深入理解LVS,還學不會算我輸!
如今,在各種互聯網應用中,隨著站點對硬件性能、響應速度、服務穩定性、數據可靠性等要求也越來越高,單臺服務器也將難以無法承擔所有的訪問需求。
圖片來自 Pexels
當然了,除了使用性價比高的設備和專用負載分流設備外,還有一些其他選擇來幫你解決此問題,就是搭建集群服務器通過整合多臺普通的服務器設備并以同一個地址對外提供相同的服務。
今天就帶大家學習企業中常用的一種群集技術 LVS:
- 什么是 LVS
- 為什么要用 LVS
- LVS 的組成及作用
- 負載均衡的由來及所帶來的好處
- LVS 負載均衡集群的類型
- DNS/軟硬件負載均衡的類型
- LVS 集群的通用體系結構
- LVS 負載均衡的基本原理
- LVS 負載均衡的三種工作模式
- LVS 的十種負載調度算法
- LVS 涉及相關的術語與說明
- 總結
什么是 LVS?
LVS 是 Linux Virtual Server 的簡寫,也就是 Linux 虛擬服務器,是一個虛擬的服務器集群系統,本項目在 1998 年 5 月由章文嵩博士成立,是中國國內最早出現的自由軟件項目之一。
官方網站:http://www.linuxvirtualserver.org,LVS 實際上相當于基于 IP 地址的虛擬化應用,為基于 IP 地址和內容請求分發的負載均衡提出了高效的解決方法,現在 LVS 已經是 Linux 內核標準的一部分。
使用 LVS 可以達到的技術目標是:通過 LVS 達到的負載均衡技術和 Linux 操作系統實現一個高性能高可用的 Linux 服務器集群,具有良好的可靠性、可擴展性和可操作性,從而以低廉的成本實現最優的性能。
LVS 是一個實現負載均衡集群的開源軟件項目,LVS 架構從邏輯上可分為調度層、Server 集群層和共享存儲層。
為什么要用 LVS?
那為什么還需要用 LVS 呢?隨著 Internet 的爆炸性增長以及日常生活中的日益重要的作用,Internet 上的流量速度增長,以每年 100% 以上的速度增長。
服務器上的工作負載壓力也迅速增加,因此服務器在短時間內將會過載,尤其是對于受歡迎的網站而言。
為了克服服務器的過載壓力問題,有兩種解決方案:
- 一種是:單服務器解決方案,即將服務器升級到性能更高的服務器,但是當請求增加時,將很快過載,因此必須再次對其進行升級,升級過程復雜且成本高;
- 另一個是:多服務器解決方案,即在服務器集群上構建可擴展的網絡服務系統。當負載增加時,可以簡單地在群集中添加新服務器或更多服務器以滿足不斷增長的需求,而商用服務器具有最高的性能/成本比。因此,構建用于網絡服務的服務器群集系統更具可伸縮性,并且更具成本效益。
構建服務器集群的方法如下:
基于 DNS 的負載均衡集群:DNS 負載均衡可能是構建網絡服務群集的最簡單方法。
使用域名系統通過將域名解析為服務器的不同 IP 地址來將請求分發到不同的服務器。
當 DNS 請求到達 DNS 服務器以解析域名時,DNS 服務器將基于調度策略發出服務器 IP 地址之一,然后來自客戶端的請求使用相同的本地緩存名稱服務器將在指定的名稱解析生存時間(TTL)中發送到同一服務器。
但是,由于客戶端和分層 DNS 系統的緩存特性,很容易導致服務器之間的動態負載不平衡,因此服務器很難處理其峰值負載。在 DNS 服務器上不能很好地選擇名稱映射的 TTL 值。
如果值較小,DNS 流量很高,而 DNS 服務器將成為瓶頸;如果值較大,則動態負載不平衡將變得更糟。
即使 TTL 值設置為零,調度粒度也是針對每個主機的,不同用戶的訪問模式可能會導致動態負載不平衡,因為有些人可能從站點中拉出很多頁面,而另一些人可能只瀏覽了幾頁然后轉到遠。
而且,它不是那么可靠,當服務器節點發生故障時,將名稱映射到 IP 地址的客戶端會發現服務器已關閉。
基于分派器的負載平衡集群:分派器,也稱為負載平衡器,可用于在群集中的服務器之間分配負載,以便服務器的并行服務可以在單個 IP 地址上顯示為虛擬服務,并且最終用戶可以像單個服務器一樣進行交互不知道群集中的所有服務器。
與基于 DNS 的負載平衡相比,調度程序可以按精細的粒度(例如每個連接)調度請求,以實現服務器之間的更好負載平衡。一臺或多臺服務器發生故障時,可以掩蓋故障。
服務器管理變得越來越容易,管理員可以隨時使一臺或多臺服務器投入使用或退出服務,而這不會中斷最終用戶的服務。
負載均衡可以分為兩個級別,即應用程序級別和 IP 級別。例如,反向代理和 pWEB是用于構建可伸縮 Web 服務器的應用程序級負載平衡方法。
他們將 HTTP 請求轉發到群集中的其他 Web 服務器,獲取結果,然后將其返回給客戶端。
由于在應用程序級別處理 HTTP 請求和答復的開銷很高,我相信當服務器節點數增加到 5 個或更多時,應用程序級別的負載均衡器將成為新的瓶頸,這取決于每個服務器的吞吐量服務器。
LVS 與 Nginx 功能對比如下:
- LVS 比 Nginx 具有更強的抗負載能力,性能高,對內存和 CPU 資源消耗較低。
- LVS 工作在網絡層,具體流量由操作系統內核進行處理,Nginx 工作在應用層,可針對 HTTP 應用實施一些分流策略。
- LVS 安裝配置較復雜,網絡依賴性大,穩定性高。Nginx 安裝配置較簡單,網絡依賴性小。
- LVS 不支持正則匹配處理,無法實現動靜分離效果。
- LVS 適用的協議范圍廣。Nginx 僅支持 HTTP、HTTPS、Email 協議,適用范圍小。
LVS 的組成及作用
LVS 由兩部分程序組成:
- ipvs(ip virtual server):LVS 是基于內核態的 Netfilter 框架實現的 IPVS 功能,工作在內核態。用戶配置 VIP 等相關信息并傳遞到 IPVS 就需要用到 ipvsadm 工具。
- ipvsadm:ipvsadm 是 LVS 用戶態的配套工具,可以實現 VIP 和 RS 的增刪改查功能,是基于 Netlink 或 raw socket 方式與內核 LVS 進行通信的,如果 LVS 類比于 Netfilter,那 ipvsadm 就是類似 iptables 工具的地位。
作用如下:
- 主要用于多服務器的負載均衡。
- 工作在網絡層,可實現高性能,高可用的服務器集群技術。
- 廉價,可把許多低性能的服務器組合在一起形成一個超級服務器。
- 易用,配置簡單,有多種負載均衡的方法。
- 穩定可靠,即使在集群的服務器中某臺服務器無法正常工作,也不影響整體效果。
- 可擴展性好。
負載均衡的由來及所帶來的好處
在業務剛起步時,一般先使用單臺服務器對外進行提供服務。隨著后期的業務增長,流量也越來越大。
當這單臺服務器的訪問量越大時,服務器所承受的壓力也就越大,性能也將無法滿足業務需求,超出自身所指定的訪問壓力就會崩掉,避免發生此類事情的發生。
我們將采取其他方案,將多臺服務器組成集群系統從而來提高整體服務器的處理性能,使用統一入口(流量調度器)的方式通過均衡的算法進行對外提供服務,將用戶大量的請求均衡地分發到后端集群不同的服務器上。
因此也就有了負載均衡來分擔服務器的壓力。使用負載均衡給我們所帶來的好處:提高系統的整體性能、提高系統的擴展性、提高系統的高可用性。
LVS 負載均衡集群的類型
負載均衡群集:Load Balance Cluster,以提高應用系統的響應能力,盡可能處理更多的訪問請求、減少延遲為目標,從而獲得高并發、高負載的整體性能。
高可用群集:High Availability Cluster,以提高應用系統的可靠性,盡可能的減少終端時間為目標、確保服務的連續性,達到高可用的容錯效果。
高性能運算群集:High Performance Computer Cluster,以提高應用系統的 CPU 運算速度、擴展硬件資源和分析能力為目標、從而獲得相當于大型、超級計算機的高性能計算能力。
DNS/軟硬件負載均衡的類型
①DNS 實現負載均衡
一個域名通過 DNS 解析到多個 IP,每個 IP 對應不同的服務器實例,就完成了流量的調度,這也是 DNS 實現負載均衡是最簡單的方式。
使用該方式最大的優點:實現簡單,成本低,無需自己開發或維護負載均衡設備。
不過存在一些缺點:服務器故障切換延遲大,升級不方便、流量調度不均衡,粒度大、流量分配策略較簡單,支持的算法較少、DNS 所支持的 IP 列表有限制要求。
②硬件負載均衡
硬件負載均衡是通過專門的硬件設備從而來實現負載均衡功能,比如:交換機、路由器就是一個負載均衡專用的網絡設備。
目前典型的硬件負載均衡設備有兩款:F5 和 A10。不過話說,能用上這種硬件負載均衡設備的企業都不是一般的公司,反而普通業務量級小的其他企業基本用不到。
硬件負載均衡的優點:
- 功能強大:支持各層級負載均衡及全面負載均衡算法。
- 性能強大:性能遠超常見的軟件負載均衡器。
- 穩定性高:硬件負載均衡,大規模使用肯定是嚴格測試過的。
- 安全防護:除具備負載均衡功能外,還具備防火墻、防 DDoS 攻擊等安全功能。
硬件負載均衡的缺點:
- 價格昂貴。
- 可擴展性差。
- 調試維護麻煩。
③軟件負載均衡
軟件負載均衡有如下幾種:
- Nginx:支持 4 層/7 層負載均衡,支持 HTTP、E-mail 協議。
- LVS:純 4 層負載均衡,運行在內核態,性能是軟件負載均衡中最高的。
- HAproxy:是 7 層負載均衡軟件,支持 7 層規則的設置,性能也不錯。
軟件負載均衡的優點:簡單、靈活、便宜(直接在 Linux 操作系統上安裝上述所使用的軟件負載均衡,部署及維護較簡單,4 層 和 7 層負載均衡可根據業務進行選擇也可根據業務特點,比較方便進行擴展及定制功能)。
LVS 集群的通用體系結構
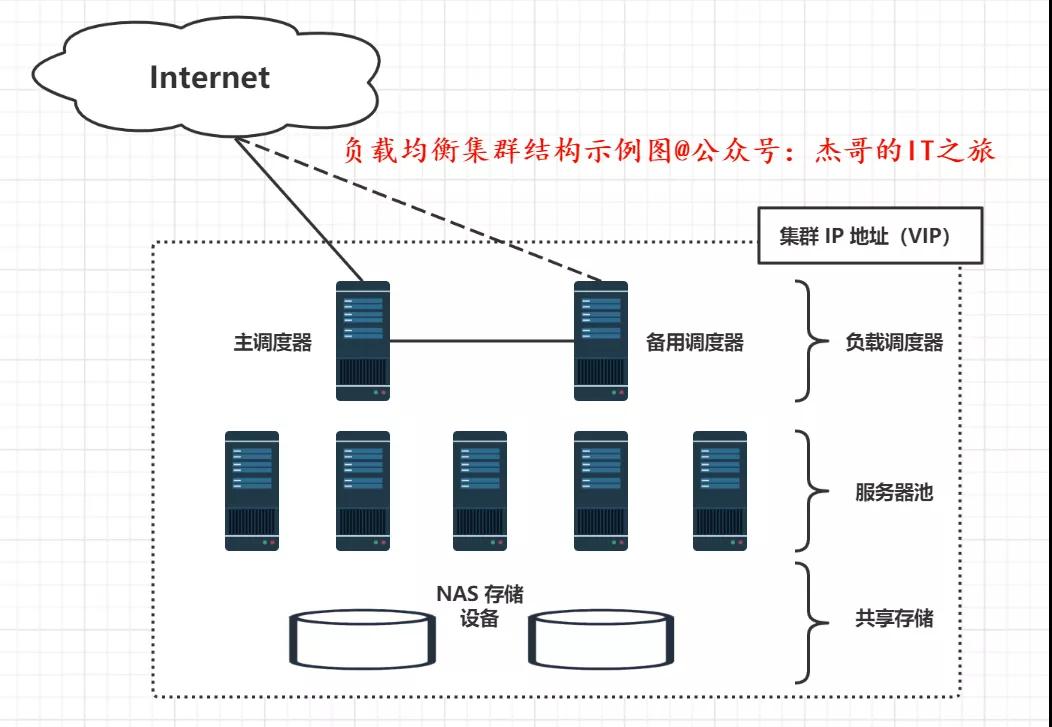
第一層:負載調度器:Load Balancer,它是訪問整個群集系統的唯一入口,對外使用所有服務器共有的虛擬 IP 地址,也成為群集 IP 地址。
負載均衡器:是服務器群集系統的單個入口點,可運行 IPVS,該 IPVS 在 Linux 內核或 KTCPVS 內部實現 IP 負載均衡技術,在 Linux 內核中實現應用程序級負載平衡。
使用 IPVS 時,要求所有服務器提供相同的服務和內容,負載均衡器根據指定的調度算法和每個服務器的負載將新的客戶端請求轉發到服務器。無論選擇哪個服務器,客戶端都應獲得相同的結果。
使用 KTCPVS 時,服務器可以具有不同的內容,負載均衡器可以根據請求的內容將請求轉發到其他服務器。
由于 KTCPVS 是在 Linux 內核內部實現的,因此中繼數據的開銷很小,因此仍可以具有較高的吞吐量。
第二層:服務器池 Server Pool,群集所提供的應用服務,比如:HTTP、FTP 服務器池來承擔,每個節點具有獨立的真實 IP 地址,只處理調度器分發過來的客戶機請求。
服務器群集的節點可根據系統所承受的負載進行分擔。當所有服務器過載時,可添加多臺服務器來處理不斷增加的工作負載。
對于大多數 Internet 服務(例如Web),請求通常沒有高度關聯,并且可以在不同服務器上并行運行。因此,隨著服務器群集的節點數增加,整體性能幾乎可以線性擴展。
第三層:共享存儲 Shared Storage,為服務器池中的所有節點提供穩定、一致的文件存儲服務,確保整個群集的統一性,可使用 NAS 設備或提供 NFS (Network File System)網絡文件系統共享服務的專用服務器。
共享存儲:可以是數據庫系統,網絡文件系統或分布式文件系統。服務器節點需要動態更新的數據應存儲在基于數據的系統中,當服務器節點并行在數據庫系統中讀寫數據時,數據庫系統可以保證并發數據訪問的一致性。
靜態數據通常保存在網絡文件系統(例如 NFS 和 CIFS)中,以便可以由所有服務器節點共享數據。
但是,單個網絡文件系統的可伸縮性受到限制,例如,單個 NFS / CIFS 只能支持 4 到 8 個服務器的數據訪問。
對于大型集群系統,分布式/集群文件系統可以用于共享存儲,例如 GPFS,Coda 和 GFS,然后共享存儲也可以根據系統需求進行擴展。
LVS 負載均衡的基本原理
Netfilter 的基本原理
在介紹 LVS 負載均衡基本原理之前,先說一下 Netfilter 的基本原理。因為 LVS 是基于 Linux 內核中 Netfilter 框架實現的負載均衡系統。
Netfilter 其實很復雜也很重要,平時說的 Linux 防火墻就是 Netfilter,不過我們操作的還是 iptables,iptables 和 Netfilter 是 Linux 防火墻組合工具,是一起來完成系統防護工作的。
iptables 是位于用戶空間,而 Netfilter 是位于內核空間。iptables 只是用戶空間編寫和傳遞規則的工具而已,真正工作的還是 Netfilter。
兩者間的區別:Netfilter 是內核態的 Linux 防火墻機制,它作為一個通用、抽象的框架,提供了一整套的 hook 函數管理機制,提供數據包過濾、網絡地址轉換、基于協議類型的連接跟蹤的功能,可在數據包流經過程中,根據規則設置若干個關卡(hook 函數)來執行相關操作。
它共設置了 5 個點,包括:
- prerouting:在對數據包做路由選擇之前,將應用此鏈中的規則。
- input:當收到訪問防火墻本機地址的數據包時,將應用此鏈中的規則。
- forward:當收到需要通過防火中轉發給其他地址的數據包時,將應用此鏈中的規則。
- output:當防火墻本機向外發送數據包時,將應用此鏈中的規則。
- postrouting:在對數據包做路由選擇之后,將應用此鏈中的規則。
iptable 是用戶層的工具,提供命令行接口,能夠向 Netfilter 中添加規則策略,從而實現報文過濾,修改等功能。
通過下圖我們可以來了解下 Netfilter 的工作機制:
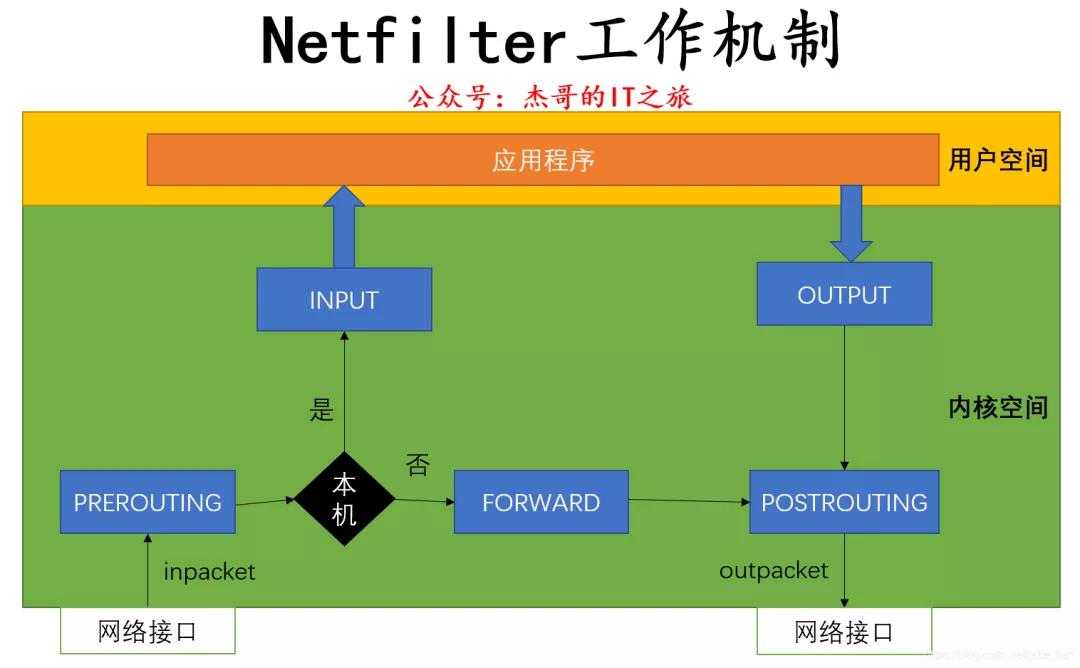
當數據包通過網絡接口進入時,經過鏈路層之后進入網絡層到達PREROUTING,然后根據目標 IP 地址進行查找路由。
如目標 IP 是本機,數據包會傳到 INPUT 上,經過協議棧后根據端口將數據送到相應的應用程序;應用程序將請求處理后把響應數據包發送至 OUTPUT 里,最終通過 POSTROUTING 后發送出網絡接口。
如目標 IP 不是本機,并且服務器開啟了 FORWARD 參數,這時會將數據包遞送給 FORWARD,最后通過 POSTROUTING 后發送出網絡接口。
LVS 的基本原理
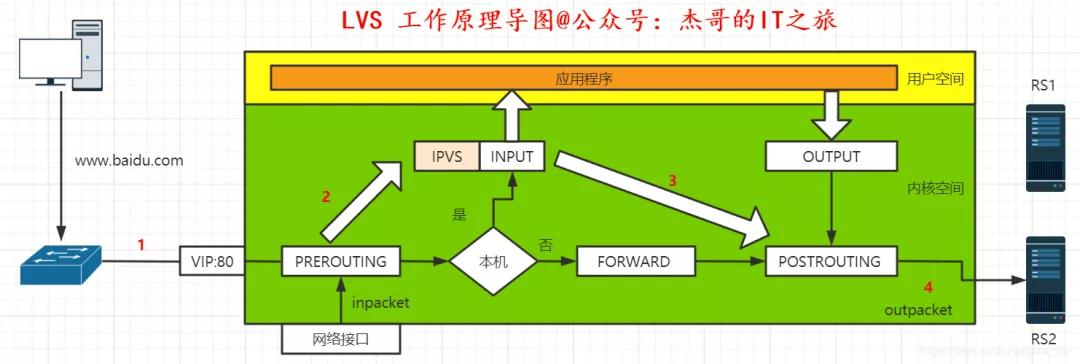
LVS 基于 Netfilter 框架,工作在 INPUT 鏈上,在 INPUT 鏈上注冊 ip_vs_in HOOK 函數,進行 IPVS 相關主流程。
詳細原理概述如下:
①當客戶端用戶訪問 www.baidu.com 網站時,用戶訪問請求通過層層網絡,最終通過交換機進入 LVS 服務器網卡進入內核空間層。
②進入 PREROUTING 后通過查找路由,確定訪問目的 VIP 是本機 IP 地址的話,數據包將進入 INPUT 鏈中。
③因為 IPVS 工作在 INPUT 鏈上,會根據訪問的 VIP 和端口判斷請求是否為 IPVS 服務,是的情況下,則調用注冊的 IPVS HOOK 函數,進行 IPVS 相關流程,并強制修改數據包的相關數據,并將數據包發往 POSTROUTING 鏈中。
④POSTROUTING 鏈收到數據包后,將根據目標 IP 地址服務器,通過路由選路,將數據包最終發送至后端真實服務器中。
上面就是我們所介紹的 LVS 的工作原理,那么 LVS 負載均衡還包括三種工作模式,且每種模式工作原理都有所不同,適用于不同應用場景,其最終目的都是能實現均衡的流量調度和良好的擴展性。
LVS 負載均衡的三種工作模式
群集的負載調度技術,可基于 IP、端口、內容等進行分發,其中基于 IP 的負載均衡是效率最高的。
基于 IP 的負載均衡模式,常見的有地址轉換(NAT)、IP 隧道(TUN)和直接路由(DR)三種工作模式。
NAT 模式
地址轉換:Network Address Translation,簡稱:NAT 模式,類似于防火墻的私有網絡結構,負載調度器作為所有服務器節點的網關,作為客戶機的訪問入口,也是各節點回應客戶機的訪問出口,服務器節點使用私有 IP 地址,與負載調度器位于同一個物理網絡,安全性要優于其他兩種方式。
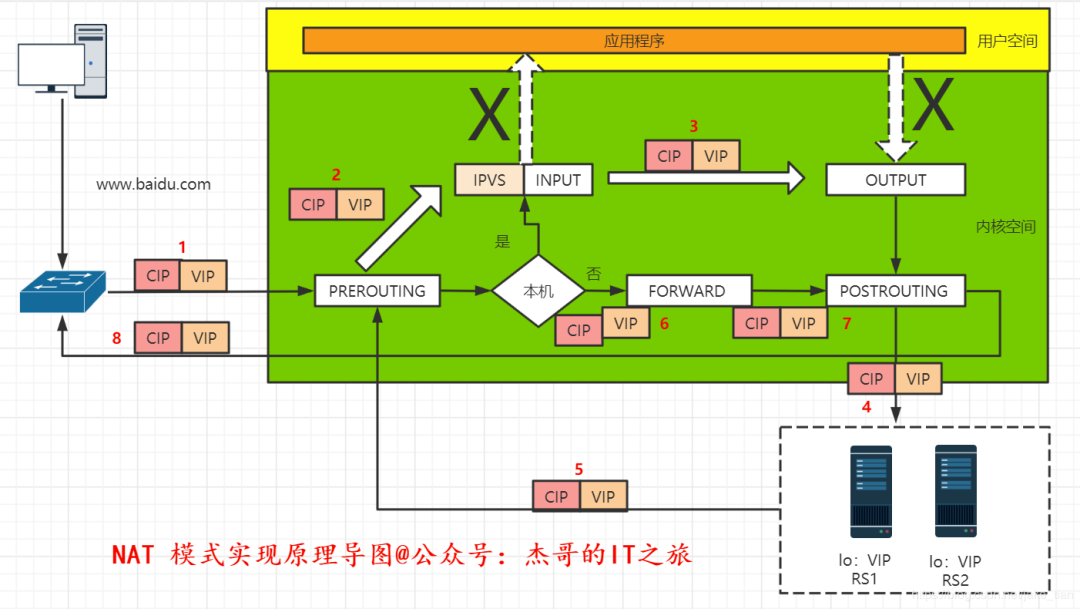
NAT 實現原理過程如下:
①客戶端發出的請求數據包經過網絡到達 LVS 網卡,數據包源 IP 為 CIP,目的 IP 為 VIP。
②然后進入 PREROUTING 鏈中,根據目的 IP 查找路由,確定是否為本機 IP 地址,隨后將數據包轉發至 INPUT 鏈中,源 IP 和 目的 IP 不變。
③到達 LVS 后,通過目的 IP 和目的 PORT 查找是否為 IPVS 服務,如是 IPVS 服務,將會選擇一個 RS 來作為后端服務器,數據包的目的 IP 地址將會修改為 RIP,這時并以 RIP 為目的 IP 去查找路由,確定下一跳及 PORT 信息后,數據包將會轉發至 OUTPUT 鏈中。
④被修改過的數據包經過 POSTROUTING 鏈后,到達 RS 服務器,數據包源 IP 為 CIP,目的 IP 為 RIP。
⑤RS 服務器經過處理后,將會把數據包發送至用戶空間的應用程序,待處理完成后,發送響應數據包,RS 服務器的默認網關為 LVS 的 IP,應用程序將會把數據包轉發至下一跳 LVS 服務器,數據包源 IP 為 RIP,目的 IP 為 CIP。
⑥LVS 服務器收到 RS 服務器響應的數據包后,查找路由,目的 IP 不是本機 IP并且 LVS 服務器開啟了 FORWARD 模式,會將數據包轉發給它,數據包不變。
⑦LVS 服務器收到響應數據包后,根據目的 IP 和 目的 PORT 查找相應的服務,這時,源 IP 為 VIP,通過查找路由,確定下一跳信息并將數據包發送至網關,最終回應給客戶端用戶。
NAT 模式的優點:
- 支持 Windows 操作系統。
- 支持端口映射,如 RS 服務器 PORT 與 VPORT 不一致的話,LVS 會修改目的 IP 地址和 DPORT 以支持端口映射。
NAT 模式的缺點:
- RS 服務器需配置網關。
- 雙向流量對 LVS 會產生較大的負載壓力。
NAT 模式的使用場景:對 Windows 操作系統的用戶比較友好,使用 LVS ,必須選擇 NAT 模式。
TUN 模式
IP 隧道:IP Tunnel,簡稱:TUN 模式,采用開放式的網絡結構,負載調度器作為客戶機的訪問入口,各節點通過各自的 Internet 連接直接回應給客戶機,而不經過負載調度器,服務器節點分散在互聯網中的不同位置,有獨立的公網 IP 地址,通過專用 IP 隧道與負載調度器相互通信。

TUN 實現原理過程如下:
①客戶端發送數據包經過網絡后到 LVS 網卡,數據包源 IP 為 CIP,目的 IP 為 VIP。
②進入 PREROUTING 鏈后,會根據目的 IP 去查找路由,確定是否為本機 IP,數據包將轉發至 INPUT 鏈中,到 LVS,源 IP 和 目的 IP 不變。
③到 LVS 后,通過目的 IP 和目的 PORT 查找是否為 IPVS 服務,如是 IPVS 服務,將會選擇一個 RS 后端服務器, 源 IP 為 DIP,目標 IP 為 RIP,數據包將會轉發至 OUTPUT 鏈中。
④數據包根據路由信息到達 LVS 網卡,發送至路由器網關,最終到達后端服務器。
⑤后端服務器收到數據包后,會拆掉最外層的 IP 地址后,會發現還有一層 IP 首部,源 IP 為 CIP,目的 IP 為 VIP,TUNL0 上配置 VIP,查找路由后判斷為本機 IP 地址,將會發給用戶空間層的應用程序響應后 VIP 為源 IP,CIP 為目的 IP 數據包發送至網卡,最終返回至客戶端用戶。
TUN 模式的優點:
- 單臂模式,LVS 負載壓力小。
- 數據包修改小,信息完整性高。
- 可跨機房。
TUN 模式的缺點:
- 不支持端口映射。
- 需在 RS 后端服務器安裝模塊及配置 VIP。
- 隧道頭部 IP 地址固定,RS 后端服務器網卡可能會不均勻。
- 隧道頭部的加入可能會導致分片,最終會影響服務器性能。
TUN 模式的使用場景:如對轉發性要求較高且具有跨機房需求的,可選擇 TUN 模式。
DR 模式
直接路由:Direct Routing,簡稱 DR 模式,采用半開放式的網絡結構,與 TUN 模式的結構類似,但各節點并不是分散在各個地方,而是與調度器位于同一個物理網絡,負載調度器與各節點服務器通過本地網絡連接,不需要建立專用的 IP 隧道。它是最常用的工作模式,因為它的功能性強大。
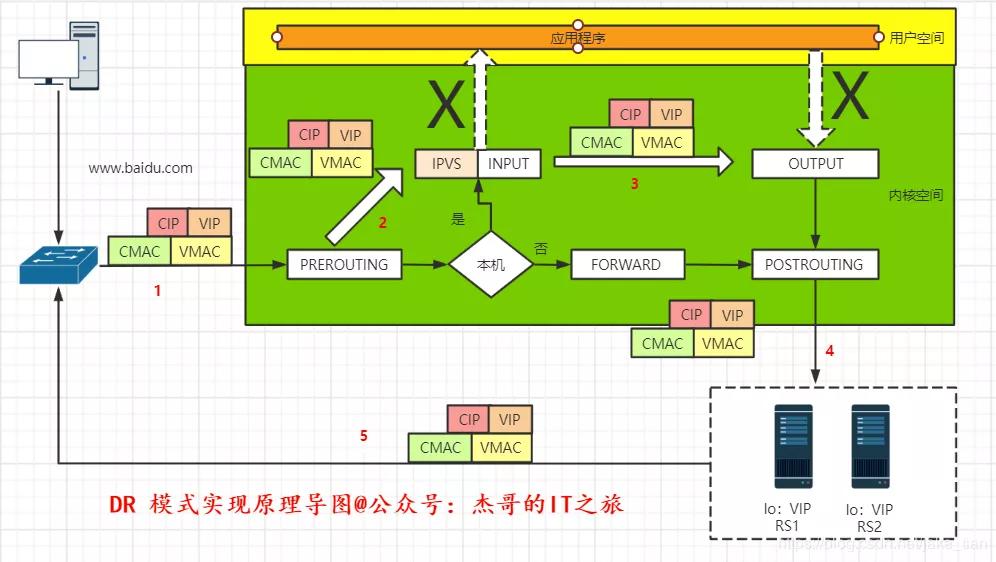
DR 實現原理過程如下:
①當客戶端用戶發送請求給 www.baidu.com 網站時,首先經過 DNS 解析到 IP 后并向百度服務器發送請求,數據包經過網絡到百度 LVS 負載均衡服務器。
這時到達 LVS 網卡時的數據包包括:源 IP 地址(客戶端地址)、目的 IP 地址(百度對外服務器 IP 地址,也就是 VIP)、源 MAC 地址(CMAC / LVS 連接路由器的 MAC 地址)、目標 MAC 地址(VMAC / VIP 對應的 MAC 地址)。
②數據包到達網卡后,經過鏈路層到達 PREROUTING 鏈,進行查找路由,發現目的 IP 是 LVS 的 VIP,這時就會發送至 INPUT 鏈中并且數據包的 IP 地址、MAC 地址、Port 都未經過修改。
③數據包到達 INPUT 鏈中,LVS 會根據目的 IP 和 Port(端口)確認是否為 LVS 定義的服務。
如是定義過的 VIP 服務,會根據配置的服務信息,從 RealServer 中選擇一個后端服務器 RS1,然后 RS1 作為目標出方向的路由,確定下一跳信息及數據包通過具體的哪個網卡發出,最好將數據包通過 INET_HOOK 到 OUTPUT 鏈中。
④數據包通過 POSTROUTING 鏈后,目的 MAC 地址將會修改為 RealServer 服務器 MAC 地址(RMAC)源 MAC 地址修改為 LVS 與 RS 同網段的 IP 地址的 MAC 地址(DMAC)此時,數據包將會發至 RealServer 服務器。
⑤數據包到達 RealServer 服務器后,發現請求報文的 MAC 地址是自己的網卡 MAC 地址,將會接受此報文,待處理完成之后,將響應報文通過 lo 接口傳送給 eth0 網卡然后向外發出。
此時的源 IP 地址為 VIP,目標 IP 為 CIP,源 MAC 地址為 RS1 的 RMAC,目的 MAC 地址為下一跳路由器的 MAC 地址(CMAC),最終數據包通過 RS 相連的路由器轉發給客戶端。
DS 模式的優點:
- 響應數據不經過 LVS,性能高。
- 對數據包修改小,信息完整性好。
DS 模式的缺點:
- LVS 與 RS 必須在同一個物理網絡。
- RS 上必須配置 lo 和其他內核參數。
- 不支持端口映射。
DS 模式的使用場景:對性能要求高的,可首選 DR 模式,還可透傳客戶端源 IP 地址。
NAT 模式:只需一個公網 IP 地址,是最易用的一種負載均衡模式,安全性較好。
TUN 模式 和 DR 模式:負載能力強大、適用范圍廣、節點安全性較差。
LVS 的十種負載調度算法
LVS 的十種負載調度算法如下:
①輪詢:Round Robin,將收到的訪問請求按順序輪流分配給群集中的各節點真實服務器中,不管服務器實際的連接數和系統負載。
②加權輪詢:Weighted Round Robin,根據真實服務器的處理能力輪流分配收到的訪問請求,調度器可自動查詢各節點的負載情況,并動態跳轉其權重,保證處理能力強的服務器承擔更多的訪問量。
③最少連接:Least Connections,根據真實服務器已建立的連接數進行分配,將收到的訪問請求優先分配給連接數少的節點,如所有服務器節點性能都均衡,可采用這種方式更好的均衡負載。
④加權最少連接:Weighted Least Connections,服務器節點的性能差異較大的情況下,可以為真實服務器自動調整權重,權重較高的節點將承擔更大的活動連接負載。
⑤基于局部性的最少連接:LBLC,基于局部性的最少連接調度算法用于目標 IP 負載平衡,通常在高速緩存群集中使用。
如服務器處于活動狀態且處于負載狀態,此算法通常會將發往 IP 地址的數據包定向到其服務器;如果服務器超載(其活動連接數大于其權重),并且服務器處于半負載狀態,則將加權最少連接服務器分配給該 IP 地址。
⑥復雜的基于局部性的最少連接:LBLCR,具有復雜調度算法的基于位置的最少連接也用于目標 IP 負載平衡,通常在高速緩存群集中使用。
與 LBLC 調度有以下不同:負載平衡器維護從目標到可以為目標提供服務的一組服務器節點的映射。對目標的請求將分配給目標服務器集中的最少連接節點。
如果服務器集中的所有節點都超載,則它將拾取群集中的最少連接節點,并將其添加到目標服務器群中;如果在指定時間內未修改服務器集群,則從服務器集群中刪除負載最大的節點,以避免高度負載。
⑦目標地址散列調度算法:DH,該算法是根據目標 IP 地址通過散列函數將目標 IP 與服務器建立映射關系,出現服務器不可用或負載過高的情況下,發往該目標 IP 的請求會固定發給該服務器。
⑧源地址散列調度算法:SH,與目標地址散列調度算法類似,但它是根據源地址散列算法進行靜態分配固定的服務器資源。
⑨最短延遲調度:SED,最短的預期延遲調度算法將網絡連接分配給具有最短的預期延遲的服務器。
如果將請求發送到第 i 個服務器,則預期的延遲時間為(Ci +1)/Ui,其中 Ci 是第 i 個服務器上的連接數,而 Ui 是第 i 個服務器的固定服務速率(權重) 。
⑩永不排隊調度:NQ,從不隊列調度算法采用兩速模型。當有空閑服務器可用時,請求會發送到空閑服務器,而不是等待快速響應的服務器。
如果沒有可用的空閑服務器,則請求將被發送到服務器,以使其預期延遲最小化(最短預期延遲調度算法)。
LVS 涉及相關的術語及說明
上述內容中涉及到很多術語或縮寫,這里簡單解釋下具體的含義,便于理解:
- DS:Director Server,前端負載均衡節點服務器。
- RS:Real Server,后端真實服務器。
- CIP:Client IP,客戶端 IP 地址。
- VIP:Virtual IP,負載均衡對外提供訪問的 IP 地址,一般負載均衡 IP 都會通過 Virtual IP 實現高可用。
- RIP:RealServer IP,負載均衡后端的真實服務器 IP 地址。
- DIP:Director IP,負載均衡與后端服務器通信的 IP 地址。
- CMAC:客戶端 MAC 地址,LVS 連接的路由器的 MAC 地址。
- VMAC:負載均衡 LVS 的 VIP 對應的 MAC 地址。
- DMAC:負載均衡 LVS 的 DIP 對應的 MAC 地址。
- RMAC:后端真實服務器的 RIP 地址對應的 MAC 地址。
總結
回顧下,通過本文你可學習到什么是 LVS、為什么要用 LVS、LVS 的組成及工作原理等。
參考文獻:
- http://www.linuxvirtualserver.org/
- http://www.linuxvirtualserver.org/how.html
- http://www.linuxvirtualserver.org/Documents.html