5分鐘解讀Python中的鏈式調用
如果你是有打算從事有關數據分析或者數據挖掘的等數據科學領域的工作,或者和我一樣目前就是從事相關領域的工作,那么「鏈式調用」對我們而言是一門必修課。
為什么是鏈式調用?
鏈式調用,或者也可以稱為方法鏈(Method Chaining),從字面意思上來說就是將一些列的操作或函數方法像鏈子一樣穿起來的 Code 方式。
我最開始感知鏈式調用的「美」,還要從使用 R 語言的管道操作符開始。
- library(tidyverse)
- mtcars %>%
- group_by(cyl) %>%
- summarise(meanmeanOfdisp = mean(disp)) %>%
- ggplot(aes(x=as.factor(cyl), y=meanOfdisp, fill=as.factor(seq(1,3))))+
- geom_bar(stat = 'identity') +
- guides(fill=F)
對于 R user 來說,對于這一段代碼很快就能明白整個流程步驟是怎樣的。這一切都是通過符號%>%(管道操作符)談起。
通過管道操作符,我們可以將左邊事物傳遞給下一個事物。這里我將mtcars數據集傳遞到group_by 函數中,然后將得到后的結果再傳遞到summarize函數,最后傳遞到ggplot函數中進行可視化繪制。
如果我沒有學會鏈式調用,那么最開始學習 R 語言的我一定是這樣寫:
- library(tidyverse)
- cyl4 <- mtcars[which(mtcars$cyl==4), ]
- cyl6 <- mtcars[which(mtcars$cyl==6), ]
- cyl8 <- mtcars[which(mtcars$cyl==8), ]
- data <- data.frame(
- ccyl = c(4, 6, 8),
- meanOfdisp = c(mean(cyl4$disp), mean(cyl6$disp), mean(cyl8$disp))
- )
- graph <- ggplot(datadata=data, aes(x=factor(cyl), y=meanOfdisp,
- fill = as.factor(seq(1,3))))
- graph <- graph + geom_bar(stat = 'identity') + guides(fill=F)
- graph
如果不使用管道操作符,那么我將會進行不必要的賦值,并且覆蓋原有的數據對象,但其實當中產生的cyl#、data 其實最后都只是為graph 這一張圖片所服務的,因此導致的問題就是代碼會變得冗余。
鏈式調用在極大程度簡潔代碼的同時,也提高了代碼的可讀性,能夠很快速地了解到每一步都是在做什么。這種方式對于做數據分析或處理數據時是十分有用,減少創建不必要的變量時,能夠以快速、簡單的方式進行探索。
你能在很多地方見到鏈式調用或者管道操作的身影,這里我舉除了 R 語言以外的兩個典型例子。
一個是 Shell 語句:
- echo "`seq 1 100`" | grep -e "^[3-4].*" | tr "3" "*"
在 shell 語句中使用「|」管道操作符能夠快速地實現鏈式調用,這里我首先是打印1-100的所有整數,然后將其傳入到grep方法中,提取由 3 或 4 開頭的所有部分,再將這部分傳入到tr 方法中,并對數字包含 3 的部分用星號替換。結果如下:
另外一個是 Scala 語言:
- object Test {
- def main(args: Array[String]): Unit = {
- val numOfseq = (1 to 100).toList
- val chain = numOfseq.filter(_%2==0)
- .map(_*2)
- .take(10)
- }
- }
在這段示例中,首先numOfseq 這個變量包含了從 1-100 的所有整數,然后從chain部分開始,我首先在numOfseq的基礎上調用了filter 方法,用以篩選這些數字中為偶數的部分,其次在調用map 方法,將這些被篩選出來的數乘以 2,最后使用take 方法從新構成的數字中取出前 10 個數,這些數共同賦值給了chain 變量。
通過以上的敘述,相信你能對鏈式調用有一個初步的印象,但是一旦你掌握了鏈式調用,那么除了會讓你的代碼風格有所改變以外,你的編程思維也會有不一樣的提升。
Python 中的鏈式調用
在 Python 中實現一個簡單的鏈式調用就是通過構建類方法并返回對象自身或返回歸屬類(@classmethod)
- class Chain:
- def __init__(self, name):
- self.name = name
- def introduce(self):
- print("hello, my name is %s" % self.name)
- return self
- def talk(self):
- print("Can we make a friend?")
- return self
- def greet(self):
- print("Hey! How are you?")
- return self
- if __name__ == '__main__':
- chain = Chain(name = "jobs")
- chain.introduce()
- print("-"*20)
- chain.introduce().talk()
- print("-"*20)
- chain.introduce().talk().greet()
在這里我們創建一個Chain 類,需要傳遞一個name 字符串參數進行實例對象的創建;當中這個類里有三個方法,分別是introduce、talk以及greet。
由于每次返回的是self 自身,那么我們就可以源源不斷地調用對象歸屬類中的方法,結果如下:
- hello, my name is jobs
- --------------------
- hello, my name is jobs
- Can we make a friend?
- --------------------
- hello, my name is jobs
- Can we make a friend?
- Hey! How are you?
在 Pandas 中使用鏈式調用
前面鋪墊了這么多終于談到有關于 Pandas 鏈式調用部分
Pandas 中的大部分方法都很適合使用鏈式方法進行操作,因為經過 API 處理后返回的往往還是 Series 類型或 DataFrame 類型,所以我們可以直接就調用相應的方法,這里我以我在今年 2 月份左右給別人做案例演示時爬取到的華農兄弟 B 站視頻數據為例。可以通過鏈接進行獲取。
數據字段信息如下所示,里面有 300 條數據,并且 20 個字段:
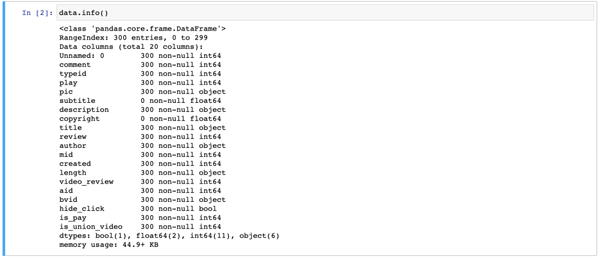
字段信息
但在使用這部分數據之前,我們還需要對這部分數據進行初步的清洗,這里我主要選取了以下字段:
- aid:視頻對應的 av 號
- comment:評論數
- play:播放量
- title:標題
- video_review:彈幕數
- created:上傳日期
- length:視頻時長
1、數據清洗
各字段對應的值如下所示:
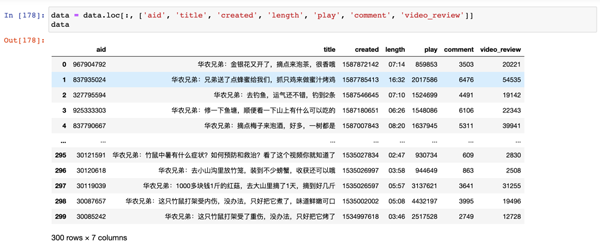
字段值
從數據中我們可以看到:
- title 字段前面都會帶有「華農兄弟」四個字,如果對標題字數進行統計時需要預先去除;
- created 上傳日期似乎顯示成了一長串的數值,但其實是從 1970 至今的時間戳,我們需要處理成可讀懂的年月日形式;
- length 播放量長度只顯示了分秒,但是小時并未用「00」來進行補全,因此這里我們一方面需要將其補全,另一方面要將其轉換成對應的時間格式
鏈式調用操作如下:
- import re
- import pandas as pd
- # 定義字數統計函數
- def word_count(text):
- return len(re.findall(r"[\u4e00-\u9fa5]", text))
- tidy_data = (
- pd.read_csv('~/Desktop/huanong.csv')
- .loc[:, ['aid', 'title', 'created', 'length',
- 'play', 'comment', 'video_review']]
- .assign(title = lambda df: df['title'].str.replace("華農兄弟:", ""),
- title_count = lambda df: df['title'].apply(word_count),
- created = lambda df: df['created'].pipe(pd.to_datetime, unit='s'),
- created_date = lambda df: df['created'].dt.date,
- length = lambda df: "00:" + df['length'],
- video_length = lambda df: df['length'].pipe(pd.to_timedelta).dt.seconds
- )
- )
這里首先是通過loc方法挑出其中的列,然后調用assign方法來創建新的字段,新的字段其字段名如果和原來的字段相一致,那么就會進行覆蓋,從assign中我們可以很清楚地看到當中字段的產生過程,同lambda 表達式進行交互:
1.title 和title_count:
- 原有的title字段因為屬于字符串類型,可以直接很方便的調用str.* 方法來進行處理,這里我就直接調用當中的replace方法將「華農兄弟:」字符進行清洗
- 基于清洗好的title 字段,再對該字段使用apply方法,該方法傳遞我們前面實現定義好的字數統計的函數,對每一條記錄的標題中,對屬于\u4e00到\u9fa5這一區間內的所有 Unicode 中文字符進行提取,并進行長度計算
2.created和created_date:
- 對原有的created 字段調用一個pipe方法,該方法會將created 字段傳遞進pd.to_datetime 參數中,這里需要將unit時間單位設置成s秒才能顯示出正確的時間,否則仍以 Unix 時間錯的樣式顯示
- 基于處理好的created 字段,我們可以通過其屬于datetime64 的性質來獲取其對應的時間,這里 Pandas 給我們提供了一個很方便的 API 方法,通過dt.*來拿到當中的屬性值
3.length 和video_length:
- 原有的length 字段我們直接讓字符串00:和該字段進行直接拼接,用以做下一步轉換
- 基于完整的length時間字符串,我們再次調用pipe方法將該字段作為參數隱式傳遞到pd.to_timedelta方法中轉化,然后同理和create_date字段一樣獲取到相應的屬性值,這里我取的是秒數。
2、播放量趨勢圖
基于前面稍作清洗后得到的tidy_data數據,我們可以快速地做一個播放量走勢的探索。這里我們需要用到created這個屬于datetime64的字段為 X 軸,播放量play 字段為 Y 軸做可視化展示。
- # 播放量走勢
- %matplotlib inline
- %config InlineBackend.figure_format = 'retina'
- import matplotlib.pyplot as plt
- (tidy_data[['created', 'play']]
- .set_index('created')
- .resample('1M')
- .sum()
- .plot(
- kind='line',
- figsize=(16, 8),
- title='Video Play Prend(2018-2020)',
- grid=True,
- legend=False
- )
- )
- plt.xlabel("")
- plt.ylabel('The Number Of Playing')
這里我們將上傳日期和播放量兩個選出來后,需要先將created設定為索引,才能接著使用resample重采樣的方法進行聚合操作,這里我們以月為統計顆粒度,對每個月播放量進行加總,之后再調用plot 接口實現可視化。
鏈式調用的一個小技巧就是,可以利用括號作用域連續的特性使整個鏈式調用的操作不會報錯,當然如果不喜歡這種方式也可以手動在每條操作后面追加一個\符號,所以上面的整個操作就會變成這樣:
- tidy_data[['created', 'play']] \
- .set_index('created') \
- .resample('1M')
- .sum()
- .plot( \
- kind='line', \
- figsize=(16, 8), \
- title='Video Play Prend(2018-2020)', \
- grid=True, \
- legend=False \
- )
但是相比于追加一對括號來說,這種尾部追加\符號的方式并不推薦,也不優雅。
但是如果既沒有在括號作用域或未追加\ 符號,那么在運行時 Python 解釋器就會報錯。
3、鏈式調用性能
通過前兩個案例我們可以看出鏈式調用可以說是比較優雅且快速地能實現一套數據操作的流程,但是鏈式調用也會因為不同的寫法而存在性能上的差異。
這里我們繼續基于前面的tidy_data操作,這里我們基于created_date 來對play、comment和video_review進行求和后的數值進一步以 10 為底作對數化。最后需要得到以下結果:
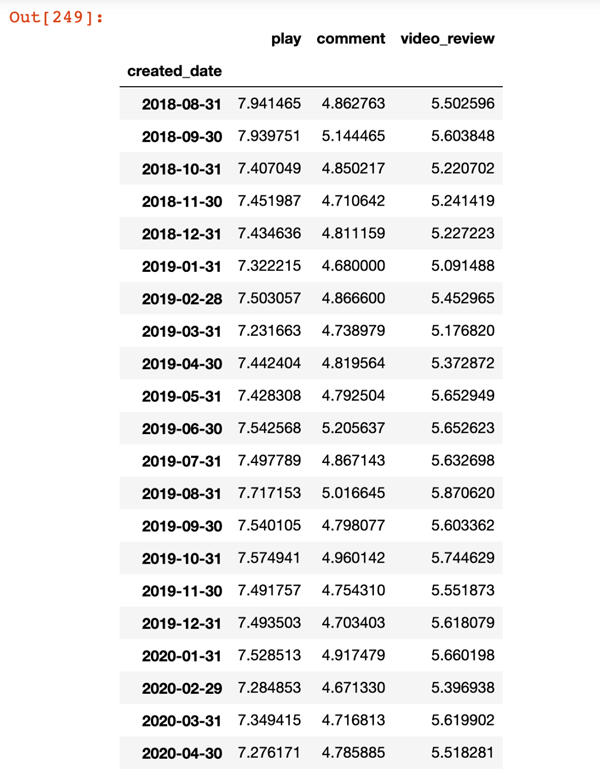
統計表格
寫法一:一般寫法

一般寫法
這種寫法就是基于tidy_data拷貝后進行操作,操作得到的結果會不斷地覆蓋原有的數據對象
寫法二:鏈式調用寫法
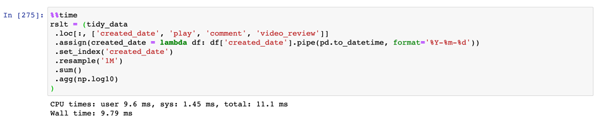
鏈式調用寫法
可以看到,鏈式調用的寫法相比于一般寫法而言會快上一點,不過由于數據量比較小,因此二者時間的差異并不大;但鏈式調用由于不需要額外的中間變量已經覆蓋寫入步驟,在內存開銷上會少一些。
結尾:鏈式調用的優劣
從本文的只言片語中,你能領略到鏈式調用使得代碼在可讀性上大大的增強,同時以盡肯能少的代碼量去實現更多操作。
當然,鏈式調用并不算是完美的,它也存在著一定缺陷。比如說當鏈式調用的方法超過 10 步以上時,那么出錯的幾率就會大幅度提高,從而造成調試或 Debug 的困難。比如這樣:
- (data
- .method1(...)
- .method2(...)
- .method3(...)
- .method4(...)
- .method5(...)
- .method6(...)
- .method7(...) # Something Error
- .method8(...)
- .method9(...)
- .method10(...)
- .method11(...)
- )
你只能從鏈式調用方法體中「從尾倒頭」一步一步地去重現發生問題的地方在哪。
因此使用鏈式調用時,一定必須要考慮以下問題:
- 是否需要中間變量
- 操作數據中的步驟是否需要分解
- 每次操作后的結果是否仍為 DataFrame 類型
如果不需要中間變量、步驟不需要分解且保證最后返回的就是 DataFrame 類型,那么就愉快地使用鏈式調用方法來完成你的數據流程吧!