面試的時候按照這個套路回答 Java GC 的相關問題一定能過!
Hello 大家好,我是鴨血粉絲,2020 注定是一個不平凡的一年,很多小伙伴在后臺和星球留言都說今年的工作不好找,也有應屆生小伙伴給阿粉發消息問阿粉所在的公司今年是否招應屆生,阿粉也只能幫小伙伴問問 HR,但是阿粉也做不了主。
剛好前幾天一個小伙伴在微信上問阿粉,說是面試一家公司被問到 Java GC 相關的東西,雖然平時也有準備,但是回答起來總是零零散散,感覺沒有邏輯。其實阿粉也能理解,現在面試都是一種問答模式,一個隨便問問,一個死記硬背,很多時候面試前準備的好好的一到面試的時候可能緊張就給忘了,事后感覺自己表現的不好。
這篇文章給大家舉個例子,在遇到一個問題或者知識點的時候要怎么去理解和學習。
Java GC
目標
遇到一個問題或者一個知識點,我們要理解和明白是要解決什么問題的。說到 Java GC 那這個 GC 的目的是什么呢?很顯然是回收內存,因為內存是有限的,隨著程序中創建的對象越來越多,如果進行回收就會導致內存越來越大,最后程序就會出現異常。既然目的是為了回收內存,那么新的問題來了,哪些對象可以被回收呢?什么時候進行回收呢?怎么回收呢?
哪些對象可以被回收
簡單來說就是無用的對象可以被回收,那么換句話說,如果定義一個對象是無用的呢?這里主要有兩種方法,一個叫引用計數法,一個叫可達性分析法。
引用計數
引用計數說的是如果一個對象被別的對象進行了一次引用,那么該對象會有一個引用計數器,這個計數器就會加一;如果被釋放一下,引用計數器就會減一。當引用計數器的計數為 0 的時候就表示這個對象是無用的,此時就可以對這樣對象進行回收了。表面上看好像挺合理的,實現起來也很方便,但是仔細一想就會發現有問題。既循環引用的問題,比如對象 A 引用了對象 B,但是對象 B 當中也引用了對象 A,那么這個時候對象 A 和對象 B 的引用計數器的計數都不會是 0,但是這兩個對象都沒有被其他對象引用,理論上來說這兩個對象都是可以被回收的。
從上面看到,這種方案是有問題的會導致內存泄露。隨之而來的就出現了另一種方案,可就是可達性分析。
可達性分析
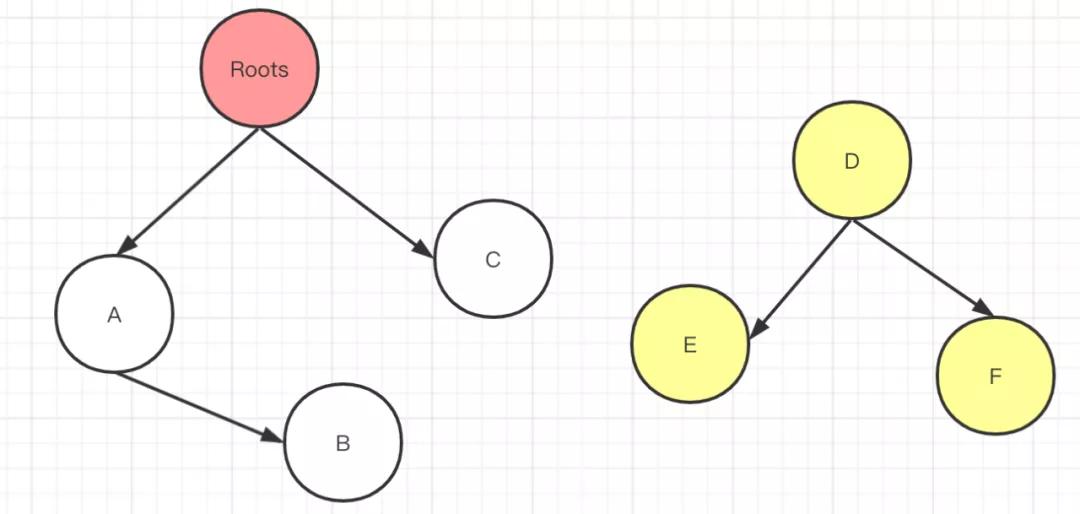
可達性分析說的是從 GCRoots 的點作為起點,向下搜索,當找不到任何引用鏈的時候表示該對象為垃圾對象。那么哪些對象可以被認為是 Roots 節點呢?有 Java 棧中的對象,方法區的靜態屬性和常量以及本地方法棧中的對象。從這幾種對象依次向下搜索,如果沒有能達到 Roots 節點的對象就是垃圾對象,就說明可以被回收。
如下圖所有,對象 A,B,C都能找到與 Roots 節點的聯系,但是對象 D,E,F 三個并不能找到與 Roots 節點的聯系,也就是不可達,所以 DEF 這三個對象就是垃圾對象。
什么時候回收
上面的兩種方案解決了哪些對象能被回收,那么下個問題,就是什么時候進行垃圾回收呢?在排除人為調用的時候,垃圾回收都是發生在為新生對象進行內存分配的時候,這個時候如果內存空間不足就會觸發 GC 進行垃圾回收。
怎么回收
上面我們知道了哪些對象可以被回收,也知道我們應該什么時候進行回收,那下面要解決的就是如何進行垃圾回收了。垃圾回收根據實現的方式不同有多種不同的算法實現。比如有標記清除算法,復制算法,標記整理算法,分代回收算法,下面簡單介紹一下,想深入了解的可以自行去研究一下。
標記清除算法
標記清除算法很好理解,主要就是執行兩個動作,一個是標記,另一個是對進行標記的對象內存進行清除回收。這個算法有個問題就是會出現內存碎片化嚴重。如下圖所示:
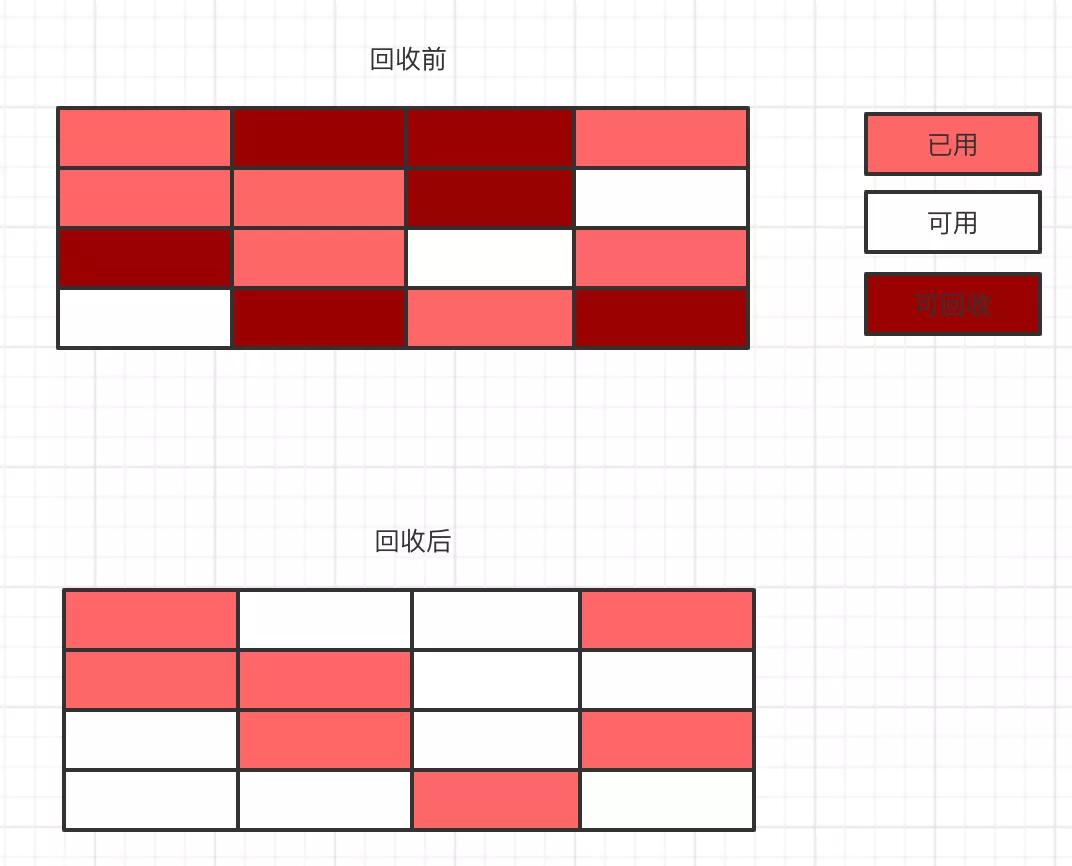
從上圖中可以看到,在進行內存回收后出現了嚴重的內存碎片化,這就導致在分配某些大對象的時候仍然會出現內存不夠的情況,但是總體內存確是夠的。
復制算法
復制算法的實現方式比較簡潔明了,就是霸道的把內存分成兩部分,在平時使用的時候只用其中的固定一份,在當需要進行 GC 的時候,把存活的對象復制到另一部分中,然后將已經使用的內存全部清理掉。如下圖:
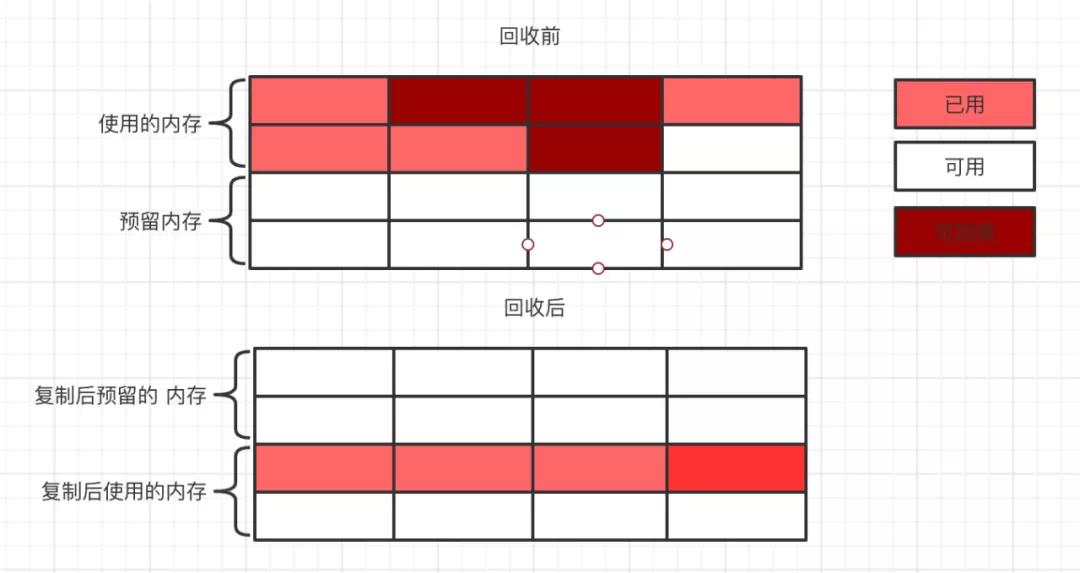
從上圖可以看到解決了標記清除的內存碎片化問題,但是很明顯復制算法有另一個問題,那就是內存的使用率大大下降,能使用的內存只有原來的一半了。
標記整理算法
既然標記清除和復制算法各有優缺點,那自然的我們就想到是否可以把這兩種算法結合起來,于是就出現了標記整理算法。標記階段是標記清除算法一樣,先標記出需要回收的部分,不過清除階段不是直接清除,而是把存活的對象往內存的一端進行移動,然后清除剩下的部分。如下圖:
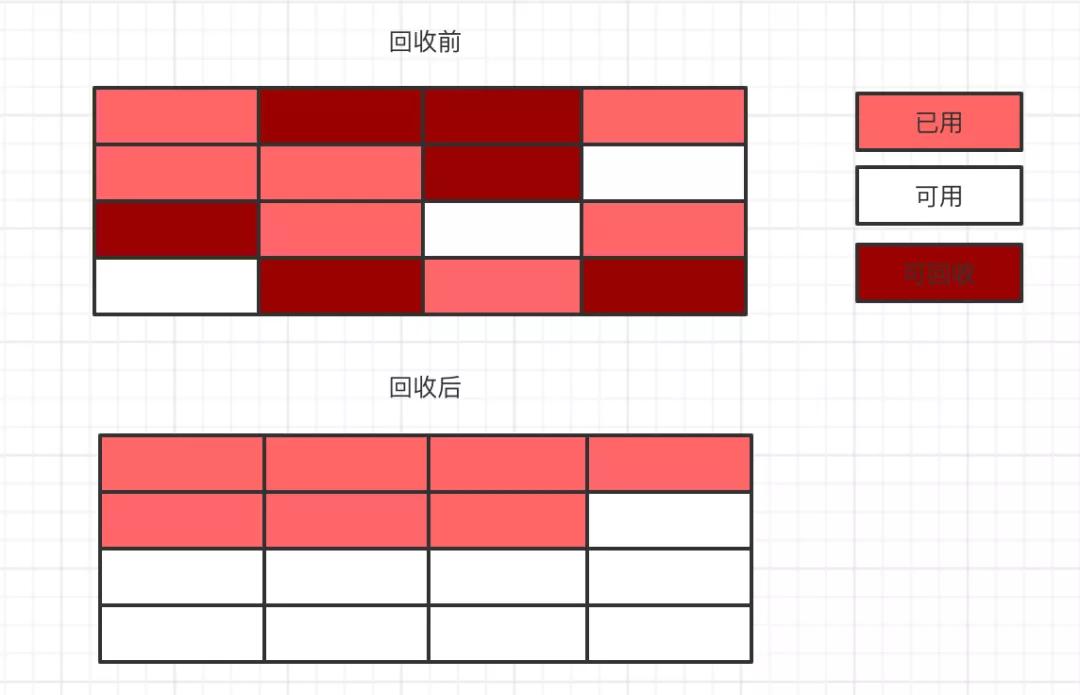
標記整理的算法雖然可以解決上面兩個算法的一些問題,但是還是需要先進行標記,然后進行移動,整個效率還是偏低的。
分代回收算法
分代回收算法是目前使用較多的一種算法,這個不是一個新的算法,只是將內存進行的劃分,不同區域的內存使用不同的算法。根據對象的存活時間將內存的劃分為新生代和老年代,其中新生代包含 Eden 區和 S0,S1。在新生代中使用是復制算法,在進行對象內存分配的時候只會使用 Eden 和 S0 區,當發生 GC 的時候,會將存活的對象復制到 S1 區,然后循環往復進行復制。當某個對象在進行了 15 次GC 后依舊存活,那這個對象就會進入老年代。老年代因為每次回收的對象都會比較少,因此使用的是標記整理算法。
垃圾回收器
講完了垃圾回收算法,我們再看下垃圾回收器,每一種垃圾回收器都是不同時代的不同產物,都有其獨特性。
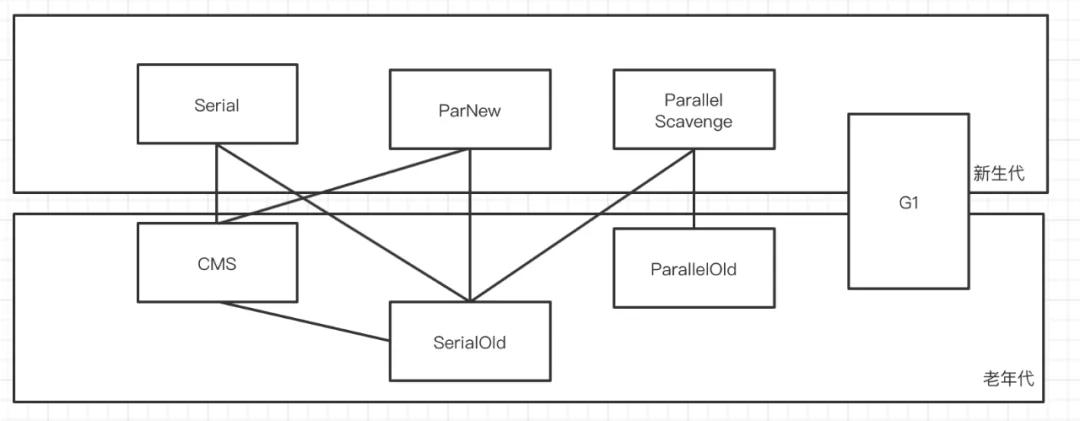
- Serial 垃圾收集器(單線程、復制算法)
- ParNew垃圾收集器(Serial+多線程)
- Parallel Scavenge 收集器(多線程復制算法、高效)
- SerialOld收集器(單線程標記整理算法)
- ParallelOld收集器(多線程標記整理算法)
- CMS收集器(多線程標記清除算法)
- G1收集器
各個垃圾收集器的配合使用情況可以參考下圖,個人覺得對這么多的收集器沒有必要全部精通,可以注重關注一下 CMS 和 G1 就可以了。感興趣的小伙伴可以自己的研究一下。