幾種常用(閉源、開源)關(guān)系型數(shù)據(jù)庫的架構(gòu)和實現(xiàn)原理解讀
一、 Oracle
(一) Oracle 架構(gòu)
Oracle Server包括數(shù)據(jù)庫(Database)和實例(Instance)兩大部分,兩者相互獨立。數(shù)據(jù)庫由數(shù)據(jù)文件 、控制文件和日志文件組成,實例由內(nèi)存池和后臺進程組成,示意圖如下:
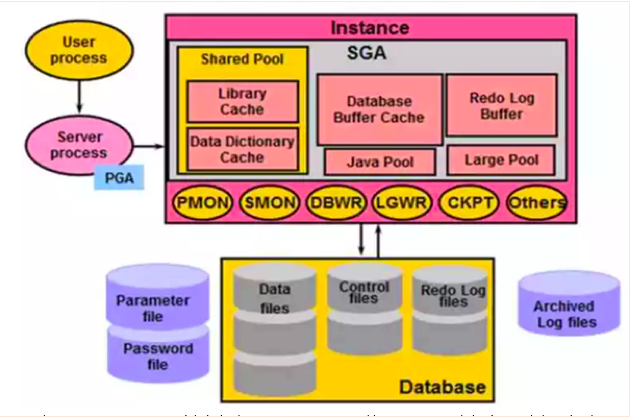
一臺Oracle Server可創(chuàng)建多個Database,不同的Database之間相互獨立。每個Database有屬于自己的全套相關(guān)文件,如:密碼文件,參數(shù)文件,數(shù)據(jù)文件,控制文件和日志文件
Database由一系列物理文件(如二維表文件)組成。用戶不能直接讀取Database中的內(nèi)容,必須通過Oracle instance才能讀取,一個Instance只能連接一個Database,但是一個Database可以被多個Instance連接。
各功能組件說明如下:
1、用戶連接進程
用戶連接進程是連接用戶和Oracle Instance的橋梁。包括:用戶進程、服務(wù)進程和PGA
- 用戶進程User Process
當一個Database User請求連接到Oracle Server時,Oracle Server創(chuàng)建的User Process。
- Server Process服務(wù)進程
用于處理Database User和Oracle Server之間的連接。
- 程序全局區(qū)PGA
PGA:由Server Process分配,用于當前User Session的內(nèi)存區(qū),不同的用戶擁有不同的PGA。PGA包含了Server Process數(shù)據(jù)和控制信息的內(nèi)存區(qū)域。包括棧空間、 Session Info、 私有SQL區(qū)。
2、SGA(System Global Area)
SGA與Oracle性能息息相關(guān),在Instance啟動時被分配,關(guān)閉時被釋放。主要包含如下幾種數(shù)據(jù)結(jié)構(gòu):
- 數(shù)據(jù)庫緩沖區(qū)(Database buffer cache)
oracle 執(zhí)行SQL語句的區(qū)域。當進行數(shù)據(jù)更新或數(shù)據(jù)查詢時,用戶執(zhí)行的SQL語句不會直接對磁盤上的數(shù)據(jù)文件進行更改操作,而是首先將數(shù)據(jù)文件復(fù)制到數(shù)據(jù)庫緩沖區(qū)緩存,再更改或查詢緩存中的副本。此外,被頻繁訪問的數(shù)據(jù)塊會存在于數(shù)據(jù)庫緩沖區(qū)緩存中。
- 日志緩沖區(qū)(Redo log Buffer)
用于短期存儲redo log。
- 共享池(Shared Pool)
用于緩存所有頻繁執(zhí)行的代碼和頻繁訪問的對象定義。共享池內(nèi)有下列三種數(shù)據(jù)結(jié)構(gòu):
庫緩沖(library cache):存儲最近執(zhí)行的代碼
數(shù)據(jù)字典緩存(data dictionary cache):存儲最近使用的對象定義
PL/SQL緩沖區(qū)(PL/SQL buffer):用于存儲過程、函數(shù)、打包的過程、打包的函數(shù)、對象類型定義和觸發(fā)器。
- 大型池(Large Buffer)
用于共享的服務(wù)器進程。
- JAVA池(Java Buffer):
只有當應(yīng)用程序需要在數(shù)據(jù)庫中運行java存儲程序時,才需要java池。
3、后臺進程
后臺進程主要用于數(shù)據(jù)庫管理 ,是Oracle Instance和Oracle Database的聯(lián)系紐帶,分為核心進程和非核心進程。
1) 核心進程:
- 數(shù)據(jù)庫寫入進程(DBWn)
Server process連接Oracle后,通過數(shù)據(jù)庫寫進程(DBWn)將數(shù)據(jù)緩沖區(qū)中的“臟緩沖區(qū)” 的數(shù)據(jù)塊寫入到數(shù)據(jù)文件;
- 檢查點進程(CKPT)
Checkpoint (CKPT)檢查點進程主要用于更新數(shù)據(jù)文件頭,更新控制文件和觸發(fā)DBWn數(shù)據(jù)庫寫進程。
- 進程監(jiān)視進程(PMON)
當后臺進程執(zhí)行失敗后負責清理數(shù)據(jù)庫緩存和閑置資源,是Oracle的自動維護機制。
- 系統(tǒng)監(jiān)視進程(SMON)
用途如下:
當數(shù)據(jù)庫實例崩潰時,用于數(shù)據(jù)庫實例的自動恢復(fù)。
清除作廢的排序臨時段,回收整理碎片,合并空閑空間,釋放臨時段,維護閃回的時間點。
- 重做日志文件和日志寫入進程
用于記錄數(shù)據(jù)庫的改變和記錄數(shù)據(jù)庫被改變之前的原始狀態(tài),當滿足以下條件時,激活LGWR:
提交指令
日志緩沖區(qū)超過1/3
每三秒
每次DBWn執(zhí)行之前
2) 非核心進程
- 歸檔進程(ARCn)
是可選的后臺進程,當數(shù)據(jù)庫處于ArchiveLog模式時,自動歸檔redo log,并保存數(shù)據(jù)庫的所有修改記錄。
SGA(System Global Area)和后臺進程組成Instance。
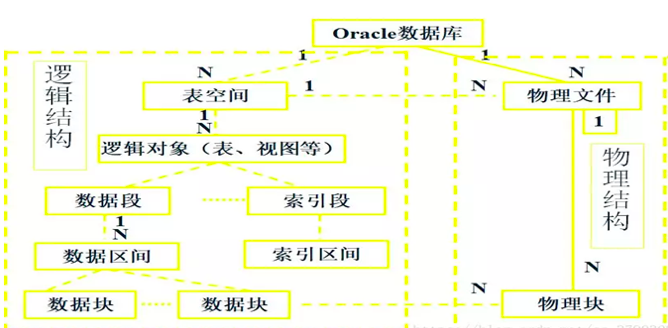
4、存儲結(jié)構(gòu)
存儲結(jié)構(gòu)可從物理結(jié)構(gòu)和邏輯結(jié)構(gòu)兩方面理解。
1) 物理結(jié)構(gòu)
Database物理結(jié)構(gòu):是Database在操作系統(tǒng)中的文件集合,即:磁盤上的物理文件,主要由數(shù)據(jù)文件、控制文件、重做日志文件、歸檔日志文件、參數(shù)文件、口令文件組成。
數(shù)據(jù)文件、重做日志文件、控制文件、跟蹤文件、警告文件屬于數(shù)據(jù)庫文件
- Data Files
數(shù)據(jù)文件是數(shù)據(jù)的存儲倉庫,數(shù)據(jù)被使用時才被調(diào)入內(nèi)存中的。
- Redo Log Files
重做日志文件包含對數(shù)據(jù)庫所做的更改操作記錄,在Oracle發(fā)生故障時能夠恢復(fù)數(shù)據(jù)。
- Control Files
控制文件包含維護和驗證數(shù)據(jù)庫完整性的必要的信息。例如,控制文件用于識別數(shù)據(jù)文件和重做日志文件,一個數(shù)據(jù)庫至少需要一個控制文件。
- 跟蹤文件 (Trace Files)
在instance 中運行的每一個后臺進程都有一個跟蹤文件(trace file)與之相連。Trace file記載后臺進程所遇到的重大事件的信息。
- 警告日志( Alert Log)
是一種特殊的跟蹤文件,每個數(shù)據(jù)庫都有一個跟蹤文件,同步記載數(shù)據(jù)庫的消息和錯誤。
參數(shù)文件、口令文件、歸檔文件屬于非數(shù)據(jù)庫文件。
- Parameter File
實例參數(shù)文件,當啟動oracle實例時,SGA結(jié)構(gòu)會根據(jù)此參數(shù)文件的設(shè)置內(nèi)存,后臺進程會據(jù)此啟動。
- Password File
用戶通過提交username/password來建立會話,Oracle根據(jù)存儲在數(shù)據(jù)字典的用戶定義對用戶名和口令進行驗證。
- 歸檔文件
是重做日志文件的脫機副本,這些副本可能對于從介質(zhì)失敗中進行恢復(fù)很必要。
2) 邏輯結(jié)構(gòu)
- 表空間
用于存儲數(shù)據(jù)庫對象的邏輯空間,是信息存儲的最大邏輯單位,是一系列數(shù)據(jù)文件的集合。一個數(shù)據(jù)庫可以由多個表空間組成,每個表空間包括多個段。
- 段:
是對象在數(shù)據(jù)庫中占用的空間。段是區(qū)的集合
- 區(qū):
是為數(shù)據(jù)一次性預(yù)留的一個較大的存儲空間,區(qū)是塊的集合
- 塊:
ORACLE最基本的存儲單位,在建立數(shù)據(jù)庫的時候指定,并被映射到磁盤塊。
3) 邏輯空間到物理空間的映射
(二) Oracle RDBMS的運行過程
1. User訪問Oracle Server之前提交一個請求(包含了db_name、password、instance_name、username等信息);
2. Oracle Server接收到請求并通過Password File的驗證后,分配SGA內(nèi)存池,啟動后臺進程同時創(chuàng)建并啟動實例;
3. 啟動實例之后,User Process與Server Process建立Connect;
4. Server process和Oracle Instance建立Sesscion,隨后接收用戶請求,執(zhí)行相關(guān)操作;
(三) 寫SQL語句的執(zhí)行過程
1. 用戶執(zhí)行SQL語句,Server process收到后,將SQL語句送到Instance,再將SQL語句載入數(shù)據(jù)庫緩沖區(qū)。
2. Server Process通知Oracle Database將與SQL語句相關(guān)的數(shù)據(jù)塊副本加載到緩沖區(qū)中。
3. 在數(shù)據(jù)庫緩存區(qū)執(zhí)行SQL語句,修改數(shù)據(jù)文件副本,形成“臟緩沖區(qū)”
4. CKPT檢查到”臟緩沖區(qū)”,調(diào)用DBWn數(shù)據(jù)庫寫進程,
5. 在DBWn運行之前,先運行了LGWR,將數(shù)據(jù)文件的原始狀態(tài)和數(shù)據(jù)庫的改變記錄到Redo Log Files
6. 運行DBWn,將“臟緩沖區(qū)的內(nèi)容寫入到數(shù)據(jù)文件”
7. 同時CKPT修改控制文件和數(shù)據(jù)文件頭
8. SMON回收不必要的空閑資源
9. 返回結(jié)果給用戶
(四) Oracle的高可用性架構(gòu)
1. Oracle RAC(Real Application Clusters)
RAC 是 Oracle 數(shù)據(jù)庫的一個群集解決方案,包括計算層和存儲層。如下圖所示:
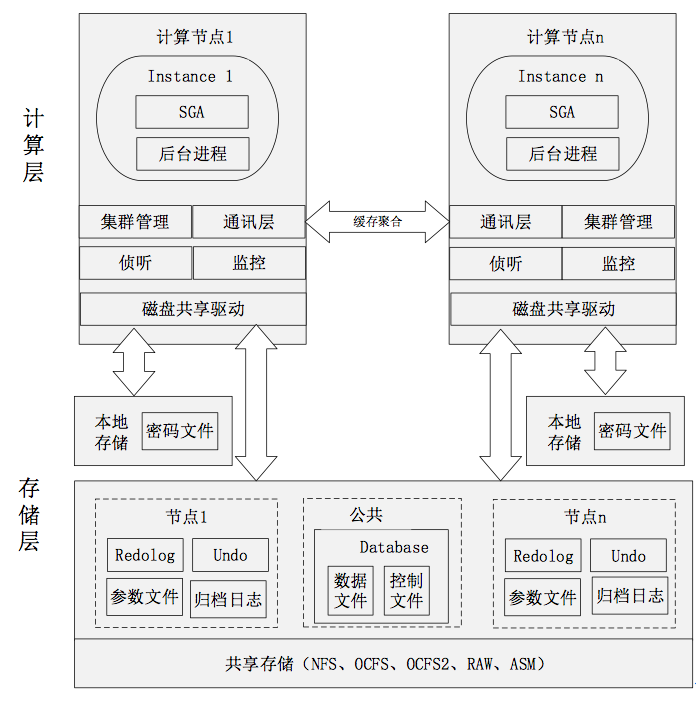
1) 存儲層——共享存儲
Oracle RAC的核心是共享磁盤子系統(tǒng),集群中所有節(jié)點必須能夠訪問所有數(shù)據(jù)文件、重做日志文件、控制文件和參數(shù)文件,因此,這些文件必須存放在共享存儲中。常用的共享存儲方式有OCFS、OCFS2、RAW、NFS、ASM 等。說明如下:
OCFS(Oracle Cluster File System) 和 OCFS2 都是文件系統(tǒng),和 NFS 一樣,提供集群環(huán)境共享存儲的文件系統(tǒng)。
RAW 裸設(shè)備也是一種存儲方式。把共享存儲映射到 RAW Device,Oracle在存儲數(shù)據(jù)時,選擇 RAW device存儲即可。但相對于文件系統(tǒng)來說, RAW不直觀,不便于管理,而且有數(shù)量的限制,現(xiàn)已被OCFS取代。
ASM 是一種數(shù)據(jù)庫存儲的方案,并不是 cluster 的方案,使用 ASM 時,還需使用OCFS/OCFS2 或RAW。
2) 計算層
計算層至少需要兩臺以上的服務(wù)器,在每臺服務(wù)器上安裝集群軟件和Oracle的 RAC 組件,從邏輯結(jié)構(gòu)上看,每個節(jié)點都有一個獨立的實例,這些實例訪問同一個數(shù)據(jù)庫。節(jié)點之間通過集群軟件的通信層(Communication Layer)進行通信,利用高速緩存合并技術(shù),實現(xiàn)集群中各節(jié)點緩存的高速同步,使得集群中的每個實例,都保留了一份相同的數(shù)據(jù)庫 cache。從而最大限度地低降低磁盤I/O。因此,RAC有如下特點:
每一個節(jié)點的實例都有自己的 SGA;
每一個節(jié)點的實例都有自己的后臺進程
每一個節(jié)點的實力都有自己的 redo logs
每一個節(jié)點的實例都有自己的 undo 表空間
所有節(jié)點都共享一份 datafiles 和 controlfiles
2、Data Guard
在Data Gurad 環(huán)境中,至少有兩個數(shù)據(jù)庫,一個主庫(Primary Database)處于Open 狀態(tài),另一個備庫(Standby Database)處于standby狀態(tài)。
備庫又分物理庫和邏輯庫。物理庫和主庫完全一樣,通過REDO應(yīng)用來保持與主庫的數(shù)據(jù)一致性,支持只讀服務(wù);邏輯庫通過SQL應(yīng)用,在備庫端執(zhí)行和主庫同樣的SQL語句,以此來保持與主庫的數(shù)據(jù)一致,因此文件的物理結(jié)構(gòu)(甚至數(shù)據(jù)的邏輯結(jié)構(gòu))都可以與主庫不一致。邏輯庫支持讀寫服務(wù)。
Data Guard適合多機房方案,實際部署時,主庫部署在主機房,備庫部署在其他機房。
二、 MySQL
(一) MySQL架構(gòu)

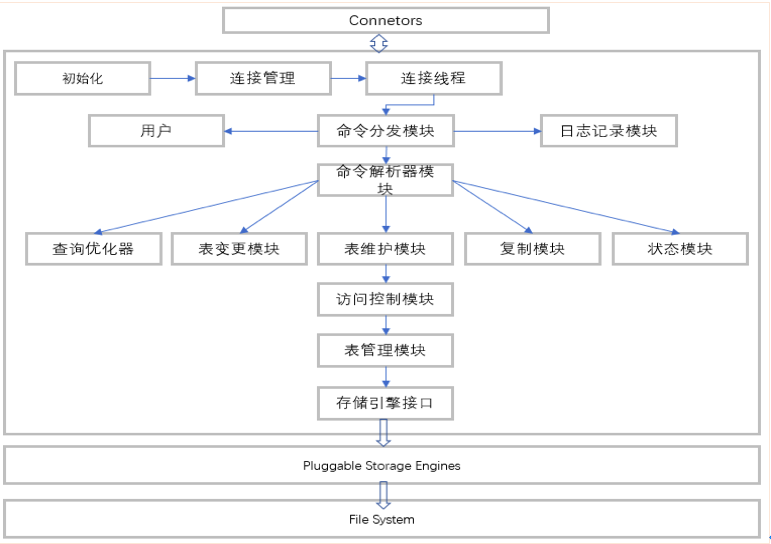
1、連接器(Connectors)
MySQL向外提供的接口,如java,.net,php等語言可以通過該組件來操作SQL語句,實現(xiàn)與SQL的交互。
2、管理服務(wù)組件和工具組件(Management Service & Utilities)
提供對MySQL的集成管理,如備份(Backup),恢復(fù)(Recovery),安全管理(Security)等
3、連接池組件(Connection Pool)
負責監(jiān)聽對客戶端向MySQL Server端的各種請求,接收請求,轉(zhuǎn)發(fā)請求到目標模塊。每個成功連接MySQL Server的客戶請求都會被創(chuàng)建或分配一個線程,該線程負責客戶端與MySQL Server端的通信,接收客戶端發(fā)送的命令,傳遞服務(wù)端的結(jié)果信息等。
4、SQL接口組件(SQL Interface)
接收用戶SQL命令,如DML,DDL和存儲過程等,并將最終結(jié)果返回給用戶。
5、查詢分析器組件(Parser)
首先分析SQL命令語法的合法性,并嘗試將SQL命令分解成數(shù)據(jù)結(jié)構(gòu),若分解失敗,則提示SQL語句不合理。
6、優(yōu)化器組件(Optimizer)
對SQL命令按照標準流程進行優(yōu)化分析。
7、緩存主件(Caches & Buffers)
緩存和緩沖組件
8、MySQL存儲引擎
MySQL屬于關(guān)系型數(shù)據(jù)庫,而關(guān)系型數(shù)據(jù)庫的存儲是以表的形式進行的,對于表的創(chuàng)建,數(shù)據(jù)的存儲,檢索,更新等都是由MySQL存儲引擎完成的。
因MySQL的開源性,允許第三方基于MySQL骨架,開發(fā)適合自己業(yè)務(wù)需求的存儲引擎。因此,MySQL支持的存儲引擎種類較多,可以分為官方存儲引擎和第三方存儲引擎。
當前,MySQL的存儲引擎有MyISAM、InnoDB、NDB、Archive、Federated、Memory、Merge、Parter、Community、Custom等。其中,比較常用的存儲引擎包括InnoDB、MyISAM和Momery。
9、物理文件(File System)
實際存儲MySQL數(shù)據(jù)庫文件和一些日志文件等的系統(tǒng),如Linux,Unix,Windows等。
(二) 一個查詢流程圖
(三) MySQL的高可用架構(gòu)
因MySQL的開源屬性,其高可用架構(gòu)非常靈活,目前常用的主要有以下幾種:
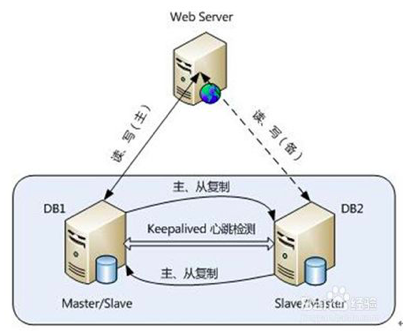
1、主從復(fù)制模式
這是MySQL自身提供的一種高可用解決方案,數(shù)據(jù)同步方法采用的是MySQL replication技術(shù)。為了達到更高的可用性,在實際的應(yīng)用環(huán)境中,需要配合高可用集群軟件keepalived來實現(xiàn)自動failover,否則,需要手工切換。
2、MHA(Master High Availability)
MHA是相對成熟的高可用解決方案,該軟件由兩部分組成:MHA Manager(管理節(jié)點)和MHA Node(數(shù)據(jù)節(jié)點)。搭建MHA時,要求一個集群必須最少有三臺數(shù)據(jù)庫服務(wù)器,一主二從(即一臺master,一臺備用master,另外一臺slave)。
MHA Manager可以單獨部署在一臺獨立的機器上管理多個master-slave集群,或部署在一臺slave節(jié)點上,MHA Node運行在每臺MySQL服務(wù)器上。
運行時,MHA Manager會定時探測集群中的master節(jié)點,當master故障時,會自動將最新數(shù)據(jù)的slave提升為新的master,然后將其他所有slave重新指向新的master。整個故障轉(zhuǎn)移過程對應(yīng)用程序完全透明。整個切換過程如下:
從宕機崩潰的master保存二進制日志事件(binlog events);
識別含有最新更新的slave;
應(yīng)用差異的中繼日志(relay log)到其他的slave;
應(yīng)用從master保存的二進制日志事件(binlog events);
提升一個slave為新的master;
使其他的slave連接新的master進行復(fù)制;
3、MGR(MySQL Group Replication)
MGR是MySQL官方推薦的另一種高可用架構(gòu),復(fù)制組間的數(shù)據(jù)同步基于Paxos協(xié)議。
當客戶端發(fā)起更新事務(wù)時,該事務(wù)先在本地執(zhí)行,執(zhí)行完成之后就要發(fā)起對事務(wù)的提交操作。在還沒有真正提交之前,需要將產(chǎn)生的復(fù)制寫集廣播出去,復(fù)制到其它成員。如果沖突檢測成功,組內(nèi)決定該事務(wù)可以提交,其它成員可以應(yīng)用,否則就回滾。
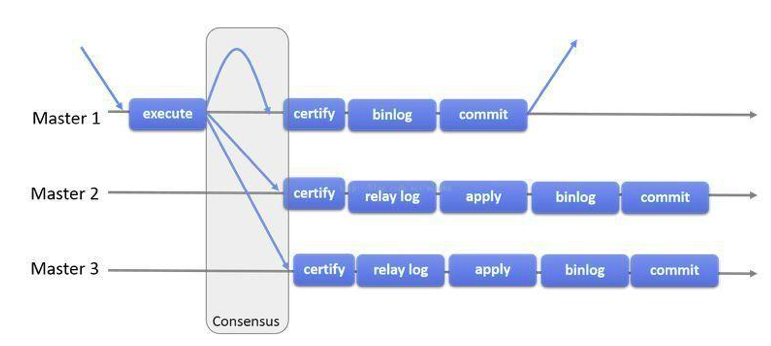
組復(fù)制可以在兩種模式下運行:
- 單主模式下,組復(fù)制具有自動選主功能,每次只有一個 Server成員接受更新,其它成員只提供讀服務(wù)。
- 多主模式下,所有的Server 成員都可以同時接受更新,沒有主從之分,成員角色是完全對等的。
三、 PostgreSQL
(一) PostgreSQL 的體系架構(gòu)
PostgreSQL 使用C/S模式提供服務(wù)。客戶端和服務(wù)器可以在不同的主機上,通過TCP/IP進行網(wǎng)絡(luò)連接,架構(gòu)如下:
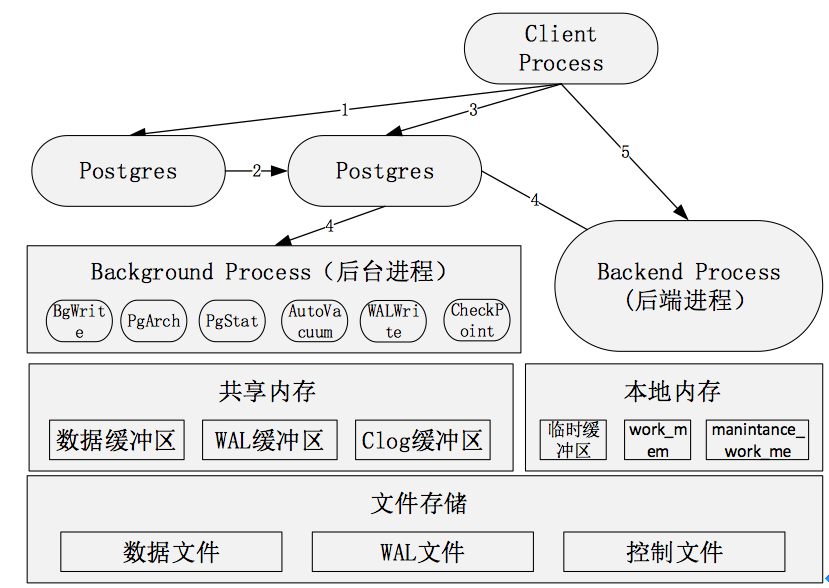
1、主進程Postgres(常駐進程)
主進程是PostgreSQL啟動時,第一個啟動的進程Postgres。啟動時,他會執(zhí)行恢復(fù)、初始化共享內(nèi)存,啟動后臺進程。當有客戶端發(fā)起鏈接請求時,postgres會生成子進程,同時創(chuàng)建后端進程。
是整個數(shù)據(jù)庫實例的總控進程,負責啟動和關(guān)閉該數(shù)據(jù)庫實例。
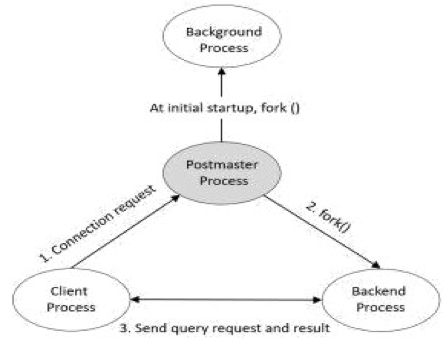
2、Postgres(子進程),子進程
Postgres接受前端請求,對數(shù)據(jù)庫進行檢索,最后返回結(jié)果。如請求是對數(shù)據(jù)庫進行更新,會先記錄日志(PostgreSQL稱為WAL日志),以便宕機重啟時的數(shù)據(jù)恢復(fù)。另外,日志會定期歸檔保存,以便需要時進行數(shù)據(jù)恢復(fù)。
3、后臺進程(Background Process)
- Syslogger(系統(tǒng)日志)進程
將錯誤信息寫到log日志中。
- BgWriter(后臺)進程
周期性的將臟內(nèi)存塊寫入文件。
- Checkpointer
當檢查點出現(xiàn)時,將臟內(nèi)存塊寫到數(shù)據(jù)文件
- WalWrite(預(yù)寫式日志)進程
將WAL(Write Ahead Log預(yù)寫式日志)緩存寫入WAL文件。
- PgArch(歸檔)進程
在歸檔模式下時,復(fù)制WAL文件到特定的路徑下。
WAL日志會被循環(huán)使用,PgArch在歸檔前會把WAL日志備份出來。通過PITY(Point in Time Recovery)技術(shù),可以對數(shù)據(jù)庫進行一次全量備份后,該技術(shù)將備份時間點之后的WAL日志通過歸檔進行備份,使用數(shù)據(jù)庫的全量備份再加上后面產(chǎn)生的WAL日志,即可把數(shù)據(jù)庫向前推到全量備份后的任意一個時間點。
- AutoVacuum(自動清理)進程
當自動vacuum被啟用時,用來派生autovacuum工作進程。autovacuum進程的作用是在需要時自動對膨脹表執(zhí)行vacuum操作。
在PostgreSQL數(shù)據(jù)庫中,對表進行DELETE操作后,舊的數(shù)據(jù)并不會立即被刪除,并且,在更新數(shù)據(jù)時,也并不會在舊的數(shù)據(jù)上做更新,而是新生成一行數(shù)據(jù)。舊的數(shù)據(jù)只是被標識為刪除狀態(tài),只有在沒有并發(fā)的其他事務(wù)讀到這些就數(shù)據(jù)時,它們才會被清楚。這個清除工作就有AutoVacuum進程完成。
- PgStat(統(tǒng)計數(shù)據(jù)收集)進程
用來收集數(shù)據(jù)庫統(tǒng)計信息。
4、共享內(nèi)存和本地內(nèi)存
示意圖如下:
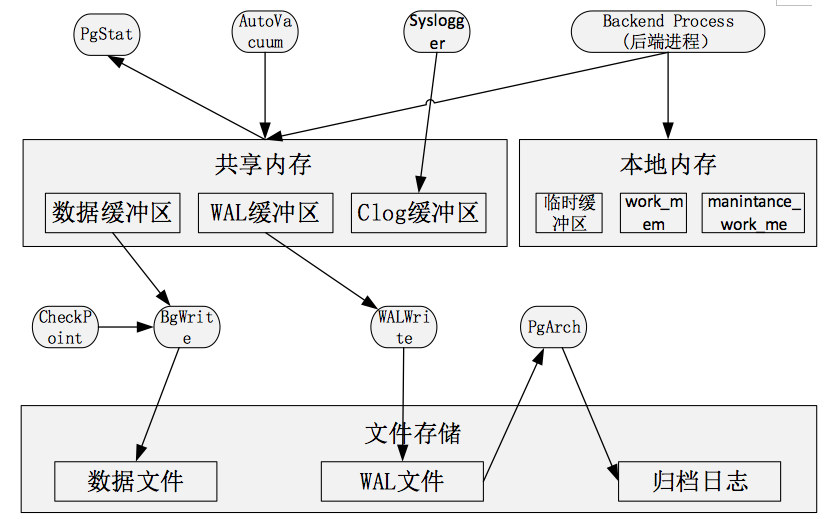
- 共享內(nèi)存
PostgreSQL啟動后,會生成一塊共享內(nèi)存,用于做數(shù)據(jù)塊的緩沖區(qū),以便提高讀寫性能。WAL日志緩沖區(qū)和Clog緩沖區(qū)也存在共享內(nèi)存中,除此之外還有全局信息比如進程、鎖、全局統(tǒng)計等信息也保存在共享內(nèi)存中。
數(shù)據(jù)緩沖區(qū)通過BgWrite進程,定期將數(shù)據(jù)寫入數(shù)據(jù)文件。WAL緩沖區(qū)通過WALWrite進程寫入WAL文件,并通過PgArch定期進行歸檔,寫入歸檔日志
- 本地內(nèi)存
非全局存儲的數(shù)據(jù)都存在本地內(nèi)存中,主要包括:
臨時緩沖區(qū):用于臨時表。默認值為8MB
work_mem: 用于排序、位圖索引、哈希鏈接和合并鏈接操作。默認值為4MB。。
manintance_work_mem: 用于vacuum和創(chuàng)建索引操作。默認值為64MB。
(二) 數(shù)據(jù)結(jié)構(gòu)
1. 數(shù)據(jù)庫相關(guān)概念:
PostgreSQL由一系列數(shù)據(jù)庫組成。一套PostgreSQL程序稱之為一個數(shù)據(jù)庫群集。
當initdb()命令執(zhí)行后,template0 , template1 , 和postgres數(shù)據(jù)庫被創(chuàng)建。
template0和template1數(shù)據(jù)庫是創(chuàng)建用戶數(shù)據(jù)庫時使用的模版數(shù)據(jù)庫,他們包含系統(tǒng)元數(shù)據(jù)表。
initdb()剛完成后,template0和template1數(shù)據(jù)庫中的表是一樣的。但是template1數(shù)據(jù)庫可以根據(jù)用戶需要創(chuàng)建對象。
用戶數(shù)據(jù)庫是通過克隆template1數(shù)據(jù)庫來創(chuàng)建的;
2. 表空間相關(guān)概念:
initdb()后,創(chuàng)建pg_default和pg_global表空間。
建表時如果沒有指定特定的表空間,表默認被存在pg_default表空間中。
用于管理整個數(shù)據(jù)庫集群的表默認被存儲在pg_global表空間中。
pg_default表空間的物理位置為$PGDATAbase目錄。
pg_global表空間的物理位置為$PGDATAglobal目錄。
一個表空間可以被多個數(shù)據(jù)庫同時使用。此時,每一個數(shù)據(jù)庫都會在表空間路徑下創(chuàng)建為一個新的子路徑。
創(chuàng)建一個用戶表空間會在$PGDATApg_tblspc目錄下面創(chuàng)建一個軟連接,連接到表空間制定的目錄位置。
3. 表相關(guān)概念:
每個表有三個數(shù)據(jù)文件:
一個文件用于存儲數(shù)據(jù)(文件名是表的OID);
一個文件用于管理表的空閑空間(文件名是OID_fsm)。
一個文件用于管理表的塊是否可見(文件名是OID_vm)。
索引沒有_vm文件,只有OID和OID_fsm兩個文件
(三) 后端進程的處理流程
接收前端發(fā)送過來的查詢(SQL文)
構(gòu)文解析。將SQL文(單純的文字)轉(zhuǎn)換成構(gòu)文樹parser tree。
構(gòu)文樹解析完以后,換為查詢樹。這時會訪問數(shù)據(jù)庫,檢查表是否存在,如果存在的話,則把表名轉(zhuǎn)換為OID。這個處理稱為分析處理(Analyze)。
因PostgreSQL還通過查詢語句的重寫實現(xiàn)視圖(view)和規(guī)則(rule),所以需要時,此階段會對查詢語句進行重寫。
解析查詢樹后,可生成計劃樹。
按照執(zhí)行計劃里面的步驟可以完成查詢要達到的目的。
執(zhí)行結(jié)果返回給前端。
返回到步驟一重復(fù)執(zhí)行。
四、 國產(chǎn)關(guān)系型數(shù)據(jù)庫
國產(chǎn)關(guān)系型數(shù)據(jù)庫較多,此處僅以GaussDB T為例
(一) GaussDB T架構(gòu)
1. 內(nèi)存結(jié)構(gòu)
內(nèi)存結(jié)構(gòu)分為4部分,如下圖:
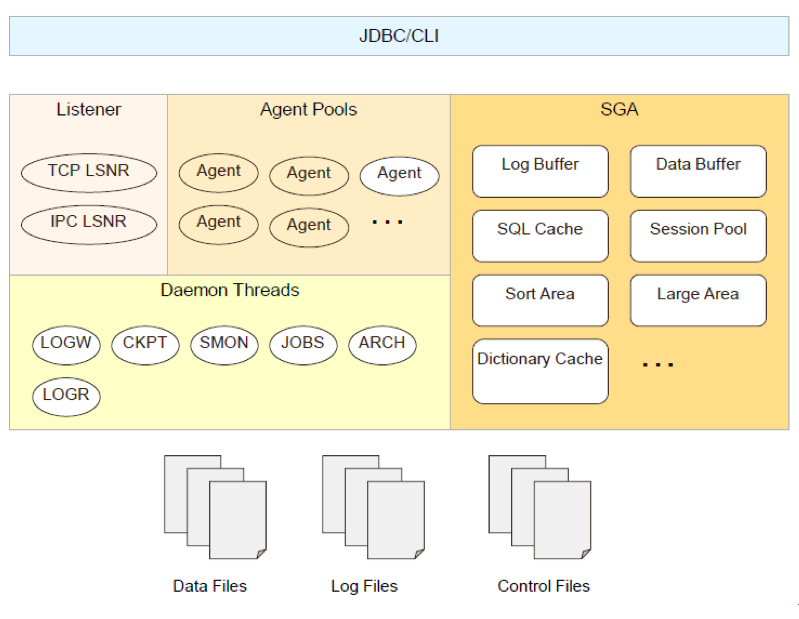
Listener:包括TCP LSNR和IPC LSNR,用于偵聽用戶的連接請求
Agent Pool:代理的連接池
SGA:
Log Buffer: 全局日志緩沖區(qū),緩存redo日志
Data Buffer:全局數(shù)據(jù)頁緩沖區(qū),用于緩存表索引等數(shù)據(jù)
SQL Cache:全局執(zhí)行計劃緩沖區(qū)
Sort Area: 全局排序/物化緩沖區(qū)
Dictionary Cache: 全局數(shù)據(jù)字典(元數(shù)據(jù))緩沖區(qū)
Large pool,大池,存放較大的SQL
Session Pool,全局Session池,用于存放Session
- 后臺進程
LOGW:日志寫線程,負責將log buffer中的日志寫到磁盤。
CKPT:負責將臟頁(Dirty Page)刷到磁盤,保證WAL,并更新Control File。
SMON:負責監(jiān)測系統(tǒng)的狀態(tài),比如檢測死鎖,修復(fù)異常的session。
JOBS:應(yīng)用定制的后臺任務(wù)調(diào)度。
LOGR:日志復(fù)制,用于HA和GR。
ARCH:用于日志文件歸檔。
2、存儲結(jié)構(gòu)
數(shù)據(jù)以文件方式存儲,主要有三種文件:
DATA FILE,數(shù)據(jù)文件,用于存放各種數(shù)據(jù),單庫最多1024個數(shù)據(jù)文件,每個數(shù)據(jù)文件最大8T(undo除外,undo最大32G)
LOG FILE,日志文件,用于存放redo日志,可以重復(fù)使用,最少3組,每個redo 日志文件一般建議5-20G
CONTROL FILE,控制文件,用于數(shù)據(jù)庫名、數(shù)據(jù)文件位置等信息,在數(shù)據(jù)庫啟動到mount階段時會檢查。
(二) GaussDB T關(guān)鍵技術(shù)
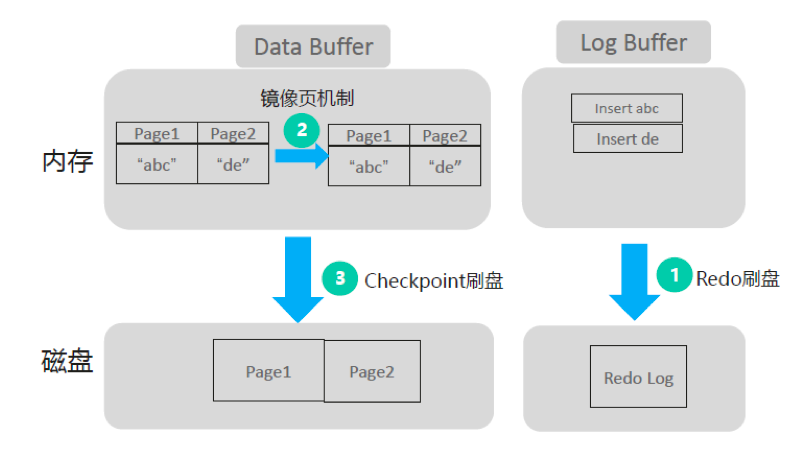
當進行事務(wù)提交時,必須先將Redo log刷盤。
臟頁數(shù)據(jù)刷盤后,可用Redo日志可回收。
如果數(shù)據(jù)未刷盤前掉電,加電后需要重做Redo,保持數(shù)據(jù)的一致性。
臟頁隊列:臟頁按時序組成鏈表,即臟頁隊列,Checkpoint按該隊列順序分組刷盤;
Checkpoint任務(wù)調(diào)度:Checkpoint后臺服務(wù)線程通過定時、臟頁量、RedoLog滿,三個策略滿足之一會觸發(fā)刷盤操作;
Redo 任務(wù)調(diào)度:Redo后臺服務(wù)線程通過定時、Redo buffer量、事務(wù)提交滿足之一時會觸發(fā)Redo Log Buffer刷盤操作;
鏡像頁機制:刷盤時間相對較長,為避免I/O阻塞,Checkpoint通過一個鏡像頁面緩存來完成刷盤。
采用MVCC機制提高事務(wù)并發(fā)能力。
(三) GaussDB T的高可用部署模式
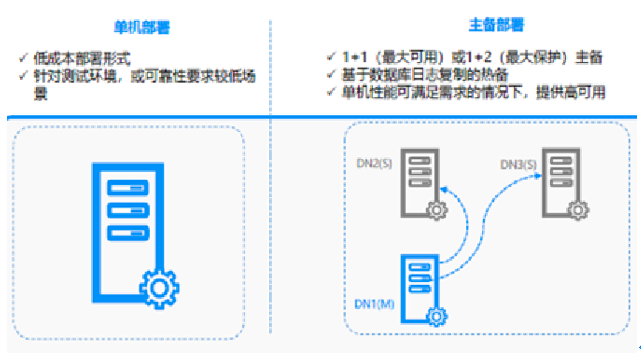
1、單機和主備部署模式
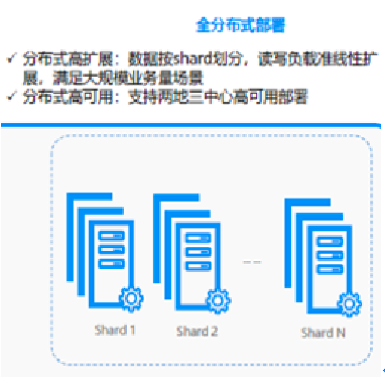
2、分布式部署模式
(四) 典型的分布式部署架構(gòu)
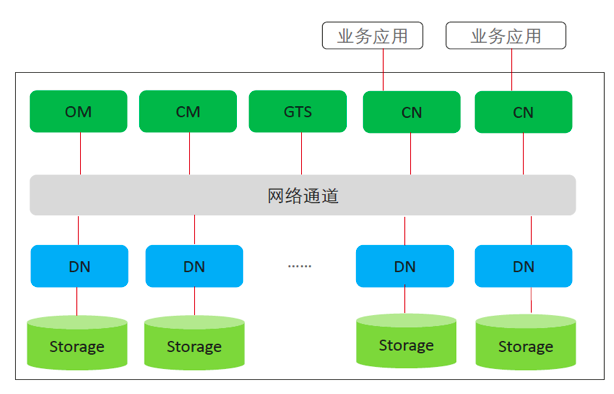
各組件說明如下:
OM(Operation Manager):運維管理模塊。提供集群日常運維、配置管理的管理接口、工具。
CM(Cluster Manager):集群管理模塊。管理和監(jiān)控分布式系統(tǒng)中各個功能單元和物理資源的運行情況,確保整個系統(tǒng)的穩(wěn)定運行。
CN(Coordinator Node):協(xié)同調(diào)度節(jié)點。負責接收來自應(yīng)用的訪問請求,并向客戶端返回執(zhí)行結(jié)果;負責分解任務(wù),并調(diào)度任務(wù)分片在各DN上并行執(zhí)行。集群中,CN有多個且CN的角色是平等的。
DN(Datanode):數(shù)據(jù)節(jié)點。負責存儲業(yè)務(wù)數(shù)據(jù),執(zhí)行數(shù)據(jù)查詢?nèi)蝿?wù)以及向CN返回執(zhí)行結(jié)果。在集群中,DN有多個。每個DN支持設(shè)置多個存儲備機。
GTS(Global Time Server):全局時鐘服務(wù)器。用于強一致場景下,為各個節(jié)點提供邏輯時鐘。
五、 主流關(guān)系型數(shù)據(jù)庫特點分析