老板讓我從幾百個Excel中查找數據,我用Python一分鐘搞定!
大家好,又到了Python辦公自動化系列。
今天分享一個真實的辦公自動化需求,大家一定要仔細閱讀需求說明,在理解需求之后即可體會Python的強大!
一、需求說明
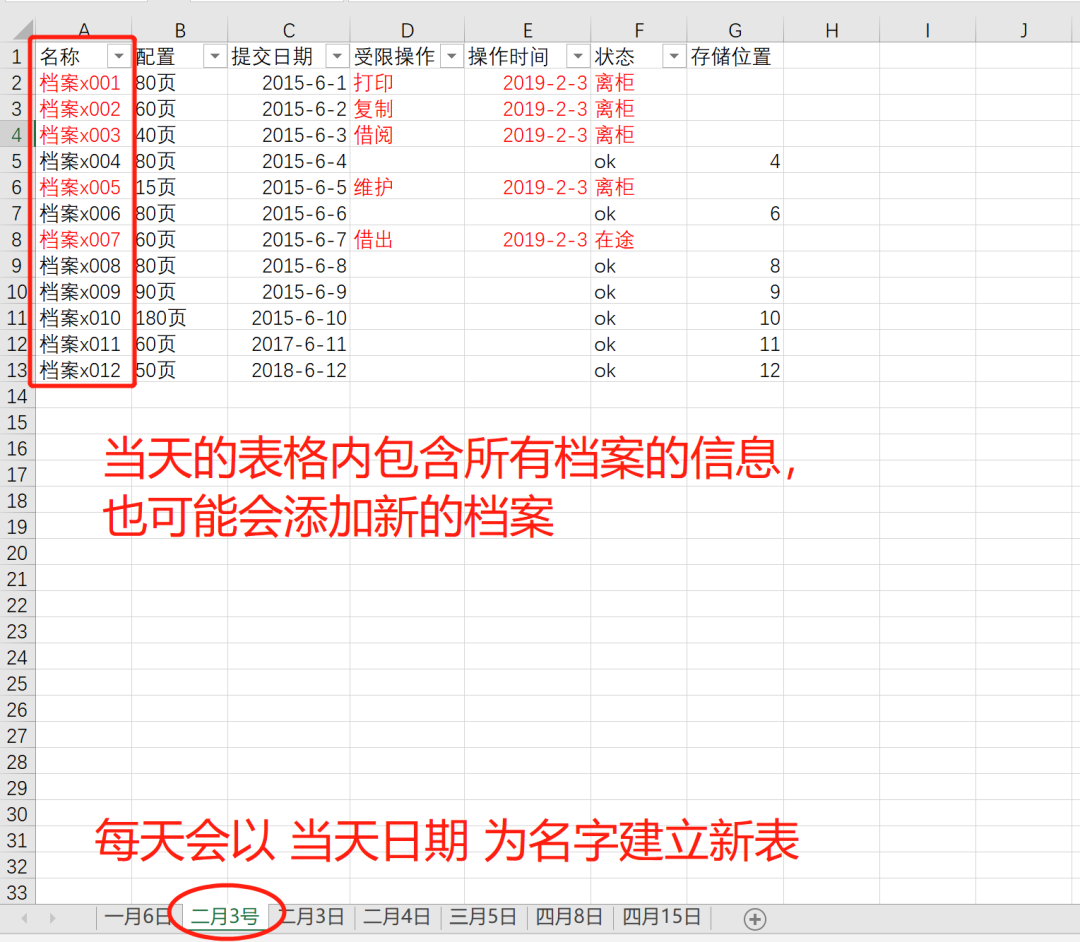
首先我們來看下今天的需求,有一份檔案記錄總表的Excel工作簿, 每天會根據當天日期建立新表,每天的表格內包含所有檔案信息,同時也有可能會添加新的檔案名。同個年度的總表在年末可能會有兩、三百個工作表,同時每個表中可能也存在千余份檔案信息。表格形式如下(為了直觀呈現本例以7個工作表和十余份檔案的形式呈現)
需要完成的操作:為了方便審查特定檔案信息,需要給出檔案名后生成一份新表,該表包含指定檔案在所有日期(即所有工作表)中的記錄。最終結果如下(以檔案x003為例):
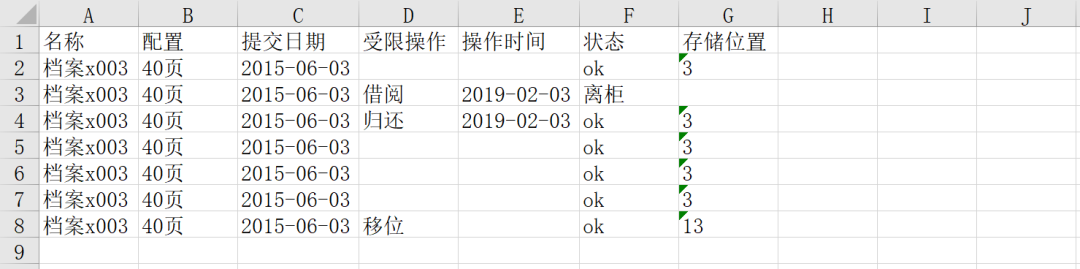
也就是老板說:給我把這幾百個表格中所有包含檔案x003的相關數據全部找到并整理個新的表格給我!
二、步驟分析
正式寫代碼前可以把需求分析清楚,將復雜問題簡單化。
說白了,這個需求要求把所有日期工作表中的特定行都提取出來整合成一個新表。那么我們可以遍歷每一張表,然后遍歷第一列(名稱列,也可以看作A列)每一個有數據的單元格,如果單元格中的文字為我們需要的檔案名,就把這一行提取出來放到新的表格中,進一步梳理步驟為
- 建立一個新的EXCEL工作簿
- 新表的表頭和檔案記錄Excel中的一樣,也是名稱、配置、提交日期等
- 遍歷檔案記錄Excel的每一張工作表sheet,再遍歷第一列每一個有數據的單元格,對內容進行判斷
- 找到符合條件的單元格后獲取行號,根據行號將當前表中的特定行提取出來,并將行追加新創建的表中
分析清楚就可以著手寫代碼了
三、Python實現
首先導入需要的庫本例中涉及舊表的打開和新表的創建,因此需要從openpyxl導入load_workbook和Workbook(如果是ppt和word用到的模塊就更智能了,一個方法就能搞定)
- from openpyxl import load_workbook, Workbook
接著導入舊表及創建新表
- # 從桌面上獲取總表
- filepath = r'C:\Users\chenx\Desktop\臺賬.xlsm' # 根據實際情況進行修改
- workbook = load_workbook(filepath)
- # 創建新的Excel工作簿獲取到工作表
- new_workbook = Workbook()
- new_sheet = new_workbook.active
- # 給新表寫入表頭
- new_headers = ['名稱', '配置', '提交日期', '受限操作', '操作時間', '狀態', '存儲位置']
- new_sheet.append(new_headers)
現在是核心步驟:多次遍歷,可以用workbook.sheetnames獲取工作簿所有工作表名稱的列表,然后遍歷即可
- for i in workbook.sheetnames:
- sheet = workbook[i]
- # 獲取檔案名稱所在列
- names = sheet['A']
按照前面的分析,需要遍歷名稱列,判斷每一個單元格的值是不是需要的檔案名。這里應注意,如果已經循環到需要的單元格,就可以停止循環了,但一定要把符合單元格的行號傳遞給一個變量做記錄,不然一旦break出循環就沒有記憶了
- flag = 0
- for cell in names:
- if cell.value == keyword: # 這里的keyword就是檔案名,可以以 檔案x003 為例
- flag = cell.row
- break
獲得到符合條件的行號后用sheet[flag]就可以拿到符合行了。openpyxl不支持舊表的一整行寫入新表,因此應對策略就是將這一行的所有單元格具體值組裝成一個列表,用sheet.append(列表)的方法寫入新表,遍歷部分的完整代碼如下:
- for i in workbook.sheetnames:
- sheet = workbook[i]
- names = sheet['A']
- flag = 0
- for cell in names:
- if cell.value == keyword:
- flag = cell.row
- break
- if flag: # 如果flag沒有被修改則不需要順序進行下列代碼
- data_lst = []
- for cell in sheet[flag]:
- # 這里加上一個對內容的判斷,是讓無內容的行直接放空,而不是寫入一個 none
- if cell.value:
- data_lst.append(str(cell.value))
- else:
- data_lst.append(' ')
- new_sheet.append(data_lst)
最后記得保存
- new_workbook.save(r'C:\Users\chenx\Desktop\臺賬查詢.xlsx')
小結
這是經過一定改編的真實案例,可見Python自動化辦公確實能夠幫助我們解放自己的雙手,不過在寫自動化腳本之前也要先拆分任務,明確思路再進行,如果對本文的代碼和數據感興趣可以在后臺回復自動化獲取。最后還是希望大家能夠理解Python辦公自動化的一個核心就是批量操作-解放雙手,讓復雜的工作自動化!