













將sklearn訓練速度提升100多倍,美國「返利網」開源sk-dist框架
在本文中,Ibotta(美國版「返利網」)機器學習和數據科學經理 Evan Harris 介紹了他們的開源項目 sk-dist。這是一個分配 scikit-learn 元估計器的 Spark 通用框架,它結合了 Spark 和 scikit-learn 中的元素,可以將 sklearn 的訓練速度提升 100 多倍。
在 Ibotta,我們訓練了許多機器學習模型。這些模型為我們的推薦系統、搜索引擎、定價優化引擎、數據質量等提供了支持,在與我們的移動 app 互動的同時為數百萬用戶做出預測。
雖然我們使用 Spark 進行大量的數據處理,但我們首選的機器學習框架是 scikit-learn。隨著計算成本越來越低以及機器學習解決方案的上市時間越來越重要,我們已經踏出了加速模型訓練的一步。其中一個解決方案是將 Spark 和 scikit-learn 中的元素組合,變成我們自己的融合解決方案。
項目地址:https://github.com/Ibotta/sk-dist
何為 sk-dist
我們很高興推出我們的開源項目 sk-dist。該項目的目標是提供一個分配 scikit-learn 元估計器的 Spark 通用框架。元估計器的應用包括決策樹集合(隨機森林和 extra randomized trees)、超參數調優(網格搜索和隨機搜索)和多類技術(一對多和一對一)。

我們的主要目的是填補傳統機器學習模型分布選擇空間的空白。在神經網絡和深度學習的空間之外,我們發現訓練模型的大部分計算時間并未花在單個數據集上的單個模型訓練上,而是花在用網格搜索或集成等元估計器在數據集的多次迭代中訓練模型的多次迭代上。
實例
以手寫數字數據集為例。我們編碼了手寫數字的圖像以便于分類。我們可以利用一臺機器在有 1797 條記錄的數據集上快速訓練一個支持向量機,只需不到一秒。但是,超參數調優需要在訓練數據的不同子集上進行大量訓練。
如下圖所示,我們已經構建了一個參數網格,總共需要 1050 個訓練項。在一個擁有 100 多個核心的 Spark 集群上使用 sk-dist 僅需 3.4 秒。這項工作的總任務時間是 7.2 分鐘,這意味著在一臺沒有并行化的機器上訓練需要這么長的時間。
- import timefrom sklearn import datasets, svm
- from skdist.distribute.search import DistGridSearchCV
- from pyspark.sql import SparkSession # instantiate spark session
- spark = (
- SparkSession
- .builder
- .getOrCreate()
- )
- sc = spark.sparkContext
- # the digits dataset
- digits = datasets.load_digits()
- X = digits["data"]
- y = digits["target"]
- # create a classifier: a support vector classifier
- classifier = svm.SVC()
- param_grid = {
- "C": [0.01, 0.01, 0.1, 1.0, 10.0, 20.0, 50.0],
- "gamma": ["scale", "auto", 0.001, 0.01, 0.1],
- "kernel": ["rbf", "poly", "sigmoid"]
- }
- scoring = "f1_weighted"
- cv = 10
- # hyperparameter optimization
- start = time.time()
- model = DistGridSearchCV(
- classifier, param_grid,
- sc=sc, cv=cv, scoring=scoring,
- verbose=True
- )
- model.fit(X,y)
- print("Train time: {0}".format(time.time() - start))
- print("Best score: {0}".format(model.best_score_))
- ------------------------------
- Spark context found; running with spark
- Fitting 10 folds for each of 105 candidates, totalling 1050 fits
- Train time: 3.380601406097412
- Best score: 0.981450024203508
該示例說明了一個常見情況,其中將數據擬合到內存中并訓練單個分類器并不重要,但超參數調整所需的擬合數量很快就會增加。以下是運行網格搜索問題的內在機制,如上例中的 sk-dist:
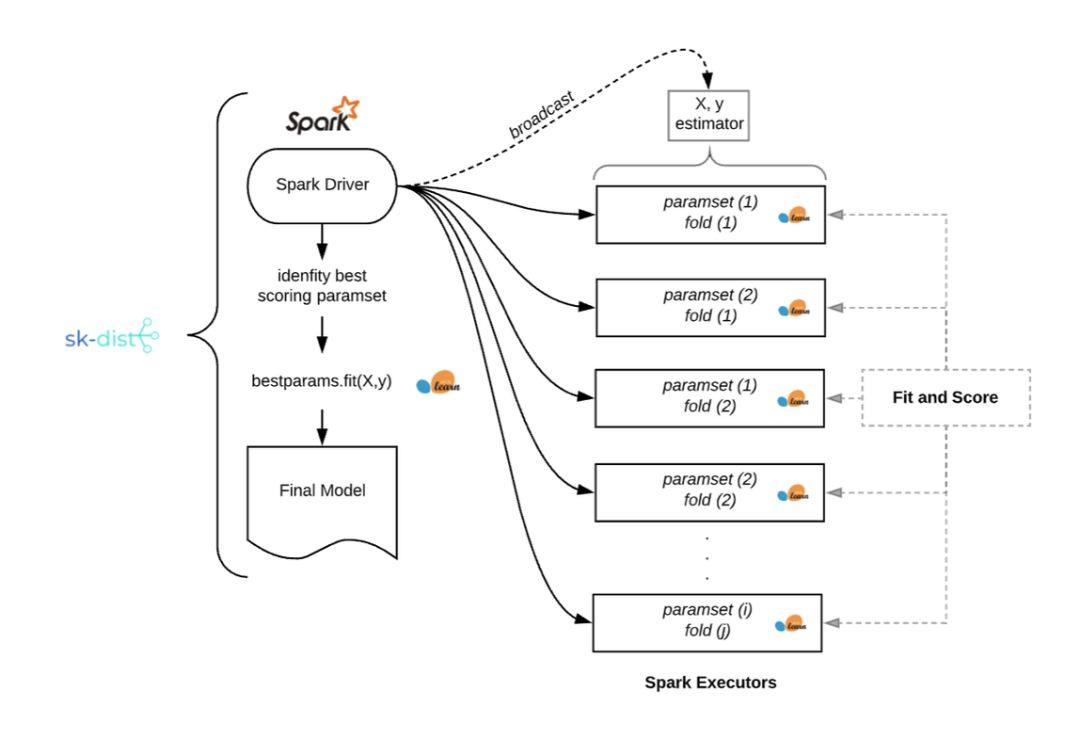
使用 sk-dist 進行網格搜索
對于 Ibotta 傳統機器學習的實際應用,我們經常發現自己處于類似情況:中小型數據(100k 到 1M 記錄),其中包括多次迭代的簡單分類器,適合于超參數調優、集合和多類解決方案。
現有解決方案
對于傳統機器學習元估計訓練,現有解決方案是分布式的。第一個是最簡單的:scikit-learn 使用 joblib 內置元估計器的并行化。這與 sk-dist 非常相似,除了一個主要限制因素:性能受限。即使對于具有數百個內核的理論單臺機器,Spark 仍然具有如執行器的內存調優規范、容錯等優點,以及成本控制選項,例如為工作節點使用 Spot 實例。
另一個現有的解決方案是 Spark ML。這是 Spark 的本機機器學習庫,支持許多與 scikit-learn 相同的算法,用于分類和回歸問題。它還具有樹集合和網格搜索等元估計器,以及對多類問題的支持。雖然這聽起來可能是分配 scikit-learn 模式機器學習工作負載的優秀解決方案,但它的分布式訓練并不能解決我們感興趣的并行性問題。
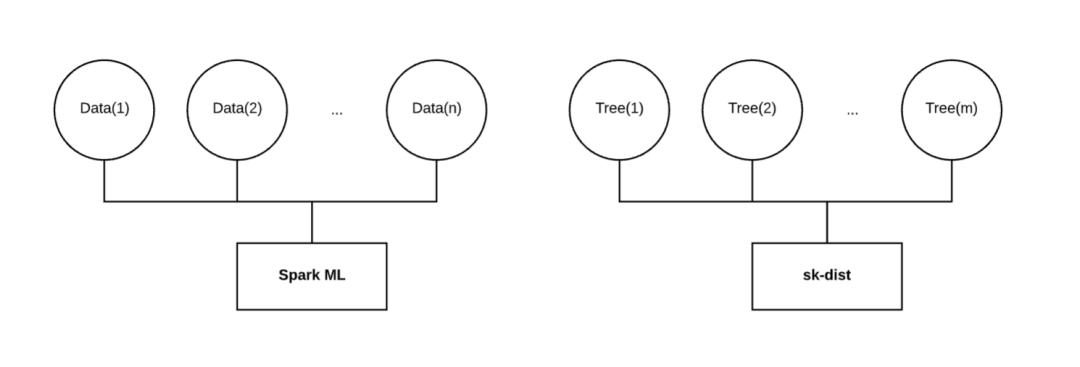
分布在不同維度
如上所示,Spark ML 將針對分布在多個執行器上的數據訓練單個模型。當數據很大且無法將內存放在一臺機器上時,這種方法非常有效。但是,當數據很小時,它在單臺計算機上的表現可能還不如 scikit-learn。此外,當訓練隨機森林時,Spark ML 按順序訓練每個決策樹。無論分配給任務的資源如何,此任務的掛起時間都將與決策樹的數量成線性比例。
對于網格搜索,Spark ML 確實實現了并行性參數,將并行訓練單個模型。但是,每個單獨的模型仍在對分布在執行器中的數據進行訓練。如果按照模型的維度而非數據進行分布,那么任務的總并行度可能是它的一小部分。
最終,我們希望將我們的訓練分布在與 Spark ML 不同的維度上。使用小型或中型數據時,將數據擬合到內存中不是問題。對于隨機森林的例子,我們希望將訓練數據完整地廣播給每個執行器,在每個執行器上擬合一個獨立的決策樹,并將那些擬合的決策樹返回驅動程序以構建隨機森林。沿著這個維度分布比串行分布數據和訓練決策樹快幾個數量級。這種行為與網格搜索和多類等其他元估計器技術類似。
特征
鑒于這些現有解決方案在我們的問題空間中的局限性,我們決定在內部開發 sk-dist。最重要的是我們要「分配模型,而非數據」。
sk-dist 的重點是關注元估計器的分布式訓練,還包括使用 Spark 進行 scikit-learn 模型分布式預測的模塊、用于無 Spark 的幾個預處理/后處理的 scikit-learn 轉換器以及用于有/無 Spark 的靈活特征編碼器。
分布式訓練:使用 Spark 分配元估計器訓練。支持以下算法:超參數調優(網格搜索和隨機搜索)、決策樹集合(隨機森林、額外隨機樹和隨機樹嵌入)以及多類技術(一對多和一對一)。
分布式預測:使用 Spark DataFrames 分布擬合 scikit-learn 估算器的預測方法。可以通過便攜式 scikit-learn 估計器實現大規模分布式預測,這些估計器可以使用或不使用 Spark。
特征編碼:使用名為 Encoderizer 的靈活特征轉換器分布特征編碼。它可以使用或不使用 Spark 并行化。它將推斷數據類型和形狀,自動應用默認的特征轉換器作為標準特征編碼技術的最佳預測實現。它還可以作為完全可定制的特征聯合編碼器使用,同時具有與 Spark 分布式轉換器配合的附加優勢。
用例
以下是判斷 sk-dist 是否適合你的機器學習問題空間的一些指導原則:
傳統機器學習 :廣義線性模型、隨機梯度下降、最近鄰算法、決策樹和樸素貝葉斯適用于 sk-dist。這些都可在 scikit-learn 中實現,可以使用 sk-dist 元估計器直接實現。
中小型數據 :大數據不適用于 sk-dist。請記住,訓練分布的維度是沿著模型變化,而不是數據。數據不僅需要適合每個執行器的內存,還要小到可以廣播。根據 Spark 配置,最大廣播大小可能會受到限制。
Spark 定位與訪問:sk-dist 的核心功能需要運行 Spark。對于個人或小型數據科學團隊而言,這并不總是可行的。此外,為了利用 sk-dist 獲得最大成本效益,需要進行一些 Spark 調整和配置,這需要對 Spark 基礎知識進行一些訓練。
這里一個重要的注意事項是,雖然神經網絡和深度學習在技術上可以與 sk-dist 一起使用,但這些技術需要大量的訓練數據,有時需要專門的基礎設施才能有效。深度學習不是 sk-dist 的預期用例,因為它違反了上面的 (1) 和 (2)。在 Ibotta,我們一直在使用 Amazon SageMaker 這些技術,我們發現這些技術對這些工作負載的計算比使用 Spark 更有效。

























