重點(diǎn)來了,Python網(wǎng)站爬蟲原理!瓜子,礦泉水備好,慢慢品!
話不多說,直接本主題!

如何于海量的互聯(lián)網(wǎng)網(wǎng)站中獲取有用資源信息,對(duì)網(wǎng)站的進(jìn)一步優(yōu)化有重要作用。為了提高網(wǎng)站資源獲取的準(zhǔn)確性及效率,本文提出一種基于Python的本地網(wǎng)站自動(dòng)化爬蟲程序設(shè)計(jì),采用搜索查詢工信部網(wǎng)站備案號(hào)呈現(xiàn)全量甘肅本地網(wǎng)站的方案,實(shí)現(xiàn)內(nèi)容爬取高效及全面。最后針對(duì)甘肅移動(dòng)資源進(jìn)行網(wǎng)站優(yōu)化,提高本地網(wǎng)站質(zhì)量。
Python網(wǎng)站爬蟲原理
基于Python網(wǎng)站爬取工具[2]包含網(wǎng)站爬取、網(wǎng)站分析、數(shù)據(jù)存儲(chǔ)共3個(gè)模塊,如圖1所示。
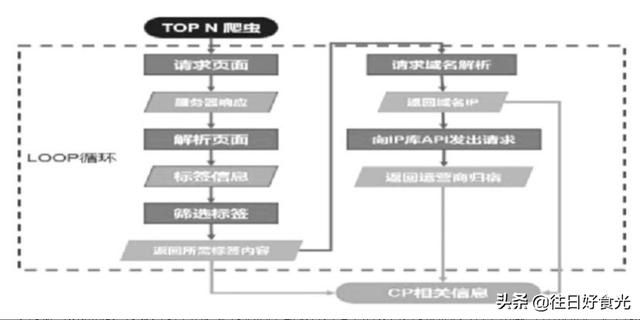
網(wǎng)站爬蟲程序流程
1.1 網(wǎng)站爬蟲方案
網(wǎng)站爬蟲系統(tǒng)通過搜索網(wǎng)站中的超鏈接信息不斷獲得網(wǎng)絡(luò)上的其它網(wǎng)站信息,并自動(dòng)篩選有用信息[。因此首先需要確定如何獲取網(wǎng)站信息,本文提出4種網(wǎng)站爬蟲方案。
1.1.1 DNS查詢方案
通過DNS系統(tǒng)訪問日志獲取。優(yōu)點(diǎn):網(wǎng)內(nèi)最準(zhǔn)確數(shù)據(jù)來源;缺點(diǎn):本地網(wǎng)站排名DNS解析次數(shù)TOP十萬以后。
1.1.2 CP流量排名查詢方案
通過亞馬遜免費(fèi)網(wǎng)站訪問量查詢。優(yōu)點(diǎn):按網(wǎng)站瀏覽量顯示,排名變化趨勢(shì)數(shù)據(jù)可查詢;缺點(diǎn):數(shù)據(jù)不全,以大型CP為主,本地網(wǎng)站無法統(tǒng)計(jì)。
1.1.3 搜索引擎排名查詢方案
通過百度、搜狗等搜索引擎查詢。優(yōu)點(diǎn):全網(wǎng)網(wǎng)站收錄較全;缺點(diǎn):存在CP付費(fèi)排名優(yōu)先的風(fēng)險(xiǎn),本地民生網(wǎng)站排名靠后。
1.1.4 工信部網(wǎng)站備案號(hào)查詢方案
通過工信部網(wǎng)站備案號(hào)查詢。優(yōu)點(diǎn):所有網(wǎng)站信息均通過工信部備案,全網(wǎng)數(shù)據(jù)最全;缺點(diǎn):部分網(wǎng)站可能本省DNS無解析數(shù)據(jù)。
通過分析四種方案的優(yōu)缺點(diǎn),本文選用基于工信部網(wǎng)站備案號(hào)查詢方案。
1.2 網(wǎng)站爬蟲流程
1.2.1 構(gòu)造網(wǎng)站
- url_base=″http://icp.chinaz.com/隴ICP備″+year_get+num+″號(hào)″
URL不同網(wǎng)站備案號(hào)不同,需通過程序構(gòu)造備案號(hào)完成遍歷。
1.2.2 獲取HTML信息

查看網(wǎng)頁(yè)源代碼,詳細(xì)處理涉及正則匹配等。
1.2.3提取網(wǎng)站域名

關(guān)聯(lián)提取網(wǎng)站全量有用信息。
1.2.4 DNS解析網(wǎng)站IP
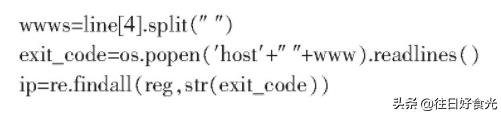
調(diào)用甘肅移動(dòng)公網(wǎng)DNS地址,實(shí)現(xiàn)批量DNS解析。
1.2.5獲取IP地址歸屬
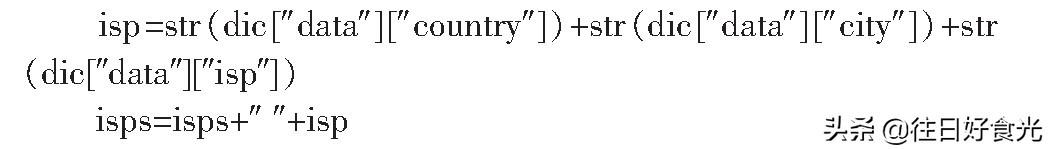
通過阿里API返回IP地址信息的json串,獲取IP地址歸屬。
1.2.6呈現(xiàn)網(wǎng)站信息

通過EXCEL導(dǎo)出全量網(wǎng)站信息。