













DJL 如何正確打開 [ 深度學(xué)習(xí) ]
本文轉(zhuǎn)載自微信公眾號「小明菜市場」,作者小明菜市場。轉(zhuǎn)載本文請聯(lián)系小明菜市場公眾號。
前言
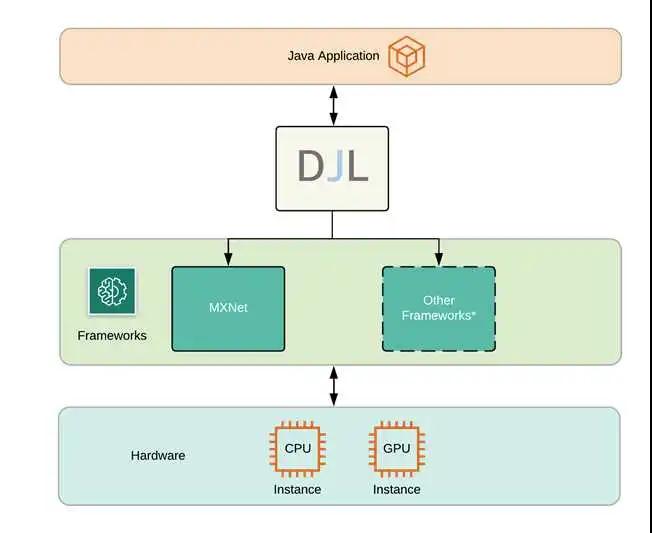
很長時間,Java都是一個相當受歡迎的企業(yè)編程語言,其框架豐富,生態(tài)完善。Java擁有龐大的開發(fā)者社區(qū),盡管深度學(xué)習(xí)應(yīng)用不斷推進和演化,但是相關(guān)的深度學(xué)習(xí)框架對于Java來說相當?shù)南∩伲F(xiàn)如今,主要模型都是Python編譯和訓(xùn)練,對于Java開發(fā)者來說,如果想要學(xué)習(xí)深度學(xué)習(xí),就需要接受一門新的語言的洗禮。為了減少Java開發(fā)者學(xué)習(xí)深度學(xué)習(xí)的成本,AWS構(gòu)建了一個Deep Java Library(DJL),一個為Java開發(fā)者定制的開源深度學(xué)習(xí)框架,其為開發(fā)者對接主流深度學(xué)習(xí)框架,提供了一個接口。
什么是深度學(xué)習(xí)
在開始之前,先了解機器學(xué)習(xí)和深度學(xué)習(xí)基礎(chǔ)概念。機器學(xué)習(xí)是一個利用統(tǒng)計學(xué)知識,把數(shù)據(jù)輸入到計算機中進行訓(xùn)練并完成特定目標任務(wù)的過程,這種歸納學(xué)習(xí)方法可以讓計算機學(xué)習(xí)一些特征并進行一系列復(fù)雜的任務(wù),比如識別照片中的物體。深度學(xué)習(xí)是機器學(xué)習(xí)的一個分支,主要側(cè)重于對于人工神經(jīng)網(wǎng)絡(luò)的開發(fā),人工神經(jīng)網(wǎng)絡(luò)是通過研究人腦如何學(xué)習(xí)和實現(xiàn)目標的過程中,歸納出的一套計算邏輯。通過模擬部分人腦神經(jīng)間信息傳遞的過程,從而實現(xiàn)各種復(fù)雜的任務(wù),深度學(xué)習(xí)中的深度來源于會在人工神經(jīng)網(wǎng)絡(luò)中編制出,構(gòu)建出許多層,從而進一步對數(shù)據(jù)信息進行更為深層次的傳導(dǎo)。
訓(xùn)練 MNIST 手寫數(shù)字識別
項目配置
利用 gradle 配置引入依賴包,用DJL的api包和basicdataset包來構(gòu)建神經(jīng)網(wǎng)絡(luò)和數(shù)據(jù)集,這個案例,使用 MXNet作為深度學(xué)習(xí)引擎,所以引入mxnet-engine和mxnet-native-auto兩個包,依賴如下
- plugins {
- id 'java'
- }
- repositories {
- jcenter()
- }
- dependencies {
- implementation platform("ai.djl:bom:0.8.0")
- implementation "ai.djl:api"
- implementation "ai.djl:basicdataset"
- // MXNet
- runtimeOnly "ai.djl.mxnet:mxnet-engine"
- runtimeOnly "ai.djl.mxnet:mxnet-native-auto"
- }
NDArry 和 NDManager
NDArray 是 DJL 存儲數(shù)據(jù)結(jié)構(gòu)和數(shù)學(xué)運算的基本結(jié)構(gòu),一個NDArry表達了一個定長的多維數(shù)組,NDArry的使用方法,類似于Python的numpy.ndarry。NDManager是NDArry的管理者,其負責(zé)管理NDArry的產(chǎn)生和回收過程,這樣可以幫助我們更好的對Java內(nèi)存進行優(yōu)化,每一個NDArry都會由一個NDManager創(chuàng)造出來,同時他們會在NDManager關(guān)閉時一同關(guān)閉,
Model
在 DJL 中,訓(xùn)練和推理都是從 Model class 開始構(gòu)建的,我們在這里主要訓(xùn)練過程中的構(gòu)建方法,下面我們?yōu)?Model 創(chuàng)建一個新的目標,因為 Model 也是繼承了 AutoClosable 結(jié)構(gòu)體,用一個 try block實現(xiàn)。
- try (Model model = Model.newInstance()) {
- ...
- // 主體訓(xùn)練代碼
- ...
- }
準備數(shù)據(jù)
MNIST 數(shù)據(jù)庫包含大量的手寫數(shù)字的圖,通常用來訓(xùn)練圖像處理系統(tǒng),DJL已經(jīng)把MNIST的數(shù)據(jù)收集到了 basicdataset 數(shù)據(jù)里,每個 MNIST 的圖的大小是 28 * 28, 如果有自己的數(shù)據(jù)集,同樣可以使用同理來收集數(shù)據(jù)。
數(shù)據(jù)集導(dǎo)入教程 http://docs.djl.ai/docs/development/how_to_use_dataset.html#how-to-create-your-own-dataset
- int batchSize = 32; // 批大小
- Mnist trainingDataset = Mnist.builder()
- .optUsage(Usage.TRAIN) // 訓(xùn)練集
- .setSampling(batchSize, true)
- .build();
- Mnist validationDataset = Mnist.builder()
- .optUsage(Usage.TEST) // 驗證集
- .setSampling(batchSize, true)
- .build();
這段代碼分別制作了訓(xùn)練和驗證集,同時我們也隨機的排列了數(shù)據(jù)集從而更好的訓(xùn)練,除了這些配置以外,也可以對圖片進行進一步的設(shè)置,例如設(shè)置圖片大小,歸一化處理。
制作 model 建立 block
當數(shù)據(jù)集準備就緒以后,就可以構(gòu)建神經(jīng)網(wǎng)絡(luò),在DJL 中,神經(jīng)網(wǎng)絡(luò)是由 Block 代碼塊構(gòu)成的,一個Block是一個具備多種神經(jīng)網(wǎng)絡(luò)特性的結(jié)構(gòu),他們可以代表一個操作神經(jīng)網(wǎng)絡(luò)的一部分,甚至一個完整的神經(jīng)網(wǎng)絡(luò),然后 block 就可以順序的執(zhí)行或者并行。同時 block 本身也可以帶參數(shù)和子block,這種嵌套結(jié)構(gòu)可以快速的幫助更新一個可維護的神經(jīng)網(wǎng)絡(luò),在訓(xùn)練過程中,每個block附帶參數(shù)也會實時更新,同時也會更新其子 block。當我們構(gòu)建這些 block 的過程中,最簡單的方式就是把他們一個一個嵌套起來,直接使用準備好的 DJL的 Block 種類,我們就可以快速制作各種神經(jīng)網(wǎng)絡(luò)。
block 變體
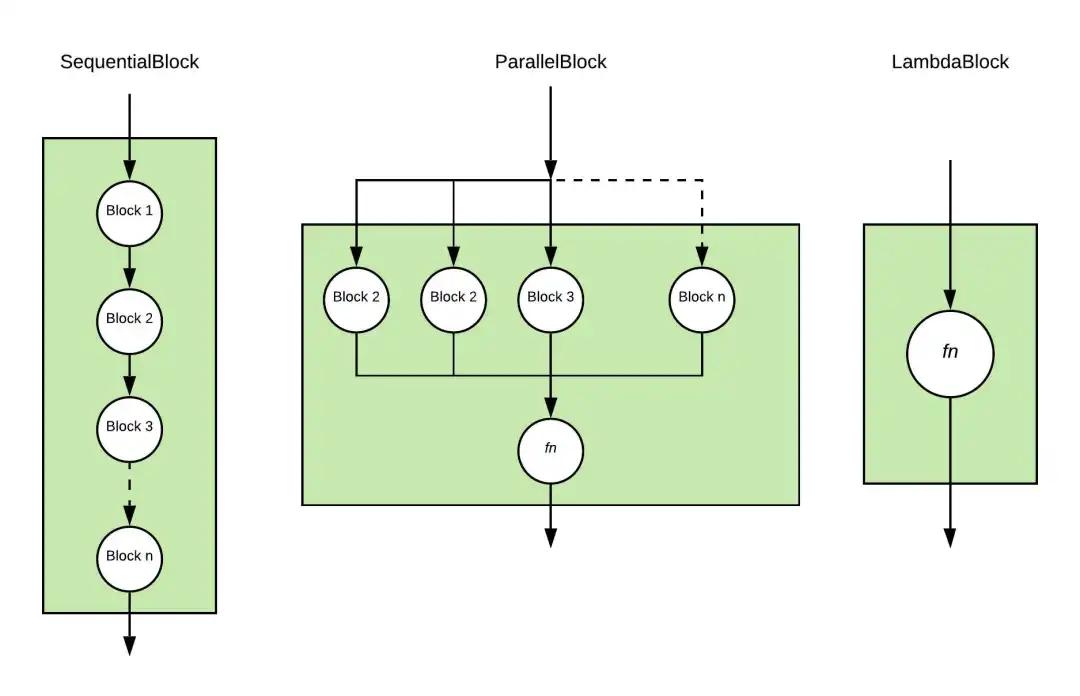
根據(jù)幾種基本的神經(jīng)網(wǎng)絡(luò)工作模式,我們提供幾種Block的變體,
- SequentialBlock 是為了輸出作為下一個block的輸入繼續(xù)執(zhí)行到底。
- parallelblock 是用于將一個輸入并行輸入到每一個子block中,同時也將輸出結(jié)果根據(jù)特定的合并方程合并起來。
- lambdablock 是幫助用戶進行快速操作的一個block,其中不具備任何參數(shù),所以在訓(xùn)練的過程中沒有任何部分在訓(xùn)練過程中更新。
構(gòu)建多層感知機 MLP 神經(jīng)網(wǎng)絡(luò)
我們構(gòu)建一個簡單的多層感知機神經(jīng)網(wǎng)絡(luò),多層感知機是一個簡單的前向型神經(jīng)網(wǎng)絡(luò),只包含幾個全連接層,構(gòu)建這個網(wǎng)路可以直接使用 sequentialblock
- int input = 28 * 28; // 輸入層大小
- int output = 10; // 輸出層大小
- int[] hidden = new int[] {128, 64}; // 隱藏層大小
- SequentialBlock sequentialBlock = new SequentialBlock();
- sequentialBlock.add(Blocks.batchFlattenBlock(input));
- for (int hiddenSize : hidden) {
- // 全連接層
- sequentialBlock.add(Linear.builder().setUnits(hiddenSize).build());
- // 激活函數(shù)
- sequentialBlock.add(activation);
- }
- sequentialBlock.add(Linear.builder().setUnits(output).build());
可以使用直接提供好的 MLP Block
- Block block = new Mlp(
- Mnist.IMAGE_HEIGHT * Mnist.IMAGE_WIDTH,
- Mnist.NUM_CLASSES,
- new int[] {128, 64});
訓(xùn)練
使用如下幾個步驟,
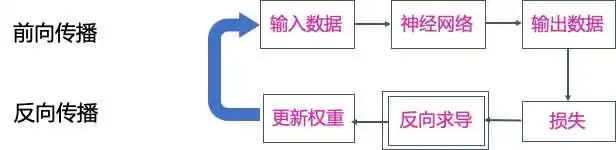
完成一個訓(xùn)練過程初始化:我們會對每一個Block的參數(shù)進行初始化,初始化每個參數(shù)的函數(shù)都是由設(shè)定的 initializer決定的。前向傳播:這一步把輸入數(shù)據(jù)在神經(jīng)網(wǎng)絡(luò)中逐層傳遞,然后產(chǎn)生輸出數(shù)據(jù)。計算損失:我們會根據(jù)特定的損失函數(shù) loss 來計算輸出和標記結(jié)果的偏差。反向傳播:在這一步中,利用損失反向求導(dǎo)計算出每一個參數(shù)的梯度。更新權(quán)重,會根據(jù)選擇的優(yōu)化器,更新每一個在 Block 上的參數(shù)的值。
精簡
DJL 利用了 Trainer 結(jié)構(gòu)體精簡了整個過程,開發(fā)者只需要創(chuàng)建Trainer 并指定對應(yīng)的initializer,loss,optimizer即可,這些參數(shù)都是由TrainingConfig設(shè)定,來看參數(shù)的設(shè)置。TrainingListener 訓(xùn)練過程設(shè)定的監(jiān)聽器,可以實時反饋每個階段的訓(xùn)練結(jié)果,這些結(jié)果可以用于記錄訓(xùn)練過程或者幫助 debug 神經(jīng)網(wǎng)絡(luò)訓(xùn)練過程中遇到的問題。用戶可以定制自己的 TrainingListener 來訓(xùn)練過程進行監(jiān)聽
- DefaultTrainingConfig config = new DefaultTrainingConfig(Loss.softmaxCrossEntropyLoss())
- .addEvaluator(new Accuracy())
- .addTrainingListeners(TrainingListener.Defaults.logging());
- try (Trainer trainer = model.newTrainer(config)){
- // 訓(xùn)練代碼
- }
訓(xùn)練產(chǎn)生以后,可以定義輸入的 Shape,之后可以調(diào)用 git函數(shù)進行訓(xùn)練,結(jié)果會保存在本地目錄下
- /*
- * MNIST 包含 28x28 灰度圖片并導(dǎo)入成 28 * 28 NDArray。
- * 第一個維度是批大小, 在這里我們設(shè)置批大小為 1 用于初始化。
- */
- Shape inputShape = new Shape(1, Mnist.IMAGE_HEIGHT * Mnist.IMAGE_WIDTH);
- int numEpoch = 5;
- String outputDir = "/build/model";
- // 用輸入初始化 trainer
- trainer.initialize(inputShape);
- TrainingUtils.fit(trainer, numEpoch, trainingSet, validateSet, outputDir, "mlp");
輸出的結(jié)果圖
- [INFO ] - Downloading libmxnet.dylib ...
- [INFO ] - Training on: cpu().
- [INFO ] - Load MXNet Engine Version 1.7.0 in 0.131 ms.
- Training: 100% |████████████████████████████████████████| Accuracy: 0.93, SoftmaxCrossEntropyLoss: 0.24, speed: 1235.20 items/sec
- Validating: 100% |████████████████████████████████████████|
- [INFO ] - Epoch 1 finished.
- [INFO ] - Train: Accuracy: 0.93, SoftmaxCrossEntropyLoss: 0.24
- [INFO ] - Validate: Accuracy: 0.95, SoftmaxCrossEntropyLoss: 0.14
- Training: 100% |████████████████████████████████████████| Accuracy: 0.97, SoftmaxCrossEntropyLoss: 0.10, speed: 2851.06 items/sec
- Validating: 100% |████████████████████████████████████████|
- [INFO ] - Epoch 2 finished.NG [1m 41s]
- [INFO ] - Train: Accuracy: 0.97, SoftmaxCrossEntropyLoss: 0.10
- [INFO ] - Validate: Accuracy: 0.97, SoftmaxCrossEntropyLoss: 0.09
- [INFO ] - train P50: 12.756 ms, P90: 21.044 ms
- [INFO ] - forward P50: 0.375 ms, P90: 0.607 ms
- [INFO ] - training-metrics P50: 0.021 ms, P90: 0.034 ms
- [INFO ] - backward P50: 0.608 ms, P90: 0.973 ms
- [INFO ] - step P50: 0.543 ms, P90: 0.869 ms
- [INFO ] - epoch P50: 35.989 s, P90: 35.989 s
訓(xùn)練結(jié)束以后,就可以對模型進行識別了和使用了。
關(guān)于作者
我是小小,一個生于二線城市活在一線城市的小小,本期結(jié)束,我們下期再見。




















