一文看懂8個常用Python庫從安裝到應(yīng)用
如果讀者安裝的是Anaconda發(fā)行版,那么它已經(jīng)自帶了以下庫:NumPy、SciPy、Matplotlib、pandas、scikit-learn。

本文主要是對這些庫進(jìn)行簡單的介紹,讀者也可以到官網(wǎng)閱讀更加詳細(xì)的使用教程。
- NumPy:提供數(shù)組支持以及相應(yīng)的高效的處理函數(shù)
- SciPy:提供矩陣支持以及矩陣相關(guān)的數(shù)值計算模塊
- Matplotlib:強(qiáng)大的數(shù)據(jù)可視化工具、作圖庫
- pandas:強(qiáng)大、靈活的數(shù)據(jù)分析和探索工具
- StatsModels:統(tǒng)計建模和計量經(jīng)濟(jì)學(xué),包括描述統(tǒng)計、統(tǒng)計模型估計和推斷
- scikit-learn:支持回歸、分類、聚類等強(qiáng)大的機(jī)器學(xué)習(xí)庫
- Keras:深度學(xué)習(xí)庫,用于建立神經(jīng)網(wǎng)絡(luò)以及深度學(xué)習(xí)模型
- Gensim:用來做文本主題模型的庫,文本挖掘可能會用到
01 NumPy
Python并沒有提供數(shù)組功能。雖然列表可以完成基本的數(shù)組功能,但它不是真正的數(shù)組,而且在數(shù)據(jù)量較大時,使用列表的速度就會很慢。為此,NumPy提供了真正的數(shù)組功能以及對數(shù)據(jù)進(jìn)行快速處理的函數(shù)。
NumPy還是很多更高級的擴(kuò)展庫的依賴庫,我們后面介紹的SciPy、Matplotlib、pandas等庫都依賴于它。值得強(qiáng)調(diào)的是,NumPy內(nèi)置函數(shù)處理數(shù)據(jù)的速度是C語言級別的,因此在編寫程序的時候,應(yīng)當(dāng)盡量使用其內(nèi)置函數(shù),避免效率瓶頸的(尤其是涉及循環(huán)的問題)出現(xiàn)。
在Windows操作系統(tǒng)中,NumPy的安裝跟普通第三方庫的安裝一樣,可以通過pip命令進(jìn)行,命令如下:
- pip install numpy
也可以自行下載源代碼,然后使用如下命令安裝:
- python setup.py install
在Linux操作系統(tǒng)下,上述方法也是可行的。此外,很多Linux發(fā)行版的軟件源中都有Python常見的庫,因此還可以通過Linux系統(tǒng)自帶的軟件管理器安裝,如在Ubuntu下可以用如下命令安裝:
- sudo apt-get install python-numpy
安裝完成后,可以使用NumPy對數(shù)據(jù)進(jìn)行操作,如代碼清單2-27所示。
- 代碼清單2-27 使用NumPy操作數(shù)組
- # -*- coding: utf-8 -*
- import numpy as np # 一般以np作為NumPy庫的別名
- a = np.array([2, 0, 1, 5]) # 創(chuàng)建數(shù)組
- print(a) # 輸出數(shù)組
- print(a[:3]) # 引用前三個數(shù)字(切片)
- print(a.min()) # 輸出a的最小值
- a.sort() # 將a的元素從小到大排序,此操作直接修改a,因此這時候a為[0, 1, 2, 5]
- b= np.array([[1, 2, 3], [4, 5, 6]]) # 創(chuàng)建二維數(shù)組
- print(b*b) # 輸出數(shù)組的平方陣,即[[1, 4, 9], [16, 25, 36]]
NumPy是Python中相當(dāng)成熟和常用的庫,因此關(guān)于它的教程有很多,最值得一看的是其官網(wǎng)的幫助文檔,其次還有很多中英文教程,讀者遇到相應(yīng)的問題時,可以查閱相關(guān)資料。
參考鏈接:
http://www.numpy.org
http://reverland.org/python/2012/08/22/numpy
02 SciPy
如果說NumPy讓Python有了MATLAB的味道,那么SciPy就讓Python真正成為半個MATLAB了。NumPy提供了多維數(shù)組功能,但它只是一般的數(shù)組,并不是矩陣,比如當(dāng)兩個數(shù)組相乘時,只是對應(yīng)元素相乘,而不是矩陣乘法。SciPy提供了真正的矩陣以及大量基于矩陣運(yùn)算的對象與函數(shù)。
SciPy包含的功能有最優(yōu)化、線性代數(shù)、積分、插值、擬合、特殊函數(shù)、快速傅里葉變換、信號處理和圖像處理、常微分方程求解和其他科學(xué)與工程中常用的計算,顯然,這些功能都是挖掘與建模必需的。
SciPy依賴于NumPy,因此安裝之前得先安裝好NumPy。安裝SciPy的方式與安裝NumPy的方法大同小異,需要提及的是,在Ubuntu下也可以用類似的命令安裝SciPy,安裝命令如下:
- sudo apt-get install python-scipy
安裝好SciPy后,使用SciPy求解非線性方程組和數(shù)值積分,如代碼清單2-28所示。
- 代碼清單2-28 使用SciPy求解非線性方程組和數(shù)值積分
- # -*- coding: utf-8 -*
- # 求解非線性方程組2x1-x2^2=1,x1^2-x2=2
- from scipy.optimize import fsolve # 導(dǎo)入求解方程組的函數(shù)
- def f(x): # 定義要求解的方程組
- x1 = x[0]
- x2 = x[1]
- return [2*x1 - x2**2 - 1, x1**2 - x2 -2]
- result = fsolve(f, [1,1]) # 輸入初值[1, 1]并求解
- print(result) # 輸出結(jié)果,為array([ 1.91963957, 1.68501606])
- # 數(shù)值積分
- from scipy import integrate # 導(dǎo)入積分函數(shù)
- def g(x): # 定義被積函數(shù)
- return (1-x**2)**0.5
- pi_2, err = integrate.quad(g, -1, 1) # 積分結(jié)果和誤差
- print(pi_2 * 2) # 由微積分知識知道積分結(jié)果為圓周率pi的一半
參考鏈接:
http://www.scipy.org
http://reverland.org/python/2012/08/24/scipy
03 Matplotlib
不論是數(shù)據(jù)挖掘還是數(shù)學(xué)建模,都要面對數(shù)據(jù)可視化的問題。對于Python來說,Matplotlib是最著名的繪圖庫,主要用于二維繪圖,當(dāng)然也可以進(jìn)行簡單的三維繪圖。它不僅提供了一整套和MATLAB相似但更為豐富的命令,讓我們可以非常快捷地用Python可視化數(shù)據(jù),而且允許輸出達(dá)到出版質(zhì)量的多種圖像格式。
Matplotlib的安裝并沒有什么特別之處,可以通過“pip install matplotlib”命令安裝或者自行下載源代碼安裝,在Ubuntu下也可以用類似的命令安裝,命令如下:
- sudo apt-get install python-matplotlib
需要注意的是,Matplotlib的上級依賴庫相對較多,手動安裝的時候,需要逐一把這些依賴庫都安裝好。安裝完成后就可以牛刀小試了。下面是一個簡單的作圖例子,如代碼清單2-29所示,它基本包含了Matplotlib作圖的關(guān)鍵要素,作圖效果如圖2-5所示。
- 代碼清單2-29 Matplotlib作圖示例
- # -*- coding: utf-8 -*-
- import numpy as np
- import matplotlib.pyplot as plt # 導(dǎo)入Matplotlib
- x = np.linspace(0, 10, 1000) # 作圖的變量自變量
- y = np.sin(x) + 1 # 因變量y
- z = np.cos(x**2) + 1 # 因變量z
- plt.figure(figsize = (8, 4)) # 設(shè)置圖像大小
- plt.plot(x,y,label = '$\sin x+1$', color = 'red', linewidth = 2)
- # 作圖,設(shè)置標(biāo)簽、線條顏色、線條大小
- plt.plot(x, z, 'b--', label = '$\cos x^2+1$') # 作圖,設(shè)置標(biāo)簽、線條類型
- plt.xlabel('Time(s) ') # x軸名稱
- plt.ylabel('Volt') # y軸名稱
- plt.title('A Simple Example') # 標(biāo)題
- plt.ylim(0, 2.2) # 顯示的y軸范圍
- plt.legend() # 顯示圖例
- plt.show() # 顯示作圖結(jié)果
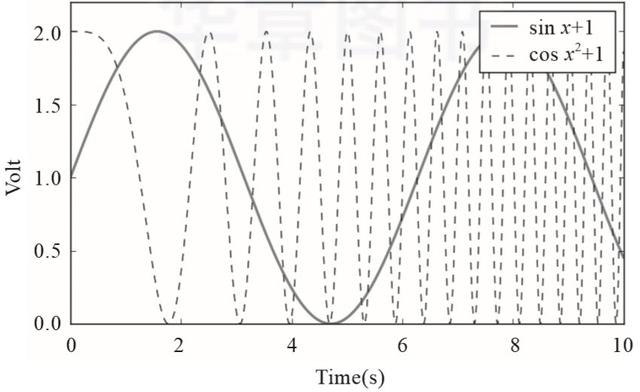
▲圖2-5 Matplotlib的作圖效果展示
如果讀者使用的是中文標(biāo)簽,就會發(fā)現(xiàn)中文標(biāo)簽無法正常顯示,這是因為Matplotlib的默認(rèn)字體是英文字體,解決方法是在作圖之前手動指定默認(rèn)字體為中文字體,如黑體(Sim-Hei),命令如下:
- plt.rcParams['font.sans-serif'] = ['SimHei'] # 用來正常顯示中文標(biāo)簽
其次,保存作圖圖像時,負(fù)號有可能不能顯示,對此可以通過以下代碼解決:
- plt.rcParams['axes.unicode_minus'] = False # 解決保存圖像是負(fù)號'-'顯示為方塊的問題
這里有一個小建議:有時間多去Matplotlib提供的“畫廊”欣賞用它做出的漂亮圖片,也許你就會慢慢愛上Matplotlib作圖了。
畫廊網(wǎng)址:
http://matplotlib.org/gallery.html
參考鏈接:
http://matplotlib.org
http://reverland.org/python/2012/09/07/matplotlib-tutorial
04 pandas
pandas是Python下最強(qiáng)大的數(shù)據(jù)分析和探索工具。它包含高級的數(shù)據(jù)結(jié)構(gòu)和精巧的工具,使得用戶在Python中處理數(shù)據(jù)非常快速和簡單。
pandas建造在NumPy之上,它使得以NumPy為中心的應(yīng)用使用起來更容易。pandas的名稱來自于面板數(shù)據(jù)(Panel Data)和Python數(shù)據(jù)分析(Data Analysis),它最初作為金融數(shù)據(jù)分析工具被開發(fā),由AQR Capital Management于2008年4月開發(fā)問世,并于2009年底開源出來。
pandas的功能非常強(qiáng)大,支持類似SQL的數(shù)據(jù)增、刪、查、改,并且?guī)в胸S富的數(shù)據(jù)處理函數(shù);支持時間序列分析功能;支持靈活處理缺失數(shù)據(jù);等等。事實上,單純地用pandas這個工具就足以寫一本書,讀者可以閱讀pandas的主要作者之一Wes Mc-Kinney寫的《利用Python進(jìn)行數(shù)據(jù)分析》來學(xué)習(xí)更詳細(xì)的內(nèi)容。
1. 安裝
pandas的安裝相對來說比較容易一些,只要安裝好NumPy之后,就可以直接安裝了,通過pip install pandas命令或下載源碼后通過python setup.py install命令安裝均可。
由于我們頻繁用到讀取和寫入Excel,但默認(rèn)的pandas還不能讀寫Excel文件,需要安裝xlrd(讀)度和xlwt(寫)庫才能支持Excel的讀寫。為Python添加讀取/寫入Excel功能的命令如下:
- pip install xlrd # 為Python添加讀取Excel的功能
- pip install xlwt # 為Python添加寫入Excel的功能
2. 使用
在后面的章節(jié)中,我們會逐步展示pandas的強(qiáng)大功能,而在本節(jié),我們先以簡單的例子一睹為快。
首先,pandas基本的數(shù)據(jù)結(jié)構(gòu)是Series和DataFrame。Series顧名思義就是序列,類似一維數(shù)組;DataFrame則相當(dāng)于一張二維的表格,類似二維數(shù)組,它的每一列都是一個Series。
為了定位Series中的元素,pandas提供了Index這一對象,每個Series都會帶有一個對應(yīng)的Index,用來標(biāo)記不同的元素,Index的內(nèi)容不一定是數(shù)字,也可以是字母、中文等,它類似于SQL中的主鍵。
類似的,DataFrame相當(dāng)于多個帶有同樣Index的Series的組合(本質(zhì)是Series的容器),每個Series都帶有一個唯一的表頭,用來標(biāo)識不同的Series。pandas中常用操作的示例如代碼清單2-30所示。
- 代碼清單2-30 pandas中的常用操作
- # -*- coding: utf-8 -*-
- import numpy as np
- import pandas as pd # 通常用pd作為pandas的別名。
- s = pd.Series([1,2,3], index=['a', 'b', 'c']) # 創(chuàng)建一個序列s
- # 創(chuàng)建一個表
- d = pd.DataFrame([[1, 2, 3], [4, 5, 6]], columns=['a', 'b', 'c'])
- d2 = pd.DataFrame(s) # 也可以用已有的序列來創(chuàng)建數(shù)據(jù)框
- d.head() # 預(yù)覽前5行數(shù)據(jù)
- d.describe() # 數(shù)據(jù)基本統(tǒng)計量
- # 讀取文件,注意文件的存儲路徑不能帶有中文,否則讀取可能出錯。
- pd.read_excel('data.xls') # 讀取Excel文件,創(chuàng)建DataFrame。
- pd.read_csv('data.csv', encoding='utf-8') # 讀取文本格式的數(shù)據(jù),一般用encoding指定編碼。
由于pandas是本書的主力工具,在后面將會頻繁使用它,因此這里不再詳細(xì)介紹,后文會更加詳盡地講解pandas的使用方法。
參考鏈接:
http://pandas.pydata.org/pandas-docs/stable/
05 StatsModels
pandas著重于數(shù)據(jù)的讀取、處理和探索,而StatsModels則更加注重數(shù)據(jù)的統(tǒng)計建模分析,它使得Python有了R語言的味道。StatsModels支持與pandas進(jìn)行數(shù)據(jù)交互,因此,它與pandas結(jié)合成為Python下強(qiáng)大的數(shù)據(jù)挖掘組合。
安裝StatsModels相當(dāng)簡單,既可以通過pip命令安裝,又可以通過源碼安裝。對于Windows用戶來說,官網(wǎng)上甚至已經(jīng)有編譯好的exe文件可供下載。如果手動安裝的話,需要自行解決好依賴問題,StatsModels依賴于pandas(當(dāng)然也依賴于pandas所依賴的庫),同時還依賴于Pasty(一個描述統(tǒng)計的庫)。
使用StatsModels進(jìn)行ADF平穩(wěn)性檢驗,如代碼清單2-31所示。
- 代碼清單2-31 使用StatsModels進(jìn)行ADF平穩(wěn)性檢驗
- # -*- coding: utf-8 -*-
- from statsmodels.tsa.stattools import adfuller as ADF # 導(dǎo)入ADF檢驗
- import numpy as np
- ADF(np.random.rand(100)) # 返回的結(jié)果有ADF值、p值等
參考鏈接:
http://statsmodels.sourceforge.net/stable/index.html
06 scikit-learn
從該庫的名字可以看出,這是一個與機(jī)器學(xué)習(xí)相關(guān)的庫。不錯,scikit-learn是Python下強(qiáng)大的機(jī)器學(xué)習(xí)工具包,它提供了完善的機(jī)器學(xué)習(xí)工具箱,包括數(shù)據(jù)預(yù)處理、分類、回歸、聚類、預(yù)測、模型分析等。
scikit-learn依賴于NumPy、SciPy和Matplotlib,因此,只需要提前安裝好這幾個庫,然后安裝scikit-learn基本上就沒有什么問題了,安裝方法跟前幾個庫的安裝一樣,可以通過pip install scikit-learn命令安裝,也可以下載源碼自行安裝。
使用scikit-learn創(chuàng)建機(jī)器學(xué)習(xí)的模型很簡單,示例如代碼清單2-32所示。
- 代碼清單2-32 使用scikit-learn創(chuàng)建機(jī)器學(xué)習(xí)模型
- # -*- coding: utf-8 -*-
- from sklearn.linear_model import LinearRegression # 導(dǎo)入線性回歸模型
- model = LinearRegression() # 建立線性回歸模型
- print(model)
1. 所有模型提供的接口有
對于訓(xùn)練模型來說是model.fit(),對于監(jiān)督模型來說是fit(X, y),對于非監(jiān)督模型是fit(X)。
2. 監(jiān)督模型提供如下接口
- model.predict(X_new):預(yù)測新樣本。
- model.predict_proba(X_new):預(yù)測概率,僅對某些模型有用(比如LR)。
- model.score():得分越高,fit越好。
3. 非監(jiān)督模型提供如下接口
- model.transform():從數(shù)據(jù)中學(xué)到新的“基空間”。
- model.fit_transform():從數(shù)據(jù)中學(xué)到新的基并將這個數(shù)據(jù)按照這組“基”進(jìn)行轉(zhuǎn)換。
Scikit-learn本身提供了一些實例數(shù)據(jù)供我們上手學(xué)習(xí),比較常見的有安德森鳶尾花卉數(shù)據(jù)集、手寫圖像數(shù)據(jù)集等。
安德森鳶尾花卉數(shù)據(jù)集有150個鳶尾花的尺寸觀測值,如萼片長度和寬度,花瓣長度和寬度;還有它們的亞屬:山鳶尾(iris setosa)、變色鳶尾(iris versicolor)和維吉尼亞鳶尾(iris virginica)。導(dǎo)入iris數(shù)據(jù)集并使用該數(shù)據(jù)訓(xùn)練SVM模型,如代碼清單2-33所示。
- 代碼清單2-33 導(dǎo)入iris數(shù)據(jù)集并訓(xùn)練SVM模型
- # -*- coding: utf-8 -*-
- from sklearn import datasets # 導(dǎo)入數(shù)據(jù)集
- iris = datasets.load_iris() # 加載數(shù)據(jù)集
- print(iris.data.shape) # 查看數(shù)據(jù)集大小
- from sklearn import svm # 導(dǎo)入SVM模型
- clf = svm.LinearSVC() # 建立線性SVM分類器
- clf.fit(iris.data, iris.target) # 用數(shù)據(jù)訓(xùn)練模型
- clf.predict([[ 5.0, 3.6, 1.3, 0.25]]) # 訓(xùn)練好模型之后,輸入新的數(shù)據(jù)進(jìn)行預(yù)測
- clf.coef_ # 查看訓(xùn)練好模型的參數(shù)
參考鏈接:
http://scikit-learn.org/stable/
07 Keras
scikit-learn已經(jīng)足夠強(qiáng)大了,然而它并沒有包含這一強(qiáng)大的模型—人工神經(jīng)網(wǎng)絡(luò)。人工神經(jīng)網(wǎng)絡(luò)是功能相當(dāng)強(qiáng)大但是原理又相當(dāng)簡單的模型,在語言處理、圖像識別等領(lǐng)域都有重要的作用。近年來逐漸流行的“深度學(xué)習(xí)”算法,實質(zhì)上也是一種神經(jīng)網(wǎng)絡(luò),可見在Python中實現(xiàn)神經(jīng)網(wǎng)絡(luò)是非常必要的。
本書用Keras庫來搭建神經(jīng)網(wǎng)絡(luò)。事實上,Keras并非簡單的神經(jīng)網(wǎng)絡(luò)庫,而是一個基于Theano的強(qiáng)大的深度學(xué)習(xí)庫,利用它不僅可以搭建普通的神經(jīng)網(wǎng)絡(luò),還可以搭建各種深度學(xué)習(xí)模型,如自編碼器、循環(huán)神經(jīng)網(wǎng)絡(luò)、遞歸神經(jīng)網(wǎng)絡(luò)、卷積神經(jīng)網(wǎng)絡(luò)等。由于它是基于Theano的,因此速度也相當(dāng)快。
Theano也是Python的一個庫,它是由深度學(xué)習(xí)專家Yoshua Bengio帶領(lǐng)的實驗室開發(fā)出來的,用來定義、優(yōu)化和高效地解決多維數(shù)組數(shù)據(jù)對應(yīng)數(shù)學(xué)表達(dá)式的模擬估計問題。它具有高效實現(xiàn)符號分解、高度優(yōu)化的速度和穩(wěn)定性等特點,最重要的是它還實現(xiàn)了GPU加速,使得密集型數(shù)據(jù)的處理速度是CPU的數(shù)十倍。
用Theano就可以搭建起高效的神經(jīng)網(wǎng)絡(luò)模型,然而對于普通讀者來說門檻還是相當(dāng)高的。Keras正是為此而生,它大大簡化了搭建各種神經(jīng)網(wǎng)絡(luò)模型的步驟,允許普通用戶輕松地搭建并求解具有幾百個輸入節(jié)點的深層神經(jīng)網(wǎng)絡(luò),而且定制的自由度非常大,讀者甚至因此驚呼:搭建神經(jīng)網(wǎng)絡(luò)可以如此簡單!
1. 安裝
安裝Keras之前首先需要安裝NumPy、SciPy和Theano。安裝Theano之前首先需要準(zhǔn)備一個C++編譯器,這在Linux系統(tǒng)下是自帶的。因此,在Linux系統(tǒng)下安裝Theano和Keras都非常簡單,只需要下載源代碼,然后用python setup.py install安裝就行了,具體可以參考官方文檔。
可是在Windows系統(tǒng)下就沒有那么簡單了,因為它沒有現(xiàn)成的編譯環(huán)境,一般而言是先安裝MinGW(Windows系統(tǒng)下的GCC和G++),然后再安裝Theano(提前裝好NumPy等依賴庫),最后安裝Keras,如果要實現(xiàn)GPU加速,還需要安裝和配置CUDA。
值得一提的是,在Windows系統(tǒng)下的Keras速度會大打折扣,因此,想要在神經(jīng)網(wǎng)絡(luò)、深度學(xué)習(xí)做深入研究的讀者,請在Linux系統(tǒng)下搭建相應(yīng)的環(huán)境。
參考鏈接:
http://deeplearning.net/software/theano/install.html#install
2. 使用
用Keras搭建神經(jīng)網(wǎng)絡(luò)模型的過程相當(dāng)簡單,也相當(dāng)直觀,就像搭積木一般,通過短短幾十行代碼,就可以搭建起一個非常強(qiáng)大的神經(jīng)網(wǎng)絡(luò)模型,甚至是深度學(xué)習(xí)模型。簡單搭建一個MLP(多層感知器),如代碼清單2-34所示。
- 代碼清單2-34 搭建一個MLP(多層感知器)
- # -*- coding: utf-8 -*-
- from keras.models import Sequential
- from keras.layers.core import Dense, Dropout, Activation
- from keras.optimizers import SGD
- model = Sequential() # 模型初始化
- model.add(Dense(20, 64)) # 添加輸入層(20節(jié)點)、第一隱藏層(64節(jié)點)的連接
- model.add(Activation('tanh')) # 第一隱藏層用tanh作為激活函數(shù)
- model.add(Dropout(0.5)) # 使用Dropout防止過擬合
- model.add(Dense(64, 64)) # 添加第一隱藏層(64節(jié)點)、第二隱藏層(64節(jié)點)的連接
- model.add(Activation('tanh')) # 第二隱藏層用tanh作為激活函數(shù)
- model.add(Dropout(0.5)) # 使用Dropout防止過擬合
- model.add(Dense(64, 1)) # 添加第二隱藏層(64節(jié)點)、輸出層(1節(jié)點)的連接
- model.add(Activation('sigmoid')) # 輸出層用sigmoid作為激活函數(shù)
- sgd = SGD(lr=0.1, decay=1e-6, momentum=0.9, nesterov=True) # 定義求解算法
- model.compile(loss='mean_squared_error', optimizer=sgd) # 編譯生成模型,損失函數(shù)為平均誤差平方和
- model.fit(X_train, y_train, nb_epoch=20, batch_size=16) # 訓(xùn)練模型
- score = model.evaluate(X_test, y_test, batch_size=16) # 測試模型
要注意的是,Keras的預(yù)測函數(shù)跟scikit-learn有所差別,Keras用model.predict()方法給出概率,用model.predict_classes()給出分類結(jié)果。
參考鏈接:
https://keras.io/
08 Gensim
在Gensim官網(wǎng)中,它對自己的簡介只有一句話:topic modelling for humans!
Gensim用來處理語言方面的任務(wù),如文本相似度計算、LDA、Word2Vec等,這些領(lǐng)域的任務(wù)往往需要比較多的背景知識。
在這一節(jié)中,我們只是提醒讀者有這么一個庫的存在,而且這個庫很強(qiáng)大,如果讀者想深入了解這個庫,可以去閱讀官方幫助文檔或參考鏈接。
值得一提的是,Gensim把Google在2013年開源的著名的詞向量構(gòu)造工具Word2Vec編譯好了,作為它的子庫,因此需要用到Word2Vec的讀者也可以直接使用Gensim,而無須自行編譯了。
Gensim的作者對Word2Vec的代碼進(jìn)行了優(yōu)化,所以它在Gensim下的表現(xiàn)比原生的Word2Vec還要快。(為了實現(xiàn)加速,需要準(zhǔn)備C++編譯器環(huán)境,因此,建議使用Gensim的Word2Vec的讀者在Linux系統(tǒng)環(huán)境下運(yùn)行。)
下面是一個Gensim使用Word2Vec的簡單例子,如代碼清單2-35所示。
- 代碼清單2-35 Gensim使用Word2Vec的簡單示例
- # -*- coding: utf-8 -*-
- import gensim, logging
- logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level= logging.INFO)
- # logging是用來輸出訓(xùn)練日志
- # 分好詞的句子,每個句子以詞列表的形式輸入
- sentences = [['first', 'sentence'], ['second', 'sentence']]
- # 用以上句子訓(xùn)練詞向量模型
- model = gensim.models.Word2Vec(sentences, min_count=1)
- print(model['sentence']) # 輸出單詞sentence的詞向量。
參考鏈接:
http://radimrehurek.com/gensim/