













Python真的是瓶頸嗎?
全面披露-我目前是一名Python工程師,因此您可以認(rèn)為我有偏見。但是我想揭露一些對(duì)Python的批評(píng),并反思對(duì)于使用Python進(jìn)行數(shù)據(jù)工程,數(shù)據(jù)科學(xué)和分析的日常工作,速度問題是否有效。
Python太慢了嗎?
我認(rèn)為,此類問題應(yīng)基于特定的上下文或用例提出。與C之類的編譯語言相比,Python的數(shù)字運(yùn)算速度慢嗎?是的。這個(gè)事實(shí)已經(jīng)存在多年了,這就是為什么速度如此重要的Python庫(例如numpy)在后臺(tái)充分利用C的原因。
但是對(duì)于所有用例來說,Python是否比其他(難于學(xué)習(xí)和使用)語言慢很多?如果查看許多為解決特定問題而優(yōu)化的Python庫的性能基準(zhǔn),它們與編譯語言相比表現(xiàn)良好。例如,看一下FastAPI性能基準(zhǔn)測(cè)試-顯然,Go作為一種編譯語言比Python快得多。盡管如此,F(xiàn)astAPI還是擊敗了Go的一些用于構(gòu)建REST API的庫:
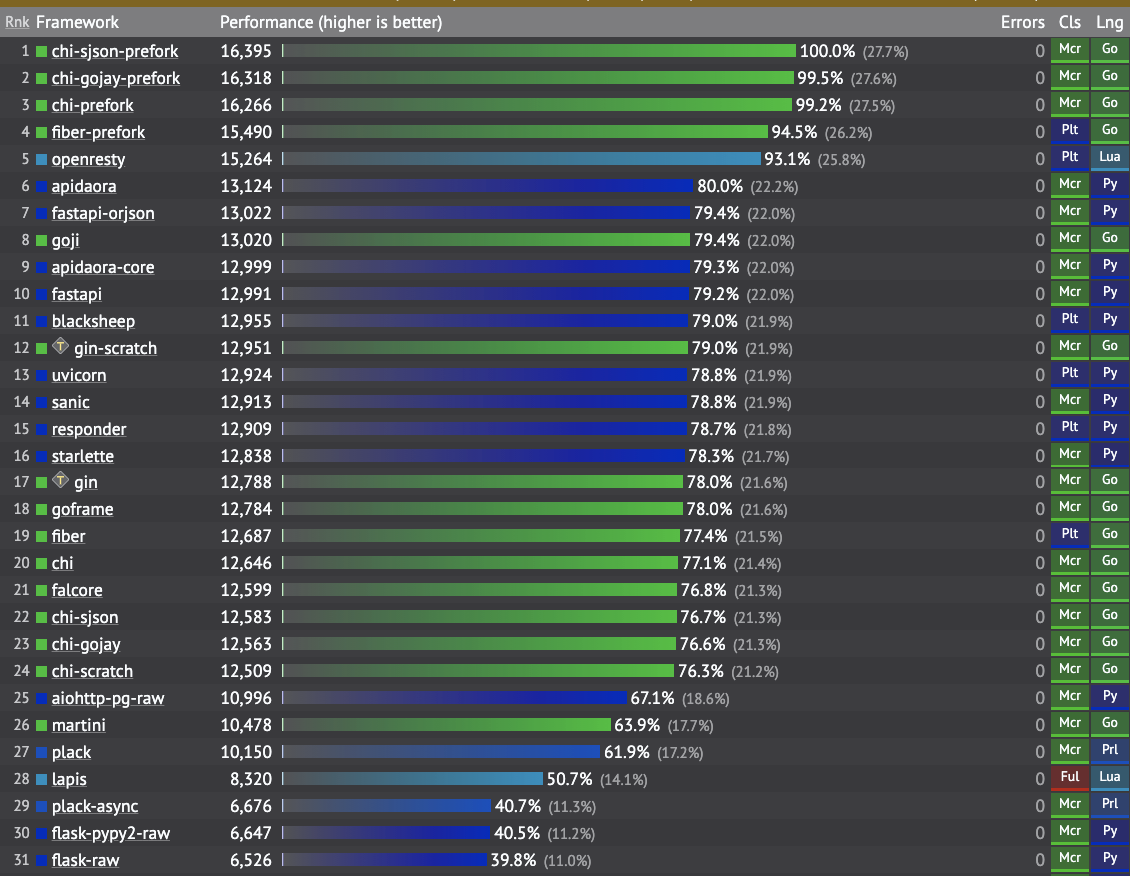
> Web Framework Benchmarks — image by the author
旁注:上面的列表不包括具有更高性能的C ++和Java Web框架。
類似地,當(dāng)將Dask(用Python編寫)與Spark(用Scala編寫)比較用于數(shù)據(jù)密集型神經(jīng)成像管道[2]時(shí),作者得出以下結(jié)論:
總體而言,我們的結(jié)果表明,發(fā)動(dòng)機(jī)之間的性能沒有實(shí)質(zhì)性差異。
我們應(yīng)該問自己的問題是我們真正需要多少速度。如果您運(yùn)行每天僅觸發(fā)一次的ETL作業(yè),則可能需要20秒鐘還是200秒鐘都不在乎。然后,您可能希望使代碼易于理解,打包和維護(hù),特別是考慮到與昂貴的工程時(shí)間相比,計(jì)算資源變得越來越負(fù)擔(dān)得起。
代碼速度與實(shí)用性
從務(wù)實(shí)的角度來看,在選擇用于日常工作的編程語言時(shí),我們需要回答許多不同的問題。
(1) 可以使用這種語言可靠地解決多個(gè)業(yè)務(wù)問題嗎?
如果您只關(guān)心速度,那就不要使用Python。對(duì)于各種用例,都有更快的替代方法。Python的主要優(yōu)點(diǎn)在于其可讀性,易用性以及可以解決的許多問題。Python可以用作將無數(shù)不同的系統(tǒng),服務(wù)和用例聯(lián)系在一起的膠水。
(2) 能找到足夠的懂這種語言的員工嗎?
由于Python非常易于學(xué)習(xí)和使用,因此Python用戶數(shù)量不斷增長(zhǎng)。以前曾在Excel中處理數(shù)字的業(yè)務(wù)用戶現(xiàn)在可以快速學(xué)習(xí)在Pandas中進(jìn)行編碼,從而學(xué)會(huì)自給自足,而無需始終依賴IT資源。同時(shí),這消除了IT和分析部門的負(fù)擔(dān)。它還可以縮短實(shí)現(xiàn)價(jià)值的時(shí)間。
如今,與那些能夠使用Java或Scala做到這一點(diǎn)的數(shù)據(jù)工程師相比,更加容易了解Python并且可以使用該語言維護(hù)Spark數(shù)據(jù)處理應(yīng)用程序的人更加容易。許多組織只是因?yàn)檎业?quot;講"該語言的員工的機(jī)會(huì)較高,而逐漸在許多用例上轉(zhuǎn)向使用Python。
相比之下,我知道迫切需要Java或C#開發(fā)人員來維護(hù)其現(xiàn)有應(yīng)用程序的公司,但是這些語言很困難(需要花費(fèi)數(shù)年時(shí)間才能熟練使用),并且對(duì)于新程序員來說似乎沒有吸引力,他們可能會(huì)在利用更簡(jiǎn)單的語言(例如,Go或Python。
來自不同領(lǐng)域的專家之間的協(xié)同作用
如果您的公司使用Python,則業(yè)務(wù)用戶,數(shù)據(jù)分析師,數(shù)據(jù)科學(xué)家,數(shù)據(jù)工程師,數(shù)據(jù)工程師,后端和Web開發(fā)人員,DevOps工程師甚至系統(tǒng)管理員都很有可能使用相同的語言。這可以在項(xiàng)目中產(chǎn)生協(xié)同作用,使來自不同領(lǐng)域的人們可以一起工作并利用相同的工具。
> Photo by Startup Stock Photos from Pexels
數(shù)據(jù)處理的真正瓶頸是什么?
根據(jù)我自己的工作,我通常遇到的瓶頸不是語言本身,而是外部資源。更具體地說,讓我們看幾個(gè)例子。
(1) 寫入關(guān)系數(shù)據(jù)庫
在以ETL方式處理數(shù)據(jù)時(shí),我們需要最終將此數(shù)據(jù)加載到某個(gè)集中位置。盡管我們可以利用Python中的多線程功能(通過使用更多線程)將數(shù)據(jù)更快地寫入某些關(guān)系數(shù)據(jù)庫中,但并行寫入次數(shù)的增加可能會(huì)最大化該數(shù)據(jù)庫的CPU容量。
實(shí)際上,當(dāng)我使用多線程來加快對(duì)AWS上RDS Aurora數(shù)據(jù)庫的寫入速度時(shí),這發(fā)生在我身上。然后,我注意到writer節(jié)點(diǎn)的CPU使用率上升到如此之高,以至于我不得不使用更少的線程來故意降低代碼速度,以確保不會(huì)破壞數(shù)據(jù)庫實(shí)例。
這意味著Python具有并行化和加速許多操作的機(jī)制,但是關(guān)系數(shù)據(jù)庫(受CPU內(nèi)核數(shù)量的限制)具有其局限性,僅通過使用更快的編程語言就不可能解決它。
(2) 調(diào)用外部API
使用外部REST API(您可能希望從中提取數(shù)據(jù)以滿足數(shù)據(jù)分析需求)是另一個(gè)例子,其中語言本身似乎并不是瓶頸。盡管我們可以利用并行性來加快數(shù)據(jù)提取的速度,但這可能是徒勞的,因?yàn)樵S多外部API限制了我們可以在特定時(shí)間段內(nèi)發(fā)出的請(qǐng)求數(shù)量。因此,您可能經(jīng)常會(huì)發(fā)現(xiàn)自己故意降低了腳本運(yùn)行速度,以確保不超出API的請(qǐng)求限制:
- time.sleep(10)
(3) 處理大數(shù)據(jù)
根據(jù)我處理海量數(shù)據(jù)集的經(jīng)驗(yàn),無論使用哪種語言,都無法將真正的"大數(shù)據(jù)"加載到筆記本電腦的內(nèi)存中。對(duì)于此類用例,您可能需要利用Dask,Spark,Ray等分布式處理框架。使用單個(gè)服務(wù)器實(shí)例或便攜式計(jì)算機(jī)時(shí),可以處理的數(shù)據(jù)量受到限制。
如果您想將實(shí)際的數(shù)據(jù)處理工作轉(zhuǎn)移到一組計(jì)算節(jié)點(diǎn)上,甚至可能利用GPU實(shí)例來進(jìn)一步加快計(jì)算速度,那么Python恰好具有一個(gè)龐大的框架生態(tài)系統(tǒng),可簡(jiǎn)化此任務(wù):
- 您是否想利用GPU加快數(shù)據(jù)科學(xué)的計(jì)算速度?使用Pytorch,Tensorflow,Ray或Rapids(即使使用SQL — BlazingSQL)
- 您是否想加快處理大數(shù)據(jù)的Python代碼的速度?使用Spark(或Databricks),Dask或Prefect(可在后臺(tái)將Dask抽象化)
- 您是否想加快數(shù)據(jù)處理以進(jìn)行分析?使用快速專用的內(nèi)存中柱狀數(shù)據(jù)庫,僅通過使用SQL查詢即可確保高速處理。
而且,如果您需要協(xié)調(diào)和監(jiān)視在計(jì)算節(jié)點(diǎn)集群上發(fā)生的數(shù)據(jù)處理,則有幾種用Python編寫的工作流管理平臺(tái),這些平臺(tái)可以加快開發(fā)并改善數(shù)據(jù)管道的維護(hù),例如Apache Airflow,Prefect或Dagster。如果您想進(jìn)一步了解這些內(nèi)容,請(qǐng)查看我以前的文章。
順便提一句,我可以想象有些抱怨Python的人沒有充分利用它的能力,或者可能沒有為眼前的問題使用適當(dāng)?shù)臄?shù)據(jù)結(jié)構(gòu)。
總而言之,如果您需要快速處理大量數(shù)據(jù),則可能需要更多的計(jì)算資源而不是更快的編程語言,并且Python庫使您可以輕松地在數(shù)百個(gè)節(jié)點(diǎn)之間分配工作。
結(jié)論
在本文中,我們討論了Python是否是當(dāng)前數(shù)據(jù)處理領(lǐng)域的真正瓶頸。盡管Python比許多編譯語言要慢,但它易于使用且功能多樣。我們注意到,對(duì)于許多人來說,語言的實(shí)用性超過了速度方面的考慮。
最后,我們討論了至少在數(shù)據(jù)工程中,語言本身可能不是瓶頸,而是外部系統(tǒng)的局限性以及龐大的數(shù)據(jù)量,無論選擇哪種編程語言,它都禁止在單個(gè)計(jì)算機(jī)上進(jìn)行處理。



















