如何用Python實現透視表?
相信接觸過Excel的小伙伴都知道,Excel有一個非常強大的功能“數據透視表”,使用數據透視表可以自由選擇不同字段,用不同的聚合函數進行匯總,并建立交叉表格,用以從不同層面觀察數據。這么強大的功能,在Python中怎么去實現呢?
不用擔心,Python的"數據分析小能手"Pandas很貼心地為我們提供了一個快速實現數據透視表功能的方法——pivot_table()。事不宜遲,讓我們趕緊看看如何在Python中實現數據透視表!
1. 數據
為幫助大家更好地理解,在講解如何使用pivot_table( )實現透視表前,我們先導入示例數據,在接下來的講解中都使用此數據作為例子。
- # 導入示例數據
- <<< datadata =pd.read_csv("data.csv")
- <<< data.head()
- 月份 項目 部門 金額 剩余金額
- 0 1月 水費 市場部 1962.37 8210.58
- 1 2月 水費 市場部 690.69 9510.60
- 2 2月 電費 市場部 2310.12 5384.92
- 3 2月 電費 運營部 -1962.37 7973.10
- 4 2月 電費 開發部 1322.33 6572.16
下面我將帶大家使用pivot_table( )一步一步實現數據透視表的操作。
2. 操作
首先,原數據有5個字段,我們在做數據透視表之前必須理解每個字段的意思,明確清楚自己需要得到什么信息。
假設我們想看看不同月份所花費的水電費金額是多少,這時我們需要把字段“月份”設置為索引,將字段“金額”設置為我們需要看的值,具體代碼如下:
- <<< data.pivot_table(index=['月份'],values=['金額'])
- 金額
- 月份
- 10月 3723.940000
- 11月 2900.151667
- 12月 10768.262857
- 1月 1962.370000
- 2月 1432.280000
- 3月 3212.106667
- 4月 4019.175000
- 5月 4051.480000
- 6月 6682.632500
- 7月 11336.463333
- 8月 17523.485000
- 9月 10431.960000
參數index為設置的索引列表,即分組依據,需要用中括號[ ]將索引字段括起來;參數values為分組后進行計算的字段列表,也需要用中括號[ ]括起來。這兩個參數的值可以是一個或多個字段,即按照多個字段進行分組和對多個字段進行計算匯總。例如,設置index=['項目','部門']代表求不同項目不同部門下的金額。
- <<< data.pivot_table(index=['項目','部門'],values=['金額'])
- 金額
- 項目 部門
- 水費 市場部 3614.318125
- 開發部 2358.205000
- 運營部 5896.213333
- 電費 市場部 6094.748235
- 開發部 1322.330000
- 運營部 7288.615000
- 采暖費 市場部 5068.380000
- 運營部 55978.000000
若設置values=['金額','剩余金額'],即求不同項目不同部門下金額和剩余金額的值。
- <<< data.pivot_table(index=['項目','部門'],values=['金額','剩余金額'])
- 剩余金額 金額
- 項目 部門
- 水費 市場部 7478.423125 3614.318125
- 開發部 6866.490000 2358.205000
- 運營部 7224.033333 5896.213333
- 電費 市場部 7645.535882 6094.748235
- 開發部 6572.160000 1322.330000
- 運營部 8821.895000 7288.615000
- 采暖費 市場部 6572.030000 5068.380000
- 運營部 7908.560000 55978.000000
同時,如果我們想以交叉表的形式查看不同項目和不同部門下的消費金額,這時就要將字段‘部門’設置為列名,進行交叉查看,具體代碼如下:
- <<< data.pivot_table(index=['項目'],columns=['部門'],values=['金額'])
- 金額
- 部門 市場部 開發部 運營部
- 項目
- 水費 3614.318125 2358.205 5896.213333
- 電費 6094.748235 1322.330 7288.615000
- 采暖費 5068.380000 NaN 55978.000000
通過上面的示例,我們可以看到某個分組下不存在記錄會被標記為NAN,例如上述中采暖部和開發部不存在金額這一字段的記錄,則會標記為NAN。如果不希望被標記為NAN,我們可以通過設置參數fill_value=0來用數值0替代這部分的缺失值。
- <<< data.pivot_table(index=['項目'],columns=['部門'],values=['金額'],fill_value=0)
- 金額
- 部門 市場部 開發部 運營部
- 項目
- 水費 3614.318125 2358.205 5896.213333
- 電費 6094.748235 1322.330 7288.615000
- 采暖費 5068.380000 0.000 55978.000000
在上面的示例中,我們都是默認分組后對值進行求平均值計算,假如我們想查看不同項目不同部門下金額的總和該怎么實現呢?
通過設置參數aggfunc=np.sum即可對分組后的值進行求和操作,參數aggfunc代表分組后值的匯總方式,可傳入numpy庫中的聚合方法。
- <<< data.pivot_table(index=['項目'],columns=['部門'],values=['金額'],fill_value=0,aggfunc=np.sum)
- 金額
- 部門 市場部 開發部 運營部
- 項目
- 水費 57829.09 4716.41 17688.64
- 電費 103610.72 1322.33 29154.46
- 采暖費 5068.38 0.00 55978.00
除了常見的求和、求平均值這兩種聚合方法,我們還可能接觸到以下這幾種:
描述方法標準差np.std()方差np.var()所有元素相乘np.prod()中數np.median()冪運算np.power()開方np.sqrt()最小值np.min()最大值np.max()以e為底的指數np.exp(10)對數np.log(10)
與前面介紹的參數index,columns,value一樣,參數aggfunc傳入的值也是一個列表,表示可傳入一個或多個值。當傳入多個值時,表示對該值進行多種匯總方式,例如同時求不同項目不同部門下金額的求和值和平均值:
- <<< data.pivot_table(index=['項目'],columns=['部門'],values=['金額'],fill_value=0,aggfunc=[np.sum,np.max])
- sum amax
- 金額 金額
- 部門 市場部 開發部 運營部 市場部 開發部 運營部
- 項目
- 水費 57829.09 4716.41 17688.64 16807.58 2941.28 6273.56
- 電費 103610.72 1322.33 29154.46 18239.39 1322.33 26266.60
- 采暖費 5068.38 0.00 55978.00 5068.38 0.00 55978.00
同時,如果我們想對不同字段進行不同的匯總方式,可通過對參數aggfunc傳入字典來實現,例如我們可以同時對不同項目不同部門下,對字段金額求總和值,對字段剩余金額求平均值:
- <<< data.pivot_table(index=['項目'],columns=['部門'],values=['金額','剩余金額'],fill_value=0,aggfunc={'金額':np.sum,'剩余金額':np.max})
- 剩余金額 金額
- 部門 市場部 開發部 運營部 市場部 開發部 運營部
- 項目
- 水費 9510.60 8719.34 7810.38 57829.09 4716.41 17688.64
- 電費 9625.27 6572.16 9938.82 103610.72 1322.33 29154.46
- 采暖費 6572.03 0.00 7908.56 5068.38 0.00 55978.00
另外,在進行以上功能的同時,pivot_table還為我們提供了一個求所有行及所有列對應合計值的參數margins,當設置參數margins=True時,會在輸出結果的最后添加一行'All',表示根據columns進行分組后每一項的列總計值;以及在輸出結果的最后添加一列'All',表示根據index進行分組后每一項的行總計值。
- <<< pd.set_option('precision',0)
- <<< data.pivot_table(index=['項目'],columns=['部門'],values=['金額','剩余金額'],fill_value=0,aggfunc={'金額':np.sum,'剩余金額':np.max},margins=True)
- 剩余金額 金額
- 部門 市場部 開發部 運營部 All 市場部 開發部 運營部 All
- 項目
- 水費 9511 8719 7810 9511 57829 4716 17689 80234
- 電費 9625 6572 9939 9939 103611 1322 29154 134088
- 采暖費 6572 0 7909 7909 5068 0 55978 61046
- All 9625 8719 9939 9939 166508 6039 102821 275368
3. 番外
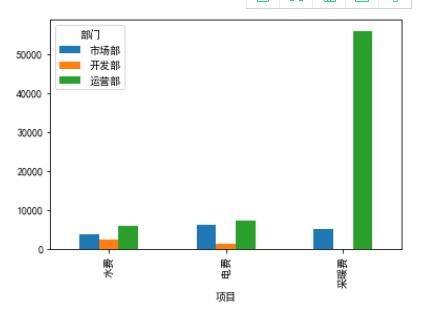
上面詳細介紹了如何在python中通過pivot_table( )方法實現數據透視表的功能,那么,與數據透視表原理相同,顯示方式不同的‘數據透視圖’又該怎么實現呢?
實現方法非常簡單,將上述進行pivot_table操作后的對象進行實例化,再對實例化后的對象進行plot繪圖操作即可,具體代碼如下:
- <<< dfdf=data.pivot_table(index=['項目'],columns=['部門'],values='金額',fill_value=0)
- <<< df.plot(kind='bar')