如何用 Python 清洗數(shù)據(jù)?
0. 序言
在做數(shù)據(jù)分析之前,我們首先要明確數(shù)據(jù)分析的目標(biāo),然后 應(yīng)用數(shù)據(jù)分析的思維,對(duì)目標(biāo)進(jìn)行細(xì)分,再采取相應(yīng)的行動(dòng)。
我們可以把數(shù)據(jù)分析細(xì)分為以下 8 個(gè)步驟:
- 讀取
- 清洗
- 操作
- 轉(zhuǎn)換
- 整理
- 分析
- 展現(xiàn)
(8)報(bào)告
在《 如何用 Python 讀取數(shù)據(jù)? 》這篇文章中,我們學(xué)習(xí)了從 5 種不同的地方讀取數(shù)據(jù)的方法,接下來(lái),我們將利用其中的一種方法, 從 Excel 文件中讀取原始數(shù)據(jù),然后利 用 Python 對(duì)它進(jìn)行清洗。
下面我們用一副待清洗的撲克牌作為示例,假設(shè)它保存在代碼文件相同的目錄下,在 Jupyter Lab 環(huán)境中運(yùn)行以下代碼:
- import numpy as np
- import pandas as pd
- # 設(shè)置最多顯示 10 行
- pd.set_option('max_rows', 10)
- # 從 Excel 文件中讀取原始數(shù)據(jù)
- df = pd.read_excel(
- '待清洗的撲克牌數(shù)據(jù)集.xlsx'
- )
- df
返回結(jié)果如下:

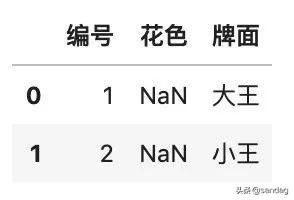
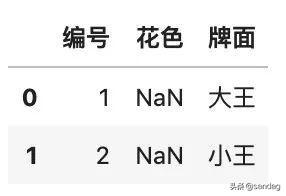
這幅待清洗的撲克牌數(shù)據(jù)集,有一些異常情況,包括:大小王的花色是缺失的,有兩張重復(fù)的黑桃:spades: A,還有一張異常的 黑桃 :spades: 30。
1. 如何查找異常?
在正式開(kāi)始清洗數(shù)據(jù)之前,往往需要先把異常數(shù)據(jù)找出來(lái),觀察異常數(shù)據(jù)的特征,然后再?zèng)Q定清洗的方法。
- # 查找「花色」缺失的行
- df[df.花色.isnull()]
- # 查找完全重復(fù)的行
- df[df.duplicated()]

- # 查找某一列重復(fù)的行
- df[df.編號(hào).duplicated()]

- # 查找牌面的所有唯一值
- df.牌面.unique()
返回結(jié)果:
array(['大王', '小王', 'A', '30', 4, 5, 6, 7, 8, 9, 10, 'J', 'Q', 'K', 2, 3], dtype=object)
根據(jù)常識(shí)可以判斷,牌面為 30 的是異常值。
- # 查找「牌面」包含 30 的異常值
- df[df.牌面.isin(['30'])]

- # 查找王牌,模糊匹配
- df[df.牌面.str.contains(
- '王', na=False
- )]
- # 查找編號(hào)在 1 到 5 之間的行
- df[df.編號(hào).between(1, 5)]
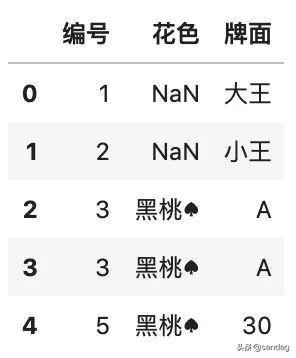
查找某個(gè)區(qū)間,也可以用邏輯運(yùn)算的方法來(lái)實(shí)現(xiàn):
- # 查找編號(hào)在 1 到 5 之間的行
- df[(df.編號(hào) >= 1)
- & (df.編號(hào) <= 5)]
其中「 & 」代表必須同時(shí)滿足兩邊的條件,也就是「且」的意思。
還可以用下面等價(jià)的方法:
- # 查找編號(hào)在 1 到 5 之間的行
- df[~((df.編號(hào) < 1)
- | (df.編號(hào) > 5))]
其中「 | 」代表兩邊的條件滿足一個(gè)即可,也就是「或」的意思,「 ~ 」代表取反,也就是「非」的意思。
2. 如何排除重復(fù)?
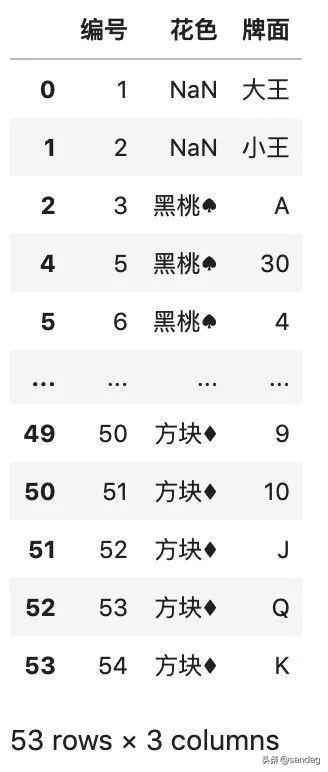
使用 drop_duplicates() 函數(shù),在排除重復(fù)之后,會(huì)得到一個(gè)新的數(shù)據(jù)框。
- # 排除完全重復(fù)的行,默認(rèn)保留第一行
- df.drop_duplicates()
返回結(jié)果如下:
如果想要改變?cè)瓉?lái)的數(shù)據(jù)框,有兩種方法,一種方法,是增加 inplace 參數(shù):
- # 排除重復(fù)后直接替換原來(lái)的數(shù)據(jù)框
- df.drop_duplicates(
- inplace=True
- )
另一種方法,是把得到的結(jié)果,重新賦值給原來(lái)的數(shù)據(jù)框:
- # 排除重復(fù)后,重新賦值給原來(lái)的數(shù)據(jù)框
- df = df.drop_duplicates()
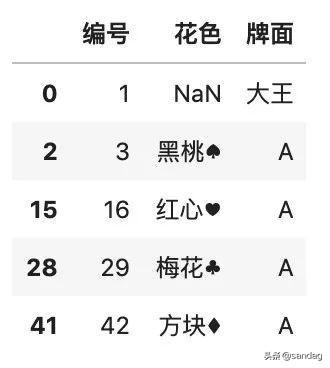
如果想要按某一列排除重復(fù)的數(shù)據(jù),那么指定相應(yīng)的列名即可。
- # 按某一列排除重復(fù),默認(rèn)保留第一行
- df.drop_duplicates(['花色'])
如果想要保留重復(fù)的最后一行,那么需要指定 keep 參數(shù)。
- # 按某一列排除重復(fù),并保留最后一行
- df.drop_duplicates(
- ['花色'], keep='last'
- )
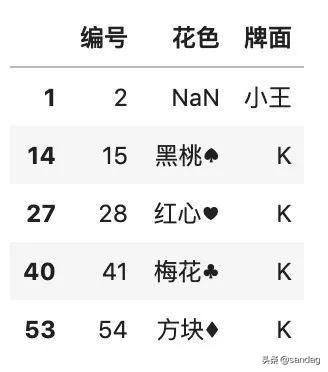
從上面兩個(gè)返回結(jié)果的編號(hào)可以看出,不同方法的差異情況。
3. 如何刪除缺失?
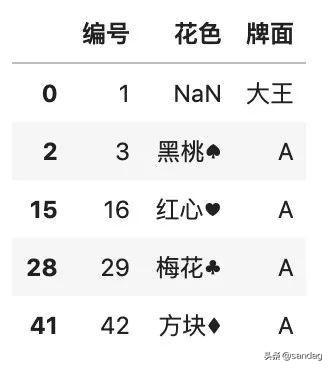
使用 dropna() 函數(shù),默認(rèn)刪除包含缺失的行。為了更加簡(jiǎn)單易懂,我們用撲克牌中不重復(fù)的花色作為示例。
- # 不重復(fù)的花色
- color = df.drop_duplicates(
- ['花色']
- )
- color
- # 刪除包含缺失值的行
- color.dropna()
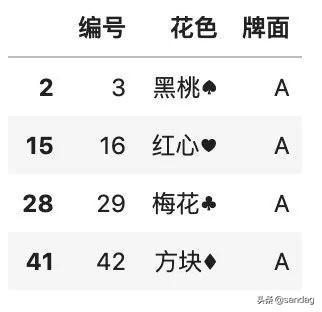
如果想要?jiǎng)h除整行全部為空的行,那么需要指定 how 參數(shù)。
- # 刪除全部為空的行
- color.dropna(how='all')
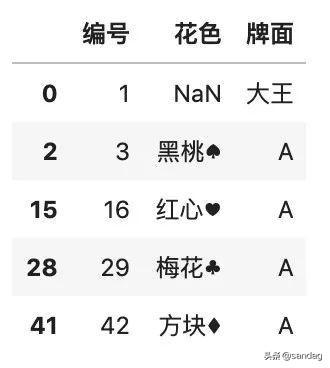
如果想要?jiǎng)h除包含缺失值的列,那么需要指定 axis 參數(shù)。
- # 刪除包含缺失值的列
- color.dropna(axis=1)
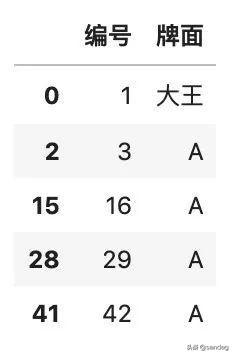
可以看到,包含缺失值的「花色」這一列被刪除了。
4. 如何補(bǔ)全缺失?
使用 fillna() 函數(shù),可以將缺失值填充為我們指定的值。
- # 補(bǔ)全缺失值
- color.fillna('Joker')
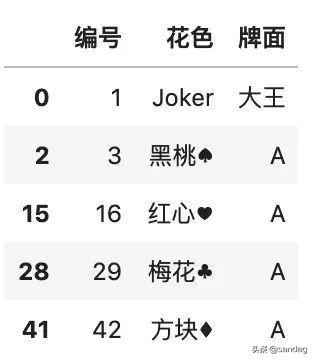
可以看到,原來(lái)的 NaN 被填充為 Joker,在實(shí)際工作的應(yīng)用中,通常填充為 0,也就是說(shuō), fillna(0) 是比較常見(jiàn)的用法。
如果想要使用臨近的值來(lái)填充,那么需要指定 method 參數(shù),例如:
- # 用后面的值填充
- color.fillna(method='bfill')
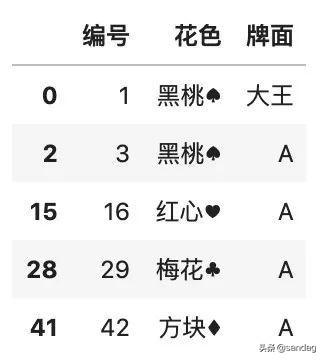
可以看到,原來(lái)第一行的 NaN 替換成了第二行的「黑桃:spades:」。
其中 method 還有一些其他的可選參數(shù),詳情可以查看相關(guān)的幫助文檔。
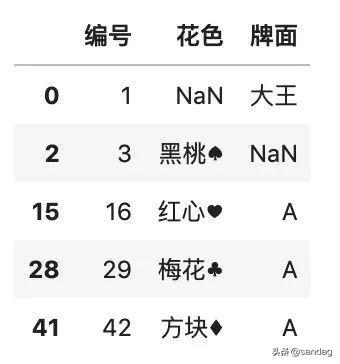
還有一種按字典填充的方法。為了讓下面的演示更加直觀易懂,我們先把索引為 2 的牌面設(shè)置為缺失值:
- # 為了演示,先指定一個(gè)缺失值
- color.loc[2, '牌面'] = np.nan
- color
- # 按列自定義補(bǔ)全缺失值
- color.fillna(
- {'花色': 0, '牌面': 1}
- )
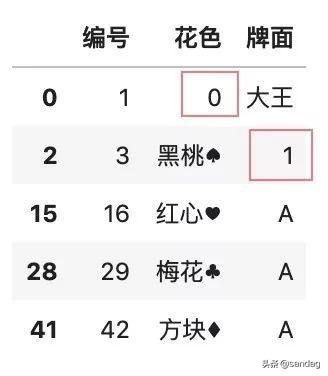
可以看出,不同列的缺失值,可以填充為不同的值,花色這一列填充為 0,牌面這一列填充為 1,我在圖中分別用紅色的方框標(biāo)記出來(lái)了。
5. 應(yīng)用案例
下面 我們用 Python 代碼,把這幅待清洗的撲克牌數(shù)據(jù)集,變成一副正常的撲克牌數(shù)據(jù)。
- import numpy as np
- import pandas as pd
- # 設(shè)置最多顯示 10 行
- pd.set_option('max_rows', 10)
- # 從 Excel 文件中讀取原始數(shù)據(jù)
- df = pd.read_excel(
- '待清洗的撲克牌數(shù)據(jù)集.xlsx'
- )
- # 補(bǔ)全缺失值
- df = df.fillna('Joker')
- # 排除重復(fù)值
- df = df.drop_duplicates()
- # 修改異常值
- df.loc[4, '牌面'] = 3
- # 增加一張缺少的牌
- df = df.append(
- {'編號(hào)': 4,
- '花色': '黑桃♠',
- '牌面': 2},
- ignore_index=True
- )
- # 按編號(hào)排序
- df = df.sort_values('編號(hào)')
- # 重置索引
- df = df.reset_index()
- # 刪除多余的列
- df = df.drop(
- ['index'], axis=1
- )
- # 把清洗好的數(shù)據(jù)保存到 Excel 文件
- df.to_excel(
- '完成清洗的撲克牌數(shù)據(jù).xlsx',
- index=False
- )
- df
返回結(jié)果如下:
- 可以看到,我們已經(jīng)成功地把它變成了一副正常的撲克牌數(shù)據(jù)。
6. 小結(jié)
我們簡(jiǎn)單回顧一下本文的主要內(nèi)容,首先,我們從宏觀層面介紹了數(shù)據(jù)分析的 8 個(gè)步驟,然后用一副待清洗的撲克牌數(shù)據(jù)集作為示例,從讀取數(shù)據(jù),到查找異常,再到排除重復(fù)、刪除缺失和補(bǔ)全缺失,最后,我們用一個(gè)案例, 完整 演示了清洗數(shù)據(jù)的過(guò)程。