機器學習中如何處理不平衡數據?
假設老板讓你創建一個模型——基于可用的各種測量手段來預測產品是否有缺陷。你使用自己喜歡的分類器在數據上進行訓練后,準確率達到了 96.2%!
你的老板很驚訝,決定不再測試直接使用你的模型。幾個星期后,他進入你的辦公室,拍桌子告訴你你的模型完全沒用,一個有缺陷的產品都沒發現。
經過一番調查,你發現盡管你們公司的產品中大約有 3.8%的存在缺陷,但你的模型卻總是回答「沒有缺陷」,也因此準確率達到 96.2%。你之所以獲得這種「naive」的結果,原因很可能是你使用的訓練數據是不平衡數據集。
本文將介紹解決不平衡數據分類問題的多種方法。
首先我們將概述檢測」naive behaviour」的不同評估指標;然后討論重新處理數據集的多種方法,并展示這些方法可能會產生的誤導;***,我們將證明重新處理數據集大多數情況下是繼續建模的***方式。
注:帶(∞)符號的章節包含較多數學細節,可以跳過,不影響對本文的整體理解。此外,本文大部分內容考慮兩個類的分類問題,但推理可以很容易地擴展到多類別的情況。
一、檢測「naive behaviour」
我們先來看幾種評估分類器的方法,以確保檢測出「naive behaviour」。如前所述,準確率雖然是一個重要且不可忽視的指標,但卻可能產生誤導,因此應當謹慎使用,***與其他指標一起使用。我們先看看還有哪些指標。
1. 混淆矩陣、精度、召回率和 F1
在處理分類問題時,一個很好且很簡單的指標是混淆矩陣(confusion matrix)。該指標可以很好地概述模型的運行情況。因此,它是任何分類模型評估的一個很好的起點。下圖總結了從混淆矩陣中可以導出的大部分指標:
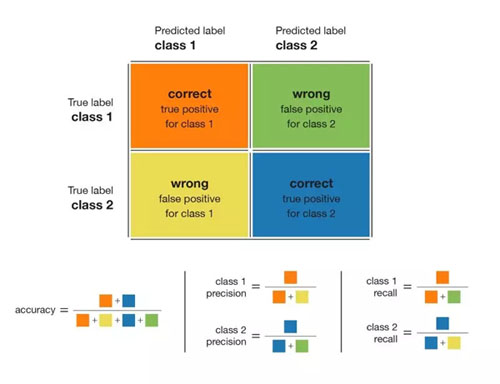
混淆矩陣以及可從中導出的指標
讓我們簡單解釋一下:所謂準確率(accuracy)就是正確預測的數量除以預測總數;類別精度(precision)表示當模型判斷一個點屬于該類的情況下,判斷結果的可信程度。類別召回率(recall)表示模型能夠檢測到該類的比率。類別的 F1 分數是精度和召回率的調和平均值(F1 = 2×precision×recall / (precision + recall)),F1 能夠將一個類的精度和召回率結合在同一個指標當中。
對于一個給定類,精度和召回率的不同組合如下:
- 高精度+高召回率:模型能夠很好地檢測該類;
- 高精度+低召回率:模型不能很好地檢測該類,但是在它檢測到這個類時,判斷結果是高度可信的;
- 低精度+高召回率:模型能夠很好地檢測該類,但檢測結果中也包含其他類的點;
- 低精度+低召回率:模型不能很好地檢測該類。
我們舉個例子,如下圖所示,我們有 10000 個產品的混淆矩陣:
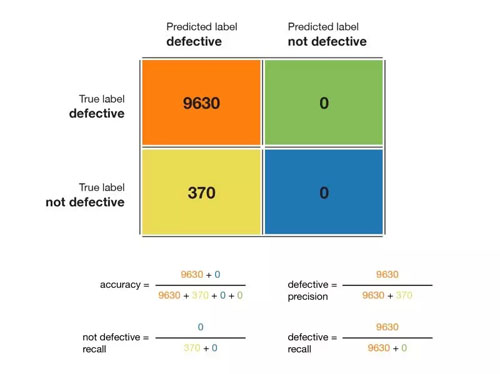
文章開頭示例的混淆矩陣。注意「not defective」精度不可計算。
根據上圖,準確率為 96.2%,無缺陷類的精度為 96.2%,有缺陷類的精度不可計算;無缺陷類的召回率為 1.0(這很好,所有無缺陷的產品都會被檢測出來),有缺陷類的召回率是 0(這很糟糕,沒有檢測到有缺陷的產品)。因此我們可以得出結論,這個模型對有缺陷類是不友好的。有缺陷產品的 F1 分數不可計算,無缺陷產品的 F1 分數是 0.981。在這個例子中,如果我們查看了混淆矩陣,就會重新考慮我們的模型或目標,也就不會有前面的那種無用模型了。
2. ROC 和 AUROC
另外一個有趣的指標是ROC 曲線(Receiver Operating Characteristic),其定義和給定類相關(下文用 C 表示類別)。
假設對于給定點 x,我們的模型輸出該點屬于類別 C 的概率為:P(C | x)。基于這個概率,我們定義一個決策規則,即當且僅當 P(C | x)≥T 時,x 屬于類別 C,其中 T 是定義決策規則的給定閾值。如果 T = 1,則僅當模型 100%可信時,才將該點標注為類別 C。如果 T = 0,則每個點都標注為類別 C。
閾值 T 從 0 到 1 之間的每個值都會生成一個點 (false positive, true positive),ROC 曲線就是當 T 從 1 變化到 0 所產生點的集合所描述的曲線。該曲線從點 (0,0) 開始,在點 (1,1) 處結束,且單調增加。好模型的 ROC 曲線會快速從 0 增加到 1(這意味著必須犧牲一點精度才能獲得高召回率)。
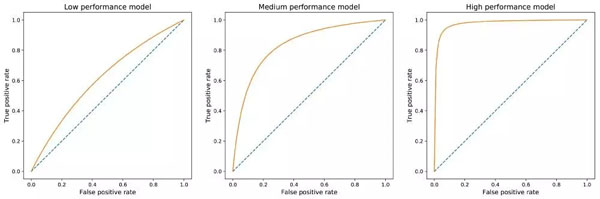
有效性不同的模型的 ROC 曲線圖示。左側模型必須犧牲很多精度才能獲得高召回率;右側模型非常有效,可以在保持高精度的同時達到高召回率。
基于 ROC 曲線,我們可以構建另一個更容易使用的指標來評估模型:AUROC(Area Under the ROC),即 ROC 曲線下面積。可以看出,AUROC 在***情況下將趨近于 1.0,而在最壞情況下降趨向于 0.5。同樣,一個好的 AUROC 分數意味著我們評估的模型并沒有為獲得某個類(通常是少數類)的高召回率而犧牲很多精度。
二、究竟出了什么問題?
1. 不平衡案例
在解決問題之前,我們要更好地理解問題。為此我們考慮一個非常簡單的例子。假設我們有兩個類:C0 和 C1,其中 C0 的點遵循均值為 0、方差為 4 的一維高斯分布;C1 的點遵循均值為 2 、方差為 1 的一維高斯分布。假設數據集中 90% 的點來自 C0,其余 10% 來自 C1。下圖是包含 50 個點的數據集按照上述假設的理論分布情況:
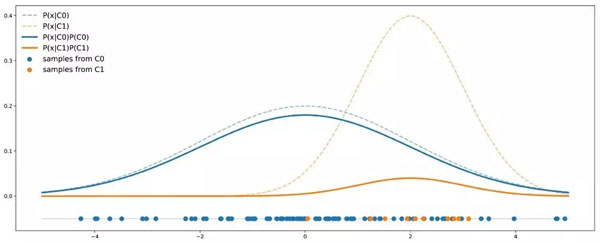
不平衡案例圖示。虛線表示每個類的概率密度,實線加入了對數據比例的考量。
在這個例子中,我們可以看到 C0 的曲線總是在 C1 曲線之上,因此對于任意給定點,它出自 C0 類的概率總是大于出自 C1 類的概率。用貝葉斯公式來表示,即:
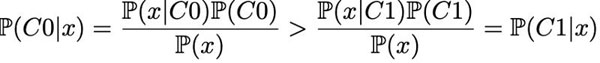
在這里我們可以清楚地看到先驗概率的影響,以及它如何導致一個類比另一個類更容易發生的情況。這就意味著,即使從理論層面來看,只有當分類器每次判斷結果都是 C0 時準確率才會***。所以假如分類器的目標就是獲得***準確率,那么我們根本就不用訓練,直接全部判為 C0 即可。
2. 關于可分離性
在前面的例子中,我們可以觀察到兩個類似乎不能很好地分離開(彼此相距不遠)。但是,數據不平衡不代表兩個類無法很好地分離。例如,我們仍假設數據集中 C0、C1 的比例分別為 90% 和 10%;但 C0 遵循均值為 0 、方差為 4 的一維高斯分布、C1 遵循均值為 10 、方差為 1 的一維高斯分布。如下圖所示:

在這個例子中,如果均值差別足夠大,即使不平衡類也可以分離開來。
在這里我們看到,與前一種情況相反,C0 曲線并不總是高于 C1 曲線,因此有些點出自 C1 類的概率就會高于出自 C0 的概率。在這種情況下,兩個類分離得足夠開,足以補償不平衡,分類器不一定總是得到 C0 的結果。
3. 理論最小誤差概率(∞)
我們應當明白這一點,分類器具有理論意義上的最小誤差概率。對于本文所討論的單特征二分類分類器,用圖表來看的話,理論最小誤差概率是由兩條曲線最小值下的面積給出的:
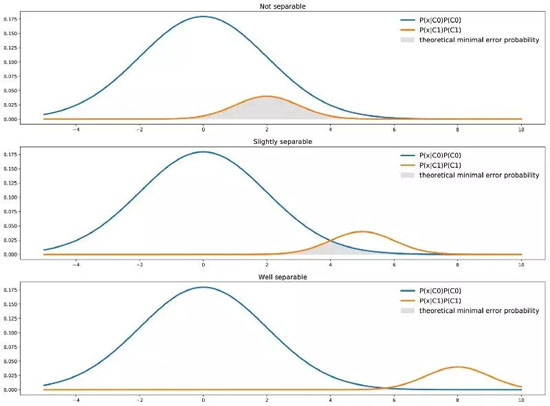
兩個類在不同分離度下的理論最小誤差
我們可以用公式的形式來表示。實際上,從理論的角度來看,***的分類器將從兩個類中選擇點 x 最有可能屬于的類。這自然就意味著對于給定的點 x,***的理論誤差概率由這兩個類可能性較小的一個給出,即
然后我們可以對全體進行積分,得到總誤差概率:
即上圖中兩條曲線最小值下區域的面積。
三、重新處理數據集并不總是解決方案
面對不平衡數據集,我們的***個反應可能會認為這個數據沒有代表現實。如果這是正確的,也就是說,實際數據應該是(或幾乎是)平衡的,但由于我們采集數據時的方法問題造成數據存在比例偏差。因此我們必須嘗試收集更具代表性的數據。
在接下來的兩個小節里,我們將簡單介紹一些常用于解決不平衡類以及處理數據集本身的方法,特別是我們將討論欠采樣(undersampling)、過采樣(oversampling)、生成合成數據的風險及好處。
1. 欠采樣、過采樣和生成合成數據
這三種方法通常在訓練分類器之前使用以平衡數據集。簡單來說:
- 欠采樣:從樣本較多的類中再抽取,僅保留這些樣本點的一部分;
- 過采樣:復制少數類中的一些點,以增加其基數;
- 生成合成數據:從少數類創建新的合成點,以增加其基數。
所有這些方法目的只有一個:重新平衡(部分或全部)數據集。但是我們應該重新平衡數據集來獲得數據量相同的兩個類嗎?或者樣本較多的類應該保持***的代表性嗎?如果是這樣,我們應以什么樣的比例來重新平衡呢?
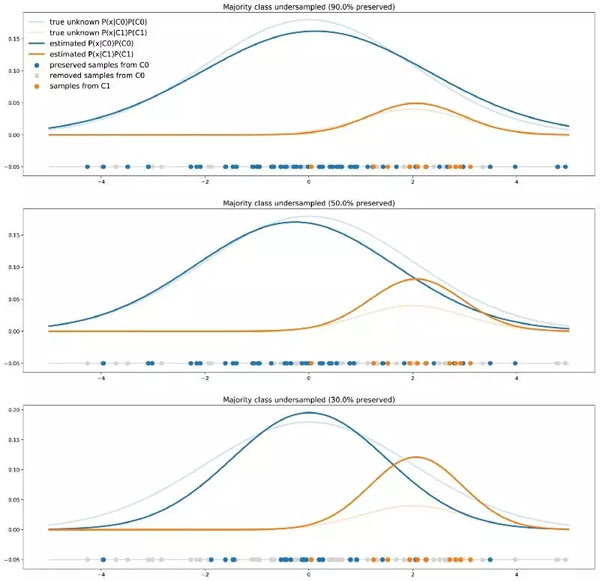
不同程度的多數類欠采樣對模型決策的影響
當使用重采樣方法(例如從 C0 獲得的數據多于從 C1 獲得的數據)時,我們在訓練過程向分類器顯示了兩個類的錯誤比例。以這種方式學得的分類器在未來實際測試數據上得到的準確率甚至比在未改變數據集上訓練的分類器準確率還低。實際上,類的真實比例對于分類新的點非常重要,而這一信息在重新采樣數據集時被丟失了。
因此,即使不完全拒絕這些方法,我們也應當謹慎使用它們:有目的地選擇新的比例可以導出一些相關的方法(下節將會講),但如果沒有進一步考慮問題的實質而只是將類進行重新平衡,那么這個過程可能毫無意義。總結來講,當我們采用重采樣的方法修改數據集時,我們正在改變事實,因此需要小心并記住這對分類器輸出結果意味著什么。
2. 添加額外特征
重采樣數據集(修改類比例)是好是壞取決于分類器的目的。如果兩個類是不平衡、不可分離的,且我們的目標是獲得***準確率,那么我們獲得的分類器只會將數據點分到一個類中;不過這不是問題,而只是一個事實:針對這些變量,已經沒有其他更好的選擇了。
除了重采樣外,我們還可以在數據集中添加一個或多個其他特征,使數據集更加豐富,這樣我們可能獲得更好的準確率結果。回到剛才的例子(兩個類無法很好地分離開來),我們附加一個新的特征幫助分離兩個類,如下圖所示:
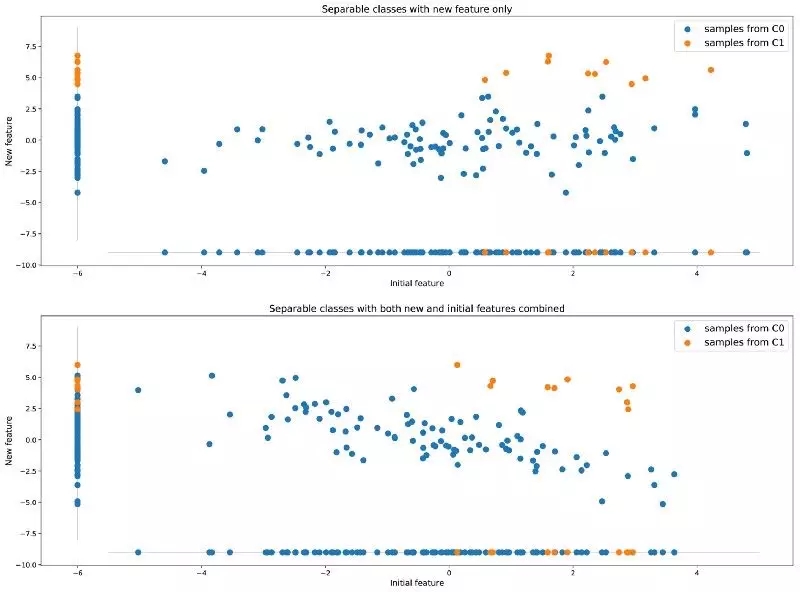
尋找附加特征可以將原本不能分離的類分離開
與前一小節提到的重采樣的方法相比,這種方法會使用更多來自現實的信息豐富數據,而不是改變數據的現實性。
四、重新解決問題更好
到目前為止,結論似乎令人失望:如果要求數據集代表真實數據而我們又無法獲得任何額外特征,這時候如果我們以***準確率來評判分類器,那么我們得到的就是一個「naive behaviour」(判斷結果總是同一個類),這時候我們只好將之作為事實來接受。
但如果我們對這樣的結果不滿意呢?這就意味著,事實上我們的問題并沒有得到很好的表示(否則我們應當可以接受模型結果),因此我們應該重新解決我們的問題,從而獲得期望結果。我們來看一個例子。
1. 基于成本的分類
結果不好的根本原因在于目標函數沒有得到很好的定義。截至此時,我們一直假設分類器具備高準確率,同時假設兩類錯誤(「假陽性」和「假陰性」)具有相同的成本(cost)。在我們的例子中,這意味著真實標簽為 C1、預測結果為 C0 與真實標簽為 C0、預測結果為 C1 一樣糟糕,錯誤是對稱的。然而實際情況往往不是這樣。
讓我們考慮本文***個例子,關于有缺陷(C1)和無缺陷(C0)產品。可以想象,對公司而言,沒有檢測到有缺陷的產品的代價遠遠大于將無缺陷的產品標注為有缺陷產品(如客戶服務成本、法律審判成本等)。因此在真實案例中,錯誤的代價是不對稱的。
我們再更具體地考慮,假設:
- 當真實標簽為 C1 而預測為 C0 時的成本為 P01
- 當真實標簽為 C0 而預測為 C1 時的成本為 P10
- 其中 P01 和 P10 滿足:0
接下來,我們可以重新定義目標函數:不再以***準確率為目標,而是尋找較低的預測成本。
2. 理論最小成本 (∞)
從理論的角度來看,我們并不想最小化前文定義的誤差概率,而是最小化期望預測成本:

其中 C(.) 定義分類器函數。因此,如果我們想要最小化期望預測成本,理論***分類器 C(.) 最小化
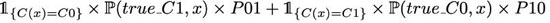
或者等價地,除以 x 的密度,C(.) 最小化
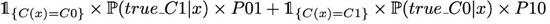
有了這個目標函數,從理論的角度來看,***的分類器應該是這樣的:

注意:當成本相等時,我們就恢復了「經典」分類器的表達式(只考慮準確率)。
3. 概率閾值
在分類器中考慮成本的***種可行方法是在訓練后進行,也即按照基本的方法訓練分類器,輸出如下概率:
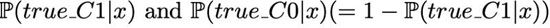
這里沒有考慮任何成本。然后,如果滿足下述條件
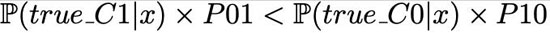
則預測類為 C0,否則為 C1。
這里,只要輸出給定點的每個類的概率,使用哪個分類器并不重要。在我們的例子中,我們可以在數據上擬合貝葉斯分類器,然后對獲得的概率重新加權,根據成本誤差來調整分類器。
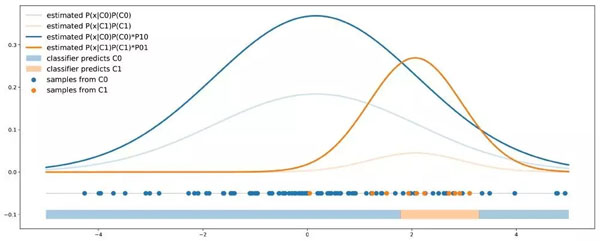
概率閾值方法:輸出概率被重新加權,使得在最終決策規則中考慮成本。
4. 類重新加權
類重新加權(class reweight),即在分類器訓練期間直接考慮成本誤差的不對稱性,這使每個類的輸出概率都嵌入成本誤差信息。然后這個概率將用于定義具有 0.5 閾值的分類規則。
對于某些模型(例如神經網絡分類器),我們可以在訓練期間通過調整目標函數來考慮成本。我們仍然希望分類器輸出
但是這次的訓練將使以下的成本函數最小化

對于一些其他模型(例如貝葉斯分類器),我們可以使用重采樣方法來偏置類的比例,以便在類比例內輸入成本誤差信息。如果考慮成本 P01 和 P10(如 P01> P10),我們可以:
- 對少數類按照 P01 / P10 的比例進行過采樣(少數類的基數乘以 P01 / P10);
- 對多數類按照 P10/P01 的比例進行欠采樣(多數類的基數乘以 P10/P01)。
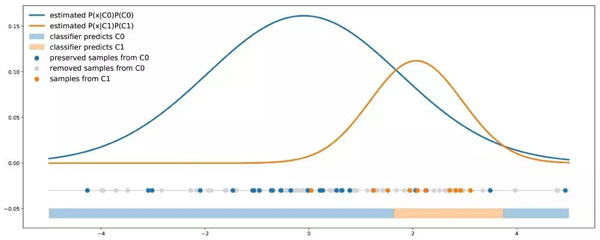
類重新加權方法:多數類按比例進行欠采樣,這樣可以直接在類比例中引入成本信息。
五、總結
這篇文章的核心思想是:
- 當我們使用機器學習算法時,必須謹慎選擇模型的評估指標:我們必須使用那些能夠幫助更好了解模型在實現目標方面的表現的指標;
- 在處理不平衡數據集時,如果類與給定變量不能很好地分離,且我們的目標是獲得***準確率,那么得到的分類器可能只是預測結果為多數類的樸素分類器;
- 可以使用重采樣方法,但必須仔細考慮:這不應該作為獨立的解決方案使用,而是必須與問題相結合以實現特定的目標;
- 重新處理問題本身通常是解決不平衡類問題的***方法:分類器和決策規則必須根據目標進行設置。
我們應該注意,本文并未討論到所有技術,如常用于批量訓練分類器的「分層抽樣」技術。當面對不平衡類問題時,這種技術(通過消除批次內的比例差異)可使訓練過程更加穩定。
***,我需要強調這篇文章的主要關鍵詞是「目標」。準確把握目標將有助于克服不平衡數據集問題,并確保獲得***結果。準確地定義目標是萬事之首,是創建機器學習模型所需選擇的起點。
原文鏈接:
https://towardsdatascience.com/handling-imbalanced-datasets-in-machine-learning-7a0e84220f28
【本文是51CTO專欄機構“機器之心”的原創譯文,微信公眾號“機器之心( id: almosthuman2014)”】