用于代碼生成的基于樹的Transformer結構
介紹:
代碼生成是一個重要的人工智能問題,有可能顯著提高程序員的生產力。給定以自然語言編寫的規范,代碼生成系統會將規范轉換為可執行程序。例如,如果 python 程序員給出指令“初始化字典 Dict”,則代碼生成器應自動生成“Dict={}”。
隨著深度學習技術的發展,研究人員已針對此問題應用了各種神經體系結構,例如序列到序列(Seq2Seq)模型或序列到樹(Seq2Tree)模型。尤其是,最先進的方法通過預測語法規則序列來生成代碼。也就是說,系統保留已生成代碼的部分抽象語法樹(AST),并預測將用于擴展特定節點的語法規則。
語法規則的分類面臨兩個主要挑戰。第一個挑戰是長時依賴問題。代碼元素可能取決于另一個遙遠的元素。例如,第 100 行的變量引用語句“if len(a)
在本文中,我們提出了一種新穎的神經體系結構 TreeGen,用于代碼生成。為了解決第一個挑戰,TreeGen 采用了最近提出的 Transformer 架構,該架構能夠捕獲長時依賴關系。但是,原始的 Transformer 體系結構不是為程序設計的,并且不能利用樹結構,即上述第二個挑戰。如在基于圖和樹的卷積神經網絡中一樣,利用結構信息的標準方法是將節點及其鄰接節點的向量表示形式組合為結構化卷積子層的輸出。但是,標準的 Transformer 結構沒有這樣的結構化卷積子層,并且不清楚在何處添加它們。
試圖在所有 Transformer 塊中添加結構化卷積子層是很誘人的。我們的核心推測是,在對一個節點及其鄰接點進行卷積時,向量表示應主要包含原始節點的信息。隨著節點的向量表示在 Transformer 的解碼器中由更多的塊進行處理,它們逐漸混入來自其他節點的更多信息并丟失其原始信息。因此,我們僅將結構卷積子層添加到前幾個 Transformer 解碼器塊中,而不是全部添加。
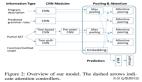
一般而言,TreeGen 體系結構包括三個部分:(1)自然語言(NL)編碼器:對文本描述進行編碼;(2)AST 解碼器(前幾個 Transformer 解碼器塊)使用結構化卷積子層對先前生成的部分代碼進行編碼;(3)解碼器(其余的 Transformer 解碼器塊)將 query(要在 AST 中擴展的節點)與前兩個編碼器組合在一起,以預測下一個語法規則。
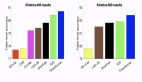
我們在建立的基準數據集上評估了我們的模型,這是紙牌游戲爐石傳說的 Python 實現。結果表明,我們的模型明顯優于以前的模型 4.5 個百分點。我們進一步在兩個語義分析數據集(ATIS 和 GEO)上評估了我們的模型,這兩個數據集將自然語言句子轉換為 lambda 微積分邏輯形式。結果表明,我們的模型在以前的神經模型中具有最高的準確性,分別為 89.1%和 89.6%。我們的評估還表明,將結構化卷積子層添加到前幾個 Transformer 塊中,其性能明顯優于所有塊中具有結構化卷積的 Transformer。
我們的模型:
我們通過預測編程語言的語法規則來生成代碼。圖 2 顯示了我們模型的整體圖,它包括三個部分:NL 編碼器,AST 編碼器和解碼器。我們將在以下小節中詳細介紹它們。
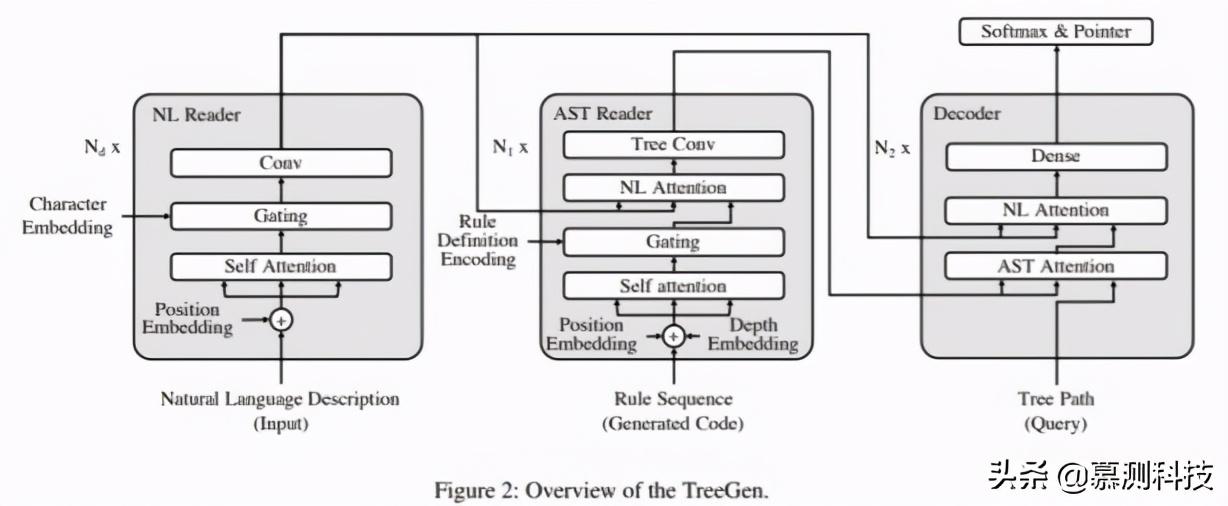
語法規則預測:
在本節中,我們介紹如何將代碼生成建模為一系列語法規則的分類問題。程序可以被分解為幾個與上下文無關的語法規則,并解析為 AST。例如,圖 1 顯示了代碼“length=10”的 PythonAST,其中虛線框是終止符,而實心框是非終止符。
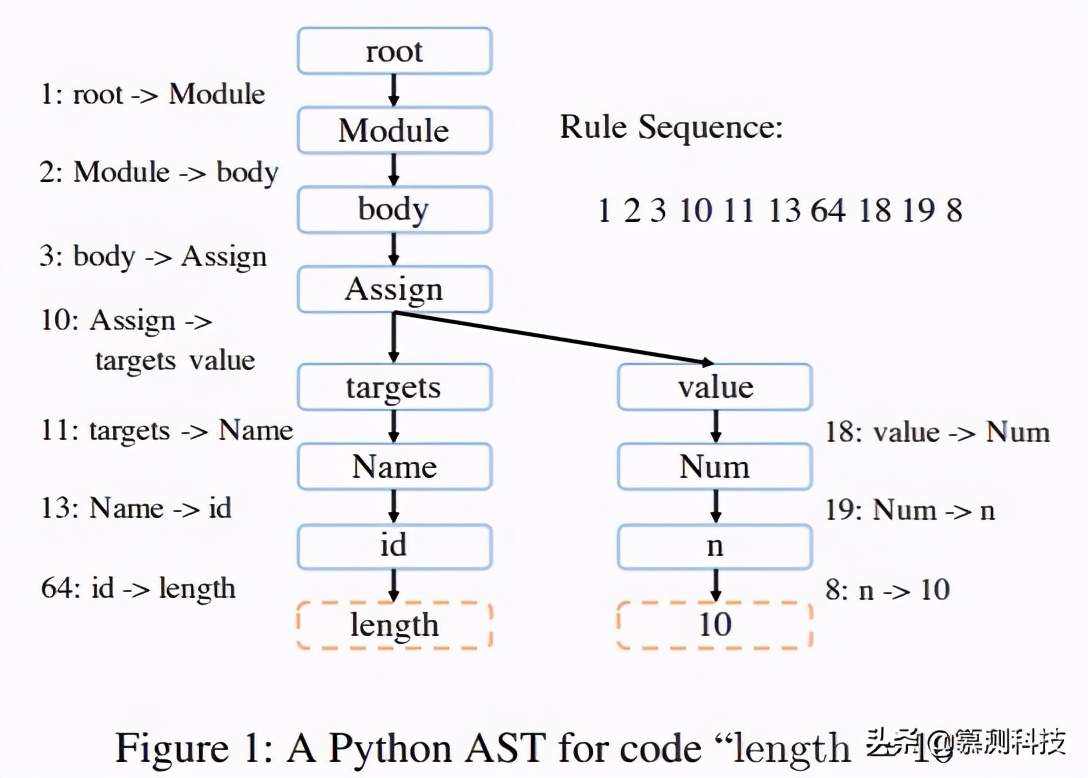
可以將基于 AST 的代碼生成視為通過語法規則擴展非終止符。重復此過程,直到所有葉節點都處于末尾。在圖 1 中,“1:root->Module”是語法規則的示例,其中前面的數字是規則的 ID。遵循預定遍歷,我們可以獲得在右上角顯示的生成 AST 的規則序列。
形式上,概率可以分解為遵循以下順序生成代碼的規則的概率。其中 ri 是規則序列中的第 i 條規則。通過這種方式,我們的任務是訓練一個模型以計算 p(ri|NL 輸入,pi),即給定自然語言描述和當前生成的部分 AST,該模型將計算擴展該節點的規則的概率。
NL 編碼器:
輸入的描述決定了代碼的功能。它可以是爐石傳說數據集中的半結構化描述,也可以是 ATIS 和 GEO 語義解析數據集中的自然語言。
對于輸入的描述,我們首先將其標記為 n1,n2,...,nL,其中 L 表示輸入的長度。然后將每個 ni 拆分為字符 c1(ni),c2(ni),...,cS(ni),其中 S 是 ni 中的字符數。通過嵌入,將所有標記和字符表示為數值向量 n1,n2,...,nL 和 c1(ni),c2(ni),...,cS(ni)。
輸入文字表示:
字符嵌入。相似詞經常具有相似的字符(例如“program”和“programs”)。為了利用此屬性,我們通過具有完全連接層的字符嵌入來表示標記。其中 W(c)是權重,字符序列被填充為預定義的最大長度 M。在全連接層之后,我們還應用層歸一化。然后將這些向量反饋到 NL 編碼器,并通過子層將其與詞嵌入集成在一起。
NL 編碼器的神經網絡結構:
NL 編碼器由一堆塊(總共 Nd 個塊)組成。每個塊包含三個不同的子層(即,self_attention,gating 機制和單詞卷積)以提取特征,我們將在以下小節中詳細介紹。在兩個子層之間,我們采用殘差連接,然后進行層歸一化。
(1) Self-attention:self-attention 子層遵循 Transformer 的架構),并使用 multi-headattention 來捕獲長依賴信息。
對于輸入標記 n1,n2,···,nL 的序列,我們通過查找表將它們表示為嵌入 n1,n2,···,nL。我們還使用位置嵌入對單詞位置的信息進行編碼,并計算第 b 個 Transformer 塊中第 i 個單詞的位置嵌入。其中 pi,b[·]是向量 pi,b 的維度的索引,而 d 是維數數量。
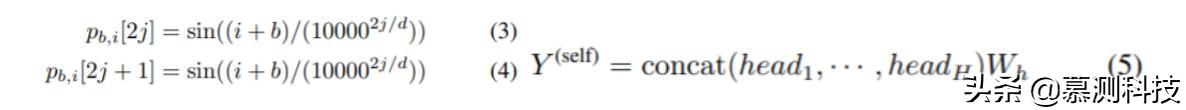
Transformer 塊通過 Multi-head 學習非線性特征,從而產生矩陣 Y。Multi-head 層的計算公式如(5),其中 H 表示頭數,Wh 表示權重。注意層應用于每個頭部 head_t,通過(6)計算。其中 dk=d/H 表示每個特征向量的長度。Q,K,V 通過(7)計算。其中 WQ,WK,WV 是模型參數。xi 是此 Transformer 模塊的輸入。對于第一個塊,它是查找表嵌入和位置嵌入的向量和,即 ni+p1,i;對于其他塊,則是更底層的 Transformer 塊的輸出和與該塊相對應的位置嵌入的矢量和。
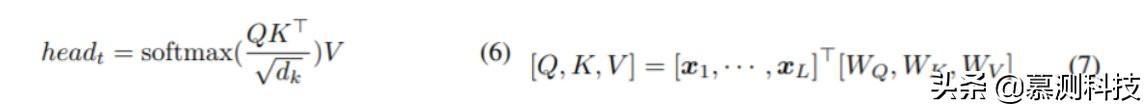
(2) Gating 機制:在通過 Self-attention 算出特征之后,我們將字符嵌入的信息進一步合并。這是由基于 softmax 的 Gating 機制給出的。對于第 i 個單詞,我們通過線性變換從 y(self)i 計算控制向量 qi。用于字符嵌入的 softmax 權重 k(c)i 由公式 2 中的 n(c)i 進行線性變換給出。用于 Transformer 輸出的 softmax 權重 k(y)i 由 y(self)i 進行的另一個線性變換給出。然后,通過(8)計算出 gate。它們用于對 Transformer 層 v(y)i 的特征和字符嵌入 v(c)i 的特征嵌入,分別由 y(self)i 和 n(c)i 線性轉換。
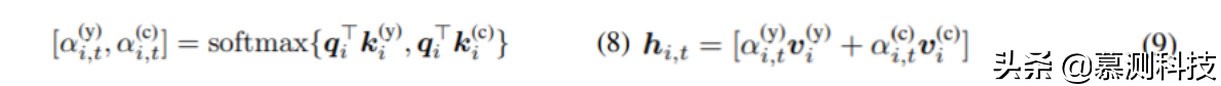
與公式 5 相似,我們的機制的輸出為 Y(gate)=(hi,t)i,t,其中(·)i,t 表示一個塊矩陣,元素為 hi,t。
(3) 單詞卷積:最后,將兩個卷積層應用于 Gating 機制 y(gate)1,...,y(gate)L,并提取每個標記 y(conv,l)1,...,附近的局部特征。y(conv,l)L,其中 l 表示卷積層。y(conv,l)i 由(10)計算。其中 W(conv,l)是卷積權重,w=(k-1)/2,k 表示窗口大小。特別地,y(conv,0)i 表示 Gating 機制 y(gate)i 的輸出。在這些層中,使用了可分離的卷積。原因是可分離的卷積參數較少,易于訓練。對于第一個和最后一個詞,我們添加零填充。在這些層之間,我們使用了 GELU 激活函數。
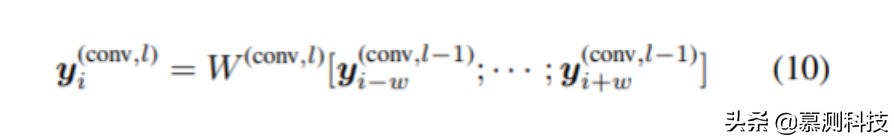
總而言之,NL 編碼器具有一些 Transformer 的 self-attention,Gating 機制和單詞卷積模塊。自然語言描述被編碼為特征 y(NL)1,y(NL)2,...,y(NL)L。
AST 編碼器
我們設計了一個 AST 編碼器,以對已生成的部分 AST 的結構進行建模。盡管我們的程序是通過預測語法規則的順序生成的,但是僅這些規則就缺少程序的具體認識,不足以預測下一個規則。因此,我們的 AST 編碼器會考慮異構信息,包括預測規則和樹結構。
為了合并此類特定于程序的信息,我們首先將代碼表示為規則序列,然后使用注意機制對規則進行編碼,最后使用樹卷積層將每個節點及其祖先的編碼表示形式組合在一起。
AST 表示
(1)規則序列嵌入:為了編碼規則信息,我們使用規則的 ID。假設我們有一個規則序列 r1,r2,...,rP,這些規則用于在解碼步驟中生成部分 AST,其中 P 表示序列的長度。我們通過查找表嵌入將這些規則表示為數值向量 r1,r2,...,rP。
(2)規則定義編碼:上面的表格查找嵌入將語法規則視為原子標記,并且會丟失該規則內容的信息。為了緩解此問題,我們使用規則定義的編碼來增強規則的表示形式。對于語法規則 i:α→β1·βK,其中 α 是父節點,β1·βK 是子節點。它們可以是終止符或非終止符。索引 i 是規則的 ID。與等式 2 相似,我們通過全連接層將規則內容編碼為向量 r(c),輸入是各個符號的查表嵌入 α,β1,...,βK。注意,該序列也被填充到最大長度。
(3)位置和深度編碼:由于我們的 AST 解碼器將使用 self-attention 機制,因此我們需要表示使用語法規則的位置。我們首先采用等式 4 中的位置嵌入,表示何時在序列 r1,...,rP 中使用規則。位置嵌入用 p1(r),...,pP(r)表示。但是,這種位置嵌入不能捕獲 AST 中規則的位置。我們通過深度嵌入進一步對此類信息進行編碼。如果我們通過規則 r 擴展符號 α:α→β1···βK,我們將通過其父節點即 α 表示規則的深度。通過這種方式,我們將查找表深度嵌入的另一序列 d1,...,dP 與使用的語法規則 r1,...,rP 的序列相關聯。
AST 編碼器的神經網絡結構:
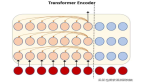
AST 編碼器還由一堆塊(總共 N1 個塊)組成。每個塊被分解為四個子層(即,self-attention,Gating 機制,NL-attention 和樹卷積)。除了樹卷積層之外,我們在每個子層周圍都采用了殘差連接。在每個子層之后,我們應用層歸一化。
(1) Self-attention:為了捕獲 AST 的信息,我們構建了一個類似 Transformer 的 self-attention 層,其中輸入是規則嵌入,位置嵌入和深度嵌入的總和,即 ri+di+p(r)i。self-attention 子層使用與公式 4、5、6 相同的機制來提取 AST 輸入的特征即 y(ast-self)1,y(ast-self)2,...,y(ast-self)P 不同的權重,但在 p(r)i 中增加了嵌入深度。
(2) Gating 機制:我們希望將內容編碼規則 y(rule)i 合并到 Transformer 的提取特征的部分中。我們采用方程式 8、9 中的 Gating 機制,在該子層之后,融合特征變為 y(ast-g)1,y(ast-g)2,...,y(ast-g)P。
(3) NL 注意力:在解碼步驟中,應將輸入的自然語言描述告知我們。這是由 Multi-headNL 給出的。所提取的特征由 y(ast-nl)1,y(ast-nl)2,…,y(ast-nl)P 表示。
(4) 樹卷積:如果我們僅考慮上述子層,那么讀者將很難將節點的信息與其祖先結合起來。在規則序列中,節點可以遠離其祖先,但結構緊密。因此,傳統的 Transformer 很難提取這種結構特征。我們將節點的特征與其祖先的特征進行組合。我們將 AST 視為圖形,并使用鄰接矩陣 M 表示有向圖。如果一個節點 αi 是 αj 的父節點,則 Mji=1。假設所有節點都由特征 f1,...,fn 表示,則它們的父節點的特征可以通過與鄰接矩陣相乘得出。總之,AST 解碼器具有這四個子層的 N1 個塊,并產生特征 y(ast)1,y(ast)2,...,y(ast)P。
解碼器:
我們的最后一個組件是一個解碼器,它將生成的代碼信息與自然語言描述集成在一起,并預測下一個語法規則。與 AST 編碼器類似,在解碼器中使用如下堆棧的塊堆棧(總共 N2 個塊),每個塊都有幾個子層。在每個子層周圍還采用殘余連接,然后進行層歸一化。解碼器將要擴展的非終止符作為 query,查詢節點表示為從根到要擴展的節點的路徑。例如,如果我們要擴展圖 1 中的節點“Assign”,則路徑應為 root,Module,body,Assign。我們將此路徑中的節點表示為數值向量。然后,將等式 2 之類的全連接層應用于這些向量,并且路徑的輸出為 qi。然后,我們應用兩個注意層來集成 AST 編碼器和 NL 編碼器的輸出。最后,應用兩個全連接層(其中第一層使用 GELU 激活函數)來提取特征以進行預測。
訓練以及推論:
我們根據解碼器的最后一層特征,通過 softmax 預測所有可能的候選詞中的下一個語法規則。我們還介紹了可以直接從自然語言描述中復制標記 a 的指針網絡(本質上是一種注意)。在這種情況下,生成的語法規則為 α→a,其中 α 是要擴展的非終止符,而 a 是終止符。這種指針機制對于用戶定義的標識符(例如,變量和函數名稱)很有幫助。具體選擇 softmax 或是指針網絡由另一個 Gating 機制 pg 給出,該值同樣由解碼器的最后一個特征計算得出。推理從起始規則 start:snode->root 開始,將特殊符號 snode 擴展到根符號。如果預測的 AST 中的每個葉節點都是終止符,則遞歸預測終止。在預測期間,我們使用大小為 5 的束搜索。在束搜索期間,將排除無效規則。
總結
在這項工作中,我們使用 TreeGen 生成程序。TreeGen 使用 Transformer 的注意力機制來緩解長期依賴問題,并引入 AST 編碼器以將語法規則和 AST 結構相結合。評估是在 Python 數據集爐石傳說和兩個語義解析數據集 ATIS 和 GEO 上進行的。實驗結果表明,我們的模型明顯優于現有方法。我們還進行了深入的消融測試,表明模型中的每個組件都發揮著重要作用。
致謝
本文由南京大學軟件學院 iSE 實驗室 2020 級碩士研究生曹振飛翻譯轉述。