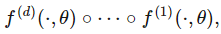超簡單的神經網絡構建方法,你上你也行!
本文轉載自公眾號“讀芯術”(ID:AI_Discovery)
人工智能,深度學習,這些詞是不是聽起來就很高大上,充滿了神秘氣息?仿佛是只對數學博士開放的高級領域?
錯啦!在B站已經變成學習網站的今天,還有什么樣的教程是網上找不到的呢?深度學習從未如此好上手,至少實操部分是這樣。
假如你只是了解人工神經網絡基礎理論,卻從未踏足如何編寫,跟著本文一起試試吧。你將會對如何在PyTorch 庫中執行人工神經網絡運算,以預測原先未見的數據有一個基本的了解。
這篇文章最多10分鐘就能讀完;如果要跟著代碼一步步操作的話,只要已經安裝了必要的庫,那么也只需15分鐘。相信我,它并不難。
長話短說,快開始吧!
導入語句和數據集
在這個簡單的范例中將用到幾個庫:
- Pandas:用于數據加載和處理
- Matplotlib: 用于數據可視化處理
- PyTorch: 用于模型訓練
- Scikit-learn: 用于拆分訓練集和測試集
如果僅僅是想復制粘貼的話,以下幾條導入語句可供參考:
- import torch
- import torch.nn as nn
- import torch.nn.functional as F
- import pandas as pd
- import matplotlib.pyplot as plt
- from sklearn.model_selection import train_test_split
至于數據集,Iris數據集可以在這個URL上找到。下面演示如何把它直接導入
- Pandas:
- iris = pd.read_csv('https://raw.githubusercontent.com/pandas-dev/pandas/master/pandas/tests/data/iris.csv')
- iris.head()
前幾行如下圖所示:
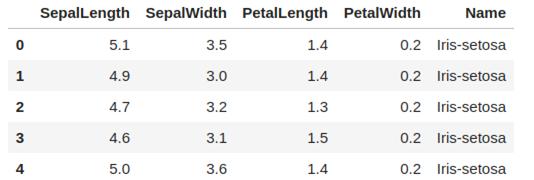
現在需要將 Name列中鳶尾花的品種名稱更改或者重映射為分類值。——也就是0、1、2。以下是步驟說明:
- mappings = {
- 'Iris-setosa': 0,
- 'Iris-versicolor': 1,
- 'Iris-virginica': 2
- }iris['Name'] = iris['Name'].apply(lambda x: mappings[x])
執行上述代碼得到的DataFrame如下:
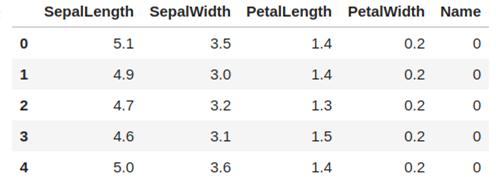
這恭喜你,你已經成功地邁出了第一步!
拆分訓練集和測試集
在此環節,將使用 Scikit-Learn庫拆分訓練集和測試集。隨后, 將拆分過的數據由 Numpy arrays 轉換為PyTorchtensors。
首先,需要將Iris 數據集劃分為“特征”和“ 標簽集” ——或者是x和y。Name列是因變量而其余的則是“特征”(或者說是自變量)。
接下來筆者也將使用隨機種子,所以可以直接復制下面的結果。代碼如下:
- X = iris.drop('Name', axis=1).values
- y = iris['Name'].valuesX_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.2, random_state=42)X_train = torch.FloatTensor(X_train)
- X_test = torch.FloatTensor(X_test)
- y_train = torch.LongTensor(y_train)
- y_test = torch.LongTensor(y_test)
如果從 X_train 開始檢查前三行,會得到如下結果:

從 y_train開始則得到如下結果:
地基已經打好,下一環節將正式開始搭建神經網絡。
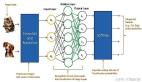
定義神經網絡模型
模型的架構很簡單。重頭戲在于神經網絡的架構:
- 輸入層 (4個輸入特征(即X所含特征的數量),16個輸出特征(隨機))
- 全連接層 (16個輸入特征(即輸入層中輸出特征的數量),12個輸出特征(隨機))
- 輸出層(12個輸入特征(即全連接層中輸出特征的數量),3個輸出特征(即不同品種的數量)
大致就是這樣。除此之外還將使用ReLU 作為激活函數。下面展示如何在代碼里執行這個激活函數。
- class ANN(nn.Module):
- def __init__(self):
- super().__init__()
- self.fc1 =nn.Linear(in_features=4, out_features=16)
- self.fc2 =nn.Linear(in_features=16, out_features=12)
- self.output =nn.Linear(in_features=12, out_features=3)
- def forward(self, x):
- x = F.relu(self.fc1(x))
- x = F.relu(self.fc2(x))
- x = self.output(x)
- return x
PyTorch使用的面向對象聲明模型的方式非常直觀。在構造函數中,需定義所有層及其架構,若使用forward(),則需定義正向傳播。
接著創建一個模型實例,并驗證其架構是否與上文所指的架構相匹配:
- model = ANN()
- model
在訓練模型之前,需注明以下幾點:
- 評價標準:主要使用 CrossEntropyLoss來計算損失
- 優化器:使用學習率為0.01的Adam 優化算法
下面展示如何在代碼中執行CrossEntropyLoss和Adam :
- criterion = nn.CrossEntropyLoss()
- optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
令人期盼已久的環節終于來啦——模型訓練!
模型訓練
這部分同樣相當簡單。模型訓練將進行100輪, 持續追蹤時間和損失。每10輪就向控制臺輸出一次當前狀態——以指出目前所處的輪次和當前的損失。
代碼如下:
- %%timeepochs = 100
- loss_arr = []for i in range(epochs):
- y_hat = model.forward(X_train)
- loss = criterion(y_hat, y_train)
- loss_arr.append(loss)
- if i % 10 == 0:
- print(f'Epoch: {i} Loss: {loss}')
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
好奇最后三行是干嘛用的嗎?答案很簡單——反向傳播——權重和偏置的更新使模型能真正地“學習”。
以下是上述代碼的運行結果:
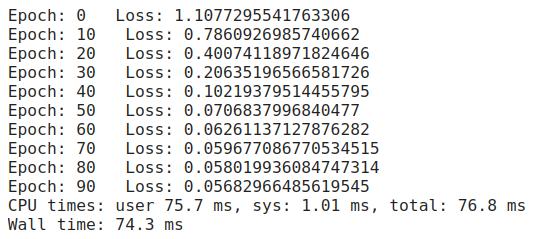
進度很快——但不要掉以輕心。
如果對純數字真的不感冒,下圖是損失曲線的可視化圖(x軸為輪次編號,y軸為損失):

模型已經訓練完畢,現在該干嘛呢?當然是模型評估。需要以某種方式在原先未見的數據上對這個模型進行評估。
模型評估
在評估過程中,欲以某種方式持續追蹤模型做出的預測。需要迭代 X_test并進行預測,然后將預測結果與實際值進行比較。
這里將使用 torch.no_grad(),因為只是評估而已——無需更新權重和偏置。
總而言之,代碼如下:
- preds = []with torch.no_grad():
- for val in X_test:
- y_hat = model.forward(val)
- preds.append(y_hat.argmax().item())
現在預測結果被存儲在 preds陣列。可以用下列三個值構建一個Pandas DataFrame。
- Y:實際值
- YHat: 預測值
- Correct:對角線,對角線的值為1表示Y和YHat相匹配,值為0則表示不匹配
代碼如下:
- df = pd.DataFrame({'Y': y_test, 'YHat':preds})df['Correct'] = [1 if corr == pred else 0 for corr, pred in zip(df['Y'],df['YHat'])]
df 的前五行如下圖所示:

下一個問題是,實際該如何計算精確度呢?
很簡單——只需計算 Correct列的和再除以 df的長度:
- df['Correct'].sum() / len(df)>>> 1.0
此模型對原先未見數據的準確率為100%。但需注意這完全是因為Iris數據集非常易于歸類,并不意味著對于Iris數據集來說,神經網絡就是最好的算法。NN對于這類問題來講有點大材小用,不過這都是以后討論的話題了。
這可能是你寫過最簡單的神經網絡,有著完美簡潔的數據集、沒有缺失值、層次最少、還有神經元!本文沒有什么高級深奧的東西,相信你一定能夠掌握它。