我看來解決這個問題非常有效的算法:
從你所有的 Dockerfile 中收集鏡像(例如,像 這樣 )
使用一個元項目,通過 Kube API 接口將這些鏡像傳遞給 Kubernetes。啟動交付過程通常需要如下幾個輸入參數:
- Kube API 的 訪問入口(endpoint)
- 一個 Secret 對象,因不同的上下文而異(local/showroom/staging/production)
- 要顯示的系統的名稱和這些系統的 Docker 鏡像的標簽(在前面的步驟中獲得)
作為一個包含所有系統和服務的元項目的例子(換句話說,一個描述生態系統是如何安排的以及更新是如何傳遞給它的項目),我更喜歡使用 Ansible 劇本與 這個模塊 同 Kube API 進行集成。然而,復雜的 自動機(automators)可以引用其他選項,我將在后面詳述我自己的選擇。但是,你必須考慮一種集中/統一的架構管理方法。擁有一個這樣的方法可以讓你方便和統一地管理所有服務/系統,中和即將到來的執行類似功能的技術和系統叢林可能帶給你的任何復雜性。
通常,在以下情況下需要安裝環境:
- ShowRoom — 測試環境, 對系統進行了一些手動檢查或調試
- Staging — 準生產環境,和外部系統的集成 (通常位于 DMZ,而不是 ShowRoom)
- Production — 生產環境,供最終用戶使用的實際環境
集成和交付的連續性
如果你有一個統一的測試方法對 Docker 鏡像(或“黑盒”)進行測試,你就可以假設這樣的測試結果將允許你無縫地(并且問心無愧地)將 特性分支(feature-branch)集成到 git 存儲庫的 上游(upstream)或 主分支(master)中。
或許,這里唯一的障礙是集成和交付的順序。當沒有發布時,你如何在一個擁有一組并行 功能分支(feature-branches)的系統上防止“競爭條件”的發生?
因此,只有在沒有競爭的情況下,這個過程才應該開始,否則“競爭條件”會一直縈繞在你的腦海中:
- 嘗試將 功能分支(feature-branch)更新到 上游分支(upstream)(git rebase/git merge)
- 使用 Dockerfile 構建鏡像
- 測試所有構建好的鏡像
- 啟動并等待,直到使用第 2 步中構建的鏡像的系統成功完成部署
- 如果前一步失敗,將生態系統回滾到之前的狀態
- 將 功能分支(feature-branch)合并進 上游分支(upstream),并將其提交到代碼庫
任何步驟中發生的任何失敗都應該終止交付過程,并將任務返回給開發人員來修復錯誤,不管是測試失敗還是代碼合并沖突。
你可以使用此流程來在多個代碼庫上工作。只需一次對所有代碼庫執行每個步驟(在 A 庫和 B 庫上執行步驟 1,在 A 庫和 B 庫上執行步驟 2,如此類推),而不是在每個單獨的代碼庫上重復執行整個過程(在 A 庫上執行步驟 1-6,在 B 庫上執行步驟 1-6,如此類推)。
此外,Kubernetes 還允許你進行部分更新,以便執行各種 A/B 測試和風險分析。Kubernetes 在內部通過分離服務(訪問點)和應用程序來實現這一點。你總是可以按期望的比例平衡組件的新版本和舊版本,以便于問題分析并為潛在的回滾提供可能。
回滾系統
架構框架的強制性要求之一是回滾任何部署過程的能力。這反過來又會帶來一些顯而易見和隱含的細微差別。以下是其中一些最重要的:
- 服務應該能夠設置其環境以及回滾更改。例如,數據庫遷移、RabbitMQ 的 schema 等等。
- 如果無法回滾環境,那么服務應該是 多態的(polymorphic),并且支持舊版本和新版本的代碼同時共存部署。例如:數據庫遷移不應該導致舊版本服務的中斷(通常是之前的 2 到 3 個舊版本)。
- 任何服務更新的向后兼容性。通常,這是應用編程接口 API 的兼容性、消息格式等等。
在 Kubernes 集群中的回滾狀態非常簡單(運行 kubectl rollout undo deployment/some-deployment,Kubernes 將恢復到以前的“快照”),但是為了有效地做到這一點,你的元項目應該包含關于該快照的信息。非常不鼓勵使用更復雜的交付回滾算法,盡管它們有時是必要的。
以下是觸發回滾機制的因素:
- 發布后應用程序發生錯誤的百分比很高
- 來自關鍵監控點的信號
- 冒煙測試 (smoke tests)失敗
- 手工模式— 人為因素
確保信息安全和審計
沒有一個工作流可以神奇地“構建”防彈車級別的安全并保護你的生態系統免受外部和內部威脅,因此你需要確保你的架構框架在執行時著眼于公司在每個級別和所有子系統中的標準和安全策略。
稍后,我將在關于監控和告警的章節中討論建議的所有三個級別解決方案,它們對系統完整性也至關重要。
Kubernetes 有一套良好的內置 訪問控制機制 、 網絡策略 、 事件審計 和其它與信息安全相關的強大工具,可用于構建出色的 周界保護(perimeter of protection)、抵御和防止攻擊以及數據泄漏。
二、從開發工作流到架構
應該認真對待在開發流程和生態系統之間建立緊密集成的嘗試。將這種集成的需求添加到傳統架構需求集(靈活性、可伸縮性、可用性、可靠性、防威脅等)中,可以極大地增加架構框架的價值。這是非常關鍵的一個方面,它導致了DevOps(Development Operation)這個概念的出現。DevOps 是實現基礎設施完全自動化和優化的一個合乎邏輯的步驟。然而,一個設計良好的架構架構和可靠的子系統,可以讓 DevOps 任務最小化。
微服務架構
沒有必要贅述面向服務的架構(SOA)的好處,包括為什么服務應該是 “微”(micro)粒度的。我只想說,如果你已經決定使用 Docker 和 Kubernetes,那么你很可能會理解(并接受)這樣的觀點:維護一個 單體(monolithic)架構是困難的,甚至在意識形態上是錯誤的。Docker 被設計成運行 單進程(single process)應用,并和持久層一起工作。它迫使我們在 DDD( 領域驅動開發(Domain-Driven Development))框架內思考。在 Docker 中,被打包的代碼被視為一個暴露部分訪問端口的黑盒。
生態系統的關鍵組成部分和解決方案
根據我設計可用性和可靠性更高的系統的經驗,有幾個組件對微服務的運行至關重要。稍后我將列出并討論這些組件,即使以下我只是在 Kubernetes 環境中引用它們,你也可以將我的這個列表作為任何其他平臺的檢查表使用。
如果你(和我一樣)能得出這樣的結論,也即將這些組件作為一個常規 Kubernetes 服務來管理是非常好的,那么我建議你在不同于 “生產集群”(production)的單獨集群中運行它們。例如, “預生產/準生產”(staging)集群可以在生產環境不穩定時挽救你的生命,因為這種情況下你會迫切需要一個能提供鏡像、代碼或監控工具的環境。可以說,這解決了雞和蛋的問題。
身份服務
和往常一樣,一切開始于對服務器、虛擬機、應用程序、辦公室郵件的訪問。如果你現在就是或想要成為主要企業平臺之一(IBM、谷歌、微軟)的客戶,訪問問題將由服務提供商提供的服務來處理。然而,如果你想有自己的解決方案,那么這一切就只能由你自己搞定,并且不能超出你的預算?
這個關于單點登錄的 列表 將幫助你決定合適的解決方案,并估計安裝配置和維護該解決方案所需的工作量。當然,你的選擇必須符合公司的安全政策并得到信息安全部門的批準。
自動化的服務開通

雖然 Kubernetes 只要求在物理機器/云虛擬機上的少量組件(docker、kubelet、kube proxy、etcd 集群),但你仍然需要能夠自動化完成添加新機器和對集群進行管理。以下是幾個簡單的方法:
- KOPS — 這個工具允許你在兩個公有云 (AWS 或 GCE)上安裝集群
- Teraform — 這個工具讓你可以管理任何環境的基礎架構,并遵循 IAC( 基礎架構即代碼(Infrastructure as Code))的思想
- Ansible — 用于構建任何類型自動化的通用工具
就我個人而言,我更喜歡第 3 個選項(加上一個 Kubernetes 集成模塊 ),因為它允許我同時使用服務器和 k8s 對象,并實現任何類型的自動化。然而,沒有什么能阻止你使用 Teraform 及其 Kubernetes 模塊 。KOPS 不能很好地使用“裸機”,但是它仍然是一個很好的使用 AWS/GCE 的工具!
Git 代碼庫和任務跟蹤器
不用說,要為開發人員和其他相關角色提供全面的工作環境,你需要有一個團隊協作和代碼存儲的地方。我很難確定哪種服務是最合適的,但我個人最喜歡的任務跟蹤工具是 redmine (免費)或 Jira (付費)。對代碼庫而言,有比較老牌的 gerrit (免費)或 bitbucket (付費)。
值得注意的是,企業環境中協作工作的兩個最一致的工具(盡管是商業版本的)是: Atlassian 和 Jetbrains 。你可以使用它們中的任何一個作為獨立的解決方案,或者將兩者的各種組件結合起來。
要充分利用任務跟蹤器和代碼庫的組合,請考慮它們的集成策略。例如,以下是一些確保代碼和相關任務關聯性的提示(當然,你也可以選擇自己的方法):
- 只有當試圖 推送(push)的分支存在相應的任務號(如:TASK-1/feature-34)時,才能提交到遠程代碼庫中
- 任何分支只有在一定數量的合格代碼復查迭代之后才可以進行合并
- 如果相應的任務不是 “進行中”(In Progress)或類似狀態,則任何分支都應被阻止和禁用,以備將來更新
- 任何旨在實現自動化的步驟都不應該直接提供給開發人員使用
- 只有經過授權的開發人員才能直接修改master主分支—其它的一切都由自動化機器人控制
- 如果相應的任務處于 “交付”(For Delivery)或類似狀態之外的任何狀態,則分支不可用于合并
Docker 注冊表
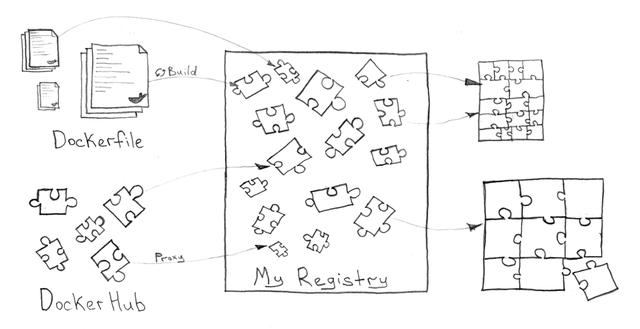
應特別注意 Docker 鏡像管理系統,因為它對于存儲和交付服務至關重要。此外,該系統應該支持用戶和用戶組的訪問,能夠刪除舊的和不必要的鏡像,提供圖形用戶界面和 RESTful 應用編程接口。
你可以使用云解決方案(例如, hub.docker.com )或私有托管服務,甚至可以安裝在你的 Kubernetes 集群中。作為 Docker 注冊表的企業解決方案, Vmware Harbor 就是一個很好的例子。最壞的情況是,如果你只想存儲鏡像,而不需要復雜的系統,你就直接使用 Docker Registry 好了。
CI/CD 和服務交付系統
我們之前討論過的組件(git 存儲庫、任務跟蹤器、帶有 Ansible 劇本的元項目、外部依賴項)都不能像懸浮在真空中一樣彼此分開運行。將它們連接起來的是持續集成和交付服務。
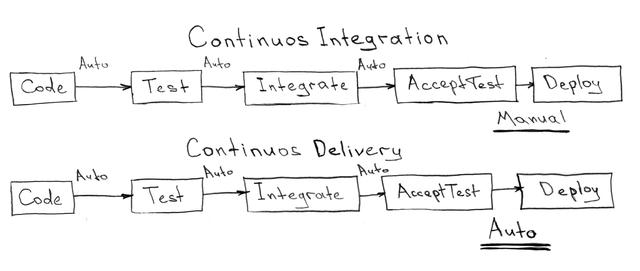
CI — 持續集成 (Continuous Integration)
CD — 持續交付(Continuous Delivery)
服務應該足夠簡單,并且沒有任何與系統交付或配置相關的邏輯。CI/CD 服務應該做的就是對外部世界的事件(git 存儲庫中的變化,任務跟蹤器中任務的移動)做出反應,并啟動元項目中描述的操作。此外,CI/CD 服務是管理所有代碼存儲庫的控制點和管理它們的工具(代碼分支合并、來自上游/主分支的更新)。
我使用過一個來自 Jetbrains 的 工具 TeamCity ,這是一個相當強大但非常簡單的工具。但是你也可以決定嘗試其他東西,比如免費的 Jenkins 。
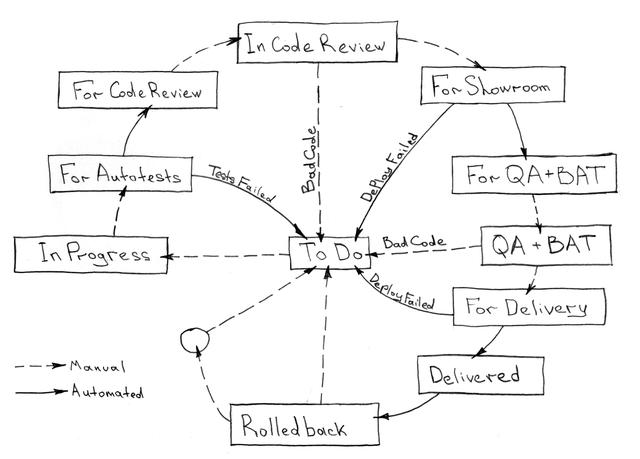
在我們上面描述的方案中,集成服務主要負責啟動四個主要流程和一個輔助流程,如下所示:
- 自動化服務測試 — 通常情況下,對單一代碼庫而言,當分支狀態改變或狀態改變為“等待自動測試”(或類似情況)時
- 服務交付 — 通常來自元項目和多個服務(分別來自于不同的代碼庫),當 QA 測試和生產環境部署的狀態分別更改為 “等待展示”(Awaiting Showroom)或 “等待交付”(Awaiting Delivery)時
- 回滾 — 通常來自元項目和單個服務或整個服務的特定部分,由外部事件或在交付不成功的情況下觸發
- 服務移除 — 這是從單個 測試環境(showroom)中完全移除整個生態系統所必需的,當 測試中(In QA)狀態已過期或不再需要該環境時
- 鏡像構建器(輔助過程) — 可以集成到服務交付過程中,或者獨立地用于編譯 Docker 鏡像并將其發送到 Docker 注冊表。這經常需要處理常用的鏡像(數據庫、通用服務或不需要頻繁更改的服務)
日志收集和分析系統
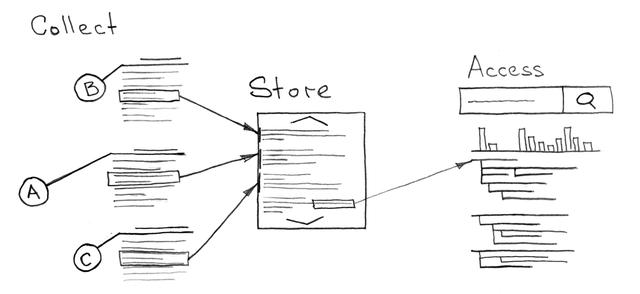
任何 Docker 容器使其日志可訪問的唯一方法是將它們寫入容器中運行的根進程的標準輸出或標準錯誤設備(STDOUT 或 STDERR)。微服務的開發人員并不真正關心日志數據接下來會發生什么,只需要保證它們應該在必要時可用,并且最好包含過去某個時刻的記錄。Kubernetes 和支持這個生態的工程師負責這一切的實現。
在 官方文檔 中,你可以找到處理日志的基本(也是一個好的)策略的描述,這將有助于你選擇用于聚合和存儲大量文本數據的服務。
在日志記錄系統的推薦服務中,相同的文檔提到了用于收集數據的 fluentd (作為代理在集群的每個節點上啟動)和存儲和索引數據的 Elasticsearch 。即使你可能不同意這種解決方案的效率,但它是可靠且易于使用的,所以我認為這至少是一個好的開始。
Elasticsearch 是一個資源密集型解決方案,但是它可以很好地擴展,并且有現成的 Docker 鏡像來運行單個節點或所需大小的集群。
追蹤系統
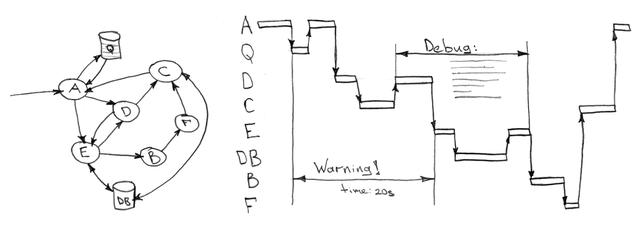
盡管你的代碼盡可能完美,但失敗確實會發生,然后你想在生產環境中仔細研究它們,并嘗試理解“在我的本地機器上一切工作都是正常的呀,現在到底是哪里出了什么問題呢?”。數據庫查詢速度慢、緩存不當、磁盤速度慢或與外部資源的連接速度慢、生態系統中的事務、瓶頸和規模不足的計算服務,這些都是你必須跟蹤和估計在實際負載下執行代碼所花費的時間的原因。
Opentracing 和 Zipkin 可以支持在大多數現代編程語言中完成這一任務,并且在 埋點(instrumenting)代碼之后不會增加任何額外的負擔。當然,所有收集的數據都應該存儲在一個合適的地方,被 組件 之一所使用。
在代碼中埋點并通過所有服務、消息隊列、數據庫等轉發 “跟蹤標識”(Trace Id)時帶來的復雜性由上述開發標準和服務模板解決。后者還負責保證方法的一致性。
監控和報警
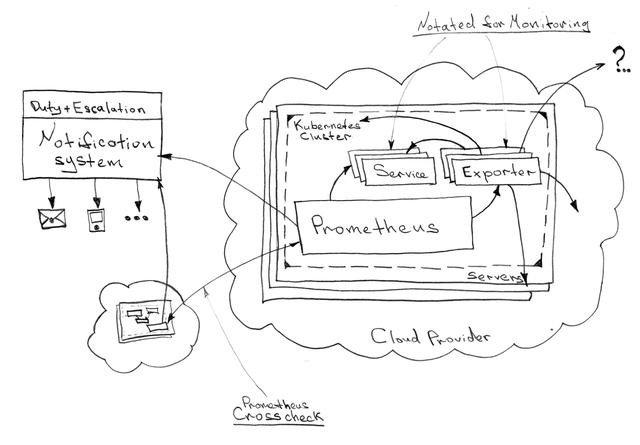
Prometheus 已經成為現代系統中事實上的監控和報警標準,更重要的是,它在 Kubernetes 中幾乎 開箱即用 。你可以參考 官方 Kubernetes 文檔 ,了解更多有關監控和報警的信息。
監控是必須安裝在群集內的少數輔助系統之一。集群是一個受監控的實體。但是監控系統的監控(請原諒重復)只能從外部執行(例如,從相同的 “預生產”(Staging)環境)。在這種情況下,交叉檢查對于任何分布式環境來說都是一個方便的解決方案,不會使高度統一的生態系統的架構復雜化。
整個監控范圍分為三個完全邏輯隔離的級別。以下是我認為在每個級別跟蹤點的最重要的例子:
- 物理資源級別:
- 網絡資源及其可用性
- 磁盤 (I/O,可用空間)
- 單個節點的基本資源(CPU、RAM、LA)
- 集群級別:
- 主集群系統中每個節點的可用性(kubelet、kubeAPI、DNS、etcd 等)
- 監控服務允許的和實際的資源消耗
- Pod 的重新加載
- 服務級別:
- 任何類型的應用程序監控
- 從數據庫內容到應用編程接口調用的頻率
- API 網關上的 HTTP 調用錯誤數
- 隊列的大小和 worker 節點的利用率
- 數據庫的多個指標(復制延遲、事務的時間和數量、慢速請求等)
- 非 HTTP 協議進程的錯誤分析
- 監控發送到日志系統的請求(你可以將任意請求轉換為度量值)
至于每個級別的報警通知,我建議你使用無數外部服務之一,這些服務可以通過電子郵件、短信發送通知或撥打手機號碼。我還要提到另一個系統 — OpsGenie ,它可以 與 Prometheus 的報警管理器緊密集成 。
OpsGenie 是一種靈活的報警工具,有助于處理故障升級報告、全天候工作、通知渠道選擇等。在團隊之間分發報警信息也很容易。例如,不同級別的監控應該向不同的團隊/部門發送通知:物理資源 —> 基礎設施 + Devops,集群 —> Devops,應用 — > 向相關團隊發送通知。
API 網關和單點登錄
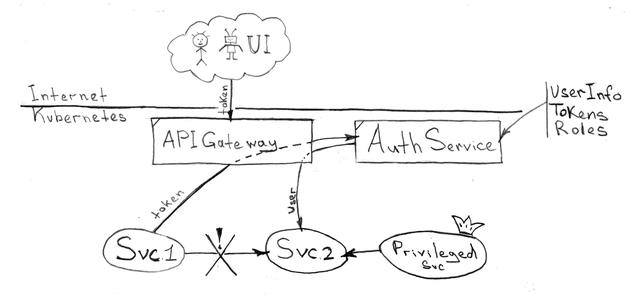
為了處理授權、身份驗證、用戶注冊(外部用戶——公司的客戶)和其他類型的訪問控制等任務,你需要一個高度可靠的服務,它可以與您的 API 網關保持靈活的集成。使用與“身份服務”相同的解決方案沒有害處,但是您可能希望將這兩種資源分開,以實現不同級別的可用性和可靠性。
服務間集成不應該很復雜,你的服務不應該擔心用戶的授權和認證。相反,架構和生態系統應該有一個代理服務來處理所有的通信和 HTTP 流量。
讓我們考慮與 API 網關集成的最合適的方式 — 令牌(token)。這種方法適用于所有三種訪問場景:從圖形用戶界面(UI),從服務到服務,以及從外部系統。那么接收令牌的任務(基于登錄名和密碼)由用戶界面本身或服務開發人員承擔。區分用戶界面中使用的令牌的生命周期(較短的 TTL)和其他情況下使用的令牌的生命周期(較長的和自定義的 TTL)也很有意義。
以下是 API 網關解決的一些問題:
- 從外部和內部訪問生態系統中的服務(服務之間不直接交流)
- 與單點登錄服務集成:
- 令牌的轉換和附加 HTTPS 請求頭包含所請求服務的用戶標識數據(ID、角色、其他詳細信息)
- 基于從單點登錄服務接收的角色來啟用/禁用對所請求服務的訪問控制
- 對 HTTP 協議流量的單點監控
- 組合來自不同服務的 API 接口文檔(例如,組合 Swagger 的 json/yml 文件 )
- 能夠根據域名和請求的 URI 來管理整個生態系統的路由
- 外部流量的單一接入點,以及與接入提供者的集成
事件總線和企業集成/服務總線
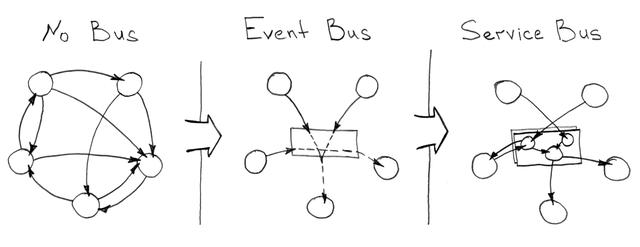
如果你的生態系統包含在一個宏域中工作的數百個服務,你將不得不處理數以千計的服務通信方式。為了簡化數據流,你應該考慮在某些事件發生時將消息分發到大量收件人的能力,而不管事件的上下文如何。換句話說,你需要一個事件總線來發布基于標準協議的事件并訂閱它們。
對于事件總線,你可以使用任何能夠操作所謂代理的系統: RabbitMQ 、 Kafka 、 ActiveMQ 和其它類似的系統。一般來說,數據的高可用性和一致性對于微服務至關重要,但是由于 CAP 定理 ,你仍然需要犧牲一些東西來實現總線的正確分布和集群管理。
很自然,事件總線應該能夠解決各種服務間通信的問題,但是隨著服務數量從成百上千增加到數萬,即使是最好的基于事件總線的架構也可能會失敗,因此你需要尋找另一種解決方案。一個很好的例子是集成總線方法,它可以擴展上述 “愚蠢的管道 —智能的消費者”(Dumb pipe — Smart consumer)策略的能力。
有很多原因決定了需要使用“ 企業集成/服務總線 ”方法,該方法旨在降低面向服務架構的復雜性。下面列出了部分原因:
- 多個消息的聚合
- 將一個事件拆分成幾個事件
- 系統對事件響應的同步/事務分析
- 接口的適配,這對與外部系統的集成尤其重要
- 事件路由的高級邏輯
- 與相同服務的多重集成(從外部和內部)
- 數據總線的不可擴展集中化
作為企業集成總線的開源軟件,你可能需要考慮 Apache ServiceMix ,它包含了設計和開發這種 SOA 所必需的幾個組件。
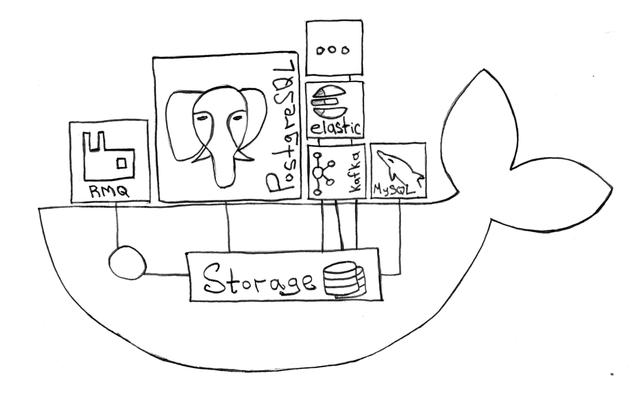
數據庫和其他有狀態服務
和 Kubernetes 一樣,對于需要數據持久性和與磁盤緊密合作的服務,Docker 徹底改變了游戲規則。有人說,服務應該在物理服務器或虛擬機上以舊的方式“生存”。我尊重這一觀點,我不會就其利弊展開爭論,但我相當肯定,這種說法的存在只是因為在 Docker 環境中暫時缺乏管理有狀態服務的知識、解決方案和經驗。
我還應該提到,數據庫通常占據存儲世界的中心位置,因此你選擇的解決方案應該為在 Kubernetes 環境中工作做好充分準備。
根據我的經驗和市場情況,我可以區分以下幾組有狀態服務,并為每一組服務提供最合適的面向 Docker 的解決方案示例:
- 數據庫管理系統 — PostDock 是任何 Docker 環境中 PostgreSQL 的簡單可靠的解決方案
- 隊列/消息 代理(broker) — RabbitMQ 是構建消息隊列系統和路由消息的經典軟件。RabbitMQ 配置中的 cluster_formation 參數對于集群設置是必不可少的
- 緩存服務 — redis 被認為是最可靠和靈活的數據緩存解決方案之一
- 全文搜索 — 我前面已經提到過的 Elasticsearch 技術棧,最初用于文本搜索,但同樣擅長存儲日志和處理大量文本數據的任何工作
- 文件存儲服務 — 為任何類型的文件存儲和交付(ftp、sftp 等)提供的通用服務
鏡像依賴
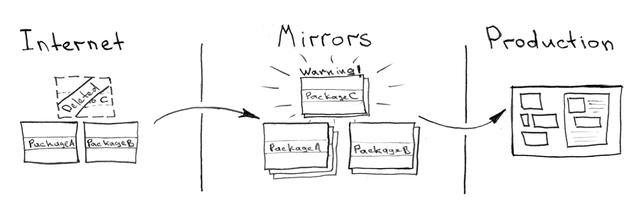
如果你還沒有遇到你需要的包或依賴項已經從公共服務器上刪除或暫時不可用的情況,請不要認為這種情況永遠不會發生。為了避免任何不必要的不可用性并為內部系統提供安全性,請確保你的服務的構建和交付都不需要互聯網連接。在內部網絡中配置所有鏡像和拷貝:Docker 鏡像、rpm 包、源代碼庫、python/go/js/php 模塊。
這些和任何其它類型的依賴都有自己的解決方案。最常見的方法可以通過在搜索引擎查詢“ X 的私有依賴鏡像 ”找到。
三、從架構回歸現實
不管你喜不喜歡,你的整個架構遲早都會失敗。這樣的情況一直在發生:技術很快就過時了(1-5 年),方法論變化慢一點(5-10 年),設計原則和基礎理論偶爾變化(10-20 年),但不管怎么樣這個趨勢是不可阻擋的。
考慮到技術的過時,請始終努力將你的生態系統保持在技術創新的巔峰,規劃和推出新的服務來滿足開發人員、業務部門和最終用戶的需求,向利益相關方推廣新的實用程序,提供知識來推動你的團隊和公司向前發展。
通過融入專業社區、閱讀相關文獻和與同事交流,可以讓你保持領先地位。意識到你的機會,并在項目中正確使用新趨勢。試驗并應用科學的方法來分析你的研究結果,或者依靠你信任和尊重的其他人的結論。
現在,很難為根本性的變化做好準備。但如果你是這個領域的專家,這也是可能的。我們所有人一生中只會見證幾個重大的技術變革,但不是頭腦中的知識數量讓我們成為專業人士,讓我們達到頂峰,而是我們對于新想法的開放性和接受蛻變的能力。
回到標題中的問題,“有可能構建一個完美的架構嗎”?不,當然不可能輕易“一勞永逸”,但一定要為之奮斗,在某個時刻,“在一個階段內”,你一定會成功!